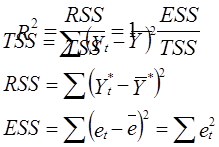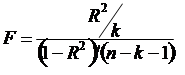Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Простейшие модели временных рядов.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Модели временных рядов - модели, построенные по данным, характеризующим один объект за ряд последовательных моментов (периодов). Каждый уровень временного ряда формируется из трендовой (T), сезонной (S), циклической (U) и случайной (E) компонент. (Моделирование циклических колебаний в целом осуществляется аналогично моделированию сезонных колебаний, поэтому далее рассматривается только сезонная компонента S). В зависимости от вида связи между перечисленными компонентами можно построить аддитивную модель временного ряда: Y = T+S+E; или мультипликативную модель: Y = T*S*E. Выбор одной из двух моделей осуществляется на основе анализа структуры сезонных колебаний. Если амплитуда колебаний относительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается (непостоянна), строят мультипликативную модель, которая ставит уровни ряда в зависимость от значений сезонной компоненты. Построение моделей сводится к расчету значений T, S и Е для каждого уровня ряда. Процесс построения модели включает следующие шаги: 1. Выравнивание исходного ряда методом скользящей средней. 2. Расчет значений сезонной компоненты S. 3. Устранение сезонной компоненты из исходных уровней ряда и получение выравненных данных (T + E) в аддитивной или (T*E) в мультипликативной модели. 4. Аналитическое выравнивание уровней (T+E) или (T*E) и расчет значений T с использованием полученного уравнения тренда. 5. Расчет полученных по модели значений (T+S) или (T*S). 6. Расчет абсолютных и/или относительных ошибок.
32. F-тест качества спецификации множественной регрессионной модели: выдвигаемая статистическая гипотеза, процедура ее проверки, формулы для расчета статистики (15 баллов). Под качеством спецификации модели понимается: - качество выбора функции уравнения регрессии; - качество выбора набора регрессоров (факторов). В качестве меры влияния регрессоров на формирование значения эндогенной переменной y вводится коэффициент детерминации R2 как отношение регрессионной суммы квадратов к общей сумме квадратов. Коэффициент детерминации показывает, какая доля изменения зависимой переменной обусловлена изменениями объясняющих переменных.
где TSS – общая сумма квадратов эндогенной переменной (Totalsumofsquares) RSS – регрессионнаясуммаквадратов (Regression sum of squares) ESS – сумма квадратов остатков (ошибок) (Errorsumofsquares). Вариация зависимой переменной может быть представлена в виде суммы двух составлящих: TSS = RSS + ESS. Если R2=1, т.е. RSS=TSS, a ESS=0, то такая модель называется «абсолютно хорошей». Это означает, что выбранные регрессоры полностью объясняют поведение эндогенной переменной. Если R2=0, т.е. RSS=0, а ESS=TSS, то такую модель называют «абсолютно плохой». В этом случае весь диапазон изменения эндогенной переменной объясняется влиянием случайного возмущения, а выбранные регрессоры не оказывают влияния, не объясняют поведение эндогенной переменной. Ситуация совершенно плохой спецификации равносильна справедливости статистической гипотезы Н0: a1 = a2 = … = ak = 0, где a – коэффициенты (параметры) модели. Необходимо помнить, что R2 – величина случайная, т.к. его конкретное значение вычисляется по результатам случайной выборки. Это означает, что полученное значение коэффициента детерминации отличное от нуля (R2>0) еще не является достаточным основанием считать модель качественной и опровергнуть гипотезу Н0. Замечание. Коэффициент детерминации имеет смысл только при наличии свободного коэффициента a0 в спецификации. Для проверки гипотезы H0 используется F-тест, проверяющий значимость всего уравнения (модели): 1. Формируем случайную величину FTest с известным законом распределения и вычисляем ее значение:
где: k - количество регрессоров в модели, n – количество наблюдений в выборке. Случайная величина FTest подчиняется закону распределения вероятностей Фишера. 2. Находим по таблице значение критическое значение F: Fкрит (Pдов, k, n-k-1), зависящее от уровня доверительной вероятности и двух параметров: (k) и (n-k-1). В ExcelFкрит можно вычислить с помощью функции FРАСПОБР(вероятность;степени_свободы1;степени_свободы2) или F.ОБР.ПХ, где вероятность – это вероятность, связанная с F-распределением, степени_свободы 1 – это числитель степеней свободы (n1= k) и степени_свободы 2 – это знаменатель степеней свободы (n2= (n–k– 1)). 3. Сравниваем значения Fкрит и FTest. Если FTest ≤ Fкр, то гипотеза H0: a1 = a2 = … = ak = 0 принимается, значит, качество регрессии неудовлетворительно и у регрессоров отсутствует какая-либо объясняющая способность в рамках линейной модели. Напротив, когда FTest> Fкр, гипотеза H0 отклоняется и качество регрессии удовлетворительно, т.е. выбранные регрессоры (но не обязательно все из них!!! еще необходимо каждый из них по t-критерию проверить!) объясняют поведение эндогенной переменной y.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-04-26; просмотров: 481; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.226.185.58 (0.01 с.) |