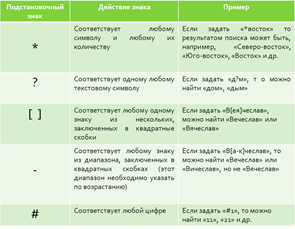
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Недостатки сетевой модели данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте · Высокая сложность и жесткость схемы БД, построенной на ее основе; · Сложность в понимании и обработки информации в БД обычному пользователю.
5. Основные понятия реляционных моделей данных Ответ: Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени.
Отношение - является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные.Термин отношение происходит от англ. relation (отношение). Сущность - есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении. Атрибуты -представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Домен - представляет собой множество всех возможных значений определенного атрибута отношения. Схема отношения (заголовок отношения) - представляет собой список имен атрибутов. Пример схемы отношения Сотрудники(ИД_Код, ФИО, Отдел, Должность). Первичный ключ (ключ отношения или ключевой атрибут) - называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей. Ключ может состоять из нескольких атрибутов, тогда такой ключ называется сложным составным. Ключи обычно используются для достижения следующих целей: · Исключения дублирования значений в ключевых атрибутах; · Упорядочивания кортежей; · Ускорения работы с кортежами отношения; · Организации связывания таблиц базы данных. Внешний ключ: п усть в отношении сотрудник имеется неключевой атрибут Отдел, значения которого являются значениями ключевого атрибута отношения Отделы, тогда говорят, что атрибут Отдел отношения Сотрудники является внешним ключом отношения Отделы. Пример внешнего ключа:
Свойства отношения: · В таблице нет двух одинаковых строк; · Все кортежи в одном отношении должны иметь одну структуру, соответствующую именам и типам атрибутов; · Каждый атрибут в отношении имеет уникальное имя; · Порядок следования кортежей в отношении произволен. Основной единицей обработки данных в реляционной базе денных является отношение, а не отдельные его кортежи. 6. Сортировка, поиск и замена данных в таблицах Ответ: Сортировка данных в таблицах позволяет упорядочить информацию по какому-либо критерию. Общий порядок сортировки для БД определяет в разделе Основные диалогового окна Параметры Access. Измененный порядок сортировки будет действовать для всех вновь создаваемых БД. Менять универсальный режим сортировки не рекомендуется.
Сортировка данных: В MS Access существует два вида сортировки: · По возрастанию; · По убыванию. Обычный порядок сортировки текстовых полей по возрастанию означает упорядочивание полей сверху вниз от начинающихся на букву «А» до начинающихся на букву «Я». Если атрибуты начинаются с одной и той же буквы, сортировка производится по второй букве и т.д. Правила сортировки: · При сортировке по возрастанию значения атрибутов, содержащие значения Null ставятся в начало списка; · Числа, находящиеся в текстовых полях сортируются как строки символов, а не как числовые значения; · Если в значениях встречаются и русские и английские символы, при сортировки по возрастанию в начало списка будут английские значения от «А» до «Z», а затем русские от «А» до «Я»; · Сортировка не применима к атрибута таблицы с типами данных OLE, вложения, а поля с типами данных гиперссылка и МЕМО можно отсортировать с помощью расширенного фильтра; · При сохранении таблицы сохраняется и порядок ее сортировки. Сортировка таблиц: Существует два метода сортировки: · Простая сортировка – в этом случае записи сортируются либо по возрастанию, либо по убыванию (но не в том и другом порядке одновременно); · Сложная сортировка - когда одни поля упорядочены по возрастанию, а другие по убыванию. Сложная сортировка доступна в окне расширенного фильтра, в режимах конструкторов запросов, отчетов и др., т. е. там, где для отдельного поля можно установить свой режим сортировки. Средства поиска и замены: С помощью диалогового окна Поиск и Замена можно найти конкретные записи или определенные значения в полях, а также произвести их замену на новые.
Маска ввода, поиск и замена: Если в таблицу, уже содержащие данные, была добавлена маска ввода, могут возникнуть сложности при поиске и замене данных, но не удовлетворяющих маске ввода. Чтобы этого не происходило, необходимо сначала удалить маску ввода, произвести поиск или замену, а затем заново добавить маску ввода Фильтр используется как инструмент работы с данными, их просмотра, проверки и редактирования. Фильтр – фактически набор условий для отбора подмножества данных (или для сортировки данных). Фильтры могут применяться не только в таблицах, но и в формах, запросах и отчетах Виды фильтров: · Простой фильтр (фильтр по значению поля); · Фильтр по выделенному; · Обычный фильтр (фильтр по форме) - может содержать сразу несколько условий по нескольким полям таблицы. Чтобы их задать пользователю предлагается заполнить ячейки в специальном окне – форме фильтра, поэтому этот тип фильтра еще называют «фильтр по форме». · Расширенный фильтр - имеет окно, очень похожее на окно запроса и открывается на собственной вкладке в рабочей области программы. Команда Масштаб контекстного меню ячейки условий открывает окно Область ввода, которое имеет больше места для задания условий, а также позволяет настроить шрифт. Расширенный фильтр, единственный, который можно сохранить как запрос. Фильтр по выделенному:
7. Индексирование данных в реляционных таблицах Ответ: Термин «индекс» тесно связан с понятием «ключ», хотя между ними есть и некоторое отличие. Под индексом понимают средство ускорения операции поиска записей в таблице, а следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д. Таблицу, для которой используется индекс, называют индексированной. Индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. В некоторых системах, например Paradox, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов. Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов: • вида содержимого в поле ключа записей индексного файла; • типа используемых ссылок (указателей) на запись основной таблицы; • метода поиска нужных записей. В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (так называемый хеш-код). Преимущество хранения хеш-кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поиско-вых операций. Недостатком хеширования является необходимость выполнения операции свертки (требует определенного времени), а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код). Для организации ссылки на запись таблицы могут использоваться три типа адресов: абсолютный (действительный), относительный и символический (идентификатор). На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД как правило индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, часто называются файлами первичных индексов. Индексы, создаваемые пользователем для не ключевых полей, иногда называют вторичными (пользовательскими) индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, обычно называются файлами вторичных индексов. В системах управления реляционными БД индексация является механизмом повышения их производительности за счет ускорения сортировки и поиска записей. Поля первичного ключа индексируются по умолчанию. Поля с типами данных OLE и Вложения индексировать нельзя. Индексирование полей целесообразно использовать если: · Они имеют тип данных Текстовый, Числовой, Денежный или Дата/Время; · По ним часто выполняется сортировка; · Они используются для поиска значений; · Они часто используются в операциях объединения. Индекс нецелесообразно использовать, если: · Поля редко используются в запросах; · Поля часто используются в запросах на изменение; · Поля имеют только несколько возможных значений (или много повторяющихся значений), например, пол человека; · Поля небольших таблиц с несколькими записями. В SQL Server поддерживает два типа индексов – кластерные и некластерные. Кластерный индекс представляет собой двоичное дерево, в котором на нулевом уровне (уровне листов) содержатся страницы актуальных данных таблицы, а физически информация хранится в логическом порядке данного индекса. В случае некластерных индексов странницы листового уровня содержат не актуальные данные таблицы (как в случае кластерного индекса), а указатель на строку данных, включающий номер страницы данных и порядковый номер записи на странице. Некластерный индекс не требует физического переупорядочения данных таблицы. Создание некластерного индекса не требует наличия в базе данных большого свободного дискового пространства, которое необходимо при создании кластерных индексов. Для одной таблицы может быть создано не более одного кластерного индекса и до 249 некластерных индексов. Индексы не могут быть созданы для столбцов со следующими типами данных BIT, TEXT и IMAGE. Индексы не могут также создаваться для видов. Для создания индексов используется команда CREATE INDEX. Общий синтаксис которой показан ниже: CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX index_name ON table (column [,...n]) [WITH [PAD_INDEX][[,] FILLFACTOR = fillfactor][[,] IGNORE_DUP_KEY][[,] DROP_EXISTING][[,] STATISTICS_NORECOMPUTE]][ON filegroup], где index_name – имя создаваемого индекса; table – имя таблицы, в которой создается; column – имя столбца таблицы; PAD_INDEX – этот параметр определяет размер пространства, оставляемого открытым на каждой внутренней странице; IGNORE_DUP_KEY – этот параметр не отменяет установленного требования уникальности ключей, но позволяет продолжить работу даже при попытке поместить в таблицу строку с дублирующимся значением уникального ключевого поля; DROP_EXISTING – этот параметр используется только при создании кластерных индексов и определяет обработку существующих некластерных индексов таблицы; STATISTICS_NORECOMPUTE – этот параметр блокирует автоматическое обновление статистических сведений по индексам, что потребует выполнения команды UPDATE STATISTICS вручную. Пример создания простого индекса: USE biblio GO CREATE INDEX numbil_id_ind ON Tbl_Chiteteli (NumBillet) GO
Пример создания уникального кластерного индекса USE biblio GO CREATE UNIQUE CLUSTERED INDEX TelephonID_ind ON Tbl_Chiteteli (Telephon) GO
Просмотр индексов базы данных Для получения подробных сведений о связанных с таблицами индексах можно воспользоваться командами sp_helpindex и sp_statistics. Переименование индексов базы данных Для переименования индекса используется системная хранимая процедура sp_rename. Команда вызова которой имеет приведенный ниже синтаксис: Sp_rename index_old, index_new [, COLUMN | INDEX] Удаление индексов базы данных Для удаления индекса используется команда, формат которой показан ниже: DROP INDEX [owner] table_name.index_name [, [owner,] table_name.index_name] где owner – владелец базы данных; index_name – имя индекса; table_name – имя таблицы, в которой удаляется индекс.
8. Концептуальная модель данных, основные понятия и определения Ответ: Главными элементами концептуальной модели данных являются объекты и отношения. Объекты обычно представляют в виде существительных, а отношения в виде глаголов. Объекты – вещи, которые пользователи считают важными в моделируемой предметной области: люди, автомобили, деревья, дома, книги и т.д. Концептуальными объектами являются компании, навыки, организации, проекты товаров, деловые операции, штатное расписание и т. д. Объектное множество (ОМ) – множество вещей одного типа (все люди, все автомобили, все банки); Объект-элемент – конкретный элемент объектного множества. Объектные множества могут быть лексическими и абстрактными. Элементы лексических объектных множеств можно написать, абстрактных же – нет!!! Например: (ИМЯ, ДАТА, КОЛИЧЕСТВО, – лексические ОМ, ЧЕЛОВЕК – абстрактное ОМ). Элементы лексических множеств обычно представляют в виде строк символов; элементы абстрактных множеств представляют внутренними номерами, не имеющими смысла вне компьютерной системы (идентификаторами или суррогатными ключами). Внутри одних объектных множеств могут содержаться другие ОМ. Например ОМ МУЖЧИНА содержится внутри ОМ ЧЕЛОВЕК. Конкретизация – это ОМ, являющееся подмножеством другого множества. Если ОМ является конкретизацией другого ОМ, он наследует все атрибуты и отношения обобщённого объекта. Пример конкретизации:
Обобщение – это объектное множество, являющееся надмножеством другого объектного множества (содержащее его). Пример обобщения:
Отношение – это связь между элементами двух объектных множеств. Рассмотрим пример: для служащих компании можно выделить два ОМ ИНСПЕКТОР и РАБОЧИЙ, причём инспекторы контролируют рабочих. Отношение Контролирует связывает каждого инспектора с рабочими, которых он контролирует. Пример отношения Контролирует:
Мощность отношения – максимальное количество элементов одного объектного множества, связанных с одним элементом другого объектного множества.
Типы отношений объектных множеств: · Функциональным называется отношение, максимальная мощность которого как минимум в одном направлении равна 1. Отношение один-к-одному означает, что максимальная мощность равна 1 в обоих направлениях (1:1). Например, у АВТОМОБИЛЯ один ВОДИТЕЛЬ, у ВОДИТЕЛЯ один АВТОМОБИЛЬ. · Отношение один-ко-многим означает, что максимальная мощность равна 1 в одном направлении и многим в обратном (1:М). Например СЛУЖАЩИЙ работает в одном ОТДЕЛЕ, но в ОТДЕЛЕ работает много СЛУЖАЩИХ. · Отношение многие-ко-многим означает, что максимальная мощность в обоих направлениях равна многим (М:М). Например: СТУДЕНТ посещает много КУРСОВ, каждый КУРС слушает много СТУДЕНТОВ. Если в отношении участвуют два объектных множества, они называются бинарными. Отношения высокого порядка называют n-арными. 3-арное отношение называется терарным (трёхсторонним). Концептуальное объектное множество – объектное множество, элементами которого являются абстрактные понятия.
9. Язык SQL, стандарты, основные операторы SQLзапроса Ответ: SQL («язык структурированных запросов») — формальный непроцедурный язык программирования, применяемый для создания, модификации и управления данными в произвольной реляционной базе данных, управляемой соответствующей системой управления базами данных (СУБД). SQL основывается на исчислении кортежей. Экспериментальная версия языка называлась SEQUEL (Structured English QUEry Language) структурированный английский язык запросов. Официальная версия была названа короче – SQL (Structured Query Language). Следует отметить, что к достоинствам языка SQL относится наличие международных стандартов. Первый международный стандарт был принят в 1989 г., и соответствующая версия языка называется SQL-89. Этот стандарт полностью поддерживается практически во всех современных коммерческих реляционных СУБД (например, в Informix, Sybase, Ingres, DB2 и т.д.). Стандарт SQL-89 во многих частях имеет чрезвычайно общий характер и допускает очень широкое толкование. В этом стандарте полностью отсутствуют такие важные разделы, как манипулирование схемой БД и динамический SQL. Многие важные аспекты языка в соответствии со стандартом определяются в реализации. Возможно, наиболее важными достижениями стандарта SQL-89 являются четкая стандартизация синтаксиса и семантики операторов выборки и манипулирования данными и фиксация средств ограничения целостности БД, включающих возможности определения первичного и внешних ключей отношений и так называемых проверочных ограничений целостности, позволяющих сформулировать условие для каждой отдельной строки таблицы. Средства определения внешних ключей позволяют легко формулировать требования так называемой целостности БД по ссылкам. Формулировка ограничений целостности на основе понятия внешнего ключа проста и понятна. Осознавая неполноту стандарта SQL-89, на фоне завершения разработки этого стандарта специалисты различных фирм начали работу над стандартом SQL2. Эта работа также длилась несколько лет, было выпущено 4нескольк 0о проектов стандарта, пока, наконец, в марте 1992 г. не был выработан окончательный проект стандарта (после чего стандарт и соответствующий язык стали называть SQL-92). Этот стандарт существенно более полный и охватывает практически все необходимые для реализации аспекты: манипулирование схемой БД, управление транзакциями и сессиями (сессия - это последовательность транзакций, в пределах которой сохраняются временные отношения), подключение к БД, динамический SQL. Наконец стандартизованы отношения-каталоги БД, что вообще-то не связано с языком непосредственно, но очень сильно влияет на реализацию. Заметим, что в стандарте представлены три уровня языка - базовый, промежуточный и полный. В течение нескольких лет после принятия стандарта производители СУБД, утверждавшие совместимость своих продуктов со стандартом, на самом деле в лучшем случае поддерживали промежуточный уровень языка SQL-92 (естественно, с собственными расширениями). Только в последних выпусках СУБД ведущих производителей обеспечивается совместимость с полным вариантом языка. Наконец, одновременно с завершением работ по определению стандарта SQL-92 была начата разработка стандарта SQL3. Общей точкой зрения ведущих производителей СУБД является то, что будущие продукты, обладая более развитыми возможностями, должны быть совместимы с предыдущими выпусками. Хотя многие разработчики и пользователи реляционных СУБД осознают наличие многих неустранимых недостатков языка SQL, от него теперь уже невозможно отказаться (как невозможно отказаться от использования языка Си в процедурном программировании). Следовательно, нужен новый стандарт языка, обеспечивающий такие очевидно необходимые возможности как определяемые пользователями типы данных, более развитые средства определения таблиц, наличие полного механизма триггеров и т.д. Нужен именно стандарт, а не наличие развитых частных версий языка, поскольку это выгодно и производителям и пользователям СУБД В 1992 году этот стандарт был назван SQL-92 (ISO/IEC 9075:1992). Последней к моменту написания этой книги версией стандарта SQL является SQL:2003 (ISO/IEC 9075X:2003). Любая реализация SQL в конкретной СУБД несколько отличается от стандарта, соответствие которому объявлено производителем. Так, многие СУБД (например, Microsoft Access 2003, PostgreSQL 7.3) поддерживают SQL-92 не в полной мере, а лишь с некоторым уровнем соответствия. Кроме того, они поддерживают и элементы, которые не входят в стандарт. Однако разработчики СУБД стремятся к тому, чтобы новые версии их продуктов как можно в большей степени соответствовали стандарту SQL. SQL задумывался как простой язык запросов к реляционной базе данных, близкий к естественному (точнее, к английскому) языку. Предполагалось, что близость по форме к естественному языку сделает SQL средством, доступным для широкого применения обычными пользователями баз данных, а не только программистами. Первоначально SQL не содержал никаких управляющих структур, свойственных обычным языкам программирования. Запросы, синтаксис которых довольно прост, вводились прямо с консоли последовательно один за другим и в этой же последовательности выполнялись. Однако SQL так и не стал инструментом банковских служащих, продавцов авиа-и железнодорожных билетов, экономистов и других служащих различных фирм, использующих информацию, хранимую в базах данных. Для них простой SQL оказался слишком сложным и неудобным, несмотря на свою близость к естественному языку вопросов. На практике с базой данных обычно работают посредством приложений, написанных программистами на процедурных языках, например, на С, Visual Basic, Pascal, Java и др. Часто приложения создаются в специальных средах визуальной разработки, таких как Delphi, Microsoft Access, Visual dBase и т. п. При этом разработчику приложения практически не приходится писать коды программ, поскольку за него это делает система разработки. Во всяком случае, работа с программным кодом оказывается минимальной. Эти приложения имеют удобный графический интерфейс, не вынуждающий пользователя непосредственно вводить запросы на языке SQL. Вместо него это делает приложение. Впрочем, приложение может как использовать, так и не использовать SQL для обращения к базе данных. SQL не единственное, хотя и очень эффективное средство получения, добавления и изменения данных, и если есть возможность использовать его в приложении, то это следует делать. Реляционные базы данных могут и действительно существуют вне зависимости от приложений, обеспечивающих пользовательский интерфейс. Если по каким-либо причинам такого интерфейса нет, то доступ к базе данных можно осуществить с помощью SQL, используя консоль или какое-нибудь приложение, с помощью которого можно соединиться с базой данных, ввести и отправить SQL-запрос (например, Borland SQL Explorer). Язык SQL считают декларативным (описательным) языком, в отличие от языков, на которых пишутся программы. Это означает, что выражения на языке SQL описывают, что требуется сделать, а не каким образом. Компоненты SQL: · DML (Data Manipulation Language — язык манипулирования данными) предназначен для поддержки базы данных: выбора (SELECT), добавления (INSERT), изменения (UPDATE) И удаления (DELETE) данных из таблиц. Эти операторы (команды) могут содержать выражения, в том числе и вычисляемые, а также подзапросы — запросы, содержащиеся внутри другого запроса. В общем случае выражение запроса может быть настолько сложным, что сразу и не скажешь, что он делает. Однако сложный запрос можно мысленно разбить на части, которые легче анализировать. Аналогично, сложные запросы создаются из относительно простых для понимания выражений (подзапросов). · DDL (Data Definition Language — язык определения данных) предназначен для создания, модификации и удаления таблиц и всей базы данных. Примерами операторов, входящих в DDL, являются CREATE TABLE (создать Таблицу), CREATE VIEW (создать представление), CREATE SHEMA (создать схему), ALTER TABLE (изменить таблицу), DROP (удалить) и др. · DCL (Data Control Language — язык управления данными) предназначен для обеспечения защиты базы данных от различного рода повреждений. СУБД предусматривает некоторую защиту данных автоматически. Однако в ряде случаев следует предусмотреть дополнительные меры, предоставляемые DCL. CREATE TABLE ИмяТаблицы ( { Имя поля таблицы Тип данных [(размер)][(ограничение)…].,…} { [, CONSTRAINT ограничения таблицы] } …); Условные обозначения: | - все, что предшествует символу, можно заменить тем, что следует за ним; { } - единое целое для применения символа; [ ] - необязательное выражение; … - повторяется произвольное число раз; .,… - повторяется произвольное число раз, но любое вхождение отделяется запятой. Пример создания простой таблицы без ограничений: CREATE TABLE Студент ( НомерЗачКнижки INTEGER, Фамилия CHAR (15), Имя CHAR (10), Отчество CHAR (15), ДатаРождения Date, Специальность CHAR (15), Примечание TEXT ); Определение первичного ключа в таблице: CREATE TABLE Студент ( НомерЗачКнижки INTEGER PRIMARY KEY NOT NULL, Фамилия CHAR (15), Имя CHAR (10), Отчество CHAR (15), ДатаРождения Date, Специальность CHAR (15), Примечание TEXT ); Структура таблицы с составным первичным ключом: CREATE TABLE Студент ( Фамилия CHAR (15), Имя CHAR (10), Отчество CHAR (15), ДатаРождения Date, Специальность CHAR (15), Примечание TEXT, CONSTRAINT PRIMARY KEY (Фамилия, Имя, Отчество));
10. Типы данных SQL Ответ: Типы данных: · Строковый (символьный): · CHARACTER или CHAR (n) · CHARACTER VARYING или VARCHAR (n) · TEXT · Числовой · Точные числовые типы: o INTEGER o SMALLINT o BIGINT o NUMERIC o DECIMAL · Приблизительные числовые типы: o REAL o DOUBLE PRECISION o FLOAT · Логический (булевский) · BOOLEAN · Даты-времени · DATE · TIME WITHOUT TIME ZONE · TIME WITH TIME ZONE · TIMESTAMP WITHOUT TIME ZONE · TIMESTAMP WITH TIME ZONE · Интервальный: INTERVAL - представляет собой разность между двумя значениями типа дата-время · Год-месяц (количество лет и месяцев между двумя датами) · День-время (количество дней, часов, минут и секунд между двумя моментами в пределах одного месяца) · Особые типы данных · ROW - запись · ARRAY - массив · MULTISET - мультимножество
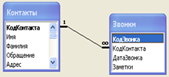
11. Операторы создания базы данных на языке SQL Ответ: Основной оператор, задающий создание новой таблицы CREATE TABLE (создать таблицу) CREATE TABLE ИмяТаблицы ( { Имя поля таблицы Тип данных [(размер)][(ограничение)…].,…} { [, CONSTRAINT ограничения таблицы] } …); Условные обозначения: | - все, что предшествует символу, можно заменить тем, что следует за ним; { } - единое целое для применения символа; [ ] - необязательное выражение; … - повторяется произвольное число раз; .,… - повторяется произвольное число раз, но любое вхождение отделяется запятой. Пример создания простой таблицы без ограничений: CREATE TABLE Студент ( НомерЗачКнижки INTEGER, Фамилия CHAR (15), Имя CHAR (10), Отчество CHAR (15), ДатаРождения Date, Специальность CHAR (15), Примечание TEXT ); Определение первичного ключа в таблице: CREATE TABLE Студент ( НомерЗачКнижки INTEGER PRIMARY KEY NOT NULL, Фамилия CHAR (15), Имя CHAR (10), Отчество CHAR (15), ДатаРождения Date, Специальность CHAR (15), Примечание TEXT ); Структура таблицы с составным первичным ключом: CREATE TABLE Студент ( Фамилия CHAR (15), Имя CHAR (10), Отчество CHAR (15), ДатаРождения Date, Специальность CHAR (15), Примечание TEXT, CONSTRAINT PRIMARY KEY (Фамилия, Имя, Отчество)); Описание примера на языке SQL: CREATE TABLE Контакты ( КодКонтакта INTEGER PRIMARY KEY NOT NULL, Имя VARCHAR (10), Фамилия VARCHAR (15), Обращение VARCHAR (10), Адрес VARCHAR (30)); CREATE TABLE Звонки ( КодЗвонка INTEGER PRIMARY KEY NOT NULL, КодКонтакта INTEGER NOT NULL, ДатаЗвонка DATE, Описание TEXT, CONSTRAINT FK1 FOREIGN KEY (КодКонтакта) REFERENCES Контакты (КодКонтакта)); Внешний ключ определяется как ограничение для таблицы в выражении с ключевыми словами CONSTRAINT имя связи FOREIGN KEY (ограничение «внешний ключ») Синтаксис оператора: CONSTRAINT имя ограничения FOREIGN KEY ВнешнийКлюч REFERENCES ВнешняяТаблица (ПервичныйКлюч) Пример: CREATE TABLE Заказы ( КодЗаказа INTEGER, кодКлиента INTEGER, CONSTRAINT FK FOREIGN KEY (КодКлиента) REFERENCES Клиенты(КодКлиента));
CREATE TABLE Контакты ( КодКонтакта INTEGER PRIMARY KEY NOT NULL, Имя VARCHAR (10), Фамилия VARCHAR (15), Обращение VARCHAR (10), Адрес VARCHAR (30));
CREATE TABLE Звонки ( КодЗвонка INTEGER PRIMARY KEY NOT NULL, КодКонтакта INTEGER NOT NULL, ДатаЗвонка DATE, Описание TEXT, CONSTRAINT FK1 FOREIGN KEY (КодКонтакта) REFERENCES Контакты (КодКонтакта));
12. Запросы, назначения запросов, виды запросов Ответ: Определение: В результате выполнения запроса создается таблица, которая либо содержит запрашиваемые данные, либо пуста, если данных, соответствующих запросу не нашлось. Эта таблица называется результирующий или результатной и существует только во время работы с БД и не присоединяется к числу ее таблиц. Запросы можно использовать для следующих действий: · Просмотра записей таблицы без ее открытия; · Объединение на экране данных нескольких таблиц в виде одной таблицы; · Просмотра отдельных полей таблицы; · Выполнения вычислений над значениями полей. Отличие запросов от фильтров: · Фильтры не позволяют добавить еще несколько таблиц, записи которых включаются в возвращаемый набор записей; · Фильтры не позволяют указать поля, которые должны отображаться в результате; · Фильтр нельзя выделить как отдельный объект БД; · Фильтры не позволяет производить вычислений. Виды запросов: · На выборку; · На изменение; · На создание таблицы; · С параметрами; · С вычисляемыми полями; · На управление. Виды запросов: Список всех видов запросов можно увидеть Конструктор (работа с запросами) Ленты, в разделе Тип зпроса.
Способы создания запросов: · С помощью мастера запросов · С помощью конструктора запросов · Создание запроса из фильтра Запрос с параметрами: Запросы с параметрами отличаются от других тем, что при выполнении запроса открываются диалоговые окна, предлагающие ввести параметры для условий на отбор записей. Вводимых параметров в одном запросе может быть несколько. Основные SQL-выражения для выборки данных: SELECT СписокСтолбцов FROM СписокТаблиц; Это обязательные SQL-выражения, ни одного из них нельзя пропустить!!! Инструкция SELECT: Сразу за оператором SELECT до списка атрибутов можно применять ключевые слова ALL (все) и DISTINCT(отличающиеся), которые указывают какие записи представить в результирующую таблицу. Если эти ключевые слова не используются, по подразумевается, что следует выбрать все записи, что соответствует применению ALL. В случае использования DISTINCT в результатной таблице представляются только уникальные записи. Использование псевдонимов: Заголовки столбцов в результатной таблице можно переопределить по своему усмотрению, назначив им так называемые псевдономы, для этого служит операнд Например SELECT Client.ClientName AS Клиент, Сlient.Adress AS Адрес FROM Client; Уточнения запросов: · WHERE (где) · GROUP BY (группировать по) · HAVING (имеющие, при условии) · ORDER BY (сортировать по) Структура запроса с уточнениями: SELECT СписокСтолбцов FROM ИмяТаблицы WHERE УсловиеПоиска GROUP BY СтолбецГруппировки HAVING УсловиеПоиска ORDER BY УсловиеСортировки Порядок выполнения операторов SQL в запросах: 1. FROM 2. WHERE 3. GROUP BY 4. HAVING 5. SELECT 6. ORDER BY Оператор WHERE: · Предикаты сравнения: (=), (<), (>), (< >), (<=), (>=); · BETWEEN; · IN, NOT IN; · LIKE, NOT LIKE; · IS NULL; · ALL, SOME, ANY; · EXISTS; · UNIQUE; · DISTINCT, · OVERLAPS, · MATCH, · SIMILAR. Оператор GROUP BY: Служит для группировки записей по значениям одного или нескольких полей. Если в SQL-выражении используется оператор WHERE, то GROUP BY находится и выполняется после него. Оператор HAVING: Обычно применяется совместно с оператором GROUP BY и задает фильтр записей в группах. Если в SQL-выражении оператора GROUP BY нет, то оператор HAVING применяется ко всем записям, возвращаемым оператором WHERE. Оператор ORDER BY: · ASC – по возрастанию (ascending); · DESC – по убыванию (descending);
13. Использование агрегированных функций запросов Ответ: Функция — это поименованная последовательность хранимых на сервере команд, выполняемая как одно целое, которая может вызываться из других частей программы столько раз, сколько необходимо. Отличия функций от хранимых процедур: · функция всегда возвращает значение в основную программу, а хранимая процедура лишь осуществляет какие-либо преобразования, не возвращая результата. · функции как и хранимые процедуры могут иметь входные параметры, но выходных параметров у них быть не может · функции можно применять в выражениях присваивания, хранимые процедуры – нельзя. Существует 2 класса функций: · встроенные · пользовательские. Встроенные функции, имеющиеся в распоряжении пользователей при работе с SQL, можно условно разделить на следующие группы: · математические функции; · строковые функции; · функции для работы с датой и временем; · функции конфигурирования; · функции системы безопасности; · функции управления метаданными; · статистические функции. Математические функции:
Для иллюстрации использования математической функции ROUND дополним БД таблицами: Disc – для хранения дисциплин, Ocenka – для хранения оценок по каждой дисциплине. create table Disc ( idDisc int identity primary key, nameDisc varchar(200) ) create table Ocenka ( idVed int identity primary key, idSt int references Student(idSt), idDisc int references Disc(idDisc), ocenka smallint ) insert into Disc values ('Математика') insert into Disc values ('История') insert into Disc values ('Информатика')
insert into Ocenka values(3,1,5) insert into Ocenka values(3,2,4) insert into Ocenka values(3,3,5) insert into Ocenka values(4,1,3) insert into Ocenka values(4,2,4) insert into Ocenka values(4,3,2) Проведем расчет среднего балла по всем студентам и округлим значение до 2-х знаков после запятой: select round(convert(float, sum(ocenka))/convert(float,count(*)),2) from Ocenka Средний балл для каждого студента: select nameSt+' '+sNameSt as ФИО, round(convert(float, sum(ocenka))/convert(float,count(*)),2) as [Средний балл] from Ocenka join Student on (Ocenka.idSt=Student.idSt) group by nameSt+' '+sNameSt Строковые функции6
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-06; просмотров: 858; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.012 с.) |