Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Общая характеристика методов сбора данных, понятие информативности данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Методы сбора данных Есть несколько методов сбора необходимых для анализа данных. 1. Получение из учетных систем. Обычно в учетных системах есть различные механизмы построения отчетов и экспорта данных, поэтому извлечение нужной информации из них чаще всего относительно несложная операция. 2. Получение данных из косвенных источников информации. О многих показателях можно судить по косвенным признакам, и этим нужно воспользоваться. Например, можно оценить реальное финансовое положение жителей определенного региона следующим образом. В большинстве случаев имеется несколько товаров, предназначенных для выполнения одной и той же функции, но отличающихся по цене: товары для бедных, средних и богатых. Если получить отчет о продажах товара в интересующем регионе и проанализировать пропорции, в которых продаются товары для бедных, средних и богатых, то можно предположить, что чем больше доля дорогих изделий из одной товарной группы, тем более состоятельны в среднем жители данного региона. 3. Использование открытых источников. Большое количество данных присутствует в таких открытых источниках, как статистические сборники, отчеты корпораций, опубликованные результаты маркетинговых исследований и пр. 4. Приобретение аналитических отчетов у специализированных компаний. На рынке работает множество компаний, которые профессионально занимаются сбором данных и представлением результатов клиентам для последующего анализа. Собираемая информация обычно представляется в виде различных таблиц и сводок, которые с успехом можно применять при анализе. Стоимость получения подобной информации чаще всего относительно невысока. 5. Проведение собственных маркетинговых исследований и аналогичных мероприятий по сбору данных. Этот вариант сбора данных может быть достаточно дорогостоящим, но в любом случае он существует. 6. Ввод данных вручную. Данные вводятся поразличного рода экспертным оценкам сотрудниками организации. Такой метод является наиболее трудоемким.
Методы сбора информации существенно отличаются по стоимости и необходимому времени, поэтому следует соизмерять затраты с результатами. Возможно, от сбора некоторых данных придется отказаться, но факторы, которые эксперты оценили как наиболее значимые, нужно собрать обязательно, несмотря на стоимость этих работ, либо вообще не проводить анализ. Данные должны быть собраны в единую таблицу в формате Excel, DBase, в текстовые файлы с разделителями или в набор таблиц в любой реляционной СУБД (системе управления базами данных), то есть должны быть представлены в структурированном виде. Кроме того, необходимо унифицировать представление данных: один и тот же объект должен везде описываться одинаково.
Информативностьданных
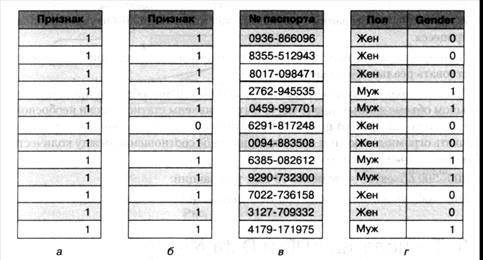
Одной из распространенных ошибок при сборе данных из структурированных источников является стремление взять для анализа как можно больше признаков, описывающих объекты. Между тем предварительная оценка данных, которая проводится визуально при помощи таблиц и базовой статистической информации по на6ору данных, существенно помогает в определении информативности признаков с точки зрения анализа. Среди неинформативных признаков выделяется четыре типа: признаки, содержащие только одно значение (рис. а); признаки, содержащие в основном одно значение (рис.6); признаки с уникальными значениями (рис. в); признаки, между которыми имеет место сильная корреляция, — в этом случае для анализа можно взять один столбец (рис. г).
Рис. Примеры неинформативных признаков Признаки, содержащие в основном одно значение, не всегда могут быть неинформативными, многое зависит от целей анализа. Например, при решении задачи анализа отклонений такие признаки могут существенно повлиять на построение моделей. Общая характеристика методики извлечения знаний Методика извлечения знаний Несмотря на разнообразие бизнес-задач, почти все они могут решаться по единой методике. Эта методика, зародившаяся в 1989 г., получила название KnowledgeDiscoveryinDatabases — извлечение знаний из баз данных. Она описывает не конкретный алгоритм или математический аппарат, а последовательность действий, которую необходимо выполнить для обнаружения полезного знания. Методика не зависит от предметной области; это набор атомарных операций, комбинируя которые можно получить нужное решение. KDD включает в себя этапы подготовки данных, выбора информативных признаков, очистки, построения моделей, постобработки и интерпретации полученных результатов. Ядром этого процесса являются методы DataMining, позволяющие обнаруживать закономерности и знания (рис.). KnowledgeDiscoveryinDatabases — процесс получения из данных знаний в виде зависимостей, правил, моделей, обычно состоящий из таких этапов, как выборка данных, их очистка и трансформация, моделирование и интерпретация полученных результатов. Рассмотрим последовательность шагов, выполняемых в процессе KDD.
Выборка данных. Первым шагом в анализе является получение исходной выборки. На основе отобранных данных строятся модели. Здесь требуется активное участие экспертов для выдвижения гипотез и отбора факторов, влияющих на анализируемый процесс. Желательно, чтобы данные были уже собраны и консолидированы. Крайне необходимы удобные механизмы подготовки выборки: запросы, фильтрация данных и сэмплинг. Чаще всего в качестве источника рекомендуется использовать специализированное хранилище данных, консолидирующее всю необходимую для анализа информацию. Очистка данных. Реальные данные для анализа редко бывают хорошего качества. Необходимость в предварительной обработке при анализе данных возникает независимо от того, какие технологии и алгоритмы используются. Более того, эта задача может представлять самостоятельную ценность в областях, не имеющих непосредственного отношения к анализу данных. К задачам очистки данных относятся: заполнение пропусков, подавление аномальных значений, сглаживание, исключение дубликатов и противоречий и пр. Трансформация данных. Этот шаг необходим для тех методов, при использовании которых исходные данные должны быть представлены в каком-то определенном виде. Дело в том, что различные алгоритмы анализа требуют специальным образом подготовленных данных. Например, для прогнозирования необходимо преобразовать временной ряд при помощи скользящего окна или вычислить агрегированные показатели. К задачам трансформации данных относятся: скользящее окно, приведение типов, выделение временных интервалов, квантование, сортировка, группировка и пр. DataMining.На этом этапе строятся модели. Интерпретация. В случае, когда извлеченные зависимости и шаблоны непрозрачны для пользователя, должны существовать методы постобработки, позволяяющие привести их к интерпретируемому виду. Для оценки качества полученной модели нужно использовать как формальные методы, так и знания аналитика. Именно аналитик может сказать, насколько применима полученная модель к реальным данным. Построенные модели являются, по сути, формализованными знаниями эксперта, а следовательно, их можно тиражировать. Найденные знания должны быть применимы и к новым данным с некоторой степенью достоверности.
|
||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 727; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.008 с.) |