
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Законы распределения случайных величин.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Результат измерения физической величины зависит от многих факторов, влияние которых заранее учесть невозможно. Поэтому значения, полученные в результате прямых измерений какого - либо параметра, являются случайными, обычно не совпадающие между собой. Следовательно, случайные величины - это такие величины, которые в зависимости от обстоятельств могут принимать те или иные значения. Если случайная величина принимает только определенные числовые значения, то она называется дискретной. Например, количество заболеваний в данном регионе за год, оценка, полученная студентом на экзамене, энергия электрона в атоме и т.д. Непрерывная случайная величина принимает любые значения в данном интервале. Например: температура тела человека, мгновенные скорости теплового движения молекул, содержание кислорода в воздухе и т.д. Под событием понимается всякий результат или исход испытания. В теории вероятностей рассматриваются события, которые при выполнение некоторых условий могут произойти, а могут не произойти. Такие события называются случайными. Например, событие, состоящее в появлении цифры 1 при выполнении условия - бросания игральной кости, может произойти, а может не произойти. Если событие неизбежно происходит в результате каждого испытания, то оно называется достоверным. Событие называется невозможным, если оно вообще не происходит ни при каких условиях. Два события, одновременное появление которых невозможно, называются несовместными. Пусть случайное событие А в серии из n независимых испытаний произошло m раз, тогда отношение:
называется относительной частотой события А. Для каждой относительной частоты выполняется неравенство:
При небольшом числе опытов относительная частота событий в значительной мере имеет случайный характер и может заметно изменяться от одной группы опытов к другой. Однако при увеличении числа опытов частота событий все более теряет свой случайный характер и приближается к некоторому постоянному положительному числу, которое является количественной мерой возможности реализации случайного события А. Предел, к которому стремится относительная частота событий при неограниченном увеличении числа испытаний, называется статистической вероятностью события:
Например, при многократном бросании монеты частота выпадения герба будет лишь незначительно отличаться от ½. Для достоверного события вероятность Р(А) равна единице. Если Р=0, то событие невозможно. Математическим ожиданием дискретной случайной величины называется сумма произведений всех ее возможных значений хi на вероятность этих значений рi:
Статистическим аналогом математического ожидания является среднее арифметическое значений
где mi - число дискретных случайных величин, имеющих значение хi. Для непрерывной случайной величины математическим ожиданием служит интеграл:
где р(х) - плотность вероятности. Отдельные значения случайной величины группируются около математического ожидания. Отклонение случайной величины от ее математического ожидания (среднего значения) характеризуется дисперсией, которая для дискретной случайной величины определяется формулой:
Дисперсия имеет размерность случайной величины. Для того, чтобы оценивать рассеяние (отклонение) случайной величины в единицах той же размерности, введено понятие среднего квадратичного отклонения σ(Х), которое равно корню квадратному из дисперсии:
Вместо среднего квадратичного отклонения иногда используется термин «стандартное отклонение». Всякое отношение, устанавливающее связь между всеми возможными значениями случайной величины и соответствующими им вероятностями, называется законом распределения случайной величины. Формы задания закона распределения могут быть разными: а) ряд распределения (для дискретных величин); б) функция распределения; в) кривая распределения (для непрерывных величин). Существует относительно много законов распределения случайных величин. Нормальный закон распределения случайных величин (закон Гаусса). Случайная величина
где <x> - математическое ожидание (среднее значение) случайной величины <x> = M (X);
f (x) – плотность вероятности (функция распределения вероятностей). Многие случайные величины (в том числе все случайные погрешности) подчиняются нормальному закону распределения (закону Гаусса). Для этого распределения наиболее вероятным значением измеряемой величиныявляется её среднее арифметическое значение. График нормального закона распределения изображен на рисунке (колоколообразная кривая).
Кривая симметрична относительно прямой х=<x>=α, следовательно, отклонения случайной величины вправо и влево от <x>=α равновероятны. При х=<x>±s кривая асимптотически приближается к оси абсцисс. Если х=<x>, то функция распределения вероятностей f(x) максимальна и принимает вид:
Таким образом, максимальное значение функции fmax(x) зависит от величины среднего квадратичного отклонения. На рисунке изображены 3 кривые распределения. Для кривых 1 и 2 <x> = α = 0 соответствующие значения среднего квадратичного отклонения различны, при этом s2>s1. (При увеличении s кривая распределения становится более пологой, а при уменьшении s – вытягивается вверх). Для кривой 3 <x> = α ≠ 0 и s3 = s2.
Закон распределения молекул в газах по скоростям называется распределением Максвелла. Функция плотности вероятности попадания скоростей молекул в определенный интервал
. На рисунке распределение Максвелла представлено графически. Распределение движется вправо или влево в зависимости от температуры газа (на рисунке Т1 < Т2). Закон распределения Максвелла определяется формулой:
где mо – масса молекулы, k – постоянная Больцмана, Т – абсолютная температура газа, Распределение концентрации молекул газа в атмосфере Земли (т.е. в силовом поле) в зависимости от высоты было дано австрийским физиком Больцманом и называется распределением Больцмана:
Где n(h) – концентрация молекул газа на высоте h, n0 – концентрация у поверхности Земли, g – ускорение свободного падения, m – масса молекулы.
Распределение Больцмана. Совокупность всех значений случайной величины называется простым статистическим рядом. Так как простой статистический ряд оказывается большим, то его преобразуют в вариационный статистический ряд или интервальный статистический ряд. По интервальному статистическому ряду для оценки вида функции распределения вероятностей по экспериментальным данным строят гистограмму – столбчатую диаграмму. (Гистограмма – от греческих слов “histos”– столб и “gramma”– запись). n
0 h Гистограмма распределения Больцмана. Для построения гистограммы интервал, содержащий полученные значения случайной величины делят на несколько интервалов Dxi одинаковой ширины. Для каждого интервала подсчитывают число mi значений случайной величины, попавших в этот интервал. После этого вычисляют плотность частоты случайной величины Затем по оси абсцисс откладывают интервалы Dxi, являющиеся основаниями прямоугольников, высота которых равна
Расчетами показано, что вероятность попадания нормально распределенной случайной величины в интервале значений от <x>–s до <x>+s в среднем равна 68%. В границах вдвое более широких (<x>–2s; <x>+2s) размещается в среднем 95% всех значений измерений, а в интервале (<x>–3s;<x>+3s) – уже 99,7%. Таким образом, вероятность того, что отклонение значений нормально распределенной случайной величины превысит 3s (s – среднее квадратичное отклонение) чрезвычайно мала (~0,003). Такое событие можно считать практически невозможным. Поэтому границы <x>–3s и <x>+3s принимаются за границы практически возможных значений нормально распределенной случайной величины («правило трех сигм»). Если число измерений (объем выборки) невелико (n<30), дисперсия вычисляется по формуле:
Уточненное среднее квадратичное отклонение отдельного измерения вычисляется по формуле:
Напомним, что для эмпирического распределения по выборке аналогом математического ожидания является среднее арифметическое значение <x> измеряемой величины. Чтобы дать представление о точности и надежности оценки измеряемой величины, используют понятия доверительного интервала и доверительной вероятности. Доверительным интервалом называется интервал (<x>–Dx, <x>+Dx), в который по определению попадает с заданной вероятностью действительное (истинное) значение измеряемой величины. Доверительный интервал характеризует точность полученного результата: чем уже доверительный интервал, тем меньше погрешность. Доверительной вероятностью (надежностью) a результата серии измерений называется вероятность того, что истинное значение измеряемой величины попадает в данный доверительный интервал (<x>±Dx). Чем больше величина доверительного интервала, т.е. чем больше Dx, тем с большей надежностью величина <x> попадает в этот интервал. Надежность a выбирается самим исследователем самостоятельно, например, a=0,95; 0,98. В медицинских и биологических исследованиях, как правило, доверительную вероятность (надежность) принимают равной 0,95. Если величина х подчиняется нормальному закону распределения Гаусса, а <x> и <s> оцениваются по выборке (числу измерений) и если объем выборки невелик (n<30), то интервал (<x> – ta,n<s>, <x> + ta,n<s>) будет доверительным интервалом для известного параметра х с доверительной вероятностью a. Коэффициент ta,n называется коэффициентом Стьюдента (этот коэффициент был предложен в 1908 г. английским математиком и химиком В.С. Госсетом, публиковавшим свои работы под псевдонимом «Стьюдент» – студент). Значении коэффициента Стьюдента ta,n зависит от доверительной вероятности a и числа измерений n (объема выборки). Некоторые значения коэффициента Стьюдента приведены в таблице 1. Таблица 1
В таблице 1 в верхней строке заданы значения доверительной вероятности a от 0,6 до 0,99, в левом столбце – значение n. Коэффициент Стьюдента следует искать на пересечении соответствующих строки и столбца. Окончательный результат измерений записывается в виде:
Где Результат серии измерений оценивается относительной погрешностью:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 573; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.120.10 (0.008 с.) |




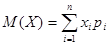
 :
: ,
, ,
,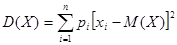 (15)
(15) (16)
(16) (17)
(17)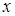 распределена по нормальному закону, если ее плотность вероятности f(x) определяется формулой:
распределена по нормальному закону, если ее плотность вероятности f(x) определяется формулой: (18),
(18), - среднее квадратичное отклонение;
- среднее квадратичное отклонение; - основание натурального логарифма (неперово число);
- основание натурального логарифма (неперово число);
 (19)
(19) теоретически была определена в 1860 году английским физиком Максвеллом
теоретически была определена в 1860 году английским физиком Максвеллом
 (20),
(20), - скорость молекулы.
- скорость молекулы. (21)
(21)

 для каждого интервала Dxi и среднее значение случайной величины <Dxi > в каждом интервале.
для каждого интервала Dxi и среднее значение случайной величины <Dxi > в каждом интервале. (или высотой
(или высотой  – плотностью относительной частоты
– плотностью относительной частоты  ).
).
 (22)
(22) (23)
(23) (25)
(25) – полуширина доверительного интервала.
– полуширина доверительного интервала.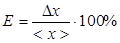 (26)
(26)


