
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Назначение экономико-математических моделей (ЭММ)Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Назначение экономико-математических моделей (ЭММ) Эконометрика – прикладная математическая дисциплина, в которой изучаются количественные взаимосвязи экономических объектов и процессов. Задача эконометрики состоит в определении приближенных значений искомых величин эк.задачи по известным количественным характеристикам данной задачи. Метод решения задач эконометрики заключается в предварительном построении упрощенной схемы решаемой задачи, составленной математическим языком и называемой эконометрической моделью, а затем в расчете по этой модели искомых величин. Экономико-математическая модель (ЭММ, эконометрическая модель) объекта – это некоторое математическое выражение (график или таблица, уравнение или система уравнений, дополненная, возможно, неравенствами, условие экстремума), связывающее воедино исходные данные и искомые неизвестные задачи.
Два принципа спецификации эконометрической модели 1. Эконометрическая модель возникает в итоге записи математическим языком взаимосвязей исходных данных и искомых неизвестных. В процессе такой записи стараются привлекать линейные алгебраические функции. 2.Количество уравнений модели обязано совпадать с числом искомых неизвестных. Этот принцип необходим для трансформации модели к приведенной форме (где каждая эндогенная переменная представляется в виде явной функции только экзогенных переменных).
Типы уравнений в ЭММ: поведенческие уравнения и тождества. Рассмотрим макромодель Кейнса, экономическим объектом в которой является закрытая экономика. Экзогенная переменная: Применим первый метод спецификации: 1) доход состоит из потребительских расходов и инвестиционных затрат
уравнение представляет собой основное тождество системы национальных счетов для закрытой экономики 2) уровень потребительских затрат объясняется дохом
c позиции математики переменная линейная алгебраическая функция; такое уравнение принято называть поведенческим 3) с ростом дохода увеличивается потребление, каждая доп.единица дохода потребляется не полностью, какая-то часть идет на инвестиции, поэтому
Итак, тождество представляет собой равенство, выполняющееся в любом случае; поведенческое уравнение включает параметры (
2. Типы переменных в экономических моделях. Структурная и приведённая форма модели (на примере макромодели). Компактная запись. Типы переменных в эконометрических моделях Экзогенные переменные – исходные данные (экономические переменные, значения которых определяются вне модели и заранее известны) Эндогенные переменные – искомые неизвестные (экономические переменные, значения которых нужно определить внутри модели)
Датированные переменные - переменные, возникающие в результате их привязывания ко времени (текущие и лаговые) Лаговые переменные - экзогенные и эндогенные переменные экономических моделей, датированные предыдущими моментами времени
Объясняемые переменные – текущие эндогенные переменные Предопределенные переменные – текущие и лаговые экзогенные переменные, а также лаговые эндогенные переменные, если они стоят в уравнении с текущими эндогенными
Компактная запись Обозначив векторы эндогенных переменных
Составив матрицы
3. Спецификация и преобразование к приведённой форме динамических моделей. Лаговые и предопределённые переменные динамической модели. Модель Линтнера корректировки размера дивидендов. Компактная запись.
Спецификация и преобразование к приведенной форме динамических моделей Для отражения в спецификации модели фактора времени её переменные датируются (привязываются ко времени). Модель с датированными переменными именуется динамической. Стоит отметить, что датирование переменных является третьим принципом спецификации эконометрической модели. Датированные переменные бывают текущие (датированные текущим моментом времени) и лаговые (датированные предыдущими моментами времени). В свою очередь, все переменные динамической модели делятся на: 1) объясняемые – текущие эндогенные переменные 2) предопределенные (объясняющие), включающие: ¾ лаговые эндогенные ¾ текущие экзогенные ¾ лаговые экзогенные
Компактная запись Обозначив векторы эндогенных переменных
Составив матрицы
4. Спецификация и преобразование к приведённой форме эконометрических моделей. Эконометрическая модель Самуэльсона–Хикса делового цикла экономики. Компактная запись.
Спецификация и преобразование к приведённой форме эконометрических моделей Принципы спецификации эконометрической модели: 1. Эконометрическая модель возникает в итоге записи математическим языком взаимосвязей исходных данных и искомых неизвестных. В процессе такой записи стараются привлекать линейные алгебраические функции. 2.Количество уравнений модели обязано совпадать с числом искомых неизвестных. Этот принцип необходим для трансформации модели к приведенной форме (где каждая эндогенная переменная представляется в виде явной функции только экзогенных переменных). 3. Переменные модели датируются, что позволяет нам получить динамическую модель, в которой текущие эндогенные переменные объясняются значениями предопределенных. 4. Поведенческие уравнения модели включают в себя случайные возмущения, таким образом, мы отражаем в спецификации влияние на текущие эндогенные переменные неучтенных факторов (повышая тем самым адекватность модели).
На основании всех четырех принципов спецификации в самом общем случае структурная форма эконометрической модели имеет вид:
а приведенная форма:
Компактная запись Обозначив векторы текущих эндогенных переменных
Составив матрицы
5. Схема построения эконометрических моделей (на примере эконометрической модели Оукена). Для начала отметим основные 4-е этапа построения эконометрических моделей: 1)построение спецификации эконометрической модели; 2)сбор и проверка статистической информации об объекте-оригинале в виде конкретных значений экзогенных и эндогенных переменных, включённых в спецификацию модели; 3)оценивание неизвестных параметров модели (настройка или идентификация модели); 4)проверка адекватности оценённой модели (проверка соответствия настроенной модели объекту- оригиналу; верификация). 1. Рассмотрим эконометрическую модель Оукена. Будем считать, что Темп прироста реального ВВП зависит от изменения уровня безработицы. Тогда модель можно представить в виде:
xt - изменения уровня безработицы, Yt-эндогенная переменная. Xt- экзогенная. a0,a1 – параметры модели, подлежащие оценке. Параметр 2.Таблица с данными. Сбор статической информации в виде конкретных значений экзогенных и эндогенных переменных, входящих в спецификацию модели. Собранная статическая информация требуется для оценивания неизвестных параметров модели (настройка модели). Собранная информация разделяется на 2 части: · Обучающая выборка (предназначена для определения параметров модели) · Контролирующая выборка (для проверки адекватности информации) 3.На 3 этапе по обучающей выборке методами математической статистики отыскиваются оценки 4.На 4 этапе оцененная модель Модель признается адекватной, если ошибки прогнозов значений эндогенной переменной из контролирующей выборки не превышают критических уровней. Прогнозы вычисляются по приведенной форме:
6. Порядок оценивания линейной эконометрической модели из изолированного уравнения в Excel. Смысл выходной статистической информации функции ЛИНЕЙН.
Рассмотрим спецификацию данного вида. В этой модели экзогенных переменных х1 и х2 и одна эндогенная переменная уt. Случайное возмущение u предполагается гомоскедастичным. Спецификация содержит 4 параметра: а0, а1, а2, Модели данного типа называются линейными эконометрическими моделями в виде изолированных уравнений с несколькими объясняющими переменными или линейной множественной регрессии. Порядок оценивания модели состоит в следующем: Ввести исходные данные или открыть из существующего файла, содержащего анализируемые данные; В данном случае выделяем область пустых ячеек 5*3 (5 строк, 3 столбца) для вывода результатов регрессионной статистики (функция линейн). В общем случае: подготавливаем область, состоящую всегда из 5 строк, а столбцов столько, сколько коэффициентов требуется оценить, но минимум 2(а0, а1). Активизировать Мастер функций любым из способов: В главном меню выбрать Вставка/Функция На панели инструментов Стандартная щелкнуть на кнопке Вставка функции; В окне Категория выбрать Статистические, в окне Функция – ЛИНЕЙН, щелкнуть ОК; Заполнить аргументы функции: Известные значения y – диапазон, содержащий данные результативного признака; Известные значения x – диапазон, содержащий данные факторов независимого признака; Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении. Если Константа =1, то свободный член рассчитывается обычным образом, если Константа=0, то свободный член равен 0; Статистика – логическое значение, которое указывает, выводить дополнительную информацию или нет. Если статистика =1, то дополнительная информация выводится, если Статистика =0, то выводятся только оценки параметров уравнения. Нажать комбинацию клавиш <CTRL>+<SHIFT>+<ENTER>. Щелкнуть ОК.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
7. Случайная переменная и закон её распределения. Нормальный закон распределения и его параметры. Переменная величина x c областью изменения X называется случайной, если свои возможные значения q из множества X она принимает в результате некоторого опыта со случайными элементарными исходами вида x- дискретная случайная переменная, если множество Х состоит из конечного или счетного количества констант З-н распределения дискретной случайной переменной- функция З-н распределения дискретной случайной переменной называется вероятностной функцией, значение которой равны вероятностям появления в опыте возможного значения сл. переменной: Нормальный закон распределения случайной величины имеет вид (НормРаспр, НормОбр):
параметры: математическое ожидание m и среднее квадратическое отклонение - сигма. Нормальный закон возникает тогда, когда случайная переменная х формируется под воздействием большого числа независимых факторов.
8. Случайная переменная и закон её распределения. Распределение хи-квадрат. Переменная величина называется случайной, если свои возможные значения она принимает в рез-те некоторого опыта, и до его завершения не возможно предсказать какое точно значение она примет. З-н распределения дискретной случайной переменной- функция З-н распределения дискретной случайной переменной называется вероятностной функцией, значение которой равны вероятностям появления в опыте возможного значения сл. переменной: Закон распределения хи-квадрат случайной величины имеет вид(ХИ2РАСП,ХИ2ОБР):
9. Случайная переменная и закон её распределения. Распределение Стьюдента, Квантиль, t крит уровня Опр1. Случайной называют переменную которая в результате испытания примет одно и только одно возможное значение, наперед не известное и зависящее от случайных причин, которые невозможно заранее учесть. Опр2. Переменная x с областью изменения X называется случайной, если свои возможные значения q из множества X переменная x принимает в результате некоторого опыта со случайными элементарными исходами вида Закон распределения – функция Полной характеристикой СП служит её дифференциальный закон распределения (ЗР). Так называется функция Для дискретной величины Для непрерывной величины Закон распределения Стьюдента случайной величины имеет вид(СтьюдРАСП-значение з-на распределения):
Г- гамма функция Эйлера, m- число степеней своб.
Пусть имеется выборка наблюденных в n+1 независимых испытаниях значений стандартной нормально распределенной случайной переменной x (т.е. x Для расчёта tкрит используем ф-цию – дробь Стьюдента с n степенями свободы.
Этот закон позволяет нам при любом фиксированном числе 1-α из интервала (0, 1) вычислить величину t1-α – двустороннюю (1-α)-квантиль распределения Стьюдента с числом свободы n (к-т Стьюдента tкрит). Величину t1-α можно рассчитать в Excel по аргументам α, n при помощи функции СТЬЮДРАСПОБР.
10. Ковариация Cov(x, y), и коэффициент корреляции, Cor(x, y) пары случайных переменных (x, y). Частная ковариация и частный коэффициент корреляции. Экономические переменные объекта (случайные или детерминированные), как правило, являются зависимыми величинами. Ковариации и коэффициент корреляции служат мерилами такой зависимости. Так, если (x, y) – пара случайных переменных (СП), то их ковариацией называется константа Cxy : Cxy = Cov(x, y) = E(x · y) – E(x) · E(y). (1) Из формулы (1) видно, что для вычисления Cxy нужно знать закон распределения Pxy (q, r) пары (x, y). Если он неизвестен, что и бывает на практике, то ковариацию можно оценить по выборке из генеральной совокупности Xx,y: {(x1, y1), (x2, y2),... (xn, yn)}, (2) Оценкой ковариации служит величина
именуемая выборочной ковариацией. Каждая пара в выборке (2) имеет один и тот же закон распределения, Pxy (q, r); компонеты двух различных пар, например, (x1, y1) и (x2, y2) являются независимыми случайными переменными. Добавим, что случайные переменные (xi, xj) из выборки (2) обладают одинаковыми количественными характеристиками; аналогично, случайные переменных (yi,yj) имеют одинаковые количественные характеристики. Оценка (3) совершеннее оценки (4) в том смысле, что она обладает свойством несмещённости,
отсутствующим у оценки, которая, в силу данного обстоятельства, является смещённой оценкой ковариации. Наконец, отметим, что физическая размерность Cxy равна произведению физических размерностей СП x и y. Но часто удобно использовать безразмерную (нормированную) ковариацию rxy ,
которая именуется коэффициентом корреляции. Замечательно, что всегда –1 £ rxy £ +1, причём если |rxy | = 1, то y = a0 + a1 · x. Так что при |rxy | = 1 между переменными (x, y) существует функциональная (жесткая) линейная зависимость. Если же Свойства 1. Операции ковариации и корреляции симметричны относительно своих аргументов; 2. Ковариация и корреляция между независимыми переменными равны 0; 3. 4. 5. 6. 7.
11. Случайная переменная и закон её распределения. Закон распределения Фишера. Квантиль, F крит уровня Опр1. Случайной называют переменную которая в результате испытания примет одно и только одно возможное значение, наперед не известное и зависящее от случайных причин, которые невозможно заранее учесть. Опр2. Переменная x с областью изменения X называется случайной, если свои возможные значения q из множества X переменная x принимает в результате некоторого опыта со случайными элементарными исходами вида Закон распределения – функция Полной характеристикой СП служит её дифференциальный закон распределения (ЗР). Так называется функция Для дискретной величины Случайная переменная (СП) x именуется дискретной (ДСП), если множество X состоит из конечного или счётного количества констант qi, то есть X = {q1, q2,..., qn }. Для непрерывной величины Если X есть некоторый интервал числовой прямой, конечный или бесконечный, то есть X = (a, b), то СП x называется непрерывной (НСП). Закон распределения Фишера
Пусть Случайная переменная
12. Случайный вектор и его основные количественные характеристики (на примере вектора Рассмотрим набор случайных переменных
Его основными характеристиками служат: 1) Вектор ожидаемых значений компонент:
так называют вектор констант, компоненты которого – мат. ожидания компонент вектора 2) Ковариационная матрица:
По главной диагонали располагаются дисперсии компонент случайного вектора. Недиагональные элементы это ковариации компонентов. Например,
ЛММР
Объясняющие переменные 19.Схема Гаусса–Маркова (на примере модели Оукена). Модель Оукена: t=1,2,... где wt - темп прироста безработицы в году t, yt - темп роста ВВП
Пусть в рамках исследуемой модели величины связаны следующим образом:
Она называется системой уравнений наблюдения объекта в рамках исследуемой линейной модели, или иначе – схемой Гаусса-Маркова ( где
Оценку вектора обозначим где f (·, ·) – символ процедуры. Данная процедура именуется линейной относительно вектора
Понятие статистической процедуры оценивания параметров эконометрической модели. Линейные статистические процедуры. Требования к наилучшей статистической процедуре. Пусть имеется выборка
значений переменных x и y модели
Данная выборка получена на этапе наблюдения и предназначена для оценивания параметров модели
В рамках данной модели величины (*) связаны следующей СЛОУ:
Она называется системой уравнений наблюдения объекта в рамках исследуемой линейной модели, или иначе – схемой Гаусса-Маркова. Вот компактная запись этой схемы где
Наконец, Оценку вектора обозначим где f (·, ·) – символ процедуры. Данная процедура именуется линейной относительно вектора
Класс таких всевозможных линейных процедур оценивания по исходной выборке вектора Наилучшая процедура f* (·, ·) из выбранного класса процедур F должна генерировать оценку
21. Теорема Гаусса-Маркова: выражение вектора оценок коэффициентов Если справедливы все предпосылки теорему Гаусса-Маркова, тогда имеет место утверждение А: Доказательство: Шаг 1. Шаг 2.
22. Теорема Гаусса-Маркова: выражение Cov( Одним из утверждений Гаусса-Маркова является утверждение D:
Обоснование. Пусть выполнены все предпосылки теоремы Гаусса-Маркова. Тогда ковариационная матрица вектора случайных остатков в уравнениях наблюдений является диагональной и конкретно скалярной: Видим, что оценки коэффициентов модели являются линейным преобразованием вектора Из вида вектора
23. Теорема Гаусса-Маркова: предпосылки и свойство наименьших квадратов Рассмотрим уравнения наблюдений вида Предпосылки теоремы Гаусса-Маркова для данных уравнений: 1. Ожидаемые значения случайных возмущений равны нулю: E(u1)=…=E(un)=0. 2. Дисперсии случайных остатков одинаковые и не зависят от объясняющих переменных: Var(u1)=…=Var(un)= 3. Случайные остатки в уравнениях наблюдений попарно некоррелированы: 4. Значения объясняющих переменных не коррелированы со значениями случайных возмущений: Cov(xij,ui)=0. Тогда выполняются необходимые утверждения (не все, только те, которые требуются в вопросе): А: С. Оценки, вычисленные в А, обладают замечательным свойством наименьших квадратов, то есть
24. Теорема Гаусса-Маркова: выражение Представим ситуацию, когда предпосылка 2 теоремы Гаусса-Маркова о гомоскедастичности случайного остатка не выполнена, то есть дисперсия зависит от объясняющих переменных, а остаток гетероскедастичен. В таком случае оценки параметров модели утрачивают свое свойство оптимальности (свойство минимальных дисперсий). Для построения оптимальной процедуры оценивания модели с гетероскедастичным остатком потребуется модель гетероскедастичности остатка, вот простейший вид такой модели: В этой модели присутствуют две константы – положительная константа
|
|||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-26; просмотров: 539; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.188.254.131 (0.015 с.) |

 – объем инвестиций в экономику страны. Эндогенные переменные:
– объем инвестиций в экономику страны. Эндогенные переменные: 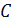 – уровень потребления в стране,
– уровень потребления в стране,  – валовой внутренний продукт (ВВП).
– валовой внутренний продукт (ВВП).


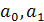 ), значения которых являются неизвестными и подлежат оцениваю.
), значения которых являются неизвестными и подлежат оцениваю.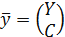 и экзогенных переменных
и экзогенных переменных 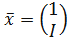 , мы можем записать макромодель Кейнса в компактном виде:
, мы можем записать макромодель Кейнса в компактном виде:
 и
и 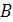 получим компактную запись:
получим компактную запись:
 и экзогенных переменных
и экзогенных переменных  , мы можем записать модель Линтнера в компактном виде:
, мы можем записать модель Линтнера в компактном виде: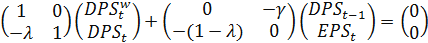
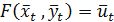


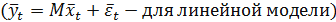
 и предопределенных переменных
и предопределенных переменных  , мы можем записать модель Самуэльсона-Хикса в компактном виде:
, мы можем записать модель Самуэльсона-Хикса в компактном виде:
 , где Yt- Темп прироста реального ВВП,
, где Yt- Темп прироста реального ВВП, -константа.
-константа.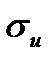 имеет смысл среднего квадратического разброса вокруг нуля возможных значений случайного возмущения
имеет смысл среднего квадратического разброса вокруг нуля возможных значений случайного возмущения  , отражающего влияние на уровень текущего темпа прироста реального ВВП не определенных в модели факторов.
, отражающего влияние на уровень текущего темпа прироста реального ВВП не определенных в модели факторов. (приближенный значения) неизвестных параметров.
(приближенный значения) неизвестных параметров. исследуется на адекватность.
исследуется на адекватность.
 У нас построена линейная эконометрическая модель с изолированными переменными:
У нас построена линейная эконометрическая модель с изолированными переменными: .
. оценка среднего квадратичного отклонения остатка (оценка случайного возмущения)
оценка среднего квадратичного отклонения остатка (оценка случайного возмущения)
 регрессионная сумма квадратов
регрессионная сумма квадратов
 остаточная сумма квадратов
остаточная сумма квадратов
 .
. .
.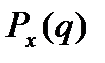 скалярного аргумента q с областью определения
скалярного аргумента q с областью определения  , характеризующая возможность появления в опыте значений q случайной переменной x.
, характеризующая возможность появления в опыте значений q случайной переменной x.
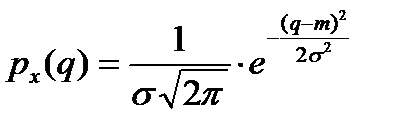

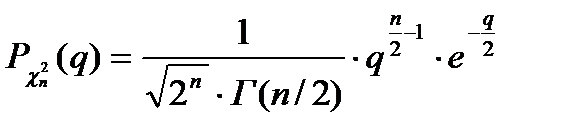 ,
,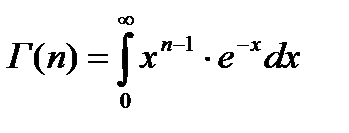 , где n-натуральное число(параметр закона).
, где n-натуральное число(параметр закона). и её расчёт в Excel.
и её расчёт в Excel.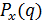 скалярного аргумента q, определенная на всей числовой прямой, характеризующую объективную возможность появления в опыте значений q случайной переменной x.
скалярного аргумента q, определенная на всей числовой прямой, характеризующую объективную возможность появления в опыте значений q случайной переменной x. скалярного аргумента q, определённая на всей числовой прямой, характеризующая объективную возможность появления в опыте
скалярного аргумента q, определённая на всей числовой прямой, характеризующая объективную возможность появления в опыте  значений СП x. Если x – ДСП, то
значений СП x. Если x – ДСП, то 


 ,
,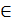 N(0;1)): (x1, х2,…,хn, хn+1)
N(0;1)): (x1, х2,…,хn, хn+1)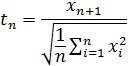
 (3)
(3) (4)
(4) ,
, = 0, то связь между переменными x и y либо вообще отсутствует, либо же имеет место функциональная (жесткая), но нелинейная зависимость.
= 0, то связь между переменными x и y либо вообще отсутствует, либо же имеет место функциональная (жесткая), но нелинейная зависимость.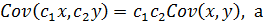

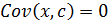 ;
; ;
;

 и её расчёт в Excel.
и её расчёт в Excel.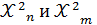 - две независимые случайные переменные, имеющие
- две независимые случайные переменные, имеющие  распределение с числом степеней свободы n и m.
распределение с числом степеней свободы n и m. называется дробью Фишера. Это позволяет при любом альфа вычислить
называется дробью Фишера. Это позволяет при любом альфа вычислить  , удовлетворяющее уравнению
, удовлетворяющее уравнению 
 , также называется Fкрит уровня
, также называется Fкрит уровня  Эту величины также можно вычислить в Excel, используя функцию FРАСПОБР по аргументам
Эту величины также можно вычислить в Excel, используя функцию FРАСПОБР по аргументам 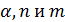 .
. левых частей схемы Гаусса – Маркова при гомоскедастичном неавтокоррелированном остатке).
левых частей схемы Гаусса – Маркова при гомоскедастичном неавтокоррелированном остатке). . Этот упорядоченный набор называется случайным вектором и обозначается
. Этот упорядоченный набор называется случайным вектором и обозначается 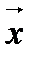 :
: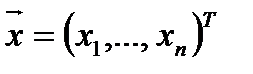 (1)
(1)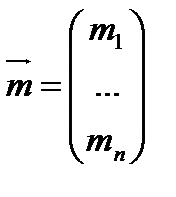
 .
. (2)
(2)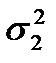 - это дисперсия компоненты
- это дисперсия компоненты  вектора (1). Элемент
вектора (1). Элемент  - это ковариация компонент
- это ковариация компонент  и
и  вектора (1) Матрица является симметричной.
вектора (1) Матрица является симметричной.
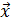 в общем случае не зависят от случайного остатка
в общем случае не зависят от случайного остатка  . Данная модель является базовой моделью эконометрики, потому что к такому виду может быть трансформирована практически любая эконометрическая модель в виде изолированного уравнения.
. Данная модель является базовой моделью эконометрики, потому что к такому виду может быть трансформирована практически любая эконометрическая модель в виде изолированного уравнения.
 , причём
, причём 
 ). Вот компактная запись этой схемы
). Вот компактная запись этой схемы 
 - вектор известных значений эндогенной переменной yt модели;
- вектор известных значений эндогенной переменной yt модели; - вектор неизвестных значений случайных возмущений ut;
- вектор неизвестных значений случайных возмущений ut; - матрица известных значений предопределенной переменной wt модели, расширенная столбцом единиц;
- матрица известных значений предопределенной переменной wt модели, расширенная столбцом единиц; – вектор неизвестных коэффициентов уравнения модели.
– вектор неизвестных коэффициентов уравнения модели. . Тот факт, что эта оценка вычисляется по выборочным данным при помощи некоторой статистической процедуры, отразим:
. Тот факт, что эта оценка вычисляется по выборочным данным при помощи некоторой статистической процедуры, отразим: 
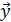 значений эндогенной переменной yt, если:
значений эндогенной переменной yt, если:  .
. , где матрица коэффициентов, зависящих только от выборочных значений W предопределенной переменной wt
, где матрица коэффициентов, зависящих только от выборочных значений W предопределенной переменной wt



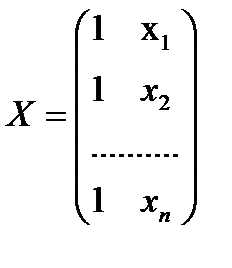 - матрица известных значений предопределенной переменной x исходной модели, расширенная столбцом единиц (при наличии a0);
- матрица известных значений предопределенной переменной x исходной модели, расширенная столбцом единиц (при наличии a0);
 .
. обозначим символом F.
обозначим символом F. , которая обладает одновременно двумя свойствами: ожидаемая оценка параметра совпадает с истинным значением
, которая обладает одновременно двумя свойствами: ожидаемая оценка параметра совпадает с истинным значением
 , i=0,1 (эффективности).
, i=0,1 (эффективности). и доказательство их несмещённости.
и доказательство их несмещённости. – оптимальная линейная процедура оценивания коэффициентов функции регрессии. Докажем, что имеет место свойство несмещенности оценок коэффициентов, то есть
– оптимальная линейная процедура оценивания коэффициентов функции регрессии. Докажем, что имеет место свойство несмещенности оценок коэффициентов, то есть  .
. .
. , ч.т.д.
, ч.т.д. , где
, где  – диагональный элемент матрицы
– диагональный элемент матрицы  . В матричном виде можно представить так (так показано в учебнике)
. В матричном виде можно представить так (так показано в учебнике)  .
. где I – единичная матрица. Теперь обратимся к утверждению А теоремы Гаусса-Маркова:
где I – единичная матрица. Теперь обратимся к утверждению А теоремы Гаусса-Маркова:  . Это значит, что мы можем воспользоваться теоремой Фишера при расчете ковариационной матрицы:
. Это значит, что мы можем воспользоваться теоремой Фишера при расчете ковариационной матрицы:  , где
, где 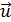 . С учетом вида матрица А и выполненных действий, мы пришли к исходному виду ковариационной матрицы вектора
. С учетом вида матрица А и выполненных действий, мы пришли к исходному виду ковариационной матрицы вектора  .
.
 -> min.
-> min. .
. .
. . Именно это свойство является причиной общепринятого названия процедуры А – МНК.
. Именно это свойство является причиной общепринятого названия процедуры А – МНК. .
. .
. и показатель степени λ. Параметр λ подбирается в итоге проведения теста Голдфилда-Квандта из множества значений ±0,5, ±1, ±2 так, чтобы тест Голдфилда-Квандта просигнализировал о гомоскедастичности остатка в преобразованной ЛММР. (Заметим, что если остаток λ=0, то остаток в модели гомоскедастичен и константа
и показатель степени λ. Параметр λ подбирается в итоге проведения теста Голдфилда-Квандта из множества значений ±0,5, ±1, ±2 так, чтобы тест Голдфилда-Квандта просигнализировал о гомоскедастичности остатка в преобразованной ЛММР. (Заметим, что если остаток λ=0, то остаток в модели гомоскедастичен и константа 


