
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Математическая обработка экспериментальных данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Математические методы представляют совокупность алгоритмов, основанных на теоретических положениях и идеях определенного раздела математики и позволяющих осуществить комплексный анализ тех или иных закономерностей и отношений. Применение математических методов в инженерной психологии развивается, как уже отмечалось, по трем основным направлениям:
■ математическая обработка экспериментальных данных; ■ математическое моделирование деятельности оператора; ■ вычисление количественных значений инженерно-психологических показателей.
Во многих случаях основным способом вычисления последних является обработка экспериментальных данных или моделирование, поэтому это направление в данном разделе специально не рассматривается. Способы вычисления этих показателей рассматриваются при изучении соответствующих вопросов. Применение математических методов связано с прогрессом вычислительной техники, применением ЭВМ в инженерно-психологических исследованиях. Эта связь наиболее ярко проявляется при автоматизации обработки результатов эксперимента, применении имитационных моделей деятельности оператора, производстве различного рода вычислений. Основными задачами математической обработки экспериментальных данных являются: определение характеристик случайных величин и событий, сравнение между собой их вычисленных значений, построение законов распределения случайных величин, установление зависимости между полученными случайными величинами, анализ случайных процессов. Эти вопросы подробно излагаются в специальной литературе [112, 128, 177]. Здесь же представляется целесообразным рассмотреть лишь особенности и возможности применения их при решении инженерно-психологических задач. Основными характеристиками случайных величин являются их математическое ожидание и дисперсия, а случайных событий — вероятность их наступления. Математическое ожидание характеризует среднее значение наблюдаемой случайной величины (например, времени реакции, погрешности измерений, числа ошибок, допущенных человеком при выполнении работы и т. п.), а дисперсия является мерой рассеивания ее значений относительно среднего значения. Выборочные (опытные) значения математического ожидания и дисперсии вычисляются соответственно по формулам
где хi — наблюденное значение случайной величины, n — объем выборки (число наблюдений). Квадратный корень из дисперсии, т. е. величина, Сравнение между собой одноименных характеристик нескольких выборок проводится потому, что в силу ограниченного объема выборки полученные различия между характеристиками случайных величин (математическими ожиданиями, дисперсиями и др.) может быть случайным и не всегда означает, что эти величины различны на самом деле. Проверку этого факта, т. е. проверку статистических гипотез, нужно проводить с помощью непараметрических и параметрических критериев согласия. В первом случае используются не сами значения наблюдаемых величин, а только их упорядоченность (для каждой пары сравниваемых величин известно, какая из них больше), т. е. критерии, не зависящие от параметров распределения. Такие критерии весьма удобны для практического использования, так как требуют минимального объема вычислений и априорных сведений и могут использоваться даже при невозможности прямых измерений изучаемых признаков. Такие случаи встречаются, например, при проверке степени различия индивидуальных качеств двух групп операторов в случае, если эти качества не могут быть количественно определены. Основными из непараметрических критериев согласия являются критерий знаков, критерий Смирнова и критерий Вилконсона. При использовании параметрических критериев вычисляются значения параметров сравниваемых распределений. Это усложняет процедуру сравнения, однако позволяет получить более точные результаты. Основными из параметрических критериев являются критерий Фишера, критерий Стьюдента и критерий x2. Критерий Фишера используется для проверки статистических гипотез о равенстве дисперсий двух выборок. Он применяется в тех прикладных задачах, где необходимо исследовать стабильность изучаемых величин. Например, он может быть использован для сравнения рассеяний ошибок двух операторов, разбросов оценок экспертов, полученных по разным методикам, однородности латентных периодов времени реакции в различных экспериментах и т. п. Критерий Стьюдента применяется для проверки значимости различия между двумя средними значениями, критерий x2 служит для сравнения двух распределений, для проверки согласия эмпирического распределения с одним из теоретических. Одним из способов проверки статистических гипотез является последовательный анализ. Он применяется в том случае, когда число наблюдений в исследовании не устанавливается заранее, а является случайной величиной. Особенность последовательного анализа состоит в том, что после осуществления каждого наблюдения принимается одно из следующих решений: принять проверяемую гипотезу, отвергнуть ее, продолжать испытания. Прикладные задачи исследования, в которых применяется последовательный анализ, могут быть теми же, что и в случае проверки гипотез по выборкам заданной длины, но при этом возможна существенная экономия в длительности эксперимента. В инженерной психологии последовательный анализ широко используется, например, при оценке результатов деятельности оператора. С его помощью определяется то число опытов (решаемых оператором учебных задач), по выполнении которых оператору с заданной достоверностью выставляется оценка «зачет» или «незачет».
Процедура последовательного анализа сводится к следующему. На каждом шаге испытаний после каждого опыта фиксируется число dn благоприятных исходов среди проведенных п наблюдений. По известным формулам [15], зная заданные вероятности ошибок первого и второго рода, определяются значения оценочных границ аn и rn. В системе координат (dn, n) строятся две параллельные прямые гп (п) и ап (п), имеющие одинаковый угловой коэффициент (рис. 8.1). Точки (dn, n) наносятся на график по ходу контроля, и эксперимент проводится до тех пор, пока очередная точка не выйдет за пределы полосы, заключенной между прямыми ап и гп. Если dn<an, то оператор получает «незачет», если
Рис. 8.1. Схема проведения последовательного анализа
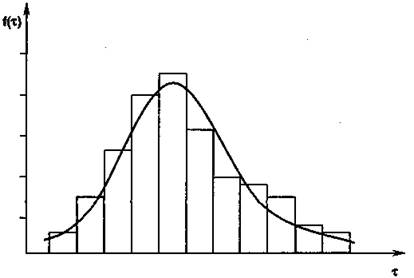
dn>rn— «зачет». В случае, если an<dn<rn, то проверка продолжается. Применение последовательного анализа позволяет существенно уменьшить объем исследования по сравнению с традиционным методом фиксированной однократной выборки. Построение законов распределения позволяет наиболее полно и точно описать изучаемую случайную величину, полученную в результате проведения инженерно-психологического наблюдения или эксперимента. Для построения закона распределения предварительно строится гистограмма (от греч. histos — столб и gramma— запись). Она является одним из способов графического представления количественных данных в виде прямоугольных столбиков, примыкающих друг к другу, высота которых соответствует частоте каждого класса данных. Для построения гистограммы интервал, в котором сосредоточены наблюдения, делится на n подынтервалов (разрядов) и подсчитывается число наблюдений, значения которых соответствует данному разряду. На основании этих данных и строится гистограмма, которая представляет собой кусочно-непрерывную функцию, которая в пределах данного разряда равна числу (частоте) наблюдений, попавших в него. Наиболее часто гистограмму практически применяют в качестве плотности распределения случайной величины, по наблюдениям которой она построена. Различают одномерные и многомерные (в частности, двумерные) законы распределения. Одномерный закон показывает, как часто в изучаемой совокупности встречаются опыты с данным значением изучаемой случайной величины. Закон распределения можно изобразить графически (рис. 8.2), либо описать той или иной аналитической зависимостью. Его пик приходится на наиболее вероятное (наиболее распространенное) значение случайной величины. Примерами такого закона являются, в частности, распределения значений тех или иных антропометрических показателей. Двумерный закон учитывает совместное распределение двух количественных показателей, например, числа ошибок и времени решения задач оператором [35]. В инженерной психологии наиболее часто применяется нормальный, экспоненциальный, биноминальный законы распределения, альфа- и гамма- распределения, распределение Пуассона и др. Соответствие между опытным
Рис. 8.2. Гистограмма и сглаживающая ее теоретическая функция распределения (пример).
и теоретическим распределениями проверяется с помощью критериев согласия x2 или Колмогорова. При этом следует иметь в виду, что одно и то же опытное распределение может дать положительный результат при сравнении не с одним, а с несколькими теоретическими распределениями. Такое обстоятельство имеет место, например, при изучении времени реакции оператора [182]. В таких случаях следует опираться не только на результаты формальной проверки с помощью критериев согласия, а изучать прежде всего психологическую сущность и условия применимости того или иного закона распределения. Для определения связи между двумя и более переменными используются такие методы статистического анализа, как корреляционный, регрессионный, дисперсионный, факторный и др. Корреляционный анализ служит для установления вида, знака и тесноты связи между двумя или несколькими случайными переменными. В первом случае используют коэффициент парной корреляции, во втором — коэффициент множественной корреляции. Примером использования корреляционного анализа в инженерной психологии является, в частности, проверка прогностической валидности психоди- агностических тестов. Мерой валидности является в этом случае коэффициент корреляции оценок испытуемых по психофизиологическим методикам с оценками их профессиональной деятельности (т. е. с внешним критерием). Однако всегда следует помнить, что при интерпретации результатов корреляционного анализа необходима особая осторожность при учете статистически достоверных высоких корреляций: иногда могут возникнуть ложные корреляции за счет того, что обе изучаемые переменные испытывают сильное влияние третьего, не учтенного при наблюдении фактора. Для более углубленного изучения сопряженности количественных показателей в исследуемой совокупности объектов служит регрессионный анализ. Регрессия (от лат. regressio — движение назад), выражаемая либо графически, либо аналитически, показывает как в среднем изменяется изучаемый показатель при изменениях какого-то фактора (факториального показателя). Так же как и корреляция, регрессия может быть парной, либо множественной. В общем случае процедура регрессивного анализа (на примере парной регрессии) сводится к следующему. Пусть есть основания полагать, что изучаемые случайные величины х и у связаны некоторым соотношением. Тогда задача его описания распадается на установление общего вида зависимости и вычисление оценок его параметров. Стандартных методов выбора общего вида кривой не существует: здесь необходимо сочетать визуальный анализ корреляционного поля с качественным анализом природы переменных. Методы оценки параметров наиболее хорошо разработаны для линейных зависимостей, основным из них является метод наименьших квадратов. В общем виде уравнение множественной линейной регрессии имеет вид
где а0 и аi — неизвестные коэффициенты, определяемые методом наименьших квадратов; xi — исследуемые психологические показатели; n — число учитываемых показателей. При п = 1 выражение (8.2) превращается в уравнение парной регрессии. Выражения типа (8.2) называются также регрессионными моделями. В заключение отметим, что регрессия показывает лишь как изменяется изучаемый показатель в зависимости от изменения факторных показателей, но она ни в коем случае не показывает причинно-следственных связей между показателями. При изучении трудовой деятельности часто приходится оценивать достоверность и степень влияния какого-либо фактора (или факторов) на изменение величины некоторого показателя деятельности человека по сравнению со случайными причинами (например, случайным изменением значений изучаемого показателя от опыта к опыту). Эффективным методом решения подобных задач является дисперсионный анализ. В зависимости от числа факторов, влияние которых исследуется, дисперсионный анализ подразделяется на одно-, двух-, трех- и т. д. факторный. При проведении дисперсионного анализа вся совокупность экспериментальных данных разбивается на группы по градациям факторов. Градации могут различаться либо качественно, либо количественно по степени действия фактора. Так, при изучении влияния космического полета на психофизиологические показатели космонавта в дисперсионный комплекс были включены такие факторы, как условия работы космонавта с двумя градациями (полетные условия, земные условия); индивидуальность космонавта, каждую градацию которой представлял конкретный человек [137]. Значимость влияния фактора оценивается с помощью критерия согласия Фишера, представляющего в данном случае отношение факториальной (межгрупповой) дисперсии к случайной (внутригрупповой). Если различие между этими дисперсиями оказывается значимым, то и действие фактора на исследуемый показатель деятельности человека оказывает существенное влияние. Для исследования статистически связанных признаков с целью установления определенного числа скрытых от наблюдения факторов используют факторный анализ. С его помощью устанавливается связь изменения одной переменной (например, показателя деятельности оператора) с изменением другой переменной и определяются основные факторы, лежащие в основе указанных изменений. Несколько реже по сравнению с рассмотренными при математической обработке данных в инженерной психологии используются латентный и кластерный анализы. Многие из изучаемых в инженерной психологии процессов носят вероятностный характер и поэтому описываются случайными функциями. Примером их является большинство электрофизиологических показателей, рассмотренных в главе VII: ЭЭГ, ЭКГ, ЭМГ, ЭОГ и др. Математическая обработка экспериментальных данных заключается в этом случае в вычислении основных характеристик данной случайной функции по ее отдельным реализациям, зарегистрированным в ходе эксперимента. Важной задачей при этом является установление таких свойств случайного процесса, как стационарность (постоянство основных характеристик во времени) и эргодичность (совпадение математических ожиданий и других характеристик для всех имеющихся реализаций данной случайной функции). Для анализа стационарных процессов применяется спектральный анализ. Свойство эргодичности позволяет выявить все характеристики данной случайной функции по одной достаточно длинной реализации, в то время как характеристики не эргодических процессов возможно определить лишь при достаточно большом числе реализаций. В инженерной психологии, как правило, экспериментальному изучению подвергается не вся генеральная совокупность, а только часть ее — выборка; т. е. группа испытуемых, представляющих определенную популяцию и отобранных для эксперимента или наблюдения. На основании полученных характеристик выборки делаются выводы о генеральной совокупности. Практически любое статистическое исследование в инженерной психологии основано на анализе свойств и характеристик определенной выборки. Ее объем определяется двумя противоречивыми условиями. С одной стороны, она должна быть достаточно большой, чтобы правильно отразить все свойства генеральной совокупности. С другой стороны, она не должна быть чрезмерно большой, чтобы была реальная возможность ее изучения. Поэтому результаты математической обработки экспериментальных данных для выборки (вследствие случайного отбора в нее объектов из генеральной совокупности) могут отличаться от соответствующих характеристик генеральной совокупности. В связи с этим необходимо оценить достоверность полученных результатов, т. е. возможность их распределения на всю генеральную совокупность. Для оценки достоверности пользуются принципом практической уверенности. Он состоит в том, что достоверным считают событие, имеющее достаточно большую, близкую к единице, вероятность. Такая вероятность называется доверительной. Величина, дополняющая ее до единицы, называется уровнем значимости. Он представляет собой вероятность того, что заключение, принятое достоверным, на самом деле окажется ошибочным. Общепринятыми считаются три уровня значимости: 0,05 —- для обычных исследований, 0,01 — для важных исследований, 0,001 — для особо важных исследований (например, связанных с отсутствием вредности какого-либо воздействия на человека). Соответствующие этим уровням значимости доверительные вероятности соответственно равны: 0,95; 0,99; 0,999. При построении законов распределения случайных величин вычисляется также для заданной доверительной вероятности диапазон возможных значений генеральной статистической характеристики. Этот диапазон называется доверительным интервалом. При отборе данных, характеризующих ту или иную выборку в инженерно-психологических исследованиях, следует учитывать в ряде случаев различные проявления изменчивости характеристик оператора. Существует по крайней мере два ее проявления. Во-первых, от индивидуума к индивидууму (индивидуальные различия между операторами); во-вторых, для конкретного индивидуума — случайное изменение характеристик оператора от опыта к опыту. Одновременный учет обоих проявлений изменчивости может проводиться различными способами: ■ при формировании выборки для каждого из п испытуемых берется по некоторому числу m реализаций случайной величины, всего получается N = m-n значений; ■ с помощью жребия выбирается конкретный оператор и для него берется требуемое число значений изучаемой случайной величины; ■ выборка формируется по всем п операторам из средних значений изучаемой случайной величины, полученных на основании усреднения m значений этой величины для каждого оператора, что эквивалентно, как и в первом случае, общему объему выборки, равному N=mn. Однако в любом случае выборка обязательно должна быть представительной, т. е. такой, чтобы элемент генеральной совокупности мог попасть в нее с заданной вероятностью, не зависящей от характеристик, подлежащих измерению. Такая выборка называется репрезентативной (от фр. representatif — представительный).
|
||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 598; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.135.186.233 (0.009 с.) |

 (8.1)
(8.1) , носит название среднеквадратического отклонения и имеет ту же размерность, что и сама случайная величина. Для оценки вероятности случайного события используют величину
, носит название среднеквадратического отклонения и имеет ту же размерность, что и сама случайная величина. Для оценки вероятности случайного события используют величину  , где m — число опытов, в которых данное событие имело место. Чем больше n, тем ближе вычисленные значения
, где m — число опытов, в которых данное событие имело место. Чем больше n, тем ближе вычисленные значения  , Dx, P к своим истинным значениям, характеризующим генеральную совокупность изучаемой случайной величины.
, Dx, P к своим истинным значениям, характеризующим генеральную совокупность изучаемой случайной величины.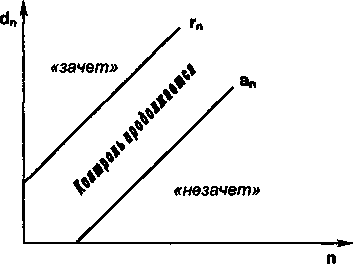
 (8.2)
(8.2)


