
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Принципы параллельных вычисленийСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
ЛЕКЦИЯ 1. Введение Среди многих закономерностей компьютерного мира можно выделить, пожалуй, самый непреложный закон – неуклонное и непрерывное повышение производительности компьютерных систем. Необходимость повышения быстродействия вычислений во многом обуславливается практической потребностью – на более высокопроизводительных компьютерах можно решать сложные вычислительно-трудоемкие научно-технические задачи более быстро. Кроме того, возрастание производительности компьютерной техники позволяет повышать сложность решаемых задач и постоянно расширять круг исследуемых проблем. Росту производительности компьютеров способствует и постоянное совершенствование технологий создания средств компьютерной техники. В сфере производства компьютеров обязательным требованием является соблюдение закона Мура, в соответствии с которым «производительность вычислительных систем должна удваиваться каждые 18 месяцев». Совсем до недавнего времени подобный рост производительности обеспечивался во многом повышением тактовой частоты основных вычислительных элементов компьютеров – процессоров. Но возможности такого подхода оказались не безграничными – после некоторого рубежа дальнейшее увеличение тактовой частоты требует значительных технологических усилий, сопровождается существенным ростом энергопотребления и наталкивается на непреодолимые проблемы теплорегуляции. В таких условиях практически неизбежным явилось кардинальное изменение основного принципа производства компьютерной техники – вместо создания сложных высокочастотных «монолитных» процессоров состоящих из множества равноправных и сравнительно простых вычислительных элементов – ядер. Максимальная производительность процессоров в этом случае является равной сумме производительности вычислительных ядер, входящих в процессоры. Тем самым, «упаковывая» в рамках процессоров все большее количество ядер, можно добиваться роста производительности без «проблематичного» повышения тактовых частот. Итак, вместо «гонки частот» наступила эпоха многоядерных процессоров. Уже в настоящее время массово выпускаемые процессоры содержат от 4 до 8 ядер; компании-производители компьютерной техники заявляют о своих планах по выпуску 12-16-ядерных процессоров. В ближайшей перспективе процессоры с сотнями и тысячами ядер.
При этом важно понимать, что переход к многоядерности одновременно знаменует и наступление эры параллельных вычислений. На самом деле, задействовать вычислительный потенциал многоядерных процессоров можно только, если осуществить разделение выполняемых вычислений на информационно независимые части и организовать выполнение каждой части вычислений на разных ядрах. Подобный подход позволяет выполнять необходимые вычисления с меньшими затратами времени, и возможность получения максимального ускорения ограничивается только числом имеющихся ядер и количеством "независимых" частей в выполняемых вычислениях. Параллельные вычисления становятся неизбежными и повсеместными. Однако необходимость организации параллельных вычислений приводит к повышению сложности эффективного применения многоядерных компьютерных систем. Для проведения параллельных вычислений необходимо "параллельное" обобщение традиционной - последовательной - технологии решения задач на ЭВМ. Так, численные методы в случае многоядерности должны проектироваться как системы параллельных и взаимодействующих между собой процессов, допускающих исполнение на независимых вычислительных ядрах. Применяемые алгоритмические языки и системное программное обеспечение должны обеспечивать создание параллельных программ, организовывать синхронизацию и взаимоисключение асинхронных процессов и т.п. Все перечисленные проблемы организации параллельных вычислений увеличивают существующий разрыв между вычислительным потенциалом современных компьютерных систем и имеющимся алгоритмическим и программным обеспечением применения компьютеров для решения сложных задач. И, как результат, устранение или, по крайней мере, сокращение этого разрыва является одной из наиболее значимых задач современной науки и техники.
ПРИНЦИПЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ Большие задачи. Все задачи принципиально можно разделить на две группы: P (Polinomial) и NP (Non Polinomial) задачи. P задачи характеризуются объемом вычислений
скорость вычислений которых пропорциональна объему данных. Время решения «больших» задач определяется количеством вычислитель ных операций в задаче и быстродействием вычислительных машин. Естествен- но, с ростом быстродействия вычислительных машин растет и размер решаемых задач. Для сегодняшних суперЭВМ доступными являются задачи с числом
Большое количество вычислительных моделей строится на базе решения СЛАУ, при этом размеры решетки (число уравнений) может достигать многих тысяч. Например, при моделировании полупроводниковых приборов число уравнений может быть равно
ЛЕКЦИЯ 2. Параллелельные системы. Параллельная машина содержит множество процессоров П, объединенных сетью обмена данными. Аппаратура одновременно выполняет более одной арифметико-логической или служебной операций.
В параллельных ЭВМ межпроцессорный обмен данными является прин- ципиальной необходимостью, и при медленном обмене однопроцессорный ва- риант может оказаться быстрее многопроцессорного, поэтому количество про- цессоров в параллельной ЭВМ определяется скоростью сетей обмена.
Формы параллелизма Параллелизм — это возможность одновременного выполнения более од- ной арифметико-логической операции или программной ветви. Возможность параллельного выполнения этих операций определяется правилом Рассела, ко- торое состоит в следующем: Программные объекты A и B (команды, операторы, программы) являются независимыми и могут выполняться параллельно, если выполняется следующее условие: (InB
где In(A) — набор входных, а Out(A) — набор выходных переменных объекта A. Если условие (1.1) не выполняется, то между A и B существует зависимость и они не могут выполняться параллельно. Если условие (1.1) нарушается в первом терме, то такая зависимость назы вается прямой. Приведем пример: A: R = R1 + R2 B: Z = R + C Здесь операторы A и B не могут выполняться одновременно, так как результат A является операндом B. Если условие нарушено во втором терме, то такая зависимость называется обратной: A: R = R1 + R2 B: R1 = C1 + C2 Здесь операторы A и B не могут выполняться одновременно, так как выполнение B вызывает изменение операнда в A. Если условие не выполняется в третьем терме, то такая зависимость называется конкуренционной: A: R = R1 + R2 B: R = C1 + C2 Здесь одновременное выполнение дает неопределенный результат. Увеличение параллелизма любой программы заключается в поиске и устранении указанных зависимостей. Наиболее общей формой представления этих зависимостей является ин- формационный граф задачи (ИГ). Пример ИГ, описывающего логику конкрет- ной задачи, точнее порядок выполнения операций в задаче В своей первоначальной форме ИГ, тем не менее, не используется ни математиком, ни программистом, ни ЭВМ.
Более определенной формой представления параллелизма является яруснопараллельная форма (ЯПФ): алгоритм вычислений представляется в виде яру сов, причем в нулевой ярус входят операторы (ветви), не зависящие друг от друга, в первый ярус — операторы, зависящие только от нулевого яруса, во второй — от первого яруса и т. д. Для ЯПФ характерны параметры, в той или иной мере отражающие степень параллелизма метода вычислений: b i — ширина i -го яруса; B — ширина графа ЯПФ (максимальная ширина яруса, т. е. максимум из b i, i = 1, 2,...); li — длина яруса (время операций) и L длина графа; ε — коэффициент заполнения ярусов; θ — коэффициент разброса указанных параметров и т. д. Главной задачей настоящего издания является изучение связи между клас сами задач и классами параллельных ЭВМ. Форма параллелизма обычно достаточно просто характеризует некоторый класс прикладных задач и предъявляет определенные требования к структуре, необходимой для решения этого класса задач параллельной ЭВМ. Изучение ряда алгоритмов и программ показало, что можно выделить сле дующие основные формы параллелизма: • Мелкозернистый параллелизм (он же параллелизм смежных операций или скалярный параллелизм). • Крупнозернистый параллелизм, который включает: векторный паралле- лизм и параллелизм независимых ветвей..
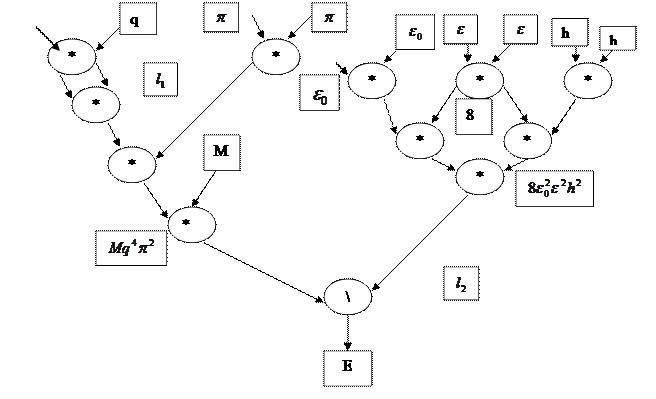
Мелкозернистый параллелизм ( Fine Grain) При исполнении программы регулярно встречаются ситуации, когда исходные данные для i -й операции вырабатываются заранее, например, при выпол нении (i - 2)-й или (i - 3)-й операции. Тогда при соответствующем построении вычислительной системы можно совместить во времени выполнение i -й опера- ции с выполнением (i - 1)-й, (i - 2)-й,... операций. В таком понимании скаляр- ный параллелизм похож на параллелизм независимых ветвей, однако они очень отличаются длиной ветвей и требуют разных вычислительных систем. Рассмотрим пример. Пусть имеется программа для расчета ширины запрещенной зоны транзистора, и в этой программе есть участок — определение энергии примесей по формуле
Тогда последовательная программа для вычисления E будет такой: F1 = M * Q ** 4* P ** 2 F2 = 8 * E0 ** 2* E ** 2 * H** 2 E = F1/F2 Здесь имеется параллелизм, но при записи на Фортране или Ассемблере у нас нет возможности явно отразить его. Явное представление параллелизма для вычисления E задается ЯПФ Ширина параллелизма первого яруса этой ЯПФ (первый такт) сильно зависит от числа операций, включаемых в состав ЯПФ. Так, в примере для l 1 = 4 параллелизм первого такта равен двум, для l 1 = 12 параллелизм равен пяти.
Поскольку это параллелизм очень коротких ветвей и с помощью операторов FORK и JOIN описан быть не может (вся программа будет состоять в основ ном из этих операторов), данный вид параллелизма должен автоматически вы- являться аппаратурой ЭВМ в процессе выполнения машинной программы.
Для скалярного параллелизма часто используют термин мелкозернистый параллелизм (МЗП), в отличие от крупнозернистого параллелизма (КЗП), к ко- торому относят векторный параллелизм и параллелизм независимых ветвей.
ЛЕКЦИЯ 3. ЛЕКЦИЯ 4. ЛЕКЦИЯ 5. МЕЛКОЗЕРНИСТЫЙ ПАРАЛЛЕЛИЗМ Мелкозернистый параллелизм обеспечивается за счет параллелизма внутри базовых блоков (ББ), которые являются частями программ, не содержащими условных и безусловных переходов. Этот вид параллелизма реализуется блока- ми одного процессора: различными АЛУ, умножителями, блоками обращения к памяти, хранения адреса, переходов и так далее.
Принципы распараллеливания и планирования базовых блоков. Размер ББ и его увеличение. Базовые блоки невелики по размеру (5 − 20 команд) и даже при оптимальном планировании параллелизм не может быть большим. На рисунке точками представлена экспериментальная зависимость ускорения от размера базового блока. Поле полученных в экспериментах ре- зультатов ограничено контуром (точками представлены значения для некото- рых ББi).

На основе рисунка с учетом вероятностных характеристик контура ре- зультатов можно получить следующую качественную зависимость: h = a + b w,
ло параллельных ветвей), w – число команд в программе. Следовательно, можно сказать, что
Здесь: tпар и tпосл – времена параллельного и последовательного исполнения одного и того же отрезка программы. Таким образом, основной путь увеличения скалярного параллелизма про- граммы − это удлинение ББ, а развертка − наиболее простой способ для этого. Цикл: DO 1 I=1,N C(I) = A(I) + B(I) 1 CONTINUE имеет небольшую длину ББ, но ее можно увеличить путем развертки приведен- ного цикла на две, четыре и так далее итераций, как показано ниже DO 1 I=1,N,2 C(I) = A(I) + B(I) C(I+1) = A(I+1) + B(I+1) 1 CONTINUE DO 1 I=1,N,4 C(I) = A(I) + B(I) C(I+1) = A(I+1) + B(I+1) C(I+2) = A(I+2) + B(I+2) C(I+3) = A(I+3) + B(I+3) 1 CONTINUE К сожалению, развертка возможна только, если: • все итерации можно выполнять параллельно; • в теле цикла нет условных переходов.
Метод Фишера. Существует большое количество методов увеличения па раллелизма при обработке базовых блоков. Но в большинстве случаев тело цикла содержит операторы переходов. Достаточно универсальный метод пла- нирования трасс с учетом переходов предложил в 80-е годы J.Fisher. Рас- смотрим этот метод на примере рисуна. На схеме в кружках представлены но- мера вершин, а рядом − вес вершины (время ее исполнения); на выходах опера-
торов переходов проставлены вероятности этих переходов. Возможны три варианта путей исполнения тела цикла: • путь 1-2-4 обладает объемом вычислений (5+5+5) и вероятностью 0.8*0.8=0.64; • путь 1-2 имеет объем вычислений 5+5 и вероятность 0.8*0.2=0.16; • путь 1-3 имеет объем вычислений 5+1 и вероятность 0.2. Примем путь 1-2-4 в качестве главной трассы. Остальные пути будем считать простыми трассами. Ограничимся рассмотрением метода планирования трасс только по отношению к главной трассе. Если метод планирования трасс не применяется, то главная трасса состоит из трех независимых блоков. Суммарное время выполнения этих блоков будет в соответствии с вышеприведенными формулами равным:
В методе планирования трасс предлагается считать главную трассу единым ББ, который выполняется с вероятностью 0,64. Если переходов из данной трассы в другие трассы нет, то объединенный ББ выполняется за время
Таким образом, выигрыш во времени выполнения главной трассы составил Т1/Т2 = 1.8 раз. В общем случае при объединении k блоков с равным временем исполнения w получаем:
При построении ЯПФ объединенного ББ и дальнейшем планировании команды могут перемещаться из одного исходного ББ в другой, оказываясь выше или ниже оператора перехода, что может привести к нарушению логики выполнения программы. Чтобы исключить возможность неправильных вычислений, вводятся ком- пенсационные коды. Рассмотрим примеры рисунок. Пусть текущая трасса (рис.а) состоит из операций 1, 2, 3. Предположим, что операция 1 не являет- ся срочной и перемещается поэтому ниже условного перехода 2. Но тогда опе- рация 4 читает неверное значение a. Чтобы этого не произошло, компилятор вводит компенсирующую операцию 1 (рис.б). Пусть теперь операция 3 перемещается выше оператора IF. Тогда операция 5 считает неверное значение d. Если бы значение d не использовалось на расположенном вне трассы крае перехода, то перемещение операции 3 выше оператора IF было бы допустимым.
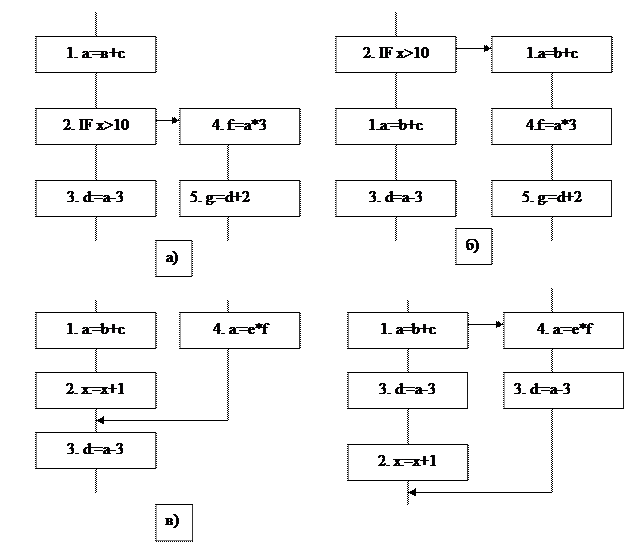
Рассмотрим переходы в трассу извне. Пусть текущая трасса содержит операции 1, 2, 3 (рис.в). Предположим, что компилятор перемещает операцию 3 в положение между операциями 1 и 2. Тогда в операции 3 будет использовано неверное значение a. Во избежание этого, необходимо ввести компенсирующий код 3 (рис.г). Порядок планирования трасс для получения конечного результата таков: 1. Выбор очередной трассы и ее планирование (распараллеливание и размещение по процессорам). 2. Коррекция межтрассовых связей по результатам упаковки по процессорам очередной трассы. Компенсационные коды увеличивают размер машинной программы, но не увеличивают числа выполняемых в процессе вычислений операций. 3. Если все трассы исчерпаны или оставшиеся трассы имеют очень низкую вероятность исполнения, то компиляция программы считается законченной, в противном случае осуществляется переход на пункт 1. Основным объектом распараллеливания в области скалярного параллелизма являются базавые блоки. Если ББ представлен на язык высокого уровня, тогда распараллеливанию подвергаются арифметические выражения. Если ББ представлен на ассемблер или в машинных кодах, то распараллеливается отре- зок программы. Эти операции отличаются. Далее будут рассмотрены оба под- хода, которые используются в компиляторах для автоматического распараллливания.
ЛЕКЦИЯ 6. ЛЕКЦИЯ 7. Планирование ЯПФ базовых блоков. Спланировать – означает указать, на каком процессоре и в каком такте будет запущен на исполнение некоторый блок вычислений. Алгоритмы планирования связаны с природой графа управления: состоит ли он из одного или нескольких базовых блоков, является ли граф управления циклическим или ациклическим графом в случае нескольких базовых блоков. Алгоритмы для одиночных базовых блоков называются локальными, остальные – глобальными. Алгоритмы ациклического планирования связаны с графами управления, которые не содержат циклов, или, что более типично, с циклическими графами, для которых существует самостоятельное управление на каждой обратной дуге графа управления.
Метод списочных расписаний. Планирование для единичного ББ заключается в построении как можно более короткого плана. Поскольку эта проблема имеет переборный характер, внимание было сосредоточено на эвристических алгоритмах планирования. Среди таких алгоритмов наиболее подходящими оказались списочные расписания. Алгоритмы планирования по списку при линейном росте времени планирования при увеличении числа планируемых объектов, дают результаты, отличающиеся от оптимальных всего на 10-15%. В таких расписаниях оператором присваиваются приоритеты по тем или иным эвристическим правилам, после чего операторы упорядочиваются по убыванию или возрастанию приоритета в виде линейного списка. В процессе планирования затем осуществляется назначение операторов процессорам в по- рядке их извлечения из списка. На рисунке (а) представлена исходная ЯПФ. Номера вершин даны внутри кружков, а время исполнения — около вершин. На рисунке (б) приведены уровни вершин. Под уровнем вершины понимается длина наибольшего пути из этой вершины в конечную. Построим для примера два расписания из множества возможных. Для каждого из них найдем характеристики всех вершин по соот ветствущим алгоритмам и примем значения этих характеристик в качестве ве- личин приоритетов этих вершин. В первом расписании величина приоритета вершины есть ее уровень. Это расписание УР. Во втором расписании величина приоритета вершины есть ее уровень без учета времени исполнения, то есть здесь веса всех вершин полага- ются одинаковыми (единичными).
б) Приоритеты и списки вершин (П— приоритеты, В — номера вершин) в) Уровни вершин
г) Реализация расписаний (Р1, Р2 — процессоры, X — простой процессора)
УР (по уровню вершин)
УР без учета веса вершин
Об оптимальности расписания можно судить по количеству простоев про- цессоров. Первое расписание дает 2, второе — 5.
ЛЕКЦИЯ 8. Процессоры потока данных. Существует два типа управления выполнением программы: управление от потока команд (IF − Instruction Flow) и управление от потока данных (DF − Data Flow). Если в ЭВМ первого типа используется традиционное выполнение команд по ходу их расположения в программе, то применение ЭВМ второго типа предполагает активацию операторов по мере их текущей готовности. В случае DF все узлы информационного графа задачи представляются в виде отдельных операторов: КОП О1, О2, A3, БС где О1, О2 — поля для приема первого и второго операндов от других операторов; A3 − адрес (имя) оператора, куда посылается результат; БС − блок событий. В БС записывается число, равное количеству операндов, которое нужно принять, чтобы начать выполнение данного оператора. После приема очередного операнда из БС вычитается единица, когда в БС оказывается нуль, оператор начинает выполняться. Программа полностью повторяет ИГ, но ее операторы могут располагаться в памяти в произвольном порядке. Выполняться они будут независимо от начального расположения строго в соответствии с зависимостью по данным. Это и есть управление потоком данных. Считается, что такая форма представления ИГ обеспечивает наибольший потенциальный параллелизм. В случае зависимостной архитектуры компилятор или программист выяв- ляют параллелизм в программе и представляют его аппаратуре путем описания зависимостей между операциями в машинной программе. Аппаратура все же еще должна определить на этапе исполнения, когда каждая операция становит- ся независимой от всех других операций, и тогда выполнить планирование. Но прежде рассмотрим вопрос о влиянии количества регистров общего на- значения РОН на величину параллелизма. Существует несколько видов памяти с разным временем доступа и объемом хранимой информации:
Регистры – самая быстрая память. Обычно их немного. Рассмотрим сле- дующую ситуацию. Пусть требуется сложить четыре числа - Рассмотрим эту операцию для двух случаев: в микропроцессоре имеется 2 или 4 РОН. В программе для двух РОН из-за недостатка регистров приходится промежуточные результаты записывать в память, поэтому программы удлиняется и в нейт нет параллелизма. Если предположить, что одно обращение к памяти занимает 3 такта, а сложение – 1 такт, то приведенная программа выполняется за 30 тактов. Программа mov r1, [a1] mov r2, [a2] r1=r1+r2
mov [b1], r1 mov r1, [a3] mov r2, [a4] r1=r1+r2
mov [b2], r1 mov r1, [b1] mov r2, [b2] r1=r1+r2 mov [c], r1
Увеличение числа регистров до 4 –ех устраняет использование промежу- точных переменных и позволяет параллельное выполнение операций: mov r1, [a1] mov r2, [a2] mov r3, [a3] mov r4, [a4] r1=r1+r2, r3=r3+r4 r1=r1+r2 mov [c], r1 Итого, 17 тактов, что значительно меньше, чем в предыдущем случае. При увеличении объема данных и числа РОН выигрыш будет намного больше. Микропроцессор Pentium Pro компании Intel (рис) построен по принципу управления от потока данных (DF), отсюда и получил название потокового. Главное в потоковом процессоре − выполнить команду сразу, как только станут доступны входные операнды и освободятся необходимые функциональные устройства Блок ВД (выборка и декодирование команд) по существу является микро- программной частью компилятора. Он обеспечивает: • Чтение команд из КЭШ и их преобразование из формата i86 в формат DF (управление от потока данных) • Запись команд в буфер команд в буфер команд БК. В БК команды пред- ставлены в трехадресном формате. Поскольку в системе команд i 86 мало РОН (всего 8), то для устранения ложных зависимостей по данным в МП Pentium Pro введено 40 дополнительных регистров, которые недоступны программисту. Они используются аппаратурой для временного хранения результатов. Обозначим эти регистры временного хранения через V. Тогда
на рисунке V1, V2 и VР обозначают соответственно номера регистров для хранения первого, второго операндов и результата. Блок ПВ (планирование и выполнение) является центральным блоком МП Pentium Pro. Именно он выполняет команды в порядке их готовности. ПВ содержит несколько АЛУ и устройств обращения к памяти. За один такт ПВ выполняет следующие действия: • Выделяет в БК команды, готовые к исполнению. • Планирует и назначает на исполнение до пяти команд, поскольку в ПВ имеется пять исполнительных устройств. • Выполняет эти команды. • Передает результаты в блок БК, вычитает единицу из БС и в случае воз можности устанавливает в командах признак готовности. Чтобы блок ПВ мог выполнять за один такт до 3...5 команд, необходимо, чтобы в БК находилось до 20...30 команд. По статистике среди такого объема команд в среднем имеется имеется 4...5 команд условных переходов. Следова- тельно, в БК находится некоторая трасса выполнения команд. Выбор таких наиболее вероятных трасс является новой функцией МП с непоследовательным выполнением команд. Эта функция выполняется в блоке ВД на основе расши- ренного до 512 входов буфера истории переходов. Поскольку реально вычисленный в ПВ адрес перехода не всегда совпадает с предсказанным в блоке ВД, то вычисление в ПВ выполняется условно, т. е. результат записывается в регистр временного хранения. Только после того, как установлено, что переход выполнен правильно, блок удаления команд УК вы- водит из БК все выполненные команды, расположенные за командой условного перехода, преобразует их в формат системы i 86 и производит запись результа- тов по адресам, указанным в исходной программе.
ЛЕКЦИЯ 9. VLIW. Архитектура процессора С6 (Texas Instruments). Особенностью процес сора является наличие двух практически идентичных вычислительных блоков, которые могут работать параллельно и обмениваться данными. Каждый блок содержит четыре фунциональных устройства (ФУ), которые также могут работать параллельно. На рисунке представлена структура процессора. Блоки выборки программ, диспетчирования и декодирования команд могут каждый такт доставлять функциональным блокам до восьми 32-разрядных команд. Обработка команд производится в в путях А и В, каждый из которых содержит 4 функциональных устройства (L, S, M, и D) и 16 32-разрядных регистра общего назначения. Каждое ФУ одного пути почти идентично соответствующему ФУ другого пути.
Каждое ФУ прямо обращается к регистровому файлу внутри своего пути, однако существуют дополнительные связи, позволяющие ФУ одного пути получать доступ к данным другого пути. Функциональные устройства описаны в таблице:
За один такт из памяти всегда извлекается 8 команд. Они составляют пакет выборки длиною 256 разрядов. В нем содержится 8 32-разрядных команд. Выполнение отдельной команды частично управляется р- разрядом, распо ложенным в этой команде. р − разряды сканируюся слева направо (к более старшим адресам команд в пакете). Если в команде i р -разряд равен 1, то i+ 1 команда может выполняться параллельно с i -ой. В противном случае команда i+ 1 должна выполняться в следующем цикле, то есть после цикла, в котором выполнялась команда i. Все команды, которые будут выполниться в одном цик- ле, образуют исполнительный пакет. Пакет выборки и исполнительный пакет это различные объекты. Исполнительный пакет может содержать до 8 команд. Каждая команда этого пакета должна использовать отдельное функциональное устройство. Исполнительный пакет не может пересекать границу 8 слов. Следовательно, последний р -разряд в пакете всегда устанавливается в 0 и каждый пакет выборки запускает новый исполнительный пакет. Имеется три типа пакетов выборки: полностью последовательные, полностью параллельные, и смешанные. В полно стью последовательных пакетах р- разряды всех команд установлены в 0, следо- вательно, все команды выполняются строго последовательно. В полностью па- раллельных пакетах р -разряды всех команд установлены в 1 и все команды вы- полняются параллельно. Пример смешанного пакета выборки из восьми 32- разрядных команд приведен на рисунке.
Состав исполнительных пакетов для этой команды:
Технология MMX. В 1997 году компания Intel выпустила первый процессор с архитектурой SIMD с названием Pentium MMX (MultiMedia eXtension), который реализует частный случай векторной абработки. При разработке МMХ специалистами Intel как в области архитектуры, так и в области программного обеспечения был обследован большой объем приложений различного назначения: графика, полноэкранное видео, синтез музыки, компрессия и распознавание речи, обработка образов, сигналов, игры, учебные приложения. Анализ участков с большим объемом вычислений показал, что все приложения имеют следующие общие свойства, определившие выбор системы команд и структуры данных: • небольшая разрядность целочисленных данных (например, 8-разрядные пикселы для графики или 16-разрядное представление речевых сигналов); • небольшая длина циклов, но большое число их повторений; • большой объем вычислений и значительный удельный вес операций умножения и накопления; • существенный параллелизм операций в программах. Это и определило новую структуру данных и расширение системы команд. Технология ММХ выполняет обработку параллельных данных по методу SIMD. Для этого используются четыре новых типа данных, 57 новых команд и восемь 64-разрядных ММХ-регистров. Метод SIMD позволяет по одной команде обрабатывать несколько пар операндов (векторная обработка). Основой новых типов данных является 64- разрядный формат, в котором размещаются следующие четыре типа операндов: • упакованный байт (Packed Byte) − восемь байтов, размещенных в одном 64- разрядном формате; • упакованное слово (Packed Word) − четыре 16-разрядных слова в 64- разрядном формате; • упакованное двойное слово (Packed Doubleword) − два 32-разрядных двойных слова в 64-разрядном формате; • учетверенное слово (Quadword) − 64-разрядная единица данных. Совместимость ММХ с операционными системами и приложениями обеспечивается благодаря тому, что в качестве регистров ММХ используются 8 регистров блока плавающей точки архитектуры Intel. Это означает, что операци онная система использует стандартные механизмы плавающей точки также и для сохранения и восстановления ММХ кода. Доступ к регистрам осуществля- ется по именам MM0-MM7. MMX команды обеспечивают выполнение двух новых принципов: операции над упакованными данными и арифметику насыщения.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 613; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.59.214.200 (0.015 с.) |

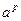 , где a – объем входных данных, p – полином невысокой степени. Такие задачи под силу современным многопроцессорным ЭВМ и называются «большими». NP задачи характеризуются выражением
, где a – объем входных данных, p – полином невысокой степени. Такие задачи под силу современным многопроцессорным ЭВМ и называются «большими». NP задачи характеризуются выражением  и современным машинам «не по зубам». Для решения таких задач могут использоваться квантовые ЭВМ,
и современным машинам «не по зубам». Для решения таких задач могут использоваться квантовые ЭВМ, операций с плавающей точкой.
операций с плавающей точкой. . Известно, что решение такой системы требует порядка
. Известно, что решение такой системы требует порядка  вычислений по
вычислений по 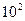 плавающих операций для каждого вычисления. Тогда общее время расчета одного варианта моделирования будет порядка
плавающих операций для каждого вычисления. Тогда общее время расчета одного варианта моделирования будет порядка  операций.
операций.
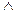 OutA)
OutA)  (InA
(InA 









 .
.




