Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Розв’язання задач дедуктивного виборуСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
У дедуктивних моделях подання й обробки знань вирішувану проблему записують у вигляді тверджень формальної системи, у вигляді твердження, правдивість якого треба встановити чи спростувати на підставі аксіом (загальних законів) і правил виведення формальної системи. Як формальну систему використовують числення предикатів першого порядку. Відповідно до правил, установлених у формальній системі, заключному твердженню-теоремі, отриманому з початкової системи тверджень (аксіом, посилок), присвоюється значення ІСТИНА, якщо кожній посилці, аксіомі також присвоєно значення ІСТИНА. Процедура виведення – це процедура, яка із заданої групи виразів виводить відмінний від заданих вираз. Звичайно в логіці предикатів застосовують формальний метод доведення теорем, що допускає можливість його машинної реалізації, але існує також можливість доведення неаксіоматичним шляхом – прямим чи зворотним виведенням. Метод резолюції застосовують як повноцінний (формальний) метод доведення теорем. Для застосування цього методу вихідну групу заданих логічних формул потрібно перетворити на деяку нормальну форму. Це перетворення проводять у кілька стадій, що складають машину виведення.
Розв’язання задач, що використовують немонотонну логіку, імовірнісну логіку
Дані й знання, із якими доводиться мати справу в ІС, рідко бувають абсолютно точними й достовірними. Властива знанням невизначеність може мати різноманітний характер, і для її опису застосовується широкий спектр формалізмів. Розглянемо один із типів невизначеності в даних і знаннях – їх неточність. Будемо називати висловлення неточним, якщо його істинність (чи хибність) не можна встановити з певністю. Основним поняттям у процесі побудови моделей неточного виведення є поняття ймовірності, тому всі описувані далі методи пов'язані з імовірнісною концепцією. Модель оперування неточними даними й знаннями включає два складники: мову подання неточності й механізм виведення на неточних знаннях. Для побудови мови необхідно вибрати форму подання неточності (наприклад, скаляр, інтервал, розподіл, лінгвістичний вираз, множина) і передбачити можливість присвоювати міру неточності всім висловленням. Механізми оперування неточними висловленнями можна поділити на два типи. До першого відносять механізми, що мають „приєднаний” характер: перерахування мір неточності неначе супроводжує процес виведення, здійснюваного на точних висловленнях. Для розробки „приєднаної” моделі неточного виведення в заснованій на правилах виведення системі необхідно задати функції перерахування, що дозволяють обчислювати: а) міру неточності антецедента правила (його лівої частини) за мірами неточності складників його висловлень; б) міру неточності консеквента правила (його правої частини) за мірами неточності правила і посилки правила; в) об'єднану міру неточності висловлення за мірами, отриманими з правил. Уведення міри неточності дозволяє додати в процес виведення щось принципово нове – можливість об'єднувати декілька свідчень, що підтверджують чи спростовують одну й ту саму гіпотезу. Іншими словами, у процесі використання мір неточності доцільно виводити одне й те саме твердження різними шляхами (з наступним об'єднанням значень неточності), що зовсім безглуздо в традиційній дедуктивній логіці. Для об'єднання свідчень потрібна функція перерахування,що займає центральне місце в перерахуванні. Зазначимо, що, незважаючи на „приєднаність” механізмів виведення цього типу, їх реалізація в базах знань (БЗ) впливає на загальну стратегію виведення: з одного боку, необхідно виводити гіпотезу всіма можливими шляхами для того, щоб урахувати всі релевантні цій гіпотезі свідчення, з іншого боку, слід унеможливити багаторазовий вплив сили тих самих свідчень. Для механізмів оперування неточними висловленнями другого типу характерна наявність схем виведення, спеціально орієнтованих на використовувану мову подання неточності. Як правило, кожному кроку виведення відповідає перерахування мір неточності, обумовлене співвідношенням на множині висловлень (співвідношенням може бути елементарний логічний зв'язок безвідносно до того, чи є це відношення фрагментом якого-небудь правила). Таким чином, механізми другого типу застосовують не тільки до знань, виражених у формі правил. Водночас для них, як і для механізмів „приєднаного” типу, однією з головних є проблема об'єднання свідчень. Експертні системи
На початку 80-х рр. у дослідженнях зі штучного інтелекту сформувався самостійний напрямок, що одержав назву експертних систем (ЕС). Мета досліджень із застосуванням ЕС полягає в розробці програм, які в ході розв’язання задач одержують результати, що не поступаються за якістю й ефективністю рішенням, одержуваним експертами. В ЕС часто використовують термін „інженерія знань”, уведений Е. Фейгенбаумом, що означає привнесення принципів та інструментарію досліджень із галузі штучного інтелекту у вирішення складних прикладних проблем, що потребують знань експертів. Програмні засоби (ПЗ), що ґрунтуються на технології ЕС, або інженерії знань набули значного поширення у світі. ЕС призначені для розв’язання так званих неформалізованих задач, тобто ЕС не відкидають і не заміняють традиційного підходу до розробки програм, орієнтованого на розв’язання формалізованих задач. Неформалізовані задачі звичайно мають такі особливості: – помилковість, неоднозначність, неповнота й суперечливість початкових даних; – помилковість, неоднозначність, неповнота і суперечливість знань про проблемну галузь і розв'язувану задачу; – велика розмірність простору рішення, тобто перебір у процесі пошуку рішення дуже великий; – дані й знання, що динамічно змінюються. Неформалізовані задачі – це великий і дуже важливий клас задач. Багато фахівців вважають, що ці задачі становлять найбільш масовий клас задач, розв'язуваних ЕОМ. ЕС і системи штучного інтелекту відрізняє від систем обробки даних те, що в них в основному застосовується символьний (а не числовий) спосіб подання, символьне виведення й евристичний пошук рішення (а не виконання відомого алгоритму). Основні переваги, яке забезпечує використання ЕС, такі: 1) сталість. Людська компетенція з часом слабшає. Перерва в діяльності людини-експерта може серйозно відбитися на її професійних якостях; 2) простота передачі або відтворення. Передача знань від однієї людини до іншої – досить довгий і дорогий процес. Передача штучної інформації – це простий процес копіювання програми чи файлу даних; 3) стійкість і відтворюваність результатів. Людина-експерт може приймати в тотожних ситуаціях різні рішення через емоційні фактори. Результати ЕС стабільні; 4) вартість. Послуги експертів, особливо висококваліфікованих коштують дуже дорого. ЕС, навпаки, порівняно недорогі. Їх розробка дорога, але вони дешеві в експлуатації. Водночас розробка ЕС не дозволяє цілком відмовитися від експерта-людини. Хоч ЕС добре справляється зі своєю роботою, проте в певних сферах людська компетенція явно перевершує штучну. Однак і в цих випадках із застосуванням ЕС можна відмовитися від послуг висококваліфікованого експерта, залишивши експерта середньої кваліфікації, використовуючи при цьому ЕС для посилення й розширення професійних можливостей людини. Уявлення про те, як функціонує ЕС може дати схема, зображена на рис. 4. Щоб проводити експертизу, комп'ютерна програма має бути здатна розв’язувати задачі за допомогою логічного виведення й одержувати при цьому досить надійні результати. Програма повинна мати доступ до системи фактів, яку називають базою знань. Програма також повинна під час консультації робити висновок з інформації, що знаходиться в БЗ. Деякі ЕС можуть також використовувати нову інформацію, яку додають під час консультації. ЕС, таким чином, складається з трьох частин: 1) БЗ; 2) механізм виведення; 3) система інтерфейсу користувача. БЗ – центральна частина ЕС. Вона містить правила, що описують відношення або явища, методи і знання для розв’язання задач із галузі застосування системи. БЗ складається з фактичних знань і знань, використовуваних для виведення інших знань. Факти й правила в ЕС не завжди або правильні, або помилкові. Іноді існує деякий ступінь непевності у вірогідності факту або точності правила. Якщо цей сумнів виражений явно, то він має назву коефіцієнта довіри.
Рис. 4. Структура експертних систем
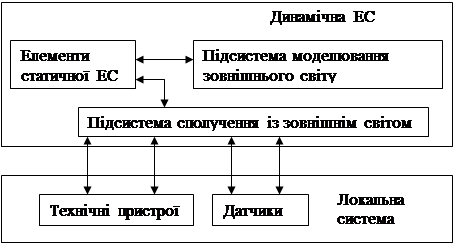
Коефіцієнт довіри – це число, що означає ймовірність чи ступінь упевненості, з яким можна вважати деякий факт або правило достовірним чи правдивим. Багато правил ЕС – евристики, тобто емпіричні правила або спрощення, що ефективно обмежують пошук рішення. ЕС використовує евристики, тому що задачі, які вона розв’язує, важкі, не до кінця зрозумілі, не підлягають строгому математичному аналізу чи алгоритмічному розв’язанню. Алгоритмічний метод гарантує коректне або оптимальне розв’язання задачі, тоді як евристичний метод в основному дає прийнятне рішення. Знання в ЕС організовані таким чином. Зокрема, знання про предметну галузь відокремлені від інших типів знань системи, таких як загальні знання про те, як розв’язувати задачі, чи про те, як взаємодіяти з користувачем. Виділені знання про предметну галузь мають назву БЗ, тоді як загальні знання щодо розв’язання задач називають механізмом виведення. Програмні засоби, що працюють зі знаннями, організованими таким чином, називають системами, заснованими на знаннях. БЗ містить факти (дані) і правила (чи інші подання знань), що застосовують ці факти як основу для прийняття рішень. Існують різні види подання даних, наприклад: · пари атрибут–значення (властивість–значення); · триплети об’єкт–атрибут–значення; · записи; · фрейми; · семантичні мережі. Найбільш фундаментальна є схема, яка використовує пари атрибут–значення. Це, наприклад, пари колір – білий, розмір – великий. Коли система оперує складними об’єктами, необхідно в пару атрибут–значення включити об’єкт. Наприклад, система встановлення меблів у кімнаті могла б мати справу зі складаними стільцями, які мають різні атрибути, такі як розмір. У цьому випадку подання даних повинне включати об’єкт. Оскільки об’єкти включено в систему, кожен із них може мати складні атрибути. Це приводить до структури, яка ґрунтується на записах, де кожен пункт даних складається з імені об’єкта і всіх пов’язаних із ним пар атрибут–значення. Фрейми – ще більш складний спосіб зберігання об’єктів і їх атрибутів та значень. Фрейми надають інтелектуальності поданню даних і дозволяють об’єктам успадковувати значення від інших об’єктів. Більше того, кожен атрибут може бути пов’язаний із певною процедурою (яку називають „демоном”), виконуваною в процесі запиту або відновлення атрибута. Механізм виведення містить принципи й правила роботи. Він „знає”, як використовувати БЗ, так щоб можна було одержувати розумно погоджені висновки з інформації, що знаходиться в ній. Коли ЕС ставлять питання, механізм виведення вибирає спосіб застосування правил БЗ для розв’язання задачі, окресленої в питанні. Фактично, механізм виведення запускає ЕС в роботу, установлюючи, які правила потрібно викликати і як організувати доступ у БЗ. Механізм виведення виконує правила, визначає, коли знайдено прийнятне рішення, і передає результати програмі інтерфейсу з користувачем. Коли питання треба попередньо обробити, то доступ до БЗ забезпечується через інтерфейс із користувачем. Механізм виведення містить: · інтерпретатор, що визначає, як застосовувати правила для виведення нових знань на основі інформації, що зберігається в БЗ; · диспетчер, що встановлює порядок застосування цих правил. Такі ЕС одержали назву статичних і мають структуру, зображену на рис. 5. Ці ЕС використано в додатках, де можна не враховувати зміни навколишнього світу під час розв’язання задачі. Існує більш високий клас додатків, де потрібно враховувати динаміку зміни навколишнього світу під час виконання додатка. Такі ЕС одержали назву динамічних. Їм властива структура, показана на рис. 6. Порівняно зі статичною ЕС у динамічну входять ще два компоненти: · підсистема моделювання зовнішнього світу; · підсистема сполучення із зовнішнім світом. Динамічна ЕС здійснює зв'язок із зовнішнім світом через систему контролерів і датчиків. Крім того, компоненти БЗ і механізму виведення істотно змінюються, відбиваючи часову логіку подій, що відбуваються в реальному світі.
Рис. 5. Структура статичної експертної системи
Рис. 6. Загальна структура динамічної експертної системи До таких динамічних середовищ розробки ЕС належить сім’я програмних продуктів фірми „Gensym Corp.” (США).Один із таких продуктів – система G2 – базовий програмний продукт, що являє собою графічне об'єктозорієнтоване середовище для побудови й супроводу ЕС реального часу, призначених для моніторингу, діагностики, оптимізації, планування динамічного процесу і керування ним. Існують два порядки механізму виведення – прямий (forward chaining) і зворотний (backward chaining). Інша їх назва – міркування, керовані даними (Data driven reasoning), і міркування, керовані метою (Goal driven reasoning) Прямий порядок виведення будують від активних фактів до висновку, тобто за відомими фактами знаходять висновок, який випливає з цих фактів. Цей механізм аналогічний тому, який застосовує слідчий, коли на основі певної кількості фактів визначає злочинця. За зворотного порядку виведення низку готових висновків послідовно розглядають, доки не будуть знайдені факти конкретної ситуації, які підтверджують який-небудь один висновок, тобто шляхом добору фактів, які підходять під висновок. Цей механізм аналогічний процедурі, коли в слідчого є певна кількість підозрюваних і він по черзі перевіряє кожного з них, знаходячи злочинця. Зворотне виведення ефективне для вирішення так званих проблем „структурного вибору”. Мета системи в цьому разі – зробити найкращий вибір із деякої кількості альтернатив. Наприклад, до цієї категорії потрапляє задача ідентифікації. Цю модель використовують також системи діагностики, тому що мета системи – поставити найточніший діагноз. Для значної кількості проблем неможливо перерахувати всі ймовірні відповіді до певної задачі. До цієї категорії належать, зокрема, проблеми конфігурації. Наприклад, це можуть бути системи: вибору компонентів комп’ютера; проектування монтажних схем; оптимального розміщення меблів у кімнаті і т. д. Оскільки в цьому випадку вхідні дані дуже різноманітні і їх можна скомбінувати майже нескінченною кількістю способів, зворотне виведення не ефективне. У цьому разі доцільно застосовувати пряме виведення. Системи, які ґрунтуються на прямому виведенні, часто називають продукційними. Система інтерфейсу з користувачем приймає інформацію від користувача й передає йому інформацію. Просто кажучи, система інтерфейсу повинна переконатися, що після того як користувач описав завдання, усю необхідну інформацію отримано. Інтерфейс, ґрунтуючись на виді й природі інформації, уведеної користувачем, передає необхідні дані механізму виведення. Коли механізм виведення повертає знання, виведені з БЗ, інтерфейс передає їх назад користувачу в зручній формі. Інтерфейс із користувачем і механізм виведення можна розглядати як „додаток” до БЗ. Вони разом утворюють оболонку ЕС. Для БЗ, що містить різноманітну інформацію у великому обсязі, можна розробити й реалізувати кілька різних оболонок. Добре розроблені оболонки ЕС звичайно містять механізм для додавання і відновлення інформації в БЗ. В інтерфейсі з користувачем мовою спілкування є обмежена природна мова, а не формальна мова програмування. У ньому можна використовувати всі відомі форми діалогу: · директивна. Словник цієї форми складається з ключових слів природної мови, скорочень, чисел, мнемокодів; · таблична. Складається з таких типів: вибір операції для виконання з меню; заповнення і редагування шаблону; · фразова. Використовує обмежену природну мову. Фразову форму використано в численних існуючих ЕС, але на досить примітивному рівні. Допустимі вхідні повідомлення користувача обмежені набором понять, які містяться в БЗ. Перспективний напрямок становить розробка ЕС, орієнтованих на користувача-нефахівця, який може спілкуватись із системою за допомогою повних речень, що містять будь-які частини мови. Для зменшення часу набору фраз можна застосовувати скорочення, шаблони фраз, запрограмовані клавіші ключових слів і меню. Для обробки фраз застосовують такі види аналізу: · морфологічний (лексичний) – обробка словоформ (відрізок тексту між двома сусідніми пробілами) без зв’язку з контекстом. Виділяють два методи: – декларативний – пошук у словнику всіх можливих словоформ кожного слова. Застосування цього методу уможливлює обробку повідомлень, які складаються з малих і великих літер у довільній комбінації; – процедурний – виділення в поточній словоформі основи з подальшим ідентифікуванням; · синтаксичний – побудова на основі інформації, отриманої після морфологічного аналізу, синтаксичної структури вхідного повідомлення, тобто розбір речення; · семантичний – визначення смислових відношень між словоформами (знаходження головних предикатів). Стосовно цього виду аналізу можна виділити такі функції інтерфейсу: - перетворення природномовної форми повідомлення на форму внутрішнього вигляду і зворотне перетворення; - аналіз і синтез повідомлень користувача й системи; - відстеження й запам’ятовування пройденого шляху.
|
|||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 434; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.59.116.142 (0.01 с.) |