
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Независимостные архитектуры.Содержание книги
Поиск на нашем сайте
К таким архитектурам относятся процессоры со сверхдлинной командой (СДК), однако для них чаще используется название − процессоры VLIW (Very Long Instruction Word). Чтобы выполнить операции параллельно, система должна определить, являются ли операции независимыми от других. Суперскалярный и потоковый процессоры представляют два способа извлечения этой информации на этапе исполнения. В случае потокового процессора эта явная информация используется, чтобы определить момент запуска команды. Суперскалярный процессор делает то же самое, однако, из-за отсутствия явной информации он вынужден сначала определять зависимости между командами. Напротив, для независимостных архитектур компилятор определяет параллелизм в программе и привязывает его к аппаратуре путем указания, какие операции независимы от других. Эта информация есть прямое указание для аппаратуры, какие операции можно проводить в том же самом цикле. Вместо описания всех независимых команд обычно описывают только часть этих независимых команд, которые предполагается выполнить одновременно. Если архитектура дополнительно требует, чтобы программа описывала, где (в каком функциональном устройстве) и когда (в каком такте) операция выполнялась, тогда оборудованию вообще не надо тратить времени на принятие этих решений, и выходная запись последовательности исполненных операций полностью совпадает с входной программой. Построенные к этому времени VLIW процессоры обладают именно такой архитектурой. Программа для VLIW процессора точно описывает, на каком функциональном устройстве и в каком такте операция должна быть запущена, так чтобы она была независима от всех запускаемых в данном такте операций и от других еще незаконченных операций. Для VLIW процессора важно ввести различие между командой и операцией. Операция есть единица вычислений (сложение, выборка из памяти, переход) для последовательной машины. VLIW команда (сверхдлинная команда) есть ряд операций, которые предполагается запустить одновременно. Задачей компилятора является определение того, какие операции должны входить в команду. Этот процесс называется планированием. Все допустимые операции упаковываются в единую команду. Порядок операций внутри команды задает устройства, на которых каждая операция должна выполняться. Первым примером такой архитектуры является архитектура микропроцессора компании Intel под названием Itanium (ранее Merced), разработанная в соответствии с концепцией IA-64 (Intel Architecture для 64 разрядов) и структура СДК микропроцессора С6 компании Texas Instruments
ЛЕКЦИЯ 9. VLIW. Архитектура процессора С6 (Texas Instruments). Особенностью процес сора является наличие двух практически идентичных вычислительных блоков, которые могут работать параллельно и обмениваться данными. Каждый блок содержит четыре фунциональных устройства (ФУ), которые также могут работать параллельно. На рисунке представлена структура процессора. Блоки выборки программ, диспетчирования и декодирования команд могут каждый такт доставлять функциональным блокам до восьми 32-разрядных команд. Обработка команд производится в в путях А и В, каждый из которых содержит 4 функциональных устройства (L, S, M, и D) и 16 32-разрядных регистра общего назначения. Каждое ФУ одного пути почти идентично соответствующему ФУ другого пути.
Каждое ФУ прямо обращается к регистровому файлу внутри своего пути, однако существуют дополнительные связи, позволяющие ФУ одного пути получать доступ к данным другого пути. Функциональные устройства описаны в таблице:
За один такт из памяти всегда извлекается 8 команд. Они составляют пакет выборки длиною 256 разрядов. В нем содержится 8 32-разрядных команд. Выполнение отдельной команды частично управляется р- разрядом, распо ложенным в этой команде. р − разряды сканируюся слева направо (к более старшим адресам команд в пакете). Если в команде i р -разряд равен 1, то i+ 1 команда может выполняться параллельно с i -ой. В противном случае команда i+ 1 должна выполняться в следующем цикле, то есть после цикла, в котором выполнялась команда i. Все команды, которые будут выполниться в одном цик- ле, образуют исполнительный пакет. Пакет выборки и исполнительный пакет это различные объекты. Исполнительный пакет может содержать до 8 команд. Каждая команда этого пакета должна использовать отдельное функциональное устройство. Исполнительный пакет не может пересекать границу 8 слов. Следовательно, последний р -разряд в пакете всегда устанавливается в 0 и каждый пакет выборки запускает новый исполнительный пакет. Имеется три типа пакетов выборки: полностью последовательные, полностью параллельные, и смешанные. В полно стью последовательных пакетах р- разряды всех команд установлены в 0, следо- вательно, все команды выполняются строго последовательно. В полностью па- раллельных пакетах р -разряды всех команд установлены в 1 и все команды вы- полняются параллельно. Пример смешанного пакета выборки из восьми 32- разрядных команд приведен на рисунке.
Состав исполнительных пакетов для этой команды:
Технология MMX. В 1997 году компания Intel выпустила первый процессор с архитектурой SIMD с названием Pentium MMX (MultiMedia eXtension), который реализует частный случай векторной абработки. При разработке МMХ специалистами Intel как в области архитектуры, так и в области программного обеспечения был обследован большой объем приложений различного назначения: графика, полноэкранное видео, синтез музыки, компрессия и распознавание речи, обработка образов, сигналов, игры, учебные приложения. Анализ участков с большим объемом вычислений показал, что все приложения имеют следующие общие свойства, определившие выбор системы команд и структуры данных: • небольшая разрядность целочисленных данных (например, 8-разрядные пикселы для графики или 16-разрядное представление речевых сигналов); • небольшая длина циклов, но большое число их повторений; • большой объем вычислений и значительный удельный вес операций умножения и накопления; • существенный параллелизм операций в программах. Это и определило новую структуру данных и расширение системы команд. Технология ММХ выполняет обработку параллельных данных по методу SIMD. Для этого используются четыре новых типа данных, 57 новых команд и восемь 64-разрядных ММХ-регистров. Метод SIMD позволяет по одной команде обрабатывать несколько пар операндов (векторная обработка). Основой новых типов данных является 64- разрядный формат, в котором размещаются следующие четыре типа операндов: • упакованный байт (Packed Byte) − восемь байтов, размещенных в одном 64- разрядном формате; • упакованное слово (Packed Word) − четыре 16-разрядных слова в 64- разрядном формате; • упакованное двойное слово (Packed Doubleword) − два 32-разрядных двойных слова в 64-разрядном формате; • учетверенное слово (Quadword) − 64-разрядная единица данных. Совместимость ММХ с операционными системами и приложениями обеспечивается благодаря тому, что в качестве регистров ММХ используются 8 регистров блока плавающей точки архитектуры Intel. Это означает, что операци онная система использует стандартные механизмы плавающей точки также и для сохранения и восстановления ММХ кода. Доступ к регистрам осуществля- ется по именам MM0-MM7. MMX команды обеспечивают выполнение двух новых принципов: операции над упакованными данными и арифметику насыщения. Арифметику насыщения легче всего определить, сравнивая с режимом циклического возврата. В режиме циклического возврата результат в случае переполнения или потери значимости обрезается. Таким образом перенос игнорируется. В режиме насыщения, результат при переполнении или потери значимо- сти, ограничивается. Результат, который превышает максимальное значение типа данных, обрезается до максимального значения типа. В случае же, если результат меньше минимального значения, то он обрезается до минимума. Это является полезным при проведении многих операций, например, операций с цветом. Когда результат превышает предел для знаковых чисел, он округляется до 0x7F (0xFF для беззнаковых). Если значение меньше нижнего предела, оно округляется до 0x80 для знаковых чисел(0x00 для беззнаковых). Для примера с цветоделением это означает, что цвет останется чисто черным или чисто белым и удается избежать негативной инверсии Если команда оперирует несколькими типами данных − байтами (В), словами (W), двойными словами (DW) или учетверенными словами (QW), то конкретный тип данных указан в скобках. Например, базовая мнемоника PADD (упакованное сложение) имеет следующие вариации: PADDB, PADDW и PADDD. Все команды MMX оперируют над двумя операндами: операнд-источник и операнд приемник. В обозначених команды правый операнд является источником, а левый – приемником. Операнд-источник для всех команд MMX (кроме команд пересылок) может располагаться либо в памяти либо в регистре MMX. Операнд-приемник будет располагаться в регистре MMX. Для команд пересылок операндами могут также выступать целочисленные РОН или ячейки памяти. Все 57 ММХ-команд разделенны на следующие классы: арифметические, сравнения, преобразования, логические, сдвига, пересылки и смены состояний. Приведем несколько примеров, иллюстрирующих выполнение команд ММХ. В этих примерах используются 16-разрядные данные, хотя есть и моди- фикации для 8- или 32-разрядных операндов. Пример 1. Пример представляет упакованное сложение слов без переноса. По этой команде выполняется одновременное и независимое сложение четырех пар 16-разрядных операндов. На рисунке самый правый результат превышает значение, которое можно представить в 16-разрядном формате. FFFFh + 8000h дали бы 17-разрядный результат, но 17-ый разряд теряется, поэтому результат будет 7FFFh.
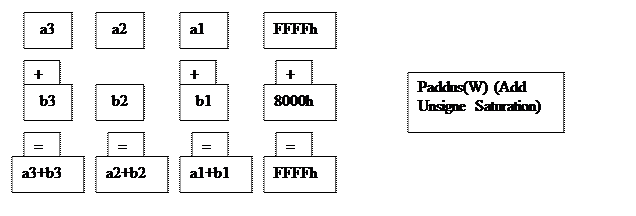
Пример 2. Этот пример иллюстрирует сложение слов с беззнаковым насыщением. Самая правая операция дает результат, который не укладывается в 16 разрядов, поэтому имеет место насыщение. Это означает, что если сложение дает в результате переполнение или вычитание выражается в исчезновении данных, то в качестве результата используется наибольшее или наименьшее значение, допускаемое 16-разрядным форматом. Для беззнакового представле- ния наибольшее и наименьшее значение соответственно будут FFFFh и 0х0000, а для знакового представления — 7FFFh и 0х8000. Это важно для обработки пикселов, где потеря переноса заставляла бы черный пиксел внезапно превра- щаться в белый, например, при выполнении цикла заливки по методу Гуро в 3D-графике. Особой здесь является команда PADDUS [W] − упакованное сло- жение слов беззнаковое с насыщением. Число FFFFh, обрабатываемое как без- знаковое (десятичное значение 65535), добавляется к 0х0000 беззнаковому (де- сятичное 32768) и результат насыщения до FFFFh − наибольшего представимо- го в 16-разрядной сетке числа.
ЛЕКЦИЯ 10.
Пример 3. Этот пример представляет ключевую команду умножения с накоплением, которая является базовой для многих алгоритмов цифровой обра- ботки сигналов: суммирования парных произведений, умножения матриц, бы- строго преобразования Фурье и т.д. Эта команда − упакованное умножение со сложением PMADD. Команда PMADD использует в качестве операндов 16-разрядные числа и вырабатывает 32-разрядный результат. Производится умножение четырех пар чисел и получаются четыре 32-разрядных результата, которые затем попарно складываются, вырабатывая два 32-разрядных числа. Этим и оканчивается вы- полнение PMADD. Чтобы завершить операцию умножения с накоплением, результаты PMADD следует прибавить к данным в регистре, который используется в качестве аккумулятора. Для этой команды не используется никаких новых флагов условий, кроме того, она не воздействует ни на какие флаги, имеющиеся в архитектуре процессоров Intel.
Pmadd (Packed Multiply Add)
Пример 4. Следующий пример иллюстрирует операцию параллельного сравнения. Сравниваются четыре пары 16-разрядных слов, и для каждой пары вырабатывается признак “истина” (FFFFh) или “ложь” (0000h). Результат сравнения может быть использован как маска, чтобы выбрать элементы из входного набора данных при помощи логических операций, что исключает необходимость использования ветвления или ряда команд ветвления. Способность совершать условные пересылки вместо использования команд ветвления является важным усовершенствованием в перспективных процессорах, которые имеют длинные конвейеры и используют прогнозирование ветвлений.
Greate Then Ветвление, основанное на результате сравнения входных данных, обыч- но трудно предсказать, так как входные данные во многих случаях изменяются случайным образом. Поэтому исключение операций ветвления совместно с па- раллелизмом ММХ-команд является существенной особенностью технологии ММХ. Пример 5. Пример иллюстрирует работу команды упаковки. Она принимает четыре 32-разрядных значения и упаковывает их в четыре 16-разрядных значения, выполняя операцию насыщения, если какое-либо 32-разрядное входное значение не укладывается в 16-разрядный формат результата. Имеются также команды, которые выполняют противоположное действие — распаковку, например, то есть преобразуют упакованные байты в упакован- ные слова.

Эти команды особенно важны, когда алгоритму нужна более высокая точ- ность промежуточных вычислений, как, например, в цифровых фильтрах при распознавании образов. Такой фильтр обычно требует ряда умножений коэффициентов на соответ ствующие значения пикселов с последующей аккумуляцией полученных значе- ний. Эти операции нуждаются в большей точности, чем та, которую может обеспечить 8-разрядный формат для пикселов. Решением проблемы точности является распаковка 8-разрядных пикселов в 16-разрядные слова, выполнение расчетов в 16-разрядной сетке и затем обратная упаковка в 8-разрядный формат для пикселов перед записью в память или дальнейшими вычислениями.
Пример 6. Пример на умножение матриц (Matrix Multiply) связан с 3D- играми, количество которых увеличивается каждый день. Типичная операция над 3D-объектами заключается в многократном умножении матрицы размером 4х4 на четырехэлементный вектор. Вектор имеет значения X, Y, Z и информа- цию о коррекции перспективы для каждого пиксела. Матрица 4х4 используется для выполнения операций вращения (rotate), масштабирования (scale), переноса (translate) и коррекции информации о перспективе для каждого пиксела. Эта матрица 4х4 используется для многих векторов.
Приложения, которые работают с 16-разрядным представлением исходных данных, могут широко использовать команду PMADD. Для одной строки матрицы нужна одна команда PMADD, для четырех строк − четыре команды. Более подробный подсчет показывает, что умножение матриц 4х4 требует 28 команд для технологии ММХ, а без нее − 72 команды
Расширение SSE Технология MMX имеет ряд расширений, называемых SSE (Streaming SIMD Extensions). SSE - это расширение инструкций процессора для потоковой обработки в режиме SIMD (Single Instruction Multiple Data), т.е. когда требуется применять однотипные операции к потоку данных. Технология SSE позволила преодолеть проблемы MMX - при использовании MMX невозможно было од- новременно использовать инструкции сопроцессора, так как его регистры за- действовались для MMX и работы с вещественными числами. В общем случае, к архитектуре процессора добавляется ряд инструкций и несколько 128-битных регистров с различной интерперетацией. Изначально каждый регистр трактуется как два значения с плавающей точкой двойной точ- ности (2*64-бит). Однако, операции могут применяться практически ко всем типам, "помещающимся" в 16 байт. Это означает, например, что появляется возможность одновременно сложить или умножить с помощью всего одной ин- струкции два операнда из четырех чисел с плавающей точностью одинарной точности, двух - с двойной, двух 64-битных целочисленных, 16 8-битных целых и т.п. Существуют следующие расширения: SSE, SSE2, SSE3 и SSE4, о которых имеется обширная информация в интеренете.
ЛЕКЦИЯ 11. КРУПНОЗЕРНИСТЫЙ ПАРАЛЛЕЛИЗМ Крупнозернистый параллелизм обеспечивается за счет параллелизма независимых программных ветвей, подпрограмм, потоков (нитей) внутри программ, служебных программ и реализуется процессорами или ядрами многоядерных процессоров.
Классификация Флинна Существует много классификаций для крупноформатного параллелизма. Одна из них – классификация Флинна, предложенная в 1970 году, получила большое распространение. Флинн ввел два рабочих понятия: поток команд и поток данных. Под потоком команд упрощенно понимают последовательность выполняемых команд одной программы. Поток данных – это последователь- ность данных, обрабатывемых одним потоком команд. На этой основе Флинн построил свою классификацию параллельных ЭВМ с крупнозернистым парал- лелизмом: 1) ОКОД (одиночный поток команд − одиночный поток данных) или SISD (Single Instruction − Single Data). Это обычные последовательные ЭВМ, в которых выполняется одна программа. Здесь может использоваться конвейерная обработка в единственном потоке команд. 2) ОКМД (одиночный поток команд − множественный поток данных) или SIMD (Single Instruction – Multiple Data). В таких ЭВМ выполняется единственная программа, но каждая ее команда обрабатывает много чисел. Это соответствует векторной форме параллелизма, реализованноq в машинах CRAY. 3) МКОД (множественный поток команд − одиночный поток данных) или MISD (Multiple Instruction − Single Data). Здесь несколько команд одновременно работает с одним элементом данных. Этот класс не нашел применения на практике. 4) МКМД и (множественный поток команд − множественный поток данных) или MIMD (Multiple Instruction − Multiple Data). В таких ЭВМ одновре- менно и независимо друг от друга выполняется несколько программных ветвей, в определенные промежутки времени обменивающихся данными. Такие систе- мы обычно называют многопроцессорными. Этот класс разделяется на два больших подкласса: 1. С общей для всех процессоров памятью. Это упрощает оборудование, но количество процессоров ограничено пропускной способностью памяти. 2. С индивидуальной памятью для каждого процессора. Число процессоров не ограничивается, но межпроцессорный обмен данными снижает потен- циальное ускорение. С течение времени появилась разновидность этой технологии, называемая SPMD (Single Program − Multiple Data), которая используется в многопроцессорных системах с обшей памятью SMP (Symmetric Multiprocessing). Таким образом, далее будут рассмотрены только два класса параллельных ЭВМ: SIMD (SPMD) и MIMD. SIMD –ЭВМ в свою очередь делятся на два подкласса: векторно-конвейерные ЭВМ и процессорные матрицы.
Арифметические конвейеры Векторно-конвейерная ЭВМ CRAY относится к классу ОКМД ЭВМ. Но ее отличием от других ЭВМ этого класса является наличие развитой систе- мы арифметических конвейеров, которые и обеспечивают ее быстродействие. На рисунке представлен принцип постороения системы с арифметическим конвейером. Обычно в конвейере команд самым медленным звеном («узким» местом трубопровода) является этап исполнения арифметических операций EXE. Существуют способы разбить этот этап на несколько более мелких арифметических этапов, снабдив каждый из них аппаратурой. Это и будет ариф-метический конвейер в составе конвейера команд. Теперь скорость всего конвейера определяется тактом арифметического конвейера Δак.
Ниже приведены некоторые способы построения арифметических конвейеров. На рисунке 1 представлена схема конвейера для сложения потока чисел с плавающей запятой, а на рисунке 2 – для умножения чисел. Такие конвейеры можно построить практически для всех команд.
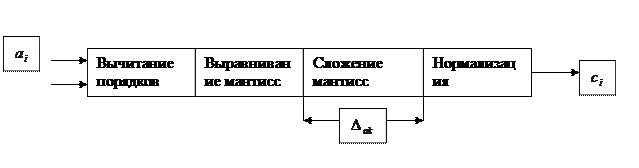

Впервые арифметические конвейеры были использованы для целей обра- ботки числовых векторов в ЭВМ STAR-100, запущенной в США в 1973 г., а за- тем на этом принципе была построена знаменитая ЭВМ CRAY-1, которая стала родоначальником множества векторно-конвейерных ЭВМ различных компаний и разного быстродействия. Однако, принцип работы всех этих машин вклады- вается в организацию CRAY-1, как “скрипка в футляр”. ОКМД ЭВМ CRAY обладает рядом особенностей: • Класс – ОКМД, система с общей памятью. Все АЛУ – конвейерные. • Большой объем векторных регистров (сотни в новых машинах) снижает нагрузку на общую память. • Выполнение команд в скалярном процессоре управляется потоком дан- ных. • Со временем эта архитектура была реализована в виде одного микропро цессора в состве многопроцессорной ЭВМ.Такие ЭВМ занимают по бы- стродействию первые места в списке TOP 500. ЭВМ CRAY состоит из скалярного и векторного процессоров (на рисунке). Скалярный процессор выбирает из памяти и выполняет скалярные и векторные команды, но скалярные – целиком, а арифметическую часть векторных команд передает в векторный процессор.
Скалярный процессор. Ускорение векторных вычислений согласно закону Амдала очень чуствительно к времени выполнения скалярных операций. Это время можно уменьшить двояко: • Уменьшить количество скалярных операций, что не всегда возможно • Увеличить быстродействие скалярного процессора. Именно это и сделано в CRAY.
ЛЕКЦИЯ 12.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 297; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.22.202 (0.015 с.) |







 - Rotate & Scale
- Rotate & Scale  - Translate
- Translate  - Perspective
- Perspective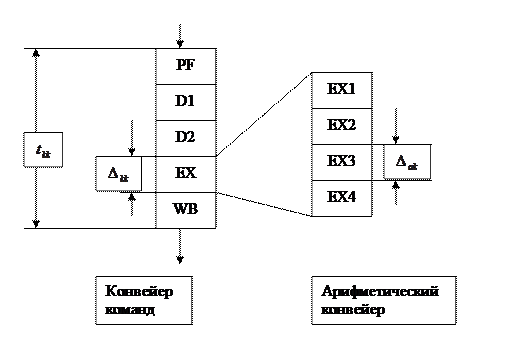
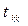 - полное время выполнения команды
- полное время выполнения команды - время такта конвейера команд
- время такта конвейера команд - время такта арифметического конвейера
- время такта арифметического конвейера






