
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Критическое значение хи-квадрат для правосторонней областиСодержание книги
Поиск на нашем сайте
c2кр( 2; 0,05)=6,0. Поскольку величина В меньше c2кр (2; 0,05), отвергнуть нулевую гипотезу об однородности дисперсий нет оснований.
Дисперсионный анализ предусматривает вычисление: · суммы квадратов
Sобщ = 701,65; Sфакт = 19,81; Sост = 681,84;
· оценок дисперсий
μ*2 общ=701,65/19=36,93; μ*2 факт=19,81/2=9,91; μ*2 ост=681,84/17=40,10.
Оценка факторной дисперсии меньше оценки остаточной дисперсии, поэтому можно сразу утверждать справедливость нулевой гипотезы о равенстве математических ожиданий по слоям выборки, Иначе говоря, в данном примере фактор Φ не оказывает существенного влияния на случайную величину.
КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИОННЫЙ АНАЛИЗ
Матрица данных
Многие объекты исследования характеризуются множеством параметров, и по результатам наблюдения за их функционированием формируются многомерные совокупности (матрицы) ЭД
Строки такой матрицы соответствуют результатам регистрации всех наблюдаемых параметров объекта в одном эксперименте, а столбцы содержат результаты наблюдений за одним параметром (фактором, вариантой) во всех экспериментах. Обозначим количество параметров через m (m >1), а количество наблюдений – через n. В матрице элемент хij соответствует значению j -й варианты в i -м наблюдении. Матрица, вообще говоря, может содержать пустые значения некоторых элементов, например, из-за пропусков в регистрации значений параметров. В многомерном анализе желательно устранить пропущенные значения. Для этого существуют специальные приемы, в частности, вычеркивание соответствующих строк матрицы или занесение средних значений вместо отсутствующих. В дальнейшем будем считать, что матрица не содержит пустых элементов, а параметры объекта характеризуются непрерывными случайными величинами. Методы обработки матрицы ЭД основаны на следующем предположении: если объект подвергнуть новому обследованию и получить, вообще говоря, другую матрицу данных, то после ее обработки с помощью тех же методов будут получены результаты, близкие к результатам обработки первой матрицы. Данное предположение основано на статистической гипотезе формирования матрицы ЭД. Матрица порождается случайным образом в соответствии с определенной вероятностной закономерностью, а именно: в m -мерном пространстве параметров существует некоторое (пусть и неизвестное) распределение вероятностей, и каждая строка матрицы появляется в соответствии с этим распределением независимо от появления других строк.
Каждый столбец матрицы представляет собой случайную выборку значений одного параметра объекта. Указанное предположение означает, во-первых, что оценки моментов и параметров распределения, вычисленные по выборке, будут близки к истинным значениям, во-вторых, значения непрерывных функций, построенных по этим оценкам, будут близки к значениям функций, построенным по истинным значениям параметров. Таким образом, объектом исследования в многомерном анализе является многомерная случайная величина, представленная выборкой конечного объема. К такой выборке применимы все методы и оценки, рассмотренные при обработке одномерных ЭД. Конечно, приведенные суждения не являются доказательством допустимости применения рассматриваемых методов, но вполне подтверждаются практикой. Параметры, характеризующие объект исследования, имеют разный физический смысл, и матрица данных существенно изменяется, если изменяются шкалы, в которых измеряются те или иные параметры. Матрицу данных еще до проведения анализа целесообразно привести к стандартному виду, т.е. стандартизовать значения вариант (напомним, что среднее значение стандартизованной варианты равно нулю, дисперсия – единице). В тех случаях, когда все варианты измеряются в одной шкале, это преобразование все-таки желательно, ибо оно упрощает последующие преобразования. Стандартизованную матрицу будем обозначать через U. Переход от исходной к стандартизованной матрице осуществляется следующим образом. 1. По каждой варианте вычисляются оценки: · математического ожидания · дисперсии
2. Вычисляются элементы стандартизованной матрицы
Элементы матрицы U являются безразмерными величинами. Именно матрица U будет являться объектом последующей обработки.
Корреляционный анализ
Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными. Различают два вида зависимостей между величинами (факторами): функциональную и статистическую.
При функциональной зависимости двух величин значению одной из них обязательно соответствует одно или несколько точно определенных значений другой величины. Функциональная связь двух факторов возможна лишь при условии, что вторая величина зависит только от первой и не зависит ни от каких других величин. Функциональная связь одной величины с множеством других возможна, если эта величина зависит только от этого множества факторов. В реальных ситуациях существует бесконечно большое количество свойств самого объекта и внешней среды, влияющих друг на друга, поэтому такого рода связи не существуют, иначе говоря, функциональные связи являются математическими абстракциями. Их применение допустимо тогда, когда соответствующая величина в основном зависит от соответствующих факторов. При исследовании сложных систем многие параметры следует считать случайными, что исключает проявление однозначного соответствия значений. Воздействие общих факторов, наличие объективных закономерностей в поведении объектов приводят лишь к проявлению статистической зависимости. Статистической называют зависимость, при которой изменение одной из величин влечет изменение распределения других (другой), и эти другие величины принимают некоторые значения с определенными вероятностями. Функциональную зависимость в таком случае следует считать частным случаем статистической: значению одного фактора соответствуют значения других факторов с вероятностью, равной единице. Однако на практике такое рассмотрение функциональной связи применения не нашло. Более важным частным случаем статистической зависимости является корреляционная зависимость, характеризующая взаимосвязь значений одних случайных величин со средним значением других, хотя в каждом отдельном случае любая взаимосвязанная величина может принимать различные значения. Если же у взаимосвязанных величин вариацию имеет только одна переменная, а другая является детерминированной, то такую связь называют не корреляционной, а регрессионной. Например, при анализе скорости обмена с жесткими дисками можно оценивать регрессию этой характеристики на определенные модели, но не следует говорить о корреляции между моделью и скоростью. При исследовании зависимости между одной величиной и такими характеристиками другой, как, например, моменты старших порядков (а не среднее значение), то эта связь будет называться статистической, а не корреляционной. Корреляционная связь описывает следующие виды зависимостей: · причинную зависимость между значениями параметров. Примером такой зависимости является взаимосвязь пропускной способности канала передачи данных и соотношения сигнал/шум (на пропускную способность влияют и другие факторы – характер помех, амплитудно-частотные характеристики канала, способ кодирования сообщений и др.). Установить однозначную связь между конкретными значениями указанных параметров не удается. Но очевидно, что пропускная способность зависит от соотношения уровней сигнала и помех в канале. Иногда при этом причину и следствие особо не выделяют. В некоторых случаях такая корреляция является бессмысленной, например: если в качестве исходного фактора взять доходы разработчиков антивирусных программ, а за результат – количество вновь появляющихся вирусов, то можно сделать вывод, что разработчики антивирусов "стимулируют" создание вирусов;
· "зависимость" между следствиями общей причины. Подобная зависимость характерна, в частности, для скорости и безошибочности набора текста оператором (указанные факторы зависят от квалификации оператора). Корреляционная зависимость определяется различными параметрами, среди которых наибольшее распространение получили показатели, характеризующие взаимосвязь двух случайных величин (парные показатели): корреляционный момент, коэффициент корреляции. Оценка корреляционного момента (коэффициента ковариации) двух вариант xj и xk вычисляется по исходной матрице Х
Этот показатель неудобен для практического применения, так как имеет размерность, равную произведению размерностей вариант, и по его величине трудно судить о зависимости параметров. Коэффициент ковариации rjk нормированных случайных величин называют коэффициентом корреляции, его оценка
Значение коэффициента корреляции лежит в пределах от –1 до +1. Если случайные величины Xj и Xk независимы, то коэффициент rjk обязательно равен нулю, обратное утверждение неверно. Коэффициент rjk характеризует значимость линейной связи между параметрами: · при rjk =1 значения xij и xik полностью совпадают, т.е. значения параметров принимают одинаковые значения. Иначе говоря, имеет место функциональная зависимость: зная значение одного параметра, можно однозначно указать значение другого параметра; · при rjk = – 1 величины xij и xik принимают противоположные значения. И в этом случае имеет место функциональная зависимость; · при rjk = 0 величины xij и xik практически не связаны друг с другом линейным соотношением. Это не означает отсутствия каких-то других (например, нелинейных) связей между параметрами; · при | rjk | > 0 и | rjk | < 1 однозначной линейной связи величин xij и xik нет. И чем меньше абсолютная величина коэффициента корреляции, тем в меньшей степени по значениям одного параметра можно предсказать значение другого. Используя понятие коэффициента корреляции, матрице ЭД можно поставить в соответствие квадратную матрицу оценок коэффициентов корреляции (корреляционную матрицу)
К числу характерных свойств корреляционной матрицы относят: симметричность относительно главной диагонали, r*jk = r*kj,; единичные значения элементов главной диагонали, rkk =1 (rkk соответствует дисперсии стандартизованного параметра Xk),.
Оценка коэффициента корреляции, вычисленная по ограниченной выборке, практически всегда отличается от нуля. Но из этого еще не следует, что коэффициент корреляции генеральной совокупности также отличен от нуля. Требуется оценить значимость выборочной величины коэффициента или, в соответствии с постановкой задач проверки статистических гипотез, проверить гипотезу о равенстве нулю коэффициента корреляции. Если гипотеза Н0 о равенстве нулю коэффициента корреляции будет отвергнута, то выборочный коэффициент значим, а соответствующие величины связаны линейным соотношением. Если гипотеза Н0 будет принята, то оценка коэффициента не значима, и величины линейно не связаны друг с другом (если по физическим соображениям факторы могут быть связаны, то лучше говорить о том, что по имеющимся ЭД эта взаимосвязь не установлена). Проверка гипотезы о значимости оценки коэффициента корреляции требует знания распределения этой случайной величины. Распределение величины rik изучено только для частного случая, когда случайные величины Uj и Uk распределены по нормальному закону. В качестве критерия проверки нулевой гипотезы Н0 применяют случайную величину
Если модуль коэффициента корреляции относительно далек от единицы, то величина t при справедливости нулевой гипотезы распределена по закону Стьюдента с n–2 степенями свободы. Конкурирующая гипотеза Н1 соответствует утверждению, что значение rik не равно нулю (больше или меньше нуля). Поэтому критическая область двусторонняя. Проверка гипотезы Н0 о равенстве нулю генерального коэффициента парной корреляции двумерной нормально распределенной случайной величины осуществляется в следующей последовательности: · вычисляется значение статистики t; · при уровне значимости a для двусторонней области определяется критическая точка распределения Стьюдента tкр(n–2; a), табл; · сравнивается значение статистики t с критическим значением tкр(n–2; a). Если t < tкр (п–2; a), то нет оснований отвергнуть нулевую гипотезу, иначе гипотеза Н0 отвергается (коэффициент корреляции значим). Когда модуль величины r*ik близок к единице, распределение r*ik отличается от распределения Стьюдента, так как значение | r*ik | ограничено справа единицей. В этом случае применяют преобразование yik=0,5ln[(1+|rik |)/(1–|rik |)]. Величина yik не имеет указанного ограничения, она при п > 10 распределена приблизительно нормально с центром m1*(rik)= 0,5ln [( 1 +|rik|)/( 1 –|rik|)]+ 0,5 |rik|/(n– 1 ) и дисперсией μ2* (rik)=s2(rik)= 1 /(п– 3 ).
|
||||||||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 384; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.221.114.102 (0.009 с.) |

 (6.1)
(6.1) ;
; .
.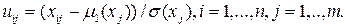
 (6.2)
(6.2) (6.3)
(6.3) . (6.4)
. (6.4) .
.


