Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Проблема багатовимірної візуалізаціїСодержание книги
Поиск на нашем сайте
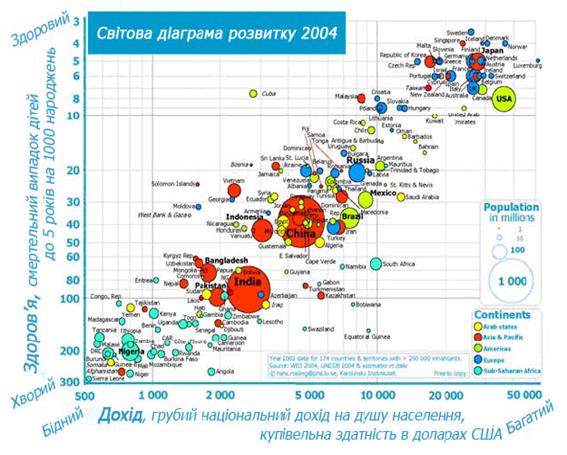
Раніше розглянули деякі приклади двох і трьохвимірних даних, які представлені простим розсіянням на декартові осі. Діаграми розсіювання дуже прості і інтуїтивно зрозумілі візуальні форми що добре працюють, коли є два залежних атрибута. Їх значення відображаються вздовж значення декартових осей. Проте, кількість ситуацій, в яких один або два з залежних атрибутів беруть участь дуже обмежена, і найбільш реальні проблеми мають досить велику кількість залежних атрибутів для аналізу. Цей приклад, який показує дані з 174 країн і цілі для порівняння рівня добробуту (представлений валовий національний дохід кожного жителя) і стан здоров'я місцевого населення (представлено число випадків смерті дітей у віці до п'яти років на кожну 1000 новонароджених). Ці значення відповідно відображаються на осі х і осі у. Крім того, вони прагнуть представити число жителів (відображається як розмірність графічних елементів), і на континенті якому кожна країна належить (відображається на кольорі графічного елементу). Відразу безпосередньо звертає увагу майже лінійна кореляція між багатством і станом здоров'я: стан здоров'я покращується за умови багатства населення. Є також окремі випадки, які йдуть проти течії по відношенню до загальної тенденції, найбільш очевидним є Куба, населення якої має високий рівень охорони здоров'я, незважаючи на багатство. Що навіть вище, ніж у Сполучених Штатів у порівнянні з Індією. Інша цікава інформація з кольору кіл. Наприклад, африканські країни майже всі згруповані в лівому нижньому кутку графіка із зазначенням стану крайньої убогості і жахливого рівня здоров'я в цих нещасних народів.
Рис. 2.12 Розсіювання, які представляють чотири-мірні атрибути. Зображення опубліковано на даних, отриманих з статистичних досліджень.
Геометричні методи Геометричні методи в візуалізації інформації складаються з відображення даних з атрибутів на геометричному просторі. Діаграми розсіювання належать до цієї категорії, але, обмежуються тим, що вони мають лише дві декартові осі, на якій карта має тільки два виміри. У 1981 році Альфред Інсельберг, науковий співробітник IBM, запропонував блискучу ідею визначення у геометричному просторі через довільну кількість осей, розташовуючи їх паралельно, а не перпендикулярно, як це було зроблено раніше. Це був початок однієї з найбільш поширених технік сьогоднішнього візуального представлення багатовимірних даних. Паралельні координати Цей метод бере свою назву від методу, де значення даних представлені: так що кожен атрибут відповідає осі та осі розташовуються паралельно на рівній відстані. Кожен запис даних представляє полігональний ланцюг, який пов'язує значення атрибутів на його осі. Розглянемо приклад, щоб допомогти зрозуміти, як працює саме цей тип візуалізації. Давайте припустимо, що ми повинні представляти наступні дані про осіб через паралельні координати.
Кожен запис даних має різні кольори для полегшення розуміння процесу генерації. Мова йде про тривимірні дані, два з яких є числа (вік і вага) і одно категоричне (стать). Ім'я особи, вважається незалежним даним. Ми представимо ці дані як відображення значень на три паралельні осі, використовуючи кількісні просторової підкладки для перших двох атрибутів і номінальні для останніх. Приєднавши точки, відповідні координати кожного запису, ми досягаємо подання що показано на рис..2.13
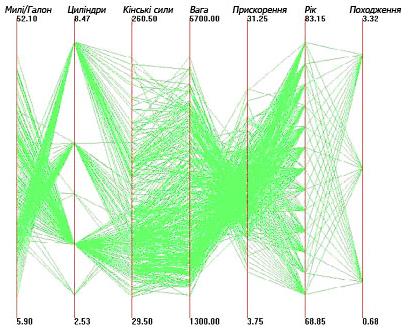
Рис. 2.13 Паралельні координати уявлення. Перейдемо до аналізу конкретного випадку, з використанням даних наданих у програмному забезпеченні, розробленому Метью Уордом. Програмне забезпечення є суспільним надбанням і може бути вільно застосовано. Дані містять технічні характеристики 392 моделей автомобілів виробництва в 1970-х років, з сімома залежними атрибутами. На основі аналізу даних за допомогою програмного забезпечення, ми можемо досягти візуального представлення яке показано на рис. 2.14.
Рис.2.14 Паралельні координати для 730 елементів з 7 варіантами атрибутів. Паралельні координати дуже потужний інструмент для дослідницького аналізу даних. Наприклад, зворотній зв'язок між споживанням палива (MPG) і числом циліндрів у автомобілів легко помітною: перетин ліній, які з'єднують значення між двома осями наочно демонструє, як автомобілі з великою кількістю циліндрів (у верхній частині осі) охоплюють меншу кількість міль на галон, чим менше циліндрів. Інший чіткий зворотній зв'язок, є між вагою і прискоренням автомобіля бо важкі автомобілі, як правило мають, короткі прискорення (мається на увазі час, необхідний для досягнення певної швидкості, починаючи від стану спокою). Хоча вони є дуже потужним інструментом дослідницького аналізу, паралельні координати можуть представити деякі проблеми з дуже великими обсягами даних (наприклад, у наборі з 5000 елементів). У таких випадках, візуальне подання може бути занадто щільним, щоб розрізнити лінії скорочення представництва. Ця проблема притаманна будь-якому візуальному уявленню: Місця на екрані може бути недостатньо щоб вмістить всі візуальні елементи.
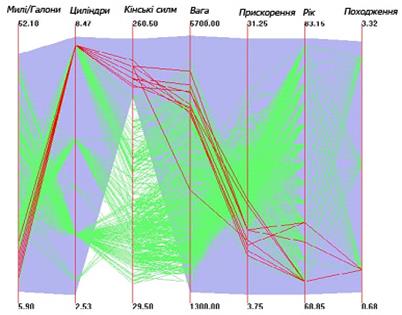
Рис. 2.15 Чистка значень на паралельних координатах. Червоні лінії представляють елементи, які задовольняють всі обмеження на значення що позначаються фіолетовим фоном.
Матриця розсіяння Матриці розсіяння представляють цікаві розширення загального 2D розгляду сюжету, просто і інтуїтивно представляють загальне число багатовимірних атрибутів. Це дуже проста техніка складається з представлень пари ознак, через двовимірної діаграми розсіювання, і покладання діаграм розсіювання на площину. Таким чином формується матриця, де N це кількість атрибутів для подання. Малюнок 2.16 ілюструє, приклад, породжений за допомогою програмного забезпечення, використовуючи той самий набір даних, який раніше використовувався для паралельних координат.
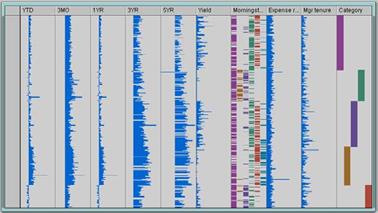
Рис. 2.16 Матриця розсіювання багатовимірних даних З малюнка, видно тип кореляції, який курсує між різними парами атрибутів. Наприклад, абсолютно ясно, що за рахунок збільшення кінських сил і ваги, кількість міль покриття (в термінах міля на галон,) значно знижується (див. графіки що включені в синій рамці). Використання матриці розсіювання, робить зв'язок між парами відразу помітним, що не потребує втручання візуального представлення. З іншого боку, матриця розсіювання може представити деякі незручності. Неможливо поставити етикетки для позначення окремих точок, або вибрати конкретний момент за допомогою миші, щоб прочитати значення її координати. Крім того, втрачається колективне бачення всіх атрибутів, які ми спостерігали раніше. Таблиця лінзи Таблиці, додатки, такі як Microsoft Excel, стали одним з найбільш поширених типів програмного забезпечення. Завдяки дуже інтуїтивному візуальному інтерфейсу, а також завдяки деяким дуже ефективним ініціативам маркетингу, цей тип інструменту є частиною програмного забезпечення устаткування кожного комп'ютера. Велика інтуїція, яку мали творці даного програмного забезпечення ще на початку 1980-х було запропоновано використовувати структуру, аналогічну таблиці множення для виконання розрахунків, в дуже простій організації даних. Слідуючи цьому принципу, в 1994 році Джон Лампінг і Рамана Рао пропонують візуальний інструмент аналізу даних, які називаються таблиці лінз. Його структура була натхненна поширенням для представлення даних з допомогою горизонтальних смуг, а не числових значень. Зокрема, дані представлені матрицею, де атрибути представлені в колонки і кожен екземпляр даних розміщується в рядках матриці. Чисельні значення атрибутів набору даних зіставляються з довжиною горизонтальних смуг. Візуально, горизонтальні смуги можуть бути представлені в дуже обмеженому просторі. Таким чином йому вдається представляти велику кількість атрибутів та випадків, в одному екрані і дозволяє користувачам відразу визначити можливі моделі, тенденцій і взаємозв'язків між атрибутами рис 2.17.
Рис. 2.17Представлення таблиці лінз Цікавою особливістю цього типу уявлення є можливість користувачеві взаємодіяти з візуалізацією
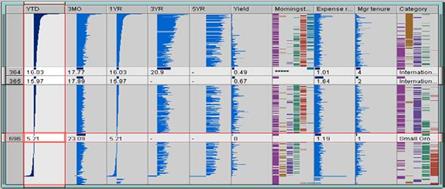
Рис.2.18 Таблиця лінз відсортована за значеннями першого стовпця.
Приклад показаний на рис.2.18 де дані відсортовані за значеннями першого стовпця ліворуч. Геометричні методи, обговорювані досі можуть бути використані з будь-яким типом атрибута.
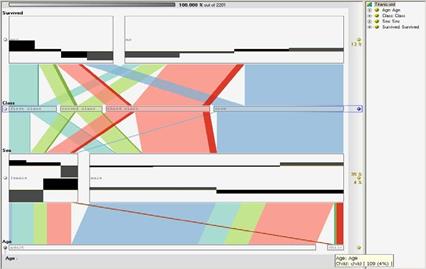
Рис.2.19Представлення даних катастрофи Титаніка з використанням паралельних множин. Цей тип подання, на відміну від паралельних координат, виявляється більш доцільним у разі категоріальних даних
Рис.2.19 показує уявлення зокрема, паралельні набори даних, отриманих з жертв катастрофи Титаніка, після зіткнення з айсбергом в ніч на 14 квітня 1912 року. Набір даних складається з чотирьох залежних атрибутів: вік пасажирів, статі, класу, в якому вони подорожували, і чи вони пережили катастрофу. Макет нагадує паралельні координати, але, в даному випадку, були замінені на число прямокутників, які представляють категорії. Ширина цих прямокутників відповідає частоті відповідної категорії (наприклад, в зоні, яка представляє статі, було 470 жінок пасажирів і 1731 чоловіків пасажирів; розмір прямокутника відображає цю частку дуже ясно). Крім того, кількісні ознаки можуть бути відображені на осі, як ми бачимо у випадку віку. Атрибути розташовані поруч один з одним пов'язані у сполуки, що в цьому випадку є значення частот, в якому умови перевіряються. Наприклад, на малюнку, атрибут у верхній частині, стосується тих що залишилися в живих, поділяється на дві області. Ті, хто пережив лихо розташовані по відношенню до пасажирського класу, до якого вони належать.
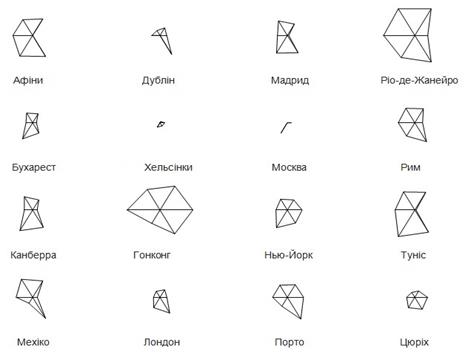
Методи іконок Інше сімейство методів представлення багатовимірних даних, яке використовує геометричні властивості фігури називається методом символьних іконок. Назва походить від того, що геометрична фігура (ікона, яку в даному випадку також називають символом), може мати ряд особливостей, які можуть відрізнятися: колір, форма, розмір, орієнтація і т.д. Основна ідея полягає у асоціюванні кожного атрибуту з функцією в геометричну фігуру і відображення даних на великій кількості властивостей кожного компонента. Розглянемо два з відомих методів: зірки ділянок та особи Чернова. Зірка ділянки Проста та інтуїтивна геометрична фігура представлена зоряним багатокутником, вершини якого визначають множину осей, що всі мають спільне походження. Кожен екземпляр набору даних може бути представлений як "зірки", в яких значення кожного атрибута зіставляються з довжиною кожної вершини. Приєднавшись до точок, які відповідають кожній вершині, геометрична фігура яка виходить, має специфічну форму яка глобально описує примірник набору даних. Цей метод, названий зіркові ділянки, може бути дуже корисним.
Місто Середні Середні Сер. макс. Сер. мін. Макс. зафіксована Мін. зафіксована
Афіни 37 17 21 13 42 −3 Бухарест 58 11 16 5 49 −23 Канберра 62 12 19 6 42 −10 Дублін 74 10 12 6 28 −7 Гельсінки 63 5 8 1 31 −36 Гонконг 218 23 25 21 37 2 Лондон 75 10 13 5 35 −13 Мадрид 45 13 20 7 40 −10 Мехіко 63 17 23 11 32 −3 Москва 59 4 8 1 35 −42 Нью-Йорк 118 12 17 8 40 −18 Порто 126 14 18 10 34 −2 Ріо-де-Жанейро 109 25 30 20 43 7 Рим 80 15 20 11 37 −7 Туніс 44 18 23 13 46 −1 Цюріх 107 9 12 6 35 −20
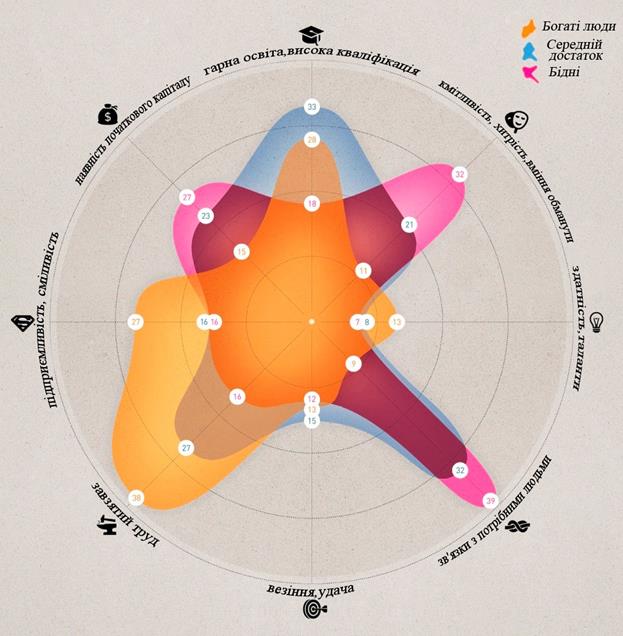
Рис. 2.20 Кліматична оцінка в градусах Цельсія у деяких містах світу. З подання зірки ділянки на рис. 2.20, ми помічаємо, що Москва і Гельсінкі мають подібні кліматичні характеристики, як і Афіни та Туніс. Просто порівнюючи форми породжених зірками сюжетів, ми можемо візуально відрізнити угруповання елементів різних наборів даних. Секрет успіху Представникам різних соціальних верств задано одне і те ж питання: «у чому основні причини успіху?». Результат подано як зіркову ділянку. Як видно з відповідей, бідним перш за все потрібно міняти свій підхід до життя.
Очевидно межа уявлень цього типу полягає в поданні масштабу. Для кількох дуже малих елементів, простір на екрані стає настільки маленьким, що важко чітко розгледіти і порівняти різницю знакових форм. Крім того, знакові методи застосовуються при якісному, а не кількісному аспекті порівняння різних атрибутів набору вивчення даних.
Рис.2.21 Зірки ділянок щорічних кліматичних даних деяких міст
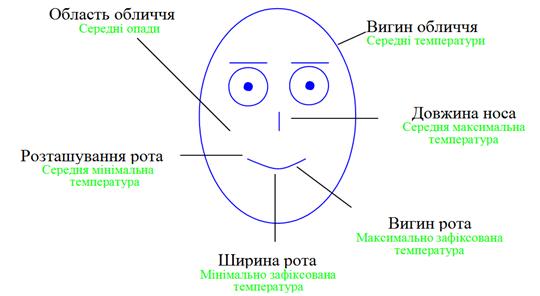
Особи Чернова Герман Чернов запропонував цікаву техніку уяви позначок, в якій елемент подання не невиразний і нудний полігон зірка, а обличчя "особа". Це важливо тому що люди, особливо здатні визначати навіть найменші зміни в людській міміці. Чернов пропонує відображення атрибутів колекції багатовимірних даних у форму, розміри і орієнтація якої подібні людським рисам обличчя, таким як очі, ніс, рот, вуха і т.д. рис. 2.22 дає приклад подання, через особу Чернова, про кліматичні дані міст, які ми раніше розглядали. Відображення подано на рис. 2.22. Як і у випадку зіркових ділянок з цих сюжетів, ми можемо вивести подібності між містами Гельсінкі та Москвою й Афінами та Тунісом. Цей тип відображення використовує знайомі риси обличчя що відразу помітно, з більшою виразною силою, ніж зіркові ділянки. Наприклад, вибравши на карті області ті особи, де розглянута середня кількість опадів у місті, ми відразу бачимо, що Гонконг є дуже дощове місто. Вибір відображення між атрибутами та елементами особи є критичним і, якщо погано проводиться, може призвести до неправильних спостережень.
Особа Чернова. Можна зрозуміти, що такі міста, як Ріо-де-Жанейро і Туніс розташовані в кращих кліматичних умовах, ніж інші, тільки тому, що особа має усміхнений вираз. Цей тип уявлення дуже цікавий, тому що його спосіб представлення даних, навіть якщо він був підданий критиці за ці роки численними експертами з візуалізації, тому, що симетрія частин, таких як очі, брови, вуха, присутні парами на обличчі, здатні створювати непотрібне дублювання. Крім того, дослідження показали, як вибір відображення атрибута може призвести відмінностей до 25% в рамках кластерного сприйняття в наборі даних. Це означає, що для класифікації двох осіб, як "подібні" широко впливає вибір відображення функції конкретного атрибута однієї особи замість іншого.
Рис. 2.22 Кліматичні дані деяких міст представлені особами Чернова
|
||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-25; просмотров: 415; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.15.190.187 (0.008 с.) |



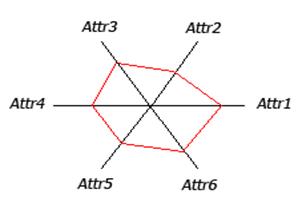 Порівнюючи різні випадки з набору даних, просто порівнюючи полігональної форми, отримані від кожного символу можна робити різні висновки про дані. На рис.2.20, ми можемо, наприклад, порівняти статистичні дані деяких кліматичних значень, представлених зірками ділянки. Представлені атрибути середньорічна кількість опадів, середньорічна температура, середня максимальна річна температура, середні мінімальні річні температури, рекорд максимальної температури і рекорд по мінімальній температурі. Ці дані надходять з багаторічної статистики. Різні атрибути зіставляються з довжиною кожної вершини зірки, починаючи з права і виходячи проти годинникової стрілки.
Порівнюючи різні випадки з набору даних, просто порівнюючи полігональної форми, отримані від кожного символу можна робити різні висновки про дані. На рис.2.20, ми можемо, наприклад, порівняти статистичні дані деяких кліматичних значень, представлених зірками ділянки. Представлені атрибути середньорічна кількість опадів, середньорічна температура, середня максимальна річна температура, середні мінімальні річні температури, рекорд максимальної температури і рекорд по мінімальній температурі. Ці дані надходять з багаторічної статистики. Різні атрибути зіставляються з довжиною кожної вершини зірки, починаючи з права і виходячи проти годинникової стрілки.