
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Вопрос 26 Нормальная кривая как инструмент подбораСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Нормальное распределение, также называемое гауссовым распределением, гауссианой или распределением Гаусса — распределение вероятностей, которое задается функцией плотности распределения:
где параметр μ — среднее значение (математическое ожидание) случайной величины и указывает координату максимума кривой плотности распределения, а σ ² — дисперсия. Нормальное распределение играет важнейшую роль во многих областях знаний, особенно в статистической физике. Физическая величина, подверженная влиянию значительного числа независимых факторов, способных вносить с равной погрешностью положительные и отрицательные отклонения, вне зависимости от природы этих случайных факторов, часто подчиняется нормальному распределению, поэтому из всех распределений в природе чаще всего встречается нормальное (отсюда и произошло одно из названий этого распределения вероятностей). Нормальное распределение зависит от двух параметров — смещения и масштаба, то есть является с математической точки зрения не одним распределением, а целым их семейством. Значения параметров соответствуют значениям среднего (математического ожидания) и разброса (стандартного отклонения). Стандартным нормальным распределением называется нормальное распределение с математическим ожиданием 0 и стандартным отклонением 1. Свойства Если случайные величины Моделирование нормальных случайных величин Простейшие, но неточные методы моделирования основываются на центральной предельной теореме. Именно, если сложить много независимых одинаково распределённых величин с конечной дисперсией, то сумма будет распределена примерно нормально. Например, если сложить 12 независимых базовых случайных величин, получится грубое приближение стандартного нормального распределения. Тем не менее, с увеличением слагаемых распределение суммы стремится к нормальному. Использование точных методов предпочтительно, поскольку у них практически нет недостатков. В частности, преобразование Бокса — Мюллера является точным, быстрым и простым для реализации методом генерации. Центральная предельная теорема Нормальное распределение часто встречается в природе. Например, следующие случайные величины хорошо моделируются нормальным распределением: отклонение при стрельбе некоторые погрешности измерений (однако, многие погрешности приборов в технике имеют сильно не нормальные распределения) рост живых организмов Такое широкое распространение закона связано с тем, что он является предельным законом, к которому приближаются многие другие (например, биномиальный). Важно понимать, что использование гауссианы допустимо только при соблюдении следующих эмпирических условий: все факторы процесса известны (нет неизвестных или они несущественны), процесс немасштабируем (существуют верхние и нижние пределы), крайние события происходят не чаще, чем предсказывает правило 3-х сигм, и не имеют больших последствий. Таким образом, с помощью гауссианы некорректно моделировать социальные и экономические процессы. Однако хорошо поддаются моделированию большинство физических процессов. Центральная предельная теорема показывает, что в случае, когда результат измерения (наблюдения) складывается под действием многих независимых причин, причем каждая из них вносит лишь малый вклад, а совокупный итог определяется аддитивно, то есть путём сложения, то распределение результата измерения (наблюдения) близко к нормальному.
Вопрос 27 Статистическая гипотеза. Критерий хи-квадрат Критерий Определение Пусть дана случайная величина X. Гипотеза Для проверки гипотезы рассмотрим выборку, состоящую из n независимых наблюдений над с.в. X: Гипотеза Разделим [a,b] на k непересекающихся интервалов Пусть
Статистика:
Проверка гипотезы
Распределение хи-квадрат В зависимости от значения критерия
Пример 1 Проверим гипотезу
Т.о. при уровне значимости Сложная гипотеза Гипотеза
Пример 2 Задача о бомбардировках Лондона [Лагутин, Т2]. Задача возникла в связи с бомбардировками Лондона во время Второй мировой войны. Для улучшения организации оборонительных мероприятий, необходимо было понять цель противника. Для этого территорию города условно разделили сеткой из 24-ёх горизонтальных и 24-ёх вертикальных линий на 576 равных участков. В течении некторого времени в центре организации обороны города собиралась информация о количестве попаданий снарядов в каждый из участков. В итоге были получены следующие данные:
Гипотеза Закон редких событий (распределение Пуассона)
Тогда при уровне значимости Объединим события (4,5,6,7) с малой частотой попаданий в одно, тогда имеем:
Проблемы Критерий
Вопрос 28 t-критерий Стьюдента t-критерий Стьюдента — общее название для класса методов статистической проверки гипотез (статистических критериев), основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках. t -статистика строится обычно по следующему общему принципу: в числителе случайная величина с нулевым математическим ожиданием (при выполнении нулевой гипотезы), а в знаменателе — выборочное стандартное отклонение этой случайной величины, получаемое как квадратный корень из несмещенной оценки дисперсии. История Данный критерий был разработан Уильямом Госсетом для оценки качества пива в компании Гиннесс. В связи с обязательствами перед компанией по неразглашению коммерческой тайны(руководство Гиннесса считало таковой использование статистического аппарата в своей работе), статья Госсета вышла в 1908 году в журнале «Биометрика» под псевдонимом «Student» (Студент). Требования к данным Для применения данного критерия необходимо, чтобы исходные данные имели нормальное распределение. В случае применения двухвыборочного критерия для независимых выборок также необходимо соблюдение условия равенства дисперсий. Существуют, однако, альтернативы критерию Стьюдента для ситуации с неравными дисперсиями. Требование нормальности распределения данных является необходимым для точного Одновыборочный t-критерий Применяется для проверки нулевой гипотезы Очевидно, при выполнении нулевой гипотезы
При нулевой гипотезе распределение этой статистики Двухвыборочный t-критерий для независимых выборок Пусть имеются две независимые выборки объемами Рассмотрим разность выборочных средних
Эта статистика при справедливости нулевой гипотезы имеет распределение Случай одинаковой дисперсии В случае, если дисперсии выборок предполагаются одинаковыми, то
Эта статистика имеет распределение Двухвыборочный t-критерий для зависимых выборок Для вычисления эмпирического значения t-критерия в ситуации проверки гипотезы о различиях между двумя зависимыми выборками (например, двумя пробами одного и того же теста с временным интервалом) применяется следующая формула:
где Эта статистика имеет распределение Проверка линейного ограничения на параметры линейной регрессии С помощью t-теста можно также проверить произвольное (одно) линейное ограничение на параметры линейной регрессии, оцененной обычным методом наименьших квадратов. Пусть необходимо проверить гипотезу Кроме того ,
Эта статистика при выполнении нулевой гипотезы имеет распределение Проверка гипотез о коэффициенте линейной регрессии Частным случаем линейного ограничения является проверка гипотезы о равенстве коэффициента
где При справедливости нулевой гипотезы распределение этой статистики — Замечание Одновыборочный тест для математических ожиданий можно свести к проверке линейного ограничения на параметры линейной регрессии. В одновыборочном тесте это «регрессия» на константу. Поэтому Аналогично можно показать, что двухвыборочный тест при равенстве дисперсий выборок также сводится к проверке линейных ограничений. В двухвыборочном тесте это «регрессия» на константу и фиктивную переменную, идентифицирующую подвыборку в зависимости от значения (0 или 1): Также к проверке линейного ограничения можно свести и в случае разных дисперсий. В этом случае дисперсия ошибок модели принимает два значения. Исходя из этого можно также получить t-статистику, аналогичную приведенной для двухвыборочного теста. Непараметрические аналоги Аналогом двухвыборочного критерия для независимых выборок является U-критерий Манна–Уитни. Для ситуации с зависимыми выборками аналогами являются критерий знаков и T-критерий Вилкоксона Билет 29 Коэффициент корреляции Корреля́ция (от лат. correlatio), (корреляционная зависимость) — статистическая взаимосвязь двух или нескольких случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом изменения значений одной или нескольких из этих величин сопутствуют систематическому изменению значений другой или других величин.Математической мерой корреляции двух случайных величин служит корреляционное отношение Впервые в научный оборот термин «корреляция» ввёл французский палеонтолог Жорж Кювье в XVIII веке. Он разработал «закон корреляции» частей и органов живых существ, с помощью которого можно восстановить облик ископаемого животного, имея в распоряжении лишь часть его останков. В статистике слово «корреляция» первым стал использовать английский биолог и статистик Фрэнсис Гальтон в конце XIX века. Некоторые виды коэффициентов корреляции могут быть положительными или отрицательными. В первом случае предполагается, что мы можем определить только наличие или отсутствие связи, а во втором — также и её направление. Если предполагается, что на значениях переменных задано отношение строгого порядка, то отрицательная корреляция — корреляция, при которой увеличение одной переменной связано с уменьшением другой. При этом коэффициент корреляции будет отрицательным. Положительная корреляция в таких условиях — это такая связь, при которой увеличение одной переменной связано с увеличением другой переменной. Возможна также ситуация отсутствия статистической взаимосвязи — например, для независимых случайных величин. Корреляция и взаимосвязь величин Значительная корреляция между двумя случайными величинами всегда является свидетельством существования некоторой статистической связи в данной выборке, но эта связь не обязательно должна наблюдаться для другой выборки и иметь причинно-следственный характер. Часто заманчивая простота корреляционного исследования подталкивает исследователя делать ложные интуитивные выводы о наличии причинно-следственной связи между парами признаков, в то время как коэффициенты корреляции устанавливают лишь статистические взаимосвязи. Например, рассматривая пожары в конкретном городе, можно выявить весьма высокую корреляцию между ущербом, который нанес пожар, и количеством пожарных, участвовавших в ликвидации пожара, причём эта корреляция будет положительной. Из этого, однако, не следует вывод «бо́льшее количество пожарных приводит к бо́льшему ущербу», и тем более не имеет смысла попытка минимизировать ущерб от пожаров путем ликвидации пожарных бригад.[5]В то же время, отсутствие корреляции между двумя величинами ещё не значит, что между ними нет никакой связи. Показатели корреляции. Параметрические показатели корреляции. Ковариация Основные статьи: Ковариация, Неравенство Коши — Буняковского Важной характеристикой совместного распределения двух случайных величин является ковариация (или корреляционный момент). Ковариация являетcя совместным центральным моментом второго порядка. Ковариация определяется как математическое ожидание произведения отклонений случайных величин:
где Свойства ковариации: Ковариация двух независимых случайных величин Доказательство Абсолютная величина ковариации двух случайных величин Линейный коэффициент корреляции Для устранения недостатка ковариации был введён линейный коэффициент корреляции (или коэффициент корреляции Пирсона), который разработали Карл Пирсон, Фрэнсис Эджуорт и Рафаэль Уэлдон (англ.) русск. в 90-х годах XIX века. Коэффициент корреляции рассчитывается по формуле[10][8]:
где Коэффициент корреляции изменяется в пределах от минус единицы до плюс единицы. Доказательство Линейный коэффициент корреляции связан с коэффициентом регрессии в виде следующей зависимости: Для графического представления подобной связи можно использовать прямоугольную систему координат с осями, которые соответствуют обеим переменным. Каждая пара значений маркируется при помощи определенного символа. Такой график называется «диаграммой рассеяния». Метод вычисления коэффициента корреляции зависит от вида шкалы, к которой относятся переменные. Так, для измерения переменных с интервальной и количественной шкалами необходимо использовать коэффициент корреляции Пирсона (корреляция моментов произведений). Если по меньшей мере одна из двух переменных имеет порядковую шкалу, либо не является нормально распределённой, необходимо использовать ранговую корреляцию Спирмена или Непараметрические показатели корреляции. Коэффициент ранговой корреляции Кендалла Применяется для выявления взаимосвязи между количественными или качественными показателями, если их можно ранжировать. Значения показателя X выставляют в порядке возрастания и присваивают им ранги. Ранжируют значения показателя Y и рассчитывают коэффициент корреляции Кендалла:
где
Если исследуемые данные повторяются (имеют одинаковые ранги), то в расчетах используется скорректированный коэффициент корреляции Кендалла:
Коэффициент ранговой корреляции Спирмена Каждому показателю X и Y присваивается ранг. На основе полученных рангов рассчитываются их разности
Коэффициент корреляции знаков Фехнера Подсчитывается количество совпадений и несовпадений знаков отклонений значений показателей от их среднего значения.
C — число пар, у которых знаки отклонений значений от их средних совпадают. H — число пар, у которых знаки отклонений значений от их средних не совпадают. Коэффициент множественной ранговой корреляции (конкордации)
Значимость:
В случае наличия связанных рангов:
Свойства коэффициента корреляции Неравенство Коши — Буняковского: если принять в качестве скалярного произведения двух случайных величин ковариацию
Коэффициент корреляции равен
где
Доказательство Если Корреляционный анализ Корреляционный анализ — метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными. Корреляционный анализ тесно связан с регрессионным анализом (также часто встречается термин «корреляционно-регрессионный анализ», который является более общим статистическим понятием), с его помощью определяют необходимость включения тех или иных факторов в уравнение множественной регрессии, а также оценивают полученное уравнение регрессии на соответствие выявленным связям (используякоэффициент детерминации). Ограничения корреляционного анализа
Множество корреляционных полей. Распределения значений (x, y) с соответствующими коэффициентами корреляций для каждого из них. Коэффициент корреляции отражает «зашумлённость» линейной зависимости (верхняя строка), но не описывает наклон линейной зависимости (средняя строка), и совсем не подходит для описания сложных, нелинейных зависимостей (нижняя строка). Для распределения, показанного в центре рисунка, коэффициент корреляции не определен, так как дисперсия y равна нулю. Применение возможно при наличии достаточного количества наблюдений для изучения. На практике считается, что число наблюдений должно быть не менее, чем в 5-6 раз превышать число факторов (также встречается рекомендация использовать пропорцию не менее, чем в 10 раз превышающую количество факторов). В случае, если число наблюдений превышает количество факторов в десятки раз, в действие вступает закон больших чисел, который обеспечивает взаимопогашение случайных колебаний. Необходимо, чтобы совокупность значений всех факторных и результативного признаков подчинялась многомерному нормальному распределению. В случае, если объём совокупности недостаточен для проведения формального тестирования на нормальность распределения, то закон распределения определяется визуально на основе корреляционного поля. Если в расположении точек на этом поле наблюдается линейная тенденция, то можно предположить, что совокупность исходных данных подчиняется нормальному закону распределения.. Исходная совокупность значений должна быть качественно однородной. Сам по себе факт корреляционной зависимости не даёт основания утверждать, что одна из переменных предшествует или является причиной изменений, или то, что переменные вообще причинно связаны между собой, а не наблюдается действие третьего фактора. Область применения Данный метод обработки статистических данных весьма популярен в экономике и социальных науках (в частности в психологии и социологии), хотя сфера применения коэффициентов корреляции обширна: контроль качества промышленной продукции, металловедение, агрохимия, гидробиология, биометрия и прочие. В различных прикладных отраслях приняты разные границы интервалов для оце
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 909; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.128.201.71 (0.017 с.) |

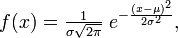
 и
и  независимы и имеют нормальное распределение с математическими ожиданиями
независимы и имеют нормальное распределение с математическими ожиданиями 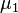 и
и  и дисперсиями
и дисперсиями 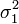 и
и  соответственно, то
соответственно, то  также имеет нормальное распределение с математическим ожиданием
также имеет нормальное распределение с математическим ожиданием  и дисперсией
и дисперсией  .
. Зеленая линия соответствует стандартному нормальному распределению
Зеленая линия соответствует стандартному нормальному распределению
 Цвета на этом графике соответствуют графику наверху
Цвета на этом графике соответствуют графику наверху

 - коэффициент сдвига (вещественное число)
- коэффициент сдвига (вещественное число)  - коэффициент масштаба(вещественный, строго положительный)
- коэффициент масштаба(вещественный, строго положительный)

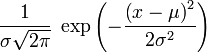
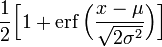





 - статистический критерий для проверки гипотезы
- статистический критерий для проверки гипотезы  , что наблюдаемая случайная величина подчиняется некому теоретическому закону распределения.
, что наблюдаемая случайная величина подчиняется некому теоретическому закону распределения. .
.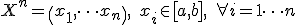 . По выборке построим эмпирическое распределение
. По выборке построим эмпирическое распределение  с.в X. Сравнение эмпирического
с.в X. Сравнение эмпирического  : Хn порождается функцией
: Хn порождается функцией  ;
; - количество наблюдений в j-м интервале:
- количество наблюдений в j-м интервале:  ;
; - вероятность попадания наблюдения в j-ый интервал при выполнении гипотезы
- вероятность попадания наблюдения в j-ый интервал при выполнении гипотезы  - ожидаемое число попаданий в j-ый интервал;
- ожидаемое число попаданий в j-ый интервал; - Распределение хи-квадрат с k-1 степенью свободы.
- Распределение хи-квадрат с k-1 степенью свободы.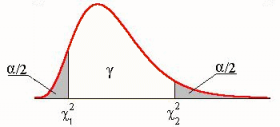
 , гипотеза
, гипотеза  (попадает в левый "хвост" распределения). Следовательно, теоретические и практические значения очень близки. Если, к примеру, происходит проверка генератора случайных чисел, который сгенерировал n чисел из отрезка [0,1] и гипотеза
(попадает в левый "хвост" распределения). Следовательно, теоретические и практические значения очень близки. Если, к примеру, происходит проверка генератора случайных чисел, который сгенерировал n чисел из отрезка [0,1] и гипотеза 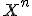 распределена равномерно на [0,1], тогда генератор нельзя называть случайным (гипотеза случайности не выполняется), т.к. выборка распределена слишком равномерно, но гипотеза
распределена равномерно на [0,1], тогда генератор нельзя называть случайным (гипотеза случайности не выполняется), т.к. выборка распределена слишком равномерно, но гипотеза  (попадает в правый "хвост" распределения) гипотеза
(попадает в правый "хвост" распределения) гипотеза  и
и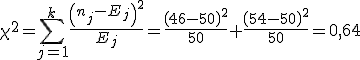
 о выполнении гипотезы
о выполнении гипотезы  (см. Таблицу распределения
(см. Таблицу распределения  ).
). - неизвестный параметр. Найдем приближенное значение параметра
- неизвестный параметр. Найдем приближенное значение параметра  с помощью метода максимального правдоподобия, основанного на частотах (фиксируем интервалы
с помощью метода максимального правдоподобия, основанного на частотах (фиксируем интервалы  для
для  ).
). ,
,
 , где
, где 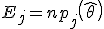
 , где S - число попаданий,
, где S - число попаданий,  .
.
 ).
). , тогда при
, тогда при  -теста. Однако, даже при других распределениях данных возможно использование
-теста. Однако, даже при других распределениях данных возможно использование  , поэтому можно использовать квантили этого распределения. Однако, часто даже в этом случае используют квантили не стандартного нормального распределения, а соответствующего распределения Стьюдента, как в точном
, поэтому можно использовать квантили этого распределения. Однако, часто даже в этом случае используют квантили не стандартного нормального распределения, а соответствующего распределения Стьюдента, как в точном  о равенстве математического ожидания
о равенстве математического ожидания  некоторому известному значению
некоторому известному значению  .
. . С учётом предполагаемой независимости наблюдений
. С учётом предполагаемой независимости наблюдений  . Используя несмещенную оценку дисперсии
. Используя несмещенную оценку дисперсии  получаем следующую t-статистику:
получаем следующую t-статистику: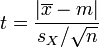
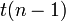 . Следовательно, при превышении критического значения нулевая гипотеза отвергается.
. Следовательно, при превышении критического значения нулевая гипотеза отвергается. нормально распределенных случайных величин
нормально распределенных случайных величин  . Необходимо проверить по выборочным данным нулевую гипотезу равенстве математических ожиданий этих случайных величин
. Необходимо проверить по выборочным данным нулевую гипотезу равенстве математических ожиданий этих случайных величин  .
. . Очевидно, если нулевая гипотеза выполнена
. Очевидно, если нулевая гипотеза выполнена  . Дисперсия этой разности равна исходя из независимости выборок:
. Дисперсия этой разности равна исходя из независимости выборок:  . Тогда используя несмещенную оценку дисперсии
. Тогда используя несмещенную оценку дисперсии  получаем несмещенную оценку дисперсии разности выборочных средних:
получаем несмещенную оценку дисперсии разности выборочных средних:  . Следовательно, t-статистика для проверки нулевой гипотезы равна
. Следовательно, t-статистика для проверки нулевой гипотезы равна
 , где
, где 
 . Тогда t-статистика равна:
. Тогда t-статистика равна:
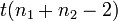

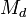 — средняя разность значений,
— средняя разность значений,  — стандартное отклонение разностей, а n — количество наблюдений
— стандартное отклонение разностей, а n — количество наблюдений . Очевидно, при выполнении нулевой гипотезы
. Очевидно, при выполнении нулевой гипотезы  . Здесь использовано свойство несмещенности МНК-оценок параметров модели
. Здесь использовано свойство несмещенности МНК-оценок параметров модели  .
. . Используя вместо неизвестной дисперсии ее несмещенную оценку
. Используя вместо неизвестной дисперсии ее несмещенную оценку  получаем следующую t-статистику:
получаем следующую t-статистику:
 , поэтому если значение статистики выше критического, то нулевая гипотеза о линейном ограничении отклоняется.
, поэтому если значение статистики выше критического, то нулевая гипотеза о линейном ограничении отклоняется. регрессии некоторому значению
регрессии некоторому значению  . В этом случае соответстующая t-статистика равна:
. В этом случае соответстующая t-статистика равна:
 — стандартная ошибка оценки коэффициента — квадратный корень из соответствующего диагонального элемента ковариационной матрицы оценок коэффициентов.
— стандартная ошибка оценки коэффициента — квадратный корень из соответствующего диагонального элемента ковариационной матрицы оценок коэффициентов. регрессии это и есть выборочная оценка дисперсии изучаемой случайной величины, матрица
регрессии это и есть выборочная оценка дисперсии изучаемой случайной величины, матрица  равна
равна  , а оценка «коэффициента» модели равна выборочному среднему. Отсюда и получаем выражение для t-статистики, приведенное выше для общего случая.
, а оценка «коэффициента» модели равна выборочному среднему. Отсюда и получаем выражение для t-статистики, приведенное выше для общего случая. . Гипотеза о равенстве математических ожиданий выборок может быть сформулирована как гипотеза о равенстве коэффициента b этой модели нулю. Можно показать, что соответствующая t-статистика для проверки этой гипотезы равна t-статистике, приведенной для двухвыборочного теста.
. Гипотеза о равенстве математических ожиданий выборок может быть сформулирована как гипотеза о равенстве коэффициента b этой модели нулю. Можно показать, что соответствующая t-статистика для проверки этой гипотезы равна t-статистике, приведенной для двухвыборочного теста. либо коэффициент корреляции
либо коэффициент корреляции  (или
(или  ). В случае, если изменение одной случайной величины не ведёт к закономерному изменению другой случайной величины, но приводит к изменению другой статистической характеристики данной случайной величины, то подобная связь не считается корреляционной, хотя и является статистической.
). В случае, если изменение одной случайной величины не ведёт к закономерному изменению другой случайной величины, но приводит к изменению другой статистической характеристики данной случайной величины, то подобная связь не считается корреляционной, хотя и является статистической. ,
,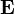 — математическое ожидание.
— математическое ожидание. и
и  равна нулю.
равна нулю. [9].
[9].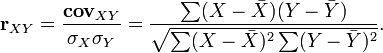
 ,
,  — среднее значение выборок.
— среднее значение выборок. где
где  — коэффициент регрессии,
— коэффициент регрессии,  — среднеквадратическое отклонение соответствующего факторного признака[12].
— среднеквадратическое отклонение соответствующего факторного признака[12]. (тау) Кендалла. В случае, когда одна из двух переменных является дихотомической, используется точечная двухрядная корреляция, а если обе переменные являются дихотомическими: четырёхполевая корреляция. Расчёт коэффициента корреляции между двумя недихотомическими переменными не лишён смысла только тогда, когда связь между ними линейна (однонаправлена).
(тау) Кендалла. В случае, когда одна из двух переменных является дихотомической, используется точечная двухрядная корреляция, а если обе переменные являются дихотомическими: четырёхполевая корреляция. Расчёт коэффициента корреляции между двумя недихотомическими переменными не лишён смысла только тогда, когда связь между ними линейна (однонаправлена). ,
, .
.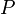 — суммарное число наблюдений, следующих за текущими наблюдениями с большим значением рангов Y.
— суммарное число наблюдений, следующих за текущими наблюдениями с большим значением рангов Y. — суммарное число наблюдений, следующих за текущими наблюдениями с меньшим значением рангов Y. (равные ранги не учитываются!)
— суммарное число наблюдений, следующих за текущими наблюдениями с меньшим значением рангов Y. (равные ранги не учитываются!)



 и вычисляется коэффициент корреляции Спирмена:
и вычисляется коэффициент корреляции Спирмена:



 — число групп, которые ранжируются.
— число групп, которые ранжируются. — ранг
— ранг  -фактора у
-фактора у  -единицы.
-единицы.

 , то гипотеза об отсутствии связи отвергается.
, то гипотеза об отсутствии связи отвергается.

 , то норма случайной величины будет равна
, то норма случайной величины будет равна  , и следствием неравенства Коши — Буняковского будет:
, и следствием неравенства Коши — Буняковского будет: .
. тогда и только тогда, когда
тогда и только тогда, когда  и
и  линейно зависимы (исключая события нулевой вероятности, когда несколько точек «выбиваются» из прямой, отражающей линейную зависимость случайных величин):
линейно зависимы (исключая события нулевой вероятности, когда несколько точек «выбиваются» из прямой, отражающей линейную зависимость случайных величин): ,
, . Более того в этом случае знаки
. Более того в этом случае знаки  и
и 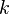 совпадают:
совпадают: .
. независимые случайные величины, то
независимые случайные величины, то  . Обратное в общем случае неверно.
. Обратное в общем случае неверно.



