
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели регрессии с фиктивными переменнымиСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
До сих в качестве факторов рассматривались экономические переменные, принимающие количественные значения в некотором интервале. Вместе с тем может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровней. Это могут быть разного рода атрибутивные признаки, таки, например, как профессия, пол, образования, климатические условия, принадлежность к определенному региону. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т.е. качественные переменные должны быть преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называтьфиктивными переменными. Рассмотрим применение фиктивных переменных для функции спроса. Предположим что по группе лиц мужского и женского пола изучается линейная зависимость потребления кофе от цены. В общем виде для совокупности обследуемых уравнение регрессии имеет вид: Аналогичные уравнения могут быть найдены отдельно для лиц мужского пола: Различия в потреблении кофе проявятся в различии средних где
В общем уравнении регрессии зависимая переменная y рассматривается как функция не только цены x, но и пола ( Для лиц мужского пола, когда Фиктивные переменные широко используются для оценки сезонных различий в потреблении. Они могут вводиться не только в линейные, но и в нелинейные модели, приводимые путем преобразования к линейному виду. Прием введения в анализируемую линейную модель регрессии фиктивных переменных используется обычно при работе с неоднородными исходными статистическими данными. Статистическая надежность будет выше. В ходе построения регрессионной модели с фиктивными переменными мы получаем возможность одновременно проверять гипотезы о наличии или отсутствии статистически значимого влияния сопутствующих переменных на структуру анализируемой модели. Однако нельзя рассматривать фиктивные переменные как панацею при применении методов регрессии к неоднородным данным.
69. Понятие временного ряда, его основные компоненты. Задачи изучения временных рядов. Временной ряд – это последовательность наблюдений некоторой величины в последовательные моменты времени. Отдельные наблюдения называются уровнями ряда (Yt), где t число уровней. Составляющие временного ряда Yt=Ut+Vt+Ct+Et: · Ut – трэнд, плавно меняющаяся компонента, описывает длительное изменение величины; · Vt – сезонная компонента, повторяемость экономических процессов в течении не очень долгого периода времени (месяц, год); · Ct – циклическая компонента, повторяемость экономических процессов в течении длительного периода времени; · Et – случайная компонента, отражающая влияние не поддающихся учету случайных факторов. Аддитивные модели представляют собой обобщение множественной регрессии (которая является частным случаем общей линейной модели). Используют операцию сложения (Y=X1+X2+X3). Задачи: 1)выявление и количественное определение перечисленных компонент с тем, чтобы использовать полученную модель для прогнозирования будущих значений ряда 2) построение модели взаимосвязи двух или более временных рядов. 70. мультипликативная и аддитивная модели временного ряда Ввиду четкой интерпретации параметров уравнения наиболее широко используются линейные и степенные функции. Если линейная модель является аддитивной, это означает, что в основе модели лежит гипотеза о том, что каждый фактор что-то добавляет или отнимает от значения результативного признака. Например, если у – это урожайность сельскохозяйственной культуры, а х1, х2 и х3 – агротехнические факторы: дозы удобрений, число прополок, поливов и т.п., то каждый из этих факторов либо повышает, либо понижает величину урожайности, причем последняя могла бы существовать и без этих факторов.
Также часто линейная регрессионная модель используется в функциях потребления (спроса), где у – потребление товара или группы товаров, а факторами могут быть доход семьи в текущем и предшествующем периоде, размер семьи, цены, прошлые привычки потребления, то есть потребление товара в предшествующем периоде. Параметр а в таком уравнении не подлежит экономической интерпретации, а коэффициенты регрессии рассматриваются как характеристики склонности к потреблению. Например, функция потребления имеет вид Пt= a +b1Dt + b2Dt-1 (5.1.6) где потребление в период времени t зависит от дохода того же периода Dt и от дохода предшествующего периода Dt-1. Коэффициент в1 называют краткосрочной предельной склонностью к потреблению. Он показывает, на сколько увеличится потребление товара при увеличении доходов текущего периода на единицу. Общим эффектом возрастания как текущего, так и предыдущего дохода будет рост потребления на величину b = b1 + b2. Коэффициент в рассматривается здесь как долгосрочная склонность к потреблению. Пример: П (потребление) = 38 + 0,47Дт +0,23Дт-1. Краткосрочная склонность к потреблению составляет здесь 0,47, а долгосрочная склонность 0,47+0,23=0,7. Однако аддитивная модель пригодна не для любых связей в экономике. Если, например, изучается зависимость объема продукции предприятия от занимаемых площадей, числа работников, стоимости основных фондов (или всего капитала), то каждый из факторов является необходимым для существования результата, а не добавлением к нему. В таких ситуациях нужно исходить из гипотезы о мультипликативной форме модели:
Такая модель по ее первым создателям получила название модель Кобба-Дугласа. Это степенная функция и, как мы уже знаем, показатели степени при факторах являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1 процент при неизменности других факторов. Решение степенной функции методом наименьших квадратов требует предварительной ее линеаризации. Как было рассмотрено ранее (лекция 4), линеаризация степенных функций проводится с помощью логарифмирования ее переменных. 71 и 72 не нашла! 71. Определение сезонной компоненты в мультипликативной и аддитивной моделях Аддитивной моделью временного ряда называется такая модель, где уровни ряда представлены как сумма трендовой (Т), сезонной или циклической (S) и случайной (Е) компонент: уt=Т+S+Е. Построению аддитивной модели обычно предшествует анализ структуры временного ряда, то есть определение наличия или отсутствия этих компонент в ряду динамики. Для этих целей строят автокорреляционную функцию. Если коэффициент автокорреляции первого порядка существенно отличен от нуля, то в ряду динамики есть тенденция, если самым высоким оказался коэффициент автокорреляции порядка k, то в ряду есть цикличность в k периодов времени. Построение аддитивной модели сводится к количественному определению указанных компонент для каждого уровня ряда, определению прогнозных уровней как 73. Моделирование тенденции временного ряда. Выбор лучшей формы тренда
Один из наиболее распространенных способов моделирования тенденции временного ряда – это подбор и решение математического уравнения, которое бы отражало зависимость уровней ряда от фактора времени. Такие функции называются трендами, а способ построения такой функции – это способ аналитического выравнивания временного ряда. Зависимость от времени может принимать разные формы, поэтому, как и в случае регрессионных уравнений, для построения трендов могут быть выбраны разные функции: линейный тренд гипербола экспонента степенная функция парабола Параметры таких функций могут быть определены обычным МНК. Параметризация нелинейных трендов требует предварительной их линеаризации. Как определить форму тренда? Существует несколько способов решения этой проблемы. Самый простой способ – это визуальный анализ графика зависимостей уровней ряда от времени. Второй способ – это определение основных показателей динамики. Если цепные абсолютные приросты для всего ряда примерно равны друг другу, то это линейный тренд; если примерно равны друг другу цепные коэффициенты роста, то функция может быть степенной или показательной. Третий способ определения формы тренда – это анализ коэффициентов автокорреляции. Если временной ряд имеет линейную тенденцию, то его соседние уровни тесно коррелированны, и в этом случае коэффициент автокорреляции первого порядка должен быть очень высокий. Если есть подозрение на существование нелинейной зависимости, то следует прологарифмировать исходный ряд данных и определить коэффициент автокорреляции первого порядка по логарифмам уровней. Чем сильнее выражена нелинейная тенденция, тем выше будет автокорреляция логарифмов по сравнению с автокорреляцией исходных данных. Если форму связи всеми перечисленными способами определить достаточно трудно, то перебирают все основные формы трендов, учитывая при этом соотношение числа наблюдений и числа определяемых параметров. Для каждого уравнения определяют коэффициент детерминации и выбирают уравнение с максимальным его значением (экспериментальный способ). Реализация этого метода предполагает компьютерную обработку данных. Наиболее простую экономическую интерпретацию имеют параметры линейного и показательного трендов. Параметры линейного тренда
Уравнение показательного тренда имеет вид Если форма тренда описывается параболой, то качественный анализ такого тренда предполагает определение поворотных точек в динамике, замедления или ускорения темпов изменения, начиная с определенного момента времени под влиянием ряда факторов. В случае, если уравнение тренда выбрано неверно, то результаты анализа и прогнозирования динамики временного ряда с использованием выбранного уравнения будут недостоверными вследствие ошибок спецификации. Для оценки пригодности уравнения тренда для прогноза, также как и для регрессионной модели, может быть рассчитана средняя ошибка аппроксимации
Если ее величина не превышает 8-10%, то уравнение тренда может быть использовано в прогнозировании будущих значений результативного признака.
74. Моделирование тенденции при наличии структурных изменений. Критерий Чоу Метод аналитического сглаживания для выявления тенденции в рядах динамики применим только для качественно однородных периодов. Если в момент (период) времени t* происходили серьезные изменения среды формирования изучаемого показателя (начало крупных экономических реформ, смена политического и экономического курсов, экономические кризисы и т.д.), то необходимо выяснить повлияли ли общие структурные изменения на характер тенденции ряда. И если ряд содержит структурные изменения, то выявлять тенденцию следует по подпериодам: до t* и после t*. Для оценки возможности построения тренда по данным всего ряда без разбиения на подпериоды используется тест Чоу. Выдвигается гипотеза о том, что вектор оценок параметров (т.е. оценки всех параметров) тренда по первому подвериоду равен вектору по второму подпериоду, также о равенстве остаточных дисперсий отклонений от линий трендов по этим подпериодам: Н0: Тест Чоу:
Выбор формы тренда можно осуществить с помощью теста на различие в остаточных дисперсиях:
Критическое значение находят при выбранном уровне значимости ( В случае выполнения неравенства делается заключение о том, что различия в дисперсиях существенны и функция, которой соответствует меньшая дисперсия, действительно лучше аппроксимирует исходные значения, и именно она выбирается для описания тенденции. Иначе, предпочтение отдается более простой функции. Необходима оценка существенности уравнения тренда и его параметров в силу того, что сам временной ряд рассматривается как выборка – одна из возможных реализаций случайного процесса. Средняя ошибка прогноза линейного тренда рассчитывается по формуле: 75. Автокорреляция уровней временного ряда. Автокорреляционная функция и ее применение при выявлении структуры ряда
Если временной ряд содержит только случайную компоненту, то уровни временного ряда будут независимы друг от друга. Если же временной ряд содержит тенденцию или циклические колебания, то значения каждого последующего уровня зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда. Автокорреляцию можно измерить количественно. Для этого рассчитывают линейный коэффициент корреляции между уровнями исходного временного ряда и уровнями этого же ряда, сдвинутыми на один или несколько шагов во времени. Например, разумно предположить, что доходы домохозяйства в текущем году зависят от доходов домохозяйства предыдущих лет. Определим коэффициент корреляции между ними. Известна рабочая формула линейного коэффициента корреляции
В качестве фактора мы рассмотрим доходы предшествующего периода (уt-1), а в качестве результата – доходы текущего периода (уt), тогда приведенная выше формула примет вид
где а Расстояние между уровнями временного ряда, для которых определяется коэффициент корреляции, называется лагом. Приведенная выше формула определяет величину автокорреляции между соседними уровнями, то есть при лаге = 1, поэтому этот коэффициент называют коэффициентом автокорреляции первого порядка. Допустим, r1 = 0,98. Полученное значение свидетельствует об очень сильной зависимости между доходами текущего и предшествующего периода и, следовательно, о наличии в ряду сильной линейной тенденции. Аналогично можно определить коэффициенты автокорреляции второго и более высоких порядков. Коэффициент автокорреляции второго порядка характеризует тесноту связи между уровнями со сдвигом на две даты, то есть с лагом 2 и т.д. С увеличением лага число пар, по которым рассчитывается коэффициент автокорреляции, уменьшается и, следовательно, снижается достоверность коэффициентов. Поэтому для обеспечения статистической достоверности лаг не должен быть больше, чем п / 4, где п – число уровней. При анализе коэффициентов автокорреляции следует помнить следующее: 1) он определяется по формуле линейного коэффициента корреляции, таким образом, он измеряет тесноту только линейной связи текущего и предыдущего уровней временного ряда. Для временных, рядов, имеющих сильную нелинейную тенденцию, коэффициент автокорреляции уровней может быть близким к нулю; 2) Знак коэффициента автокорреляции не указывает на направление тенденции в исходном ряду данных (возрастание или убывание). Большинство временных рядов экономических переменных содержат положительную автокорреляцию уровней, но при этом сам ряд может иметь и отрицательную тенденцию.
Если расположить коэффициенты по величине лага (то есть коэффициенты первого порядка, второго, третьего и т.д.), то мы получим автокорреляционную функцию временного ряда. График зависимости величины коэффициента автокорреляции от лага называют коррелограммой.
76. Моделирование взаимосвязей между признаками на основе рядов динамики. Методы исключения тенденции Изучение взаимосвязи экономических переменных по данным временных рядов осложнено тем, что в этих рядах может быть тенденция. Если в ряду динамики переменной у и в ряду динамики х есть компонента «Т», то в результате мы получим тесную связь между у и х. Однако из этого факта еще нельзя делать вывод о том, что изменение х есть причина изменения у, то есть что между этими изменениями есть причинно-следственная связь. Например, за последние 10 – 15 лет в Российской Федерации сократилось поголовье КРС и увеличилось число крестьянских (фермерских) хозяйств. Коэффициент корреляции между уровнями этих рядов динамики высок по величине; знак указывает на обратную связь. Однако это не означает, что рост численности фермерских хозяйств явился фактором снижения поголовья. Чтобы выявить причинно-следственную зависимость между переменными, необходимо устранить ложную корреляцию между ними, вызванную наличием тенденции. Существует несколько способов исключения тенденции в рядах динамики. Первый способ называется метод отклонений от тренда. Пусть имеется уt=Т + е и х t=Т + е. Проводится аналитическое выравнивание каждого ряда:
Второй способ преодоления тенденции в рядах динамики – это метод последовательных разностей. Если временной ряд содержит ярко выраженную линейную тенденцию, то для ее устранения можно заменить исходные уровни разностями первого порядка, то есть цепными абсолютными приростами: Доказательство
Мы видим, что величина Недостатком второго способа является потеря информации (приростов на единицу меньше, чем уровней), что в условиях малого числа наблюдений крайне нежелательно. Достоинством является возможность интерпретации параметров. Коэффициент регрессии b покажет изменение прироста результата при единичном изменении прироста фактора. Третьим способом является включение в модель регрессии фактора времени: yt= a+b1x1+ b2 t. В данном случае коэффициенты чистой регрессии легко интерпретируются, имеют естественные единицы измерения. Коэффициент b1 покажет на сколько единиц изменится результат при единичном изменении фактора при условии существования неизменной тенденции; коэффициент b2 отразит влияние всех прочих факторов, формирующих тенденцию, кроме x1. Однако данный способ построения регрессионной модели требует большего объема наблюдений, так как в модели появляется еще один параметр. Если тренды признаков являются экспонентами (или показательными функциями), то вместо корреляции абсолютных отклонений от трендов можно применить метод корреляции цепных темпов роста уровней, поскольку именно темпы роста – основной параметр экспоненциальных и показательных трендов.
77. Понятие автокорреляции остатков. Статистика Дарбина-Уотсона При моделировании временных рядов встречаются ситуации, когда остатки содержат тенденцию или цикличность. В этом случае остатки не являются независимыми, каждое последующее значение остатка зависит от предыдущего. Это явление получило название автокорреляция остатков. Существуют два способа определения автокорреляции в остатках. Первый заключается в визуальном анализе графика зависимостей остатков от времени. Второй способ предполагает использование критерия Дарбина-Уотсона. Величину критерия (d) можно определить по одной из формул
либо d где re1 – коэффициент автокорреляции остатков первого порядка. Если в остатках существует полная положительная автокорреляция, то re1 =1 и d = 0. Если в остатках полная отрицательная автокорреляция, то re1 =-1 и d = 4. Если автокорреляция остатков отсутствует, то re1 =0 и d = 2. На практике используется следующий алгоритм проверки гипотезы об автокорреляции остатков: 1. выдвигается нулевая гипотеза об отсутствии автокорреляции в остатках; 2. 2 определяется фактическое значение критерия Дарбина – Уотсона (d); 3. по специальным таблицам (приложение учебника по эконометрике) находят критические значения критерия dL и du, где п – число наблюдений, k - независимых переменных в модели, 4. числовой промежуток всех возможных значений d разбивается на 5 отрезков
0 d L d u 2 4- d u 4 - d L 4
5. если d- фактическое попадает в зону неопределенности, то предполагают существование автокорреляции в остатках. В последнем случае исследовать причинно-следственные связи переменных по остаткам нельзя, получим ложную корреляцию.
78. Понятие системы эконометрических уравнений, основные виды Для описания реальных экономических систем, где статистические показатели находятся во взаимодействии и взаимосвязи, применяются системы эконометрических уравнений. В данных системах случайные переменные называют эндогенными, т.е. внутренними, так как они формируют свои значения внутри модели. Признаки, считающиеся заданными, известными, неслучайными получили название экзогенных, или внешних для данной системы. Один и тот же признак может быть эндогенным в одной задаче и экзогенным – в другой. Структурная форма модели:
Структурная форма модели содержит при эндогенных переменных коэффициенты
Поэтому свободные члены в системе отсутствуют. Приведенная форма модели:
79. Структурная и приведенная форма модели. Проблема идентификации. Необходимое и достаточное условия идентификации Для описания реальных экономических систем, где статистические показатели находятся во взаимодействии и взаимосвязи, применяются системы эконометрических уравнений. В данных системах случайные переменные называют эндогенными, т.е. внутренними, так как они формируют свои значения внутри модели. Признаки, считающиеся заданными, известными, неслучайными получили название экзогенных, или внешних для данной системы. Один и тот же признак может быть эндогенным в одной задаче и экзогенным – в другой. Структурная форма модели:
Структурная форма модели содержит при эндогенных переменных коэффициенты
Поэтому свободные члены в системе отсутствуют. Приведенная форма модели:
При переходе от приведенной к структурной форме возникает проблема идентификации, то есть однозначности определения параметров структурной модели от приведенной формы. Переход необходим, поскольку экономический смысл и интерпретацию имеют только параметры структурной формы. Условия идентифицируемости проверяются для каждого уравнения в отдельности. Счетное (необходимое) условие идентифицируемости: Чтобы уравнение было идентифицируемым, нужно, чтобы:
1+nx=ny, где nx – число экзогенных переменных, содержащихся в системе, но отсутствующих в данном уравнении системы; ny – число эндогенных переменных в данном уравнении. Если 1+nx<ny, уравнение неидентифицируемо; 1+nx>ny, то уравнение сверхидентифицируемо.
Ранговое условие идентифицируемости (достаточное): Для разрешимости системы структурных уравнений достаточно, чтобы ранг матрицы, составленной из коэффициентов эндогенных и экзогенных переменных, отсутствующих в данном уравнении, но присутствующих в других уравнениях системы, был не меньше, чем число эндогенных переменных в системе без одного, а определитель этой же матрицы не был равен нулю. 80. Косвенный метод наименьших квадратов В системе рекурсивных уравнений хоты бы одна эндогенная переменная должна определятся только лишь набором независимых переменных. Если все эндогенные переменные расположены в левой части, а экзогенные – в левой, то такая система называется системой независимых уравнений. Для решения систем независимых и рекурсивных переменных используется метод наименьших квадратов. Препятствие к применению метода наименьших квадратов, которое заключается в коррелированности эндогенных переменных со случайными членами легко преодолеть, если: 1) привести систему к виду, чтобы в правой части оставались только экзогенные переменные. Такая форма называется приведенной; 2) затем применить метод наименьших квадратов к каждому уравнению в приведенной форме и получить оценки ее параметров; 3) перейти от приведенной формы к структурной, проведя процедуру обратного преобразования параметров. Эта методика получила название косвенного метода наименьших квадратов и позволяет получать состоятельные и несмещенные оценки параметров структурной форму системы одновременных уравнений. 81. Двушаговый МНК Двухшаговый МНК является универсальным, позволяет решать как точно идентифицируемые, так и сверхидентифицируемые системы структурных уравнений. Значимость этого метода определяется тем, что он позволяет решать сверхидентифицируемые системы, оценить которые косвенным методом нельзя. Сверхидентифицируемые системы бывают двух типов: · все уравнения системы сверхидентифицируемы; · система содержит наряду со сверхидентифицируемыми точно идентифицируемые уравнения. Для второго типа в отношении идентифицируемых уравнений может применяться косвенный МНК, для сверхидентифицируемых уравнений и систем, где все уравнения сверхидентифицируемы, следует применять двухшаговый МНК. Двухшаговый МНК реализуется в следующей последовательности: 1) сначала нужно привести систему к приведенной форме; 2) затем применить МНК к каждому уравнению в приведенной форме и получить оценки ее параметров; 3) находят расчетные значения эндогенных переменных, подставляя значения экзогенных переменных в соответствующие приведенные уравнения по всем единицам совокупности. 4) подставляют в структурную форму фактические значения экзогенных переменных и тех эндогенных переменных, которые находятся в левой части, и расчетные значения эндогенных переменных, находящихся в правой части системы, а затем применяют метод наименьших квадратов. Замена фактических значений эндогенных переменных, находящихся в правой части системы, решает проблему их коррелированности с ошибками регрессии. Двухшаговый метод наименьших квадратов дает такие же оценки, как и косвенный метод. Для оценки надежности параметров структурной формы может применяться дисперсионный анализ. Проверку значимости целесообразно проводить еще на стадии получения системы приведенных уравнений. Продолжать реализацию косвенного и двухшагового методов следует лишь в случае получения значимых приведенных уравнений.
82. Модель Кейнса. Инвестиционные мультипликаторы потребления и национального дохода. Наиболее широко системы одновременных уравнений применяются для моделирования макроэкономики. Большинство из них построено на основе кейнсианских моделей. Статическая модель Кейнса для описания народного хозяйства страны в наиболее простом варианте имеет следующий вид (в современных показателях системы национального счетоводства России):
где С – конечное потребление в постоянных ценах; у – валовой располагаемый национальный доход (ВРНД) в постоянных ценах;
I – валовые инвестиции в постоянных ценах (валовое сбережение).
Второе уравнение является тождеством, поэтому структурный коэффициент b не может быть больше 1. Он характеризует предельную склонность к потреблению. Система приведенных уравнений:
Приведенная форма модели содержит мультипликаторы: - инвестиционный мультипликатор потребления:
- инвестиционный мультипликатор национального дохода:
Мультипликаторы интерпретируются как коэффициенты линейной регрессии, т.е. они показывают, на сколько единиц изменится эндогенная переменная, если экзогенная переменная изменится на единицу.
|
||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-06; просмотров: 808; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.23.103.14 (0.018 с.) |

 где y – количество потребляемого кофе, x – цена.
где y – количество потребляемого кофе, x – цена.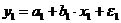 и женского пола:
и женского пола: 
 и
и  . Вместе с тем сила влияния x на yможет быть одинаковой, т.е.
. Вместе с тем сила влияния x на yможет быть одинаковой, т.е.  В таком случае возможно построение общего уравнения регрессии с включением в него фактора «пол» в виде фиктивной переменной.
В таком случае возможно построение общего уравнения регрессии с включением в него фактора «пол» в виде фиктивной переменной. 
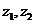 - это фиктивные переменные, принимающие значения:
- это фиктивные переменные, принимающие значения:
 , то
, то  и, наоборот, при
и, наоборот, при  переменная
переменная 
 а для лиц женского пола, когда
а для лиц женского пола, когда 
 Иными словами, различия в потреблении для лиц мужского и женского пола вызваны различиями свободных членов уравнения регрессии:
Иными словами, различия в потреблении для лиц мужского и женского пола вызваны различиями свободных членов уравнения регрессии: 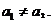 Параметр b является общим для всей совокупности лиц, как для мужчин, так и для женщин.
Параметр b является общим для всей совокупности лиц, как для мужчин, так и для женщин. (5.1.7)
(5.1.7) t=Т+S и оценке качества модели.
t=Т+S и оценке качества модели.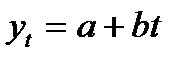 ;
;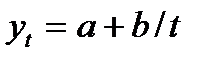 ;
; , где е = 2,71828;
, где е = 2,71828; ;
; и другие.
и другие. . Параметр а – начальный уровень временного ряда в момент времени t = 0, а показатель степени t - это средний за единицу времени коэффициент роста уровней ряда.
. Параметр а – начальный уровень временного ряда в момент времени t = 0, а показатель степени t - это средний за единицу времени коэффициент роста уровней ряда. (%) (6.1.3)
(%) (6.1.3) .
. , где р – число параметров без свободного члена,
, где р – число параметров без свободного члена, 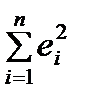 - остаточная сумма квадратов при построении тренда по всей совокупности.
- остаточная сумма квадратов при построении тренда по всей совокупности.  ,
,  - остаточные суммы квадратов для первого и второго подпериодов.
- остаточные суммы квадратов для первого и второго подпериодов. .
.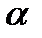 ) и числе степеней свободы для большей (
) и числе степеней свободы для большей ( ) и меньшей (
) и меньшей ( ) из двух дисперсий.
) из двух дисперсий. .
. (6.1.1)
(6.1.1)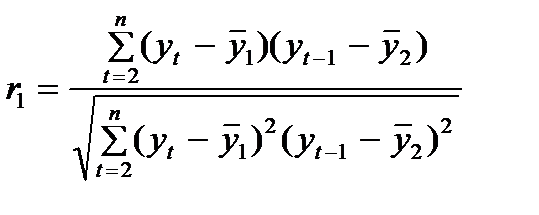
 - средний уровень по исходному ряду динамики, определенный без учета первого уровня,
- средний уровень по исходному ряду динамики, определенный без учета первого уровня, - это средний уровень по ряду динамики, сдвинутому на одну дату.
- это средний уровень по ряду динамики, сдвинутому на одну дату. и
и  , где Ту и Тх – это оценки трендовых компонент. Затем определяется остаток в каждом наблюдении
, где Ту и Тх – это оценки трендовых компонент. Затем определяется остаток в каждом наблюдении  и
и , так как остаточная компонента не содержит тенденции. Далее изучается зависимость между самими остатками еу=f(ех). Если между переменными есть связь, то она проявится в согласованном изменении остатков. Недостатком данного способа является то, что содержательная интерпретация параметров такой модели затруднительна. Однако модель может быть использована для прогнозов и, кроме того, коэффициент парной корреляции между остатками отразит связь переменных.
, так как остаточная компонента не содержит тенденции. Далее изучается зависимость между самими остатками еу=f(ех). Если между переменными есть связь, то она проявится в согласованном изменении остатков. Недостатком данного способа является то, что содержательная интерпретация параметров такой модели затруднительна. Однако модель может быть использована для прогнозов и, кроме того, коэффициент парной корреляции между остатками отразит связь переменных. и
и  . Далее прирост у рассматривается как функция прироста х:
. Далее прирост у рассматривается как функция прироста х:  . Рассмотрим математическое доказательство исключения тенденции в этом случае.
. Рассмотрим математическое доказательство исключения тенденции в этом случае. исключает фактор времени, так как b – константа, а остатки по предпосылкам МНК не должны содержать тенденции, то есть должны быть случайными и независимыми.
исключает фактор времени, так как b – константа, а остатки по предпосылкам МНК не должны содержать тенденции, то есть должны быть случайными и независимыми.
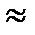 2(1 – re1)
2(1 – re1)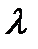 - уровень значимости;
- уровень значимости;
 , экзогенных переменных –
, экзогенных переменных –  , которые называются структурными коэффициентами модели. Все переменные в модели выражены в отклонениях от среднего уровня:
, которые называются структурными коэффициентами модели. Все переменные в модели выражены в отклонениях от среднего уровня:

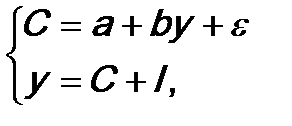
 – случайная составляющая;
– случайная составляющая;
 ;
; .
.


