Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
База знаний программы internist формируется следующим образом.Содержание книги
Поиск на нашем сайте
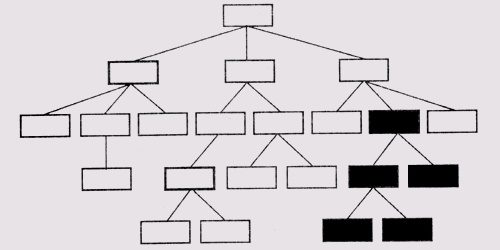
(1) Определяется базовая структура иерархии— к корневому узлу подсоединяются узлы основных областей внутренних болезней (органов дыхания, болезней печени, сердца и т.п.). (2) Выделяются подкатегории, в которых объединяются области заболеваний с похожими схемами протекания (патогенезом) и проявлениями (признаками и симптомами). (3) Эти подкатегории разделяются до тех пор, пока не будет достигнут уровень сущностей, т.е. конкретных заболеваний. (4) Собираются данные, касающиеся связей между сущностями заболеваний и их проявлениями. В число этих данных входят: список всех проявлений конкретного заболевания; оценка вероятности того, что данное заболевание является причиной проявления именно такого признака или симптома; оценка того, насколько часто у пациентов, страдающих определенным заболеванием, наблюдается каждое из отмеченных проявлений. (5) К представлению каждого заболевания D присоединяется список связанных с ним проявлений (M1,..., Мn), список показателей причинности L(D, Mi) и список показателей частотности L(Mi, D). Показатели обоих типов определены в диапазоне 0-5. (6) С каждым заболеванием D, помимо признаков и симптомов, могут быть связаны и другие заболевания, которые также могут рассматриваться как проявления заболевания D. Такие ''вторичные" заболевания связываются в структуре представления знаний с узлом заболевания отношениями EVOKE и MANIFEST. (7) После сбора и представления всей информации, касающейся "обслуживаемых" системой заболеваний D (т.е. терминальных узлов дерева), запускается программа, которая преобразует описанное дерево в обобщенное представление иерархической структуры. В этом представлении нетерминальные узлы содержат только те свойства, которые являются общими для всех его дочерних узлов. (8) Вводятся данные об отдельных проявлениях. Наиболее существенными свойствами проявлений являются TYPE (например, признак, симптом, лабораторный тест и т.п.) и INDEX (число в диапазоне 1-5, которое является показателем важности данного проявления). В ходе выполнения первых трех этапов формируется "суперструктура" базы знаний, т.е. в общих чертах определяется ее схема — диапазон категорий и уровень анализа каждой категории. На последующих трех этапах сформированная структура базы знаний наполняется содержимым. Введенные значения показателей причинности и частотности позволяют программе манипулировать в дальнейшем с "вескостью" свидетельств в пользу или против определенной гипотезы. На шаге 7 программа определяет проявления для нетерминальных узлов, представляющих области заболеваний, анализируя степень их общности для дочерних узлов более низких уровней иерархии. Например, разлитие желчи является проявлением целой группы заболеваний печени, которая объединяется областью гепатитные заболевания. Целесообразность такого обобщения проявлений объясняется следующим образом. Как уже не раз подчеркивалось ранее, пространство диагностируемых категорий для пациентов, страдающих несколькими заболеваниями, оказывается чрезвычайно большим. Вследствие этого на практике не удается применить в этом пространстве обычные методы поиска, такие как поиск в глубину. Нужно каким-то способом "свернуть" пространство поиска или сфокусировать усилия программы на определенной области пространства и таким образом добиться приемлемой скорости поиска. Проблема скорости поиска не стояла бы с такой остротой даже при наличии у пациента нескольких заболеваний, если бы существовали более прямые ассоциативные связи между заболеваниями и их проявлениями, т.е. если бы определенное проявление сразу позволило врачу прийти к заключению о наличии определенного заболевания. Такие отношения в медицинской литературе называются патогенетическими, и они действительно существуют, но, к несчастью, значительно реже, чем нам хотелось бы. Хуже всего то, что патогенетические отношения характерны для тех проявлений, которые могут быть выявлены только в процессе сложных лабораторных исследований или хирургическим путем. Установить же достаточно жесткие связи между определенными проявлениями и целой группой заболеваний (областью заболеваний в терминологии программы INTERNIST) удается гораздо чаще. Такое проявление, как разлитие желчи, жестко связано с областью заболеваний печени, а кровохаркание — с областью легочных заболеваний. Программа INTERNIST использует связи на верхних уровнях дерева для "сужения" пространства поиска. При этом начальная точка поиска как бы переносится на более низкие уровни иерархии в пространстве заболеваний и уже оттуда начинается выполнение процедуры поиска в глубину. В используемой Поплом терминологии сужение (constrictor) для конкретного случая диагноза — это нахождение во множестве известных проявлений "намека", в какой области пространства заболеваний находятся правдоподобные гипотезы. Однако не следует забывать, что такое сужение является эвристическим, а потому не гарантирует на все сто процентов, что искомое заболевание находится именно в определенной таким способом области. Хотя на верхних уровнях иерархии и могут существовать проявления, прямо связанные с определенной областью, другие проявления остаются только более предпочтительными для одной области и менее предпочтительными, но отнюдь не невозможными, для другой. При этом ситуация еще более ухудшается по мере перехода на более низкие уровни иерархии. Из всего сказанного следует, что то упорядочение проявлений, которое выполняется на этапе 7, позволяет консультационной программе начинать диагностическую процедуру на том уровне иерархии, на котором начинают проявляться патогенетические отношения, и отсеивать таким образом целые классы заболеваний. На этапе 8 обрабатываются свойства самих проявлений, что в процессе работы программы скажется на эффективности выполнения функций на стратегическом уровне. Например, свойство TYPE позволяет судить о том, насколько велики будут затраты на получение того или иного показателя или насколько процесс его получения будет опасен для здоровья пациента, а эту информацию следует учитывать при назначении уточняющих анализов. Свойство IMPORT позволяет принять решение, нельзя ли проигнорировать данное проявление в контексте определенного заболевания. Обратите внимание на то, что на этапах 5 и 8 используется довольно неформализованное представление неопределенности в суждениях. Но в дальнейшем мы увидим, что основной причиной появления проблем в процессе работы с системой INTERNIST является неудовлетворительная формулировка структуры пространства поиска, а не недостаточная точность исходных данных. Ниже, в разделе 13.4, мы рассмотрим, как отражается использование в программе INTERNIST иерархической структуры дерева гипотез на методике извлечения знаний при опросе экспертов Методика выделения правдоподобных гипотез в INTERNIST В процессе выполнения консультаций программа INTERNIST работает следующим образом. Сначала пользователь вводит список существующих проявлений заболеваний пациента. Каждое проявление активизирует один или несколько узлов в дереве заболеваний. Из выделенных на этом этапе узлов программа формирует модели заболевания, каждая из которых включает четыре списка: (1) наблюдаемые проявления, не связанные с данным заболеванием; (2) наблюдаемые проявления, согласующиеся с данным заболеванием; (3) проявления, отсутствующие во введенных данных, но всегда сопутствующие данному заболеванию; (4) проявления, которые отсутствуют во введенных данных, но не согласуются с данным заболеванием (опровергают выдвинутую гипотезу). В модели заболевания проявления, подтверждающие гипотезу, получают положительные оценки, а те, которые им противоречат, — отрицательные. Оба типа оценок "взвешиваются" значениями свойств IMPORT соответствующих проявлений, и модель получает премиальные очки, если имеет причинную связь с другим подтвержденным заболеванием. Затем модели заболеваний разделяются на две группы. В одну группу попадают модель с самой высокой оценкой и все остальные, которые представляют взаимно исключающие с ней гипотезы. Их можно считать "соседними" узлами на дереве заболеваний. Другая группа включает заболевания, совместимые с наиболее правдоподобной гипотезой, т.е. узлы, принадлежащие другим областям заболеваний (рис. 13.2).
Рис. 13.2. Разделение узлов в дереве гипотез. Узлы активизированных гипотез вычерчены утолщенными прямоугольниками, а узел наиболее правдоподобной гипотезы и его дочерние узлы залиты серым цветом В таком разделении используется концепция доминирования, которой придается следующий смысл. Модель заболевания D1 доминирует над D2 в том случае, если наблюдаемые проявления, которые не могут быть объяснены гипотезой D1, входят как подмножество в число проявлений, которые не объясняются и гипотезой D2. Если мы выделили наиболее правдоподобную гипотезу D0 среди всех активизированных на первом этапе, то каждая из остальных гипотез Di сравнивается с гипотезой Do Если D0 доминирует над Di или Di доминирует над Do, то Di включается в ту же группу "привилегированных" гипотез, что и Do Эта группа должна рассматриваться программой в первую очередь. В противном случае Д включается в другую группу гипотез, анализ которых откладывается на будущее. Рациональное зерно в таком разделении в том, что модели, включенные в привилегированную группу на любом этапе уточнения, можно считать взаимно исключающими альтернативами. Такое заключение основано на том, что для любых гипотез (моделей) Di и Dj в этой группе диагноз, включающий Di иDj, добавит очень немного или не добавит ничего к "полноте накрытия" каждой из гипотез Di и Dj по отдельности. На следующем этапе уточнения модели обрабатываются по той же методике, если проблема выбора среди моделей, связанных с Do, будет решена. Разделение начинается с нового узла Do, который получит наивысшую оценку среди уточняемых моделей. Уже после ввода первой порции исходных данных будет активизирована только часть всех узлов дерева. Теперь задача программы состоит в том, чтобы преобразовать дерево из исходного состояния в состояние решения. В состоянии решения дерево должно включать только те терминальные узлы, которые в совокупности "накрывают" все имеющиеся симптомы.
|
||||
|
|
Последнее изменение этой страницы: 2016-04-07; просмотров: 295; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.75.217 (0.007 с.) |