
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Лабораторная работа №1: Создание баз данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
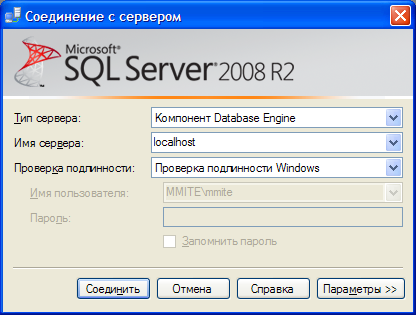
Лабораторная работа №1: Создание баз данных Утилита SQL Server Management Studio Подавляющую массу задач администрирования SQL Server можно выполнить в графической утилите SQL Server Management Studio. В ней можно создавать базы данных и все ассоциированные с ними объекты (таблицы, представления, хранимые процедуры и др.). Здесь вы можете выполнить последовательности инструкций Transact-SQL (запросы). В этой утилите можно выполнить типовые задачи обслуживания баз данных, такие как резервирование и восстановление. Здесь можно настраивать систему безопасности базы данных и сервера, просматривать журнал ошибок и многое другое. Для запуска Management Studio в меню «Пуск» операционной системы выберите пункт «Microsoft SQL Server 2008 R2\Среда SQL Server Management Studio». Когда откроется окно программы, вас попросят подключиться к какому либо серверу баз данных SQL Server. Подключение к серверу В окне «Соединение с сервером» необходимо указать следующую информацию: · Тип сервера. Здесь следует выбрать, к какой именно службе необходимо подключится. Оставьте вариант «Компонент Database Engine». · Имя сервера. Позволяет указать, к какому серверу будет осуществляться подключение. По умолчанию имя SQL Server совпадает с именем компьютера. Выберите ваш локальный компьютер. · Проверка подлинности. Способ аутентификации, можно выбрать «Проверка подлинности Windows» или «Проверка подлинности SQL Server». Первый способ использует учетную запись, под которой текущий пользователь осуществил вход в Windows. Вариант SQL Server использует свою собственную систему безопасности. Оставьте вариант проверки подлинности Windows.
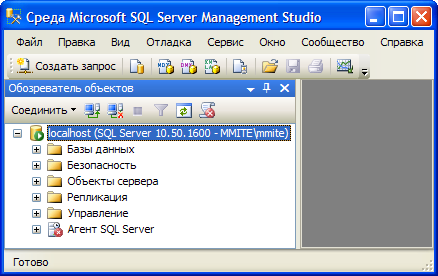
После подключения экземпляр сервера будет отображаться на панели «Обозреватель объектов».
Окно Management Studio имеет следующую структуру: · Оконное меню – содержит полный набор команд для управления сервером и выполнения различных операций. · Панель инструментов – содержит кнопки для выполнения наиболее часто производимых операций. Внешний вид данной панели зависит от выполняемой операции. · Панель «Обозреватель объектов». Это панель с древовидной структурой, отображающая все объекты сервера, а также позволяющая производить различные операции, как с самим сервером, так и с его базами данных и их объектами. Обозреватель объектов является основным инструментом для разработки.
· Рабочая область. В рабочей области производятся все действия с базой данных, а также отображается её содержимое. Прежде чем перейти к созданию своих собственных рабочих баз данных рассмотрим служебные базы данных SQL Server, которые создаются автоматически в процессе его установки. Если мы раскроем узел «Базы данных – Системные базы данных» в обозревателе объектов, то увидим следующий набор служебных баз данных: · master. Главная служебная база данных всего сервера. В ней хранится общая служебная информация сервера: настройки его работы, список баз данных на сервере с информацией о настройках каждой базы данных и ее файлах, информация об учетных записях пользователей, серверных ролях и т.п. · msdb. Эта база данных в основном используется для хранения информации службы SQL Server Agent (пакетных заданий, предупреждений и т.п.), но в нее записывается и другая служебная информация (например, история резервного копирования). · model. Эта база данных является шаблоном для создания новых баз данных в SQL Server. Если внести в нее изменения, например, создать набор таблиц, то эти таблицы будут присутствовать во всех создаваемых базах данных. · tempdb. Эта база данных предназначена для временных таблиц и хранимых процедур, создаваемых пользователями и самим SQL Server. Эта база данных создается заново при каждом запуске SQL Server. Создание пользовательских баз данных База данных представляет собой группу файлов, хранящихся на жестком диске. Эти файлы могут относиться к трем типам: файлы с первичными данными, файлы с вторичными данными и файлы журнала транзакций. Любая база данных SQL Server содержит, по крайней мере, два файла: первичный файл данных (с расширением.mdf) и файл журнала транзакций (с расширением.ldf). Существует два способа их создания: · графически с помощью SQL Server Management Studio · посредством кода Transact-SQL Типы данных При выборе типа данных для столбца следует отдавать предпочтение типу, который позволит хранить любые возможные для этого столбца значения и занимать при этом минимальное место на диске. Типы данных в MS SQL Server можно разделить на восемь категорий: 1. Целочисленные данные · bit (1 байт). Может хранить только значения 0, 1 или null (пустое значение, сообщающее об отсутствии данных). Его удобно использовать в качестве индикатора состояния – включено/выключено, да/нет, истина/ложь.
· tinyint (1 байт).Целые значения от 0 до 255. · smallint (2 байта). Диапазон значений от -215 (-32768) до 215 (3767). · int (4 байта). Может содержать целочисленные данные от -231 (-2147483648) до 231 (21474833647). · bigint (8 байт). Включает в себя данные от -263 (9223372036854775808) до 263 (9223372036854775807). Удобен для хранения очень больших чисел, не помещающихся в типе данных int. 2. Текстовые данные · char. Содержит символьные не Unicode-данные фиксированной длины до 8000 знаков. · varchar. Содержит символьные не Unicode-данные переменной длины до 8000 знаков. · nchar. Содержит данные Unicode фиксированной длины до 4000 символов. Подобно всем типам данных Unicode его удобно использовать для хранения небольших фрагментов текста, которые будут считываться разноязычными клиентами. · nvarchar. Содержит данные Unicode переменной длины до 4000 символов. 3. Десятичные данные · decimal. Содержит числа с фиксированной точностью от -1038-1 до 1038-1. Он использует два параметра: точность и степень. Точностью называется общее количество знаков, хранящееся в поле, а степень – это количество знаков справа от десятичной запятой. · numeric. Это синоним типа данных decimal – они идентичны. 4. Денежные типы данных · money (8 байт). Содержит денежные значения от -263 до 263 с десятичной точностью от денежной единицы. Удобен для хранения денежных сумм, превышающих 214768,3647. · smallmoney (4 байта). Содержит значения от -214748,3648 до 214748,3647 с десятичной точностью. 5. Данные с плавающей точкой · float. Содержит числа с плавающей запятой от -1,79Е+38 до 1,79Е+38. · real. Содержит числа с плавающей запятой от -3,40Е+38 до 3,40Е+38. 6. Типы данных даты и времени · datetime (8 байт). Содержит дату и время в диапазоне от 1 января 1753 года до 31 декабря 9999 года с точностью 3,33 мс. · smalldatetime (4 байта). Содержит дату и время, начиная от 1 января 1900 года и заканчивая 6 июнем 2079, с точностью до 1 минуты. 7. Двоичные типы данных · binary. Содержит двоичные данные фиксированной длины до 8000 байт. · varbinary. Содержит двоичные данные переменной длины до 8000 байт. 8. Специализированные типы данных · sql_variant. Используется для хранения значения с различными типами данных. · timestamp. Используется для установки временных меток записей при вставке, которые соответствующим образом обновляются. Удобен для отслеживания изменений в данных. · uniqueidentifier. Глобальный уникальный идентификатор. · xml. Используется для хранения целых документов или фрагментов XML. Создание таблиц Создадим в базе данных Sales пять таблицы. Первая таблица, Customer, будет хранить информацию о клиентах, вторая таблица City – справочник городов, третья, Product, - информацию о товарах, четвертая, Order, будет содержать подробную информацию о заказах и пятая, OrdItem, - о составе заказа (перечне товаров входящих в заказ). Ниже представлены все поля этих таблиц и их основные свойства.
Таблицы можно создавать как в графическом интерфейсе (в утилите Management Studio), так и с помощью кода T-SQL. Воспользуемся самым простым, графическим способом. Сначала создадим таблицу Customer: 1. В дереве обозревателя объектов в базе данных Sales в контекстном меню узла «Таблицы» выберите команду «Создать таблицу…». В рабочей области должна появиться вкладка с конструктором таблиц. 2. В первую строку в столбце «Имя столбца» введите IdCust, в столбце «Тип данных» выберите int. Убедитесь что параметр «Разрешить значения null» отключен. 3. В нижней половине экрана в разделе «Свойства столбцов» введите описание поля и измените значение параметра «Спецификация идентификатора / (Идентификатор)» на «Да» для того чтобы значения номера клиента формировались автоматически. Свойство «Идентифицирующий столбец» (Identity), обычно используемое совместно с типом данных int, предназначено для автоматического приращения значения на единицу при добавлении каждой новой записи. К примеру, клиент, добавленный в таблицу первым, будет иметь значение идентификатора 1, вторым – 2, третьим – 3, и т.д. 4. Аналогичным образом введите описания всех остальных полей и закройте окно конструктора таблиц. Введите в качестве имени таблицы Customer. Вновь созданная таблица должна появиться в дереве обозревателя объектов в папке «Таблицы».
Задание для самостоятельной работы: В соответствие с вышеприведенным описанием создайте оставшиеся четыре таблицы: City, Product, Order и OrdItem. Создание ограничений Перед тем как начать работать с таблицами следует ограничить вводимые в них данные в целях обеспечения так называемой целостности данных, т. е. ограничить возникновение в базе данных некорректных или противоречивых данных вследствие добавления, изменения или удаления какой-либо записи, например, ввод отрицательной цены или количества товара. Существует четыре типа целостности данных: доменная, сущностная, ссылочная и пользовательская (или бизнес-правила). Рассмотрим основные инструменты, предоставляемые в SQL Server для их реализации.
Обеспечение доменной целостности. Ограничение диапазона данных, вводимых пользователем в поле. Основными инструментами обеспечения доменной целостности являются ограничения проверки и значения по умолчанию. Создание первичных ключей Первичный ключ используется для обеспечения гарантии уникальности каждой записи в таблице. Он состоит из одного (простой ключ) или нескольких (составной ключ) столбцов с гарантированно уникальными значениями для каждой записи таблицы. Если пользователь попытается ввести в поля первичного ключа дублирующее значение будет сгенерирована ошибка и модификация данных будет отменена. В качестве примера создадим первичный ключ для таблицы Customer. В данном случае идеальным кандидатом на роль первичного ключа выступает столбец IdCust, поскольку значения, содержащиеся в нем, являются уникальными по определению (для него установлено свойство identity). Следует отметить, что в качестве первичного ключа могут быть взяты и реальные атрибуты клиента, например, ИНН, номер страхового свидетельства, серия и номер паспорта вместе взятые (пример составного ключа), но использование различных разновидностей, так называемых, суррогатных ключей (identity, uniqueidentifier) обеспечивает большую степень сущностной целостности (поскольку реальные атрибуты могут все же со временем измениться) и является распространенной практикой. Для создания первичного ключа в таблице Customer выполните следующие шаги: 1. В контекстном меню таблицы Customer выберите команду «Проект». 2. В окне конструктора таблиц щелкните правой кнопкой мыши на поле IdCust и выберите команду «Задать первичный ключ» или нажмите кнопку 3. Закройте конструктор таблиц с сохранением изменений
Задание для самостоятельной работы: Аналогичным образом создайте первичные ключи для остальных таблиц в соответствие с ниже приведенной таблицей.
Выборка отдельных столбцов SELECT [Description] FROM Product В приведенном выше операторе используется оператор SELECT для выборки одного столбца под названием Description из таблицы Product. Искомое имя столбца указывается сразу после ключевого слова SELECT, а ключевое слово FROM указывает на имя таблицы, из которой выбираются данные. Для создания и тестирования данного запроса в Management Studio выполните следующие шаги: 1. В контекстном меню базы Sales выберите команду «Создать запрос» или щелкните соответствующую кнопку на панели инструментов 2. В открывшемся окне создания нового запроса введите представленные выше инструкции SQL. 3. Для запуска запроса на выполнение щелкните кнопку
4. Management Studio позволяет сохранять пакеты SQL. Это полезно для сохранения сложных запросов, которые будут повторно запускаться в будущем. Для этого щелкните кнопку Выборка нескольких столбцов Для выборки из таблицы нескольких столбцов используется тот же оператор SELECT. Отличие состоит в том, что после ключевого слова SELECT необходимо через запятую указать несколько имен столбцов. SELECT [Description], InStock FROM Product Выборка всех столбцов Помимо возможности осуществлять выборку определенных столбцов (одного или нескольких), при помощи оператора SELECT можно запросить все столбцы, не перечисляя каждый из них. Для этого вместо имен столбцов вставляется групповой символ “звездочка” (*). Это делается следующим образом. SELECT * FROM Product Сортировка данных В результате выполнения запроса на выборку данные выводятся в том порядке, в котором они находятся в таблице. Для точной сортировки выбранных при помощи оператора SELECT данных используется предложение ORDER BY. В этом предложении указывается имя одного или нескольких столбцов, по которым необходимо отсортировать результаты. Взгляните на следующий пример. SELECT IdProd, [Description], InStock FROM Product ORDER BY InStock Это выражение идентично предыдущему, за исключением предложения ORDER BY, которое указывает СУБД отсортировать данные по возрастанию значений столбца InStock. Фильтрация данных В таблицах баз данных обычно содержится много информации и довольно редко возникает необходимость выбирать все строки таблицы. Гораздо чаще бывает нужно извлечь какую-то часть данных таблицы для каких-либо действий или отчетов. Выборка только необходимых данных включает в себя критерий поиска, также известный под названием предложение фильтрации. В операторе SELECT данные фильтруются путем указания критерия поиска в предложении WHERE. Предложение WHERE указывается сразу после названия таблицы (предложения FROM) следующим образом: SELECT IdProd, [Description], InStock FROM Product WHERE InStock = 0 Этот оператор извлекает значения всех столбцов из таблицы товаров, но показывает не все строки, а только те, значение в столбце InStock (Количество товаров на складе) которых равно 0, т.е. только список отсутствующих на складе товаров. При совместном использовании предложений ORDER BY и WHERE, предложение ORDER BY должно следовать после WHERE. В предыдущем примере проводилась проверка на равенство, т.е. определялось, содержится ли в столбце указанное значение. SQL поддерживает весь спектр условных (логических) операций, которые приведены в следующей таблице.
В следующем примере осуществляется выборка всех клиентов, для которых не указан контактный телефон. SELECT FName, LName, Phone FROM Customer WHERE PHONE IS NULL Для поиска диапазона значений можно использовать операцию BETWEEN. Ее синтаксис немного отличается от других операций предложения WHERE, так как для нее требуются два значения: начальное и конечное. Например, операцию BETWEEN можно использовать для поиска товаров, количество которых находится в промежутке между 5 и 10. SELECT IdProd, [Description], InStock FROM Product WHERE InStock BETWEEN 5 AND 10 Для объединения в предложении WHERE нескольких условий необходимо использовать логические операторы AND и (или) OR. Оператор AND требует одновременного выполнения обоих условий. Запишем предыдущий запрос посредством объединения двух операции сравнения оператором AND. SELECT IdProd, [Description], InStock FROM Product WHERE (InStock >= 5) AND (InStock <= 10) Ключевое слово AND указывает СУБД возвращать только те строки, которые удовлетворяют всем перечисленным критериям отбора. В данном случае будут выбраны только те товары, количество которых находится в промежутке от 5 до 10. Оператор OR указывает СУБД выбирать только те строки, которые удовлетворяют хотя бы одному из условий. SELECT IdCity, CityName FROM City WHERE (CityName = 'Москва') OR (CityName = 'Казань') Посредством этого SQL запроса из справочника городов выбираются только Москва и Казань. Ключевое слово OR указывает СУБД использовать какое-то одно условие, а не сразу два. Если бы здесь использовалось ключевое слово AND, мы бы не получили никаких данных. Если вы внимательно рассмотрите выражение в предыдущем предложении WHERE, то заметите, что значения, с которыми сравниваются названия городов, заключены в одинарные кавычки. Одинарные кавычки используются для определения границ строки (строковой константы). При работе со строковыми константами их всегда необходимо отделять одинарными кавычками. Предложения WHERE могут содержать любое количество логических операторов AND и OR. Комбинируя их можно создавать сложные фильтры. Однако при комбинировании ключевых слов AND и OR необходимо учитывать, что оператор AND выполняется раньше оператора OR, т.е. имеет более высокий приоритет. Изменить приоритет можно с помощью круглых скобок. В следующем примере осуществляется выборка из таблицы клиентов всех Ивановых и Петровых, для которых не указан контактный телефон. SELECT FName, LName, Phone FROM Customer WHERE (LName = 'Иванов' OR LName = 'Петров') AND PHONE IS NULL В случае отсутствия скобок результат был бы не верным, а именно включал бы в себя всех Петровых без контактного телефона и всех Ивановых без каких либо ограничений. Для определения входит ли сравниваемое значение в определенное заданное множество можно воспользоваться оператором IN. При этом все допустимые значения, заключенные в скобки, перечисляются через запятую. В частности предыдущий пример с использованием оператора IN может быть записан в более компактной форме. SELECT FName, LName, Phone FROM Customer WHERE LName IN ('Иванов','Петров') AND PHONE IS NULL Для отрицания какого-то условия используется логический оператор NOT. Поскольку NOT никогда не используется сам по себе (а только вместе с другими логическими операторами), его синтаксис немного отличается от синтаксиса остальных операторов. В отличие от них, NOT вставляется перед названием столбца, значения которого нужно отфильтровать, а не после. В следующем примере отбираются все клиенты, для которых имеются сведения об их контактом телефоне. SELECT FName, LName, Phone FROM Customer WHERE NOT PHONE IS NULL Для фильтрации данных по критерию соответствия определенной символьной строки заданному шаблону используется оператор LIKE. Шаблон может включать обычные символы и символы-шаблоны. Во время сравнения с шаблоном необходимо, чтобы его обычные символы в точности совпадали с символами, указанными в строке. Символы-шаблоны могут совпадать с произвольными элементами символьной строки. Использование символов-шаблонов с оператором LIKE предоставляет больше возможностей, чем использование обычных операторов сравнения. Шаблон может включать в себя следующие символы-шаблоны.
В следующем примере осуществляется выборка всех товаров, названия которых начинаются на букву Т. SELECT * FROM Product WHERE [Description] LIKE 'Т%' Создание вычисляемых полей Конструкция SELECT кроме имен столбцов таблиц может также включать так называемые вычисляемые поля. В отличие от всех выбранных нами ранее столбцов, вычисляемых полей на самом деле в таблицах базы данных нет. Они создаются "на лету" SQL-оператором SELECT. Рассмотрим следующий пример. SELECT IdCust AS 'Номер клиента', FName + ' ' +LName AS 'Фамилия и имя клиента' FROM Customer Здесь создается вычисляемое поле, которому с помощью ключевого слова AS дан псевдоним ‘Фамилия и имя клиента’. Оно позволяет объединить (произвести конкатенацию) с помощью оператора + фамилию, пробел и имя клиента в одно поле (столбец). Псевдоним может быть задан и для обычного столбца таблицы. В частности здесь столбцу IdCust задан псевдоним ‘Номер клиента’. Еще одним способом использования вычисляемых полей является выполнение математических операций над выбранными данными. Рассмотрим пример. SELECT IdProd, Qty, Price, Qty * Price AS 'Стоимость' FROM OrdItem WHERE IdOrd = 1 Здесь с помощью оператора умножения * вычисляется общая стоимость каждого товара в заказе с кодом 1 как произведение количества на цену. Подзапросы Подзапрос — это запрос на выборку данных, вложенный в другой запрос. Подзапрос всегда заключается в круглые скобки и выполняется до содержащего выражения. Внешний запрос, содержащий подзапрос, если только он сам не является подзапросом, не обязательно должен начинаться с оператора SELECT. В свою очередь, подзапрос может содержать другой подзапрос и т. д. При этом сначала выполняется подзапрос, имеющий самый глубокий уровень вложения, затем содержащий его подзапрос и т. д. Часто, но не всегда, внешний запрос обращается к одной таблице, а подзапрос — к другой. На практике именно этот случай наиболее интересен. Простые подзапросы Простые подзапросы характеризуются тем, что они формально никак не связаны с содержащими их внешними запросами. Это обстоятельство позволяет сначала выполнить подзапрос, результат которого затем используется для выполнения внешнего запроса. Кроме простых подзапросов, существуют еще и связанные (коррелированные) подзапросы, которые будут рассмотрены в следующем разделе. Рассматривая простые подзапросы, следует выделить три частных случая: · подзапросы, возвращающие единственное значение; · подзапросы, возвращающие список значений из одного столбца таблицы; · подзапросы, возвращающие набор записей. Тип возвращаемой подзапросом таблицы определяет, как можно ее использовать и какие операторы можно применять в содержащем выражении для взаимодействия с этой таблицей. По завершении выполнения содержащего выражения таблицы, возвращенные любым подзапросом, выгружаются из памяти. Таким образом, подзапрос действует как временная таблица, областью видимости которой является выражение (т. е. после завершения выполнения выражения сервер высвобождает всю память, отведенную под результаты подзапроса). Операции соединения При проектировании базы данных стремятся создавать таблицы, в каждой из которых содержалась бы информация об одном и только одном типе сущности. Это облегчает модификацию базы данных и поддержку ее целостности. Однако сущности могут быть взаимосвязанными. Клиенты связаны с городами по признаку проживания, заказы осуществляют клиенты, товары входят в состав заказов и т. д. Связь между таблицами устанавливается за счет размещения столбца первичного ключа одной таблицы, которая называется родительской, в другой взаимосвязанной таблице, которая называется дочерней. Столбец (или совокупность столбцов) дочерней таблицы, определенный для связи с родительской таблицей, называется внешним ключом. Так, например, таблица Customer содержит столбец IdCity, который для каждой строки клиента содержит значение первичного ключа того города, в котором проживает данный клиент. Наличие внешних ключей является основой для инициирования поиска по многим таблицам. Одна из наиболее важных особенностей предложения SELECT — это способность использования связей между различными таблицами, а также вывода содержащейся в них информации. Операция, которая приводит к соединению из двух таблиц всех пар строк, для которых выполняется заданное условие, называется соединением таблиц. Внутреннее соединение В операторе JOIN внутреннее соединение указывается ключевым словом INNER (впрочем, его можно опустить, так как соединение двух таблиц является внутренним по умолчанию). Условие соединения указывается после ключевого слова ON. В этом случае внутреннее соединение с помощью фразы FROM JOIN очень похоже на соединение с использованием фразы WHERE. Запишем первый пример с предыдущего раздела с использование оператора JOIN. Запрос: Список всех клиентов с указанием названий городов, в которых они проживают SELECT FName, LName, CityName FROM Customer k JOIN City c ON k.IdCity = c.IdCity При соединении с использованием фразы FROM дополнительное условие можно для увеличения наглядности запроса помещать во фразу WHERE. В этом случае второй пример с предыдущего раздела примет такой вид. Запрос: Список всех клиентов из Казани с фамилией Иванов SELECT K.IdCust, k.FName FROM Customer k INNER JOIN City c ON k.IdCity = c.IdCity WHERE k.LName = 'Иванов' AND c.CityName = 'Казань' Внешнее соединение Все соединения таблиц, рассмотренные до сих пор, являются внутренними. Во всех примерах вместо ключевого слова JOIN можно писать INNER JOIN (внутреннее соединение). Из таблицы, получаемой при внутреннем соединении, отбраковываются все записи, для которых нет соответствующих записей одновременно в обеих соединяемых таблицах. При внешнем соединении такие несоответствующие записи сохраняются. В этом и заключается отличие внешнего соединения от внутреннего. С помощью специальных ключевых слов LEFT OUTER, RIGHT OUTER и FULL OUTER, написанных перед JOIN, можно выполнить соответственно левое, правое и полное соединение. В SQL-выражении запроса таблица, указанная слева от оператора JOIN, называется левой, а указанная справа от него — правой. При левом внешнем соединении несоответствующие записи, имеющиеся в левой таблице, сохраняются в результатной таблице, а имеющиеся в правой — удаляются. Значения столбцов из правой таблицы во всех строках, не имеющих соответствия с левой таблицей, принимают значение NULL. При правом внешнем соединении несоответствующие записи, имеющиеся в правой таблице, сохраняются в результатной таблице, а имеющиеся в левой — удаляются. Значения столбцов из левой таблицы во всех строках, не имеющих соответствия с правой таблицей, принимают значение NULL. Соответственно левое и правое внешние соединения различаются только порядком следования таблиц. При полном внешнем соединении двух таблиц результирующая таблица содержит все строки внутреннего соединения этих таблиц, а также не включенные им строки и первой, и второй таблиц (дополненные значениями NULL для отсутствующих столбцов). В следующем примере возвращается полный список городов с указанием количества клиентов из каждого из них SELECT c.CityName, a.CountCity FROM City c LEFT OUTER JOIN (SELECT IdCity, COUNT(*) AS CountCity FROM Customer GROUP BY IdCity) a ON c.IdCity = a.IdCity ORDER BY c.CityName Если в данном запросе заменить левое внешнее соединение на внутреннее, то из результата будут потеряны города, из которых нет ни одного клиента (проверьте это заменив LEFT OUTER JOIN на INNER JOIN и объясните причину разницы). Обратите внимание, что таблица City соединяется не с таблицей, а с подзапросом, которому задан псевдоним a. Задание для самостоятельной работы: Сформулируйте на языке SQL запросы на выборку следующих данных (с использование оператора JOIN для соединения таблиц): · список всех товаров, которые когда-либо заказывал заданный клиент; · список всех клиентов, не имеющих ни одного заказа. Множественные операции Множественные операции выполняются над наборами записей (таблицами), полученными в результате запросов, и, в свою очередь, возвращают таблицу. В стандарте SQL множественные операции имеют следующий синтаксис: запрос {UNION | INTERSECT | EXCEPT} [DISTINCT | ALL] запрос где запрос является предложением SELECT. Отличаются эти операции тем, какие строки возвращенных запросами таблиц отбираются в новую результирующую таблицу: · UNION — все строки таблиц, возвращенных обоими запросами; · INTERSECT — только те строки, которые имеются в таблицах обоих запросов; · EXCEPT — только те строки таблицы первого запроса, которых нет среди строк таблицы второго запроса. Запросы, содержащие множественные операторы, называются составными. Стандарт SQL определяет следующие правила относительно повторяющихся строк в таблицах. · базовые таблицы не могут содержать повторяющихся строк (это принципиальное требование реляционной модели данных); · результирующие таблицы запросов могут содержать повторяющиеся строки, если это не запрещено ключевым словом DISTINCT во фразе SELECT; · результирующие таблицы множественных операций не могут содержать повторяющихся строк, если это не разрешено ключевым словом ALL. Таким образом, именно ключевые слова ALL и DISTINCT указывают, допускаются ли в результирующей таблице повторяющиеся строки. В запросах при отсутствии явного указания предполагается использование ключевого слова ALL, а во множественных операциях — DISTINCT. Таблицы, используемые в качестве операндов множественной операции, должны быть совместимы. Под этим подразумевается следующее: · обе таблицы должны иметь одинаковое количество столбцов; · соответствующие пары столбцов должны быть одинаковых или совместимых типов. Объединение наборов записей Нередко требуется объединить записи двух или более таблиц с похожими структурами в одну таблицу. Иначе говоря, к набору записей, возвращаемому одним запросом, требуется добавить записи, возвращаемые другим запросом. Для этого служит оператор UNION (объединение): 3anpoc1 UNION Запрос2; При этом в результатной таблице остаются только отличающиеся записи. Чтобы сохранить в ней все записи, после оператора UNION следует написать ключевое слово ALL. К базе данных Sales сложно сформулировать осмысленный запрос с объединением, который бы имел какую-либо практическую ценность. Поэтому в качестве примера рассмотрим объединение результатов выполнения запросов, возвращающих просто константные значения. Запрос: Объединение с исключением дублирующих строк SELECT 1, 'Один' UNION SELECT 1, 'Один' UNION SELECT 2, 'Два' Запрос: Объединение с сохранением дубликатов SELECT 1, 'Один' UNION ALL SELECT 1, 'Один' UNION ALL SELECT 2, 'Два' Пересечение наборов записей Пересечение двух наборов записей осуществляется с помощью оператора INTERSECT (пересечение), возвращающего таблицу, записи в которой содержатся одновременно в двух наборах: Запрос1 INTERSECT Запрос2; (SELECT 1, 'Один' UNION SELECT 2, 'Два' UNION SELECT 3, 'Три')
INTERSECT
(SELECT 1, 'Один' UNION SELECT 2, 'Два' UNION SELECT 4, 'Четыре') Разность наборов записей Для получения записей, содержащихся в одном наборе и отсутствующих в другом, служит оператор EXCEPT(за исключением): Запрос1 ЕХCЕРТ Запрос2; (SELECT 1, 'Один' UNION SELECT 2, 'Два' UNION SELECT 3, 'Три')
EXCEPT
(SELECT 1, 'Один' UNION SELECT 2, 'Два' UNION SELECT 4, 'Четыре')
Лабораторная работа №5: Основы Transact SQL: Добавление, изменение и удаление данных в таблицах Запросы, рассмотренные ранее, были направлены на то, чтобы получить данные, содержащиеся в существующих таблицах базы данных. Главным ключевым словом таких запросов на выборку данных является SELECT. Запросы на выборку данных всегда возвращают виртуальную таблицу, которая отсутствует в базе данных и создается временно лишь для того, чтобы представить выбранные данные пользователю. При создании и дальнейшем сопровождении базы данных обычно возникает задача добавления новых и удаления ненужных записей, а также изменения содержимого ячеек таблицы. В SQL для этого предусмотрены операторы INSERT (вставить), DELETE (удалить) и UPDATE (изменить). Запросы, начинающиеся с этих ключевых слов, не возвращают данные в виде виртуальной таблицы, а изменяют содержимое уже существующих таблиц базы данных. Запросы на модификацию (добавление, удаление и изменение) данных могут содержать вложенные запросы на выборку данных из той же самой таблицы или из других таблиц, однако сами не могут быть вложены в другие запросы. Таким образом, операторы INSERT, DELETE и UPDATE в SQL-выражении могут находи
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-07; просмотров: 1185; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.255.180 (0.02 с.) |


 на панели инструментов. Обратите внимание на то, что слева от поля IdCust теперь отображается значок ключа, указывающий, что поле является первичным ключом.
на панели инструментов. Обратите внимание на то, что слева от поля IdCust теперь отображается значок ключа, указывающий, что поле является первичным ключом.
 .
. на панели инструментов или нажмите клавишу F5. В нижней части экрана должны появиться результаты.
на панели инструментов или нажмите клавишу F5. В нижней части экрана должны появиться результаты.
 на панели инструментов. По умолчанию файлы запросов сохраняются с расширением.sql. В дальнейшем сохраненный запрос может быть открыт командой «Открыть файл».
на панели инструментов. По умолчанию файлы запросов сохраняются с расширением.sql. В дальнейшем сохраненный запрос может быть открыт командой «Открыть файл».


