Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Возможности программы finereaderСодержание книги
Поиск на нашем сайте
Одной из популярных программ оптического распознавания текстов является программа FineReader, созданная компанией ABBYY Software House. FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами. Особенностью программы FineReader является высокая точность распознавания И малая чувствительность к дефектам печати, что достигается бла- 201 годаря применению технологии «целостного целенаправленного адаптивного распознавания». Программа позволяет распознавать с высокой точностью тексты более чем на 175 языках, выводить на печать исходное изображение и распознанный текст, сохранять отсканированное изображение в различных форматах, настраивать панели инструментов программы, а также отвечает требованиям совместимости с новыми операционными системами Microsoft и Macintosh. Версия программы FineReader 6.0 Professional совместима с Windows-2000, -ХР, a FineReader 5.0 Pro for Mac предназначена для владельцев компьютеров Apple Macintosh. Кроме того, отсканированный файл можно сразу же отправить электронным письмом или загрузить в браузер в виде Web-странички. Программа FineReader, начиная с третьей версии, оказалась настолько удачной, что завоевала широкое признание и в России, и за ее пределами. Именно в связи с выходом на мировую арену фирма получила свое новое имя ABBYY, ранее называясь Bit Software. Программные продукты ABBYY FineReader представлены в настоящее время следующими программами: FineReader Sprint, FineReader 6.0 Professional, FineReader 6.0 Corporate Edition и ABBYY FineReader 5.0 Pro for Mac. FineReader Sprint поставляется в комплекте со сканерами. Это продукт для тех, кто только начинает работать с системами распознавания OCR. Версия обладает ограниченной функциональностью по сравнению с версиями Professional и Corporate Edition. FineReader 6.0 Corporate Edition разработана с учетом запросов корпоративных клиентов и поддерживает такие функции, как работа в локальной сети, пакетный поиск и индексирование, распознавание штрих-кодов и разбивка изображений. FineReader Scripting Edition позволяет создавать интегрированные решения, обладающие всеми возможностями Corporate Edition. Интерфейс программы ABBYY FineReader 5.0 Pro for Mac, включая панели управления, пиктограммы и диалоговые окна, создавался непосредственно для Mac OS. Поддержаны все основные технологии Apple, включая QuickTime, Speech, Drag and Drop и Navigation Services. Продукт разработан компаниями ABBYY Software House и Sound & Vision.Inc. Для автоматизации ввода платежных документов в банковских системах выпускается программа FineReader Банк, позволяющая значительно повысить эффективность работы. При создании платежного документа программа генерирует и печатает штрих-код, что позволяет при получении в банке документа и сканировании кода дополнительно идентифицировать данные. В комплект ABBYY FineReader 6.0 Professional помимо дистрибутивного компакт-диска входят руководство пользователя и ли- 202 цензионный договор. Для установки программы необходим компьютер, отвечающий следующим требованиям: • ПК с процессором Pentium 200 или более мощным; • операционная система Microsoft Windows XP/2000/NT 4.0 (SP6или выше), Windows ME/98/95 (для работы с локализованным интерфейсом операционная система должна обеспечивать необходимую языковую поддержку); • размер оперативной памяти для Windows XP/2000 — 64 Мбайт,Windows ME/98/95/NT 4.0 - 32 Мбайт; • 160 Мбайт свободного места на жестком диске, включая 90 Мбайт для установки системы в минимальной конфигурации и 70 Мбайт для работы системы; • браузер Microsoft Internet Explorer 5.0 или выше (на компакт-диске находится дистрибутив MS IE 5.5); • 100 %-й Twain-совместимый сканер, цифровая камера илифакс-модем; • дисковод для компакт-дисков; • дисковод 3,5 дюйма или возможность произвести активациюпродукта через Интернет, по электронной почте или по телефону. Это интересно FineReader работает с более чем 30 моделями TWAIN-совместимых сканеров таких компаний, как Hewlett-Packard, Canon, Epson, Microtek. Мастер установки FineReader предельно прост — пользователю предлагается выбрать язык интерфейса, вариант установки и каталог для файлов программы. Для инсталляции на диске должно быть свободно 90 Мбайт. Для удаления программы из компьютера имеются средства деинсталляции. 9.2. ТЕХНОЛОГИЯ РАСПОЗНАВАНИЯ Сложность машинного распознавания текстов заключается в том, что его невозможно построить по жесткому алгоритму хотя бы потому, что для написания одной д той же буквы существует множество вариантов написания. Значит, чтобы компьютер корректно прочитал символы, он должен их «осмыслить». Иными словами, для распознавания текста требуется моделирование рассуждений человека в подобной ситуации, а это принято обозначать термином «искусственный интеллект». Это интересно Технология распознавания, используемая FineReader, базируется на принципах целостности, целенаправленности и адаптивности. 203 Впервые они были сформулированы и применены на практике в конце 80-х гг. XX в. А.Шамисом в системе распознавания «Графит». Исходя из принципа целостности распознаваемое изображение рассматривается как единый объект, состоящий из частей, связанных между собой пространственными соотношениями. По принципу целенаправленности распознавание строится как процесс выдвижения и целенаправленной проверки гипотез об объекте, а принцип адаптивности подразумевает способность системы к самообучению. Каким образом строится распознавание символов? Для выдвижения гипотез о том, что может представлять собой изображение, применяются так называемые признаковые классификаторы. Они используют ряд признаков, на основе которых программа вычисляет степень близости распознаваемого изображения и известных ей классов изображений, после чего выдает список подходящих классов, т. е. гипотезу о принадлежности объекта к тому или иному классу. Кроме того, признаковые классификаторы применяются также и для повышения точности распознавания изображений с дефектами. Полученный набор классов последовательно проверяется структурным классификатором, анализирующим каждый символ. Скажем, если FineReader полагает, что на странице изображена буква «Ф», он специально проверяет те признаки, которые должны быть именно у буквы «Ф», а не у какой-либо другой, сравнивая этот символ со структурным эталоном. Структурный эталон описывает символ как комбинацию структурных элементов (отрезок, дуга, кольцо, точка), находящихся в определенных отношениях между собой. Процесс распознавания делится на этапы выделения структурных элементов в изображении и сопоставлении их с эталоном. Если в окончательный список попало более одной гипотезы, они попарно сравниваются с помощью дифференциальных классификаторов. Если структурный классификатор при распознавании символов не может однозначно выбрать одну из двух букв с похожим написанием, то между этими конкурирующими гипотезами делается дифференциальный выбор. Например, есть две гипотезы: распознаваемый символ представляет собой строчную букву «твердый знак» или «мягкий знак». Чтобы сделать выбор, FineReader целенаправленно проанализирует левый верхний угол буквы, где имеется единственная отличительная деталь между этими буквами. С завершением работы дифференциального классификатора заканчивается распознавание и начинается этап проверки итогового списка гипотез. Окончательная стадия распознавания осуществляется системой контекста — при наличии некоторого количе- 204
Базовые принципы целостности, целенаправленности и адаптации остаются неизменными от версии к версии программы FineReader, ведь именно они позволяют компьютеру приблизиться к логике мышления человека. 9.3. ОРГАНИЗАЦИЯ РАБОТЫ В FINEREADER Основой работы FineReader является так называемый пакет, содержащий всю информацию о распознаваемом документе. Пакет представляет собой набор страниц документа и может содержать около тысячи страниц. В один пакет для удобства работы рекомендуется объединять изображения, логически связанные между собой, например страницы одной книги. Пользователь импортирует в пакет изображение страниц со сканера или непосредственно из файлов графических форматов. В окне Пакет виден список страниц, входящих в открытый пакет. Для просмотра страницы нужно щелкнуть мышью по ее изображению или номеру, при этом откроются файлы, которыми данная страница представлена в пакете. Страницы в окне Пакет могут быть представлены пиктограммами или уменьшенным изображением страницы. Импортированные изображения подвергаются графической обработке. Если исходное изображение представляет собой негатив, оно может быть инвертировано, далее производится очистка от «мусора» — мелких дефектов изображения. Если не нужна цветность, то цветные изображения сводятся к черно-белым, что экономит место на диске и ускоряет процесс распознавания. Следующий шаг — анализ макета страниц пакета, т. е. выделение областей, подлежащих распознаванию. На этом этапе FineReader анализирует ориентацию страницы и переворачивает изображение, если это необходимо, а также выделяет блоки — области, которые при дальнейшем анализе будут интерпретироваться как текст, таблицы или рисунки. После анализа макета страниц, входящих в пакет, проводится собственно распознавание текста и таблиц. Именно технология распознавания является «сердцем» FineReader и обеспечивает ее уникальность, однако этот процесс совершенно незаметен пользователю — он видит только бегущее по тексту выделение и типовую строку состояния, указывающую, сколько информации обработано, а сколько осталось. Далее производится проверка правописания, после чего «на суд» пользователя выносятся слова, которых нет в словаре системы, а также символы, в точности распознавания которых про- 205 грамма не уверена, при этом такие слова и буквы выделяются цветом. Завершающий этап работы программы — сохранение и экспорт результатов распознавания. На самом деле, в сохранении результатов нет нужды, поскольку вся информация, включая распознанный текст и его форматирование, автоматически сохраняются в пакете вместе с исходным изображением и сведениями о макете страниц. Пользователь может просто закрыть FineReader, не опасаясь потери данных, однако отдельно сохраненный текст можно импортировать в различные форматы для дальнейшей работы с ним в других приложениях. Это интересно Каждый из описанных шагов — импорт изображений, анализ документа и распознавание, проверка орфографии и сохранение результатов — представлены кнопками в панели инструментов программы, что значительно упрощает работу. Рассмотрим основные этапы работы с программой FineReader на примере версии FineReader 5.0 для ОС Windows. 9.4. ГЛАВНОЕ ОКНО ПРОГРАММЫ FINEREADER Программа относительно проста в использовании (особенно если учесть сложность выполняемой ею задачи). Отключаемые панели инструментов снабжены всплывающими подсказками, информативная строка состояния поясняет назначение всех элементов управления, имеется мощная справочная система. После запуска программы FineReader (Пуск/Программы/ABBYY FineReader) открывается Главное окно (рис. 9.1) программы.
Внизу окна расположена информационная панель, которую называют также строкой состояния. Она отражает информацию о состоянии программы и производимых ею операциях, а также краткую справку о выбираемых пунктах меню и кнопках. Остальное пространство Главного окна занимают по мере своего появления рабочие окна программы: Пакет, Изображение, Крупный план и Текст.
Рис. 9.1. Главное окно программы FineReader Окна с изображением текущей страницы взаимосвязаны: два показывают общий и крупный планы картинки, третье содержит распознанный текст. Когда вы помещаете курсор на символ в текстовом окне, программа автоматически выделяет соответствующую деталь на крупном плане. При возникновении проблем с распознаванием FineReader выдает достаточно осмысленные сообщения, предлагая изменить параметры сканирования или точнее указать язык документа. Текстовое окно позволяет форматировать и редактировать документ. В окне Крупный план по умолчанию показывается черно-белое изображение независимо от того, какое именно изображение имеет оригинал — цветное, серое или черно-белое. Если ваше изображение цветное и вы хотите, чтобы показываемое в окне Крупный план изображение также было цветным, следует изменить настройки. Для этого в окне Опции (меню Сервис/ОпЦии) на вкладке Вид снимите отметку с пункта Черно-белая палитра в окне Крупный план (рис. 9.2). Взаимное расположение окон на экране можно изменять. Процесс ввода документа в компьютер складывается из этапов сканирования и распознавания изображения, после чего производятся проверка и сохранение полученного электронного документа. 206 207
Рис. 9.2. Окно настройки параметров FineReader I, 9.5. КАК ВВЕСТИ ДОКУМЕНТ ЗА ОДНУ МИНУТУ Перед началом сканирования необходимо включить сканер, если он имеет отдельный от компьютера источник питания, включить компьютер и запустить программу FineReader. Перед вами Мастер Scant Read
'• Со о анера ! И ч сраипз Рис. 9.3. Мастер Scan&Read 208 откроется окно программы. Вставьте в сканер страницу, которую вы хотите распознать, нажмите на стрелку справа от кнопки Scan&Read Программа вызывает специальный режим Мастер Scan&Read, при котором весь процесс сканирования сопровождается подсказками системы (рис. 9.3). Мастер Scan&Read позволяет отсканировать и распознать страницу или открыть и распознать графическое изображение. При работе с мастером следует выполнять его указания. СКАНИРОВАНИЕ ИЗОБРАЖЕНИЙ На первом этапе сканер играет роль «глаза» вашего компьютера при этом полученное изображение является ни чем иным, как набором черных, белых или цветных точек, картинкой, которую невозможно отредактировать ни в одном текстовом редакторе. FineReader взаимодействует со сканером через стандартные драйверы, что обеспечивает ему совместимость практически со всеми современными сканерами. Для сканирования изображения документа кладем на стекло сканера страницу с текстом или книгу и нажимаем кнопку Сканировать (Scan) или в меню Файл выберем пункт Сканировать. Спустя некоторое время в Главном окне программы FineReader появится окно Изображение с «фотографией» вставленной в сканер страницы. Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании, что достигается установкой основных параметров сканирования — типа изображения, разрешения и яркости (рис. 9.4). Сканирование в сером типе изображения (256 градаций) является оптимальным режимом для системы распознавания, и подбор яркости осуществляется автоматически. Черно-белый тип изображения обеспечивает более высокую скорость сканирования, но при этом теряется часть информации о буквах, что может привести к ухудшению качества распознавания на документах среднего и низкого качества печати. Если вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения. Это интересно Для обычных текстов (с размером шрифта 10 и более пунктов) устанавливают разрешение не менее 300 точек на дюйм, а 209
Рис. 9.4. Установка параметров сканирования для текстов с мелким шрифтом (9 и менее пунктов) — 400... 600 точек на дюйм. В большинстве случаев при сканировании подходит среднее значение яркости — 50 %, и только на некоторых документах при сканировании в черно-белом режиме может понадобиться дополнительная настройка яркости. Для удобства сканирования большого числа страниц в программе предусмотрен специальный режим Сканировать несколько страниц. Он позволяет отсканировать несколько страниц в цикле, затем их распознать в один прием и сохранить в выбранном формате. Если у вас нет сканера, вы можете распознавать графические объекты следующих форматов: BMP, PCX, JPEG, TIFF, PNG. Распознаваемое изображение может быть сильно «замусорено», т.е. содержать много лишних точек, возникших в результате сканирования документа среднего или плохого качества. Чтобы уменьшить количество лишних точек, можно воспользоваться опцией Очистить от мусора в меню Изображение. Ряд настроек можно сделать еще перед началом сканирования — в настройках можно указать программе инвертирование изобра- 210 жения, очистку его от «мусора», автоматическое определение ориентации текста на изображении, для чего в меню Сервис/Опции на закладке Сканирование/ Открытие следует отметить соответствующие позиции. Можно также уменьшить разрешение цветного изображения или изображения в оттенках серого (до 100 dpi), что позволит сильно уменьшить размер пакета за счет снижения качества изображений. При распознавании изображение должно иметь стандартную ориентацию, т. е. текст должен читаться сверху вниз и строки должны быть горизонтальными. По умолчанию программа при распознавании определяет и корректирует ориентацию изображения автоматически, но имеется возможность повернуть изображение вручную. После завершения сканирования изображение окажется включенным в конец пакета, если не активна опция Запрашивать номер страницы перед добавлением в пакет, а его пиктограмма отобразится на панели пакета (вертикальная панель слева на экране). Если щелкнуть мышью по этой пиктограмме, можно увидеть все окна FineReader, при этом основное место на экране будет занимать окно изображения и текста, в левой части которого расположено изображение страницы, а в правой будет находиться распознанный текст. Каждая из этих двух частей главного окна программы снабжена стандартными инструментами управления масштабом, а слева от окна изображения имеется еще и небольшая панель инструментов работы с изображением. Если присмотреться внимательно, то на изображении страницы можно увидеть небольшую пунктирную рамку с лупой. Та часть изображения, которая попадет в эту рамку, отображается в окне крупного плана. Щелчок мыши по определенной части изображения переместит центр увеличиваемой области в указанное место. 9.7. АНАЛИЗ МАКЕТА СТРАНИЦ Прежде чем FineReader приступит к собственно распознаванию текста, он должен «знать», какие именно области подлежат распознаванию, как расположены строки. Определение ориентации текста при установке соответствующей опции производится автоматически, хотя можно сделать это и вручную путем поворота исходного изображения. Выделение областей распознавания текста решает еще две задачи: во-первых, отдельными блоками выделяются таблицы и рисунки, котоРЫе не подлежат распознаванию; во-вторых, четкое выделение блоков позволяет максимально корректно сохранить макет исход- 211 ной страницы при передаче распознанного документа во внешние приложения (такие, как MS Word и Adobe Acrobat). Итак, нажимаем кнопку Распознать, при этом различные части нашего изображения, содержащие текст, таблицы или рисунки, оказались обведены рамками разных цветов и обозначены цифрами в углу каждой рамки. Цвет служит для обозначения типа блока — в стандартных настройках зеленый цвет для текста, красный для рисунков и синий для таблиц. Цветовое кодирование можно при желании изменить. Блоки — это заключенные в рамки участки изображения. Блоки выделяют для того, чтобы указать программе, какие участки отсканированной страницы надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы. При обработке изображений выделяются блоки следующих типов: зона распознавания, текст, таблица, картинка и штрих-код (только в версии Office). Обычно автоматический анализ макета страницы работает достаточно корректно, однако иногда приходится подправлять FineReader. Чаще всего это бывает необходимо, если нужно распознать только часть текста, расположенного на странице, или включить в конечный документ не все рисунки. Иногда приходится редактировать макет табличных блоков, поскольку некоторые таблицы оказываются слишком сложными по своей структуре. Еще одной причиной, заставляющей пользователя редактировать макет, являются рисунки оригинала, содержащие текст, например графики с подписями осей. В таких случаях FineReader отдает предпочтение тексту и выделяет подписи как текстовый блок, оставляя сам график без внимания или же выделяя как рисунок какую-либо его часть. Естественным решением этой проблемы будет выделение всего графика как рисунка без распознавания подписей. Более специфическим случаем ручного редактирования макета являются сложные математические или химические формулы. Внутренний формат текста в FineReader очень близок к формату RTF, поэтому он не умеет корректно работать с текстом, расположенным не в строчку (исключение составляют надстрочные символы и буквицы). При работе с документами, содержащими такие формулы, их приходится выделять как рисунки. Ну, и совсем отдельно стоят случаи плохого оригинала. FineReader испытывает естественные трудности при выделении некачественного макета на некачественных изображениях, содержащих много посторонних элементов. В частности, FineReader не любит комментарии, написанные от руки на полях оригинала, поскольку ухитряется углядеть там знакомые символы, выделить 212 их как текстовый блок и распознать, чем нарушает общую структуру основного текста. Многие подобные ошибки могут быть исправлены именно на этапе работы с макетом, поскольку сделать это проще, чем впоследствии редактировать готовый текст. Изменять размеры или форму существующих блоков можно, потянув мышью за их границы. Изменить тип блока позволяет «всплывающее» меню, появляющееся после щелчка мышью по пиктограмме в углу блока, обозначающего его тип. Для более сложного редактирования макета используются панели инструментов, расположенные слева от окна изображения. Они позволяют нарисовать новые блоки заданного типа, добавить или удалить часть блока, хотя удалить блок можно также с клавиатуры нажатием на клавишу [Del] после его выделения. Итак, при автоматическом анализе макета страниц оригинальные изображения достаточно корректно разбиваются на блоки. Неточности, которые программа все-таки допускает, можно легко отредактировать с помощью панели инструментов. 9.8. РАСПОЗНАВАНИЕ ТЕКСТА После создания макета и его редактирования можно приступить к распознаванию. Задача распознавания состоит в том, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. И первое, на что следует обратить внимание — язык распознавания, ведь FineReader поддерживает более сотни языков. Язык, на котором будет проводиться распознавание, выбирается на основной панели инструментов. Это интересно Если исходный текст документа многоязычный, то можно указать несколько языков одновременно, однако следует принять во внимание, что увеличение числа включенных языков замедляет процесс распознавания. Помимо языка оригинала, модуль распознавания учитывает и тип печати, который по умолчанию определяется автоматически, но при необходимости может быть установлен и вручную. При распознавании текстов, напечатанных на матричном принтере в черновом режиме или на пишущей машинке, можно добиться более высокого качества распознавания, установив правильный тип печати. Выделяются два специфических типа печати: матричный принтер и пишущая машинка (Сервис/Опции/Тип печати). Символы, напечатанные на матричном принтере, состоят из отдельных точек, иногда хорошо различимых даже на глаз, а 213 символы пишущей машинки, как правило, имеют одинаковую ширину (моноширинные). Именно эти две особенности должен учитывать FineReader при распознавании. На обычных типографских шрифтах тип печати должен быть установлен в Auto. 9.9. ПРОВЕРКА ПРАВОПИСАНИЯ И СОХРАНЕНИЕ РЕЗУЛЬТАТОВ РАБОТЫ Модуль распознавания анализирует не только отдельные символы, но и целые слова, используя при этом встроенный словарь. Кроме того, этот модуль особым образом помечает «неуверенно распознанные» символы. Работа со словами, неизвестными системе, и с неуверенно распознанными символами осуществляется в модуле проверки правописания. Он вызывается кнопкой Проверить правописание. На рис. 9.5 вы видите спеллер FineReader за работой. Он предлагает варианты, один из которых надо выбрать и нажать кнопку Заменить. Можно поправить ошибку прямо в окне спеллера, а можно оставить слово, как оно есть, если это правильное, но не известное спеллеру слово, и тогда воспользуемся кнопкой Пропустить. Весь распознанный текст виден в окне текста главного окна программы. Оно представляет собой несложный текстовый редактор, позволяющий свободно изменять и гарнитуру шрифта, и его начертание. К тому же в этом окне цветом будут отмечены неуверенно распознанные символы.
Рис. 9.5. Диалогоиос окно проверки ирапописания 214
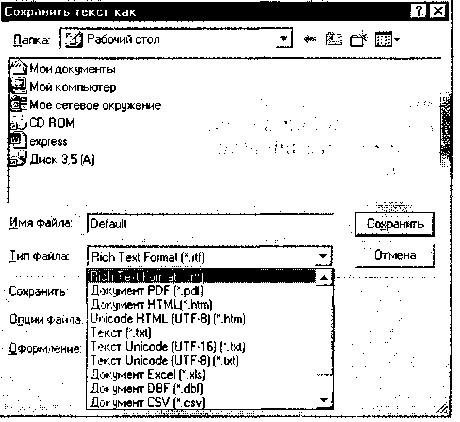
Рис. 9.6. Выбор формата сохранения изображения После окончания проверки правописания следует определить, в каком формате сохранять полученные результаты (кнопка Сохранить), например RTF, DOC, PDF, HTML, DBF, XLS (рис. 9.6). Как видно из приведенного списка, FineReader позволяет передавать результаты распознавания практически во все широко используемые приложения, такие как MS Word, MS Excel, а также использовать автоматический ввод для публикации в Web и для заполнения баз данных. Такая универсальность подчас оказывается просто незаменимой. 9.10. А ЕСЛИ ВЫ ПОЛЬЗУЕТЕСЬ ДРУГОЙ OCR-СИСТЕМОЙ? У каждой модели сканера своя программа, в ней свои настройки, свои возможности. Но есть и кое-что общее. Практически все программы делают быстрое предварительное сканирование (Preview), после которого вы можете: • выделить мышью область сканирования. Если не производитьвыделение, тогда сканируется все рабочее поле сканера или же предыдущая ручная установка этой области; • выбрать режим сканирования: цветной файл с различным ко-личеством цветов, черно-белый, в оттенках серого и другие режимы; • выставить параметры яркости, контраста или выбрать авто-матическое определение этих параметров; • запустить основное сканирование (Scan). ' 215 Было бы неплохо научиться подбирать параметры изображения для оригиналов плохого качества в зависимости от вида дефектов исходного текста, ведь одно дело, когда текст напечатан бледной лентой печатной машинки, и совсем другое, когда шрифт слишком темный с жирными заплывшими буквами. И уж совсем иначе выглядят настройки для сканирования газетного листа на плохой бумаге с мелким шрифтом. Подбор настроек сканера уменьшает количество неверно распознанных букв до вполне приемлемого качества сканирования и распознавания — есть надежда, что ошибки будут не в каждом слове, а хотя бы через строчку. Это интересно Самый важный параметр для программ распознавания — яркость. Опытные люди говорят, что изменения яркости примерно на 3% может изменить количество ошибок на целых 15 %. Особенно важен подбор оптимальной яркости при сканировании достаточно большого объема текста низкого качества, ведь повозившись 10... 15 мин с настройками вы сэкономите часы муторной и канительной работы по вылавливанию ошибок. Подбор выполнить несложно: вы сканируете одну и ту же страничку текста 4...5 раз, изменяя яркость в обе стороны от среднего значения. После этого каждое изображение распознавайте той программой, которая имеется в вашем распоряжении, и сосчитайте количество ошибок по каждому варианту. Те настройки более правильные, где ошибок меньше всего. Можно повторить цикл подбора уже вокруг варианта с меньшим количеством ошибок, уменьшая шаг отклонения. И не забудьте, что выискивать ошибки лучше спеллером (проверкой правописания), ведь читая текст с экрана многие ошибки можно просто не заметить. Контрольные вопросы 1. Для чего используются программы оптического распознавания текста? 2. Перечислите принципы технологии распознавания. 3. Чем этап сканирования отличается от распознавания? 4. Как называются встроенные программы проверки правописания? 5. Как осуществить подбор оптимальной яркости при сканировании? Глава 10 СИСТЕМЫ МАШИННОГО ПЕРЕВОДА Глобализация мировой экономики и интеграционные процессы в Европе сделали проблему взаимопонимания различных народов особенно актуальной. К тому же всемирная сеть Интернет открыла доступ к мировым многоязычным информационным ресурсам, и все это в комплексе явилось мощным стимулом развития переводческих услуг.
|
||||
|
|
Последнее изменение этой страницы: 2021-05-12; просмотров: 389; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.217.10.152 (0.013 с.) |

 ства распознанных букв из слова программа, используя словарь, может «догадаться», что это за слово.
ства распознанных букв из слова программа, используя словарь, может «догадаться», что это за слово. В верхней части Главного окна находится меню системы, под ним — панели инструментов. В программе их четыре: Стандартная, Форматирование, Изображение и Scan&Read. Спрятать или показать инструментальные панели можно через меню Вид/Панели инструментов или через локальное меню, которое открывается щелчком правой кнопки мыши на одной из инструментальных панелей. Панели, которые видны на экране, будут отмечены галочкой.
В верхней части Главного окна находится меню системы, под ним — панели инструментов. В программе их четыре: Стандартная, Форматирование, Изображение и Scan&Read. Спрятать или показать инструментальные панели можно через меню Вид/Панели инструментов или через локальное меню, которое открывается щелчком правой кнопки мыши на одной из инструментальных панелей. Панели, которые видны на экране, будут отмечены галочкой.

 Мастер ScaniReac! поможет Вам быстро ввести бчма+ныи до(yt!ент ь компьютер
Мастер ScaniReac! поможет Вам быстро ввести бчма+ныи до(yt!ент ь компьютер , в открывшемся меню выберите пункт Масmер Scan&Read.
, в открывшемся меню выберите пункт Масmер Scan&Read.