Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Порівняльний опис методів отримання векторної інформаціїСодержание книги
Поиск на нашем сайте
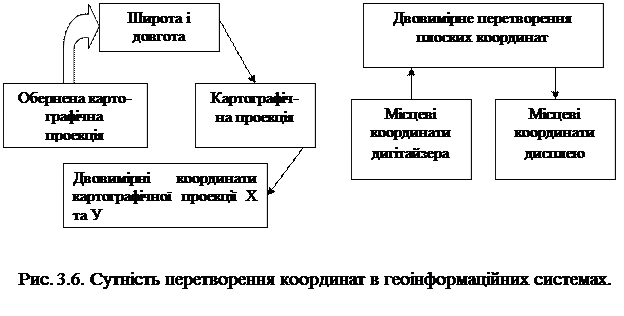
Розглянемо спочатку особливості вводу картографічної інформації в векторному форматі. Нами попередньо були розглянуті існуючі способи цифрування та їх характеристики. Тому необхідно розглянути загальну особливість процесу цифрування карти. Будь-яка карта створена в картографічній проекції та системі координат. При цифруванні карти ми переходимо від проекції карти до набору плоских прямокутних координат в системі координат дигітайзера. Перед тим, як це зробити ми повинні повідомити програмі всі вихідні дані про цю проекцію. Це дозволить перетворити карту до її вихідної картографічної проекції після вводу. Для реалізації цього перетворення геоінформаційна система виконує три основні перетворення: перенесення, поворот, масштабування. Розглянемо більш докладно їх сутність. Перенесення – це переміщення частини, або всього географічного об’єкту в інше місце на географічній площині. Воно виконується додаванням певних величин до координат Х та У об’єкту: Х1 = Х + Тх; (3.1) У1 = У + Ту. Масштабування виконується для створення карти в різних масштабах. Воно здійснюється множенням усіх координат Х та У на масштабний коефіцієнт: Х1 = Х ·Sх; (3.2) У1 = У·Sу. Поворот. Він виконується з використанням законів тригонометрії. Його метою є переорієнтація об’єкту в координатному просторі: Х1 = Х cos θ + Y sin θ; (3.3) Y1 = -Х sin θ + Y sin θ, де θ – кут повороту. За допомогою цих трьох операцій геоінформаційна система виконує необхідні перетворення. Їх сутність графічно показана на рис. 3.6.
Розглянувши сутність перетворення координат в геоінформаційній системі тепер розглянемо загальну послідовність цифрування вихідного картографічного матеріалу. Цей процес складається з: підготовки карти до цифрування; виділення об’єктів і шарів тематичної інформації; складання відомостей кодування на об’єкти (шари); безпосереднього цифрування об’єктів (шарів); занесення атрибутивної інформації у відповідні файли. Починати процес цифрування необхідно з повідомлення програмі цифрування відомостей про основу карти: вид проекції, система координат, масштаб карти тощо. Далі необхідно виділити об’єкти, які належать до одного шару (гідрографія, дорожня мережа тощо), або до одного типу (лінії, точки, полігони). Кожному об’єкту повинен бути присвоєний порядковий номер, який визначає послідовність цифрування і за яким буде додана атрибутивна інформація. Перед початком цифрування аркуш карти закріплюють на планшеті дигітайзера і визначають точки прив’язки, або реєстраційні точки. Вони потрібні для визначення області карти та переобчислення координат з системи координат карти в систему координат дигітайзера і зворотно. Більшість геоінформаційних систем має можливості для акуратного цифрування. До цих можливостей відносяться: замикання ліній, прив’язка до кінця, або до початку лінії, прив’язка до будь-якої точки визначеної лінії, тощо. Після закінчення підготовчих робіт починається процес цифрування. Він полягає в обведенні контуру, що цифрується, курсором з послідовним натисканням відповідних клавіш „миши”. При цьому на моніторі з’являється зображення об’єкту, який було обведено. Помилки цифрування усуваються, як в процесі роботи, так і після його закінчення в процесі редагування. Атрибутивні дані в векторних геоінформаційних системах вводяться найчастіше за допомогою клавіатури комп’ютера, або безпосередньо під час цифрування. Після того, як графічна інформація введена, перевірена, відредагована, вона може зберігатися, оновлюватися та приймати участь у моделюванні. Введення растрових даних виконується за іншою методикою, ніж введення векторних даних. Для вводу растрових даних використовують сканери. Результати сканування залежать в першу чергу від дозвільної спроможності сканеру. Дані дистанційного зондування Землі дуже корисні для введення в растрові ГІС. Геоінформаційні системи і різні програми обробки зображень повинні розглядатися, як взаємодоповнюючи технології. Матеріали ДДЗ дозволяють виконувати швидке оновлення баз даних і виявлення змін на великих територіях. В якості вихідних даних для вводу використовують безпосередньо матеріали дистанційного зондування, так і результати їх подальшої обробки, в першу чергу, ортофотоплани (як в цифровій так і в аналоговій формах). Матеріали ДДЗ вводяться в ГІС у двох формах: цифровим способом оброблені знімки і класифіковані зображення об’єктів. Введення даних з зовнішніх баз даних. Наявність вже існуючих баз даних підвищує ефективність створення нової геоінформаційної системи, так як це скорочує час і витрати на розробку необхідної бази даних. Сьогодні існує багато загальнодоступних баз цифрових моделей місцевості, цифрових карт місцевості, цифрових ортофотознімків, тощо. Але наявність вже створених баз даних призводить до виникнення ряду проблем під час вводу цих даних в ГІС. Перша проблема – це тип і формат носіїв інформації. Вони повинні бути в форматі, який геоінформаційна система може зчитати та записати. Друга проблема – це якість даних. Дані, незалежно від їх джерел походження, можуть містити помилки, одні з яких усуваються, а інші – ні. Тобто, необхідно знати, яка процедура контролю якості була застосована при створенні відповідної бази даних. Третя проблема. Будь-якій базі даних потрібна інформація про її зміст – метадані. Існує дві форми метаданих: активні і пасивні словники даних. Пасивні словники даних складаються з: масштабу, дозвільної спроможності, назв полів в БД, використовуємих кодів та їх значень. Метадані повинні дати користувачу достатньо подробиць для впевненості, що будь-який аналіз, який базується на цих даних, буде коректним. Активні словники даних працюють з базами даних, виконуючи перевірки коректності запитів і даних, що вводяться під час функціонування системи. Наприклад, якщо СУБД векторної геоінформаційної системи налаштована тільки на чотиризначні коди об’єктів, то активний словник даних може перевірити кожну операцію для гарантування, що це чотиризначне обмеження всюди виконано. Такі перевірки дуже корисні для забезпечення функціонування системи і запобігання помилкових результатів по причині некоректних вхідних даних. І ще, крім технічних проблем, необхідно враховувати, що використання зовнішніх баз даних пов’язано з рядом фундаментальних законодавчих та організаційних проблем, проблемою доступу до даних та ступенем їх секретності.
Робота з базами даних. Вихідна просторова інформація після її вводу в геоінформаційну систему за допомогою підсистеми введення даних обробляється підсистемою зберігання і пошуку даних – за її допомогою формуються бази даних. В базі даних ГІС інформація, як ми вже розглянули раніше, зберігається у векторному або растровому форматі (це залежить від характеристики геоінформаційної системи). База даних – це сукупність взаємопов’язаних, зберігаючихся разом даних при наявності такої мінімальної надлишковості, що припускає їх використання оптимальним чином для одного чи кількох об’єктів. При чому дані в базі даних ГІС записані таким чином, що вони є незалежні від програм, що використовують ці дані. Для додавання нових або модифікації існуючих даних, а також пошуку даних в БД застосовується спільний спосіб управління. Крім того дані структуровані таким чином, щоб була можливість подальшого збільшення додатків, які використовують ці дані. Необхідно підкреслити, що усі операції з даними, які зберігаються у базі даних виконуються за допомогою системи управління базами даних. Системи управління призначені для маніпулювання текстовими, графічними і цифровими даними за допомогою ресурсів ПЕОМ. Вони виконують функції формування наборів даних (файлів), пошуку, сортування, коректування для усіх перелічених типів даних. Основні принципи побудови СУБД базуються на тому, що для роботи з текстовими, числовими і графічними даними достатньо реалізувати обмежену кількість функцій, що використовуються, та визначити послідовність їх виконання. Відповідно до трьох типів баз даних, що були нами розглянуті раніше, існує і три основних типи СУБД: ієрархічні, мереживі, реляційні (табличні). До складу більшості систем управління базами даних входять три основні компоненти: командна мова, система інтерпретування або компілятор для обробки команд, інтерфейс користувача. Командна мова призначена для виконання необхідних операцій над даними. Вона дозволяє маніпулювати даними, створювати прикладні програми, оформляти на екрані монітору дані, друкувати необхідні форми вводу і виводу інформації, тощо. Можливості СУБД визначаються у значній мірі структурою і можливостями її командної мови. Така мова має наступні властивості і характеристики: - забезпечує високу продуктивність праці програміста; - має засоби опису як зберігання даних так і операцій над ними (пошук і модифікація даних); - має засоби роботи з текстовими, графічними і цифровими даними; - має засоби захисту бази даних; - має можливості визначення нестандартних форматів і структур; - має обчислювальні функції; - має засоби форматування екрану монітору і генератори відліків. - для роботи з таблицями є прості оператори типу: “створити”, “додати”, “модифікувати”, “знищити”, “вставити”, “знайти”. Для повсякденного використання команд, що постійно повторюються, вони можуть бути записані у файл, після чого усі визначаємі команди будуть виконуватися автоматично. Це суттєво підвищує надійність системи, оскільки користувачу не потрібно знати усі її засоби – більшу частину роботи він виконує за допомогою меню команд. Таким чином, командна мова системи управління базами даних надає користувачу наступні можливості: 1. Потужні засоби роботи з даними. Всі операції здійснюються тільки над даними, що визначив користувач. За рахунок цього, дані оновлюються в файлі одноразово. 2. Можливість виклику заздалегідь створених користувачем команд за допомогою меню. 3. Можливість використовувати власні критерії вибору і критерії, що автоматично визначаються ключами вибірки. 4. Наявності вбудованих генераторів масок, що дозволяє форматування екранів моніторів з визначенням індивідуальних заголовків. 5. Використання генераторів відліків, які працюють за схемою, що складена користувачем, у діалоговому режимі. Всі наведені можливості можна використовувати інтерактивно, або будуючи на їх базі окремі модулі для вирішення різних прикладних задач. В склад командної мови входить кілька груп операцій, які специфічні для кожної СУБД, та окрема група команд, яка складає ядро мови і є загальною. Це команди роботи з файлами даних, команди збереження даних, упорядкування записів даних, виводу даних на екран та на пристрої друку. В системі управління базами даних операції можна виконувати по одній, послідовно вводячи їх з клавіатури, або групами в автоматичному режимі. Операції мови СУБД записуються у вигляді тексту. Для перетворення текстової команди в код, що зрозумілий для ПЕОМ, використовуються спеціальні програми двох типів – інтерпретатори і компілятори. Способи якими вони обробляють текст, принципово різні. В першому випадку, використовується система інтерпретування, яка по черзі перетворює команди у виконуємий код, перед їх безпосереднім виконанням. В другому випадку, спочатку вся програма перетворюється (компілюється) в серію машинних команд і тільки після цього виконується. Компромісним рішенням є використання псевдокомпіляторів, які спочатку обробляють оператори вихідної програми, а потім їх виконують в режимі інтерпретації. СУБД з компіляторами орієнтовані на програмістів, що створюють складні прикладні системи. СУБД з інтерпретаторами орієнтовані на користувачів з початковим знанням програмування, так як працюють у режимі, що управляється за допомогою меню та у режимі вводу команд з клавіатури. До систем управління базами даних реляційного типу відносяться dBASE, Clipper, Foxbase, Paradox, тощо. На робочих станціях використовують СУБД типу ORACLE. На практиці у геоінформаційних системах використовують різні підходи до використання СУБД. Одні ГІС використовують власні вбудовані СУБД. Другі використовують готові СУБД (dBASE, Paradox тощо), треті використовують суміщений підхід – внутрішні СУБД, до тих пір поки обсяг баз не перевищує встановленої величини, та СУБД, що призначені для великих обсягів інформації (ORACLE), якщо інформації дуже багато. Без залежності від того, яка конкретна система управління базами даних використовується в ГІС, у системі повинні бути засоби, що дозволяють перевести дані з одного стандартного формату бази даних у інший та зчитувати інформацію з зовнішніх баз. До таких форматів належать: SQL, DBF, RDB, SYBASE, тощо. Розглянувши яким чином здійснюється управління базами даних, що створені, тепер розглянемо безпосередньо яким же чином здійснюється безпосередня робота з базами даних (їх редагування). Хоча деякі помилки інформації в базах даних обумовлені недоліками алгоритмів обчислення, помилок кодування програм, помилок округлення, все ж більшість помилок обумовлена неправильним вводом даних. Існує три типи помилок даних в базах даних геоінформаційних систем. Перший тип відноситься головним чином до векторних систем вводу даних і називається графічною помилкою. Такі помилки зустрічаються трьох основних типів: пропуск об’єкту, неправильне положення об’єкту (помилка положення), неправильний порядок об’єктів. Другий тип помилок – це помилки атрибутів. Вони зустрічаються, як в векторних так і в растрових системах з однаковою частотою. Частіше всього вони є помилками при вводі даних. В векторних системах помилки атрибутів включають використання неправильного коду для позначення атрибуту об’єкту, помилки запису однакових за вимогою, але різних за змістом і написом слів, що робить неможливим вибірку атрибуту. У випадку введення растру частіше всього вводять значення атрибутів, тому результатом набору неправильного коду, або його розміщення у неправильну чарунку растру є карта, що показує помилки в цих місцях. Такі неправильно розміщені атрибутивні дані створюють третій тип помилок, помилки узгодження графіки і атрибутів, які бувають і у векторних системах, коли правильні значення кодів атрибутів пов’язують з неправильними графічними об’єктами. З розглянутих трьох типів помилок баз даних ГІС найбільш трудно встановлюються останні два типи, що пов’язані з атрибутами об’єкту. Встановивши типи помилок, тепер більш докладно розглянемо, як виявляються та усуваються помилки різних типів даних в базах даних геоінформаційних систем.
|
||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 411; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.015 с.) |