
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модель однофакторного дисперсионного анализаСодержание книги
Поиск на нашем сайте
Прежде, чем говорить о строгом способе решения поставленной задачи, необходимо четко описать ту модель, которая лежит в основе всех формальных построений. Модель кажется очень простой. Но далее, перейдя к рассмотрению двухфакторного дисперсионного анализа, мы увидим, что подобные модели могут быть гораздо более сложными и неочевидными. Научиться же строить подобные модели надо. Причин тому, по крайней мере, две. Во-первых, подобного рода модели используются очень часто: в регрессионном, логлинейном и других видах анализа данных. И их смысл надо хорошо понять, чтобы иметь возможность читать соответствующую литературу. Во-вторых, хорошее понимание смысла подобных моделей, на наш взгляд, может способствовать усвоению очень актуального методологического принципа - прежде, чем собирать данные, необходимо сформировать систему «аксиом», четко обрисовывающих априорное представление социолога о том, что он изучает. При всей своей очевидности это положение на практике часто не выполняется. В результате используются анкеты, в которые включены вопросы, не имеющие отношения к делу, не включены необходимые вопросы и т.д. Все методы анализа данных опираются на такие априорные аксиомы. Они и составляют суть модели, заложенной в том или ином методе. Привычка пользоваться методами, как нам представляется, должна способствовать выработке состоятельного с методологической точки зрения подхода к планированию социологического исследования. Или, коротко говоря, – математика может научить социолога методологической грамотности. В данном случае имеется в виду одна «аксиома» – четкая формулировка того, отчего зависит основной интересующий исследователя признак Y. Предположение о том, из чего для каждого конкретного респондента формируется уровень признака Y, выглядит следующим образом:
где Сделаем несколько замечаний по поводу отдельных членов модели. Сущность По поводу
Если же окажется, что Выборочной оценкой величины
Все три элемента модели могут быть расценены как вклады в вариацию признака Y, как источники такой вариации.
|
||||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 309; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.78.249 (0.008 с.) |

 ,
, - некий средний уровень, на фоне которого изучается действие фактора Х на признак Y;
- некий средний уровень, на фоне которого изучается действие фактора Х на признак Y; 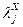 - это вклад в формирование значения зависимого признака j - го уровня фактора Х;
- это вклад в формирование значения зависимого признака j - го уровня фактора Х; 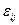 - добавка, отражающая специфические характеристики именно того (неповторимого) респондента, который включен в j-ю ячейку и имеет в ней номер i.
- добавка, отражающая специфические характеристики именно того (неповторимого) респондента, который включен в j-ю ячейку и имеет в ней номер i. .
. .
. этой суммой (а мы ищем именно такой фактор, чтобы равенство
этой суммой (а мы ищем именно такой фактор, чтобы равенство  будет примерно таким же по модулю, но положительным (из-за того, скажем, что этот респондент весь год усиленно занимался дополнительно с преподавателем). Обычно предполагается, что величины
будет примерно таким же по модулю, но положительным (из-за того, скажем, что этот респондент весь год усиленно занимался дополнительно с преподавателем). Обычно предполагается, что величины  .
.


