Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Формирование и уточнение правилСодержание книги
Поиск на нашем сайте
N-C-C-C-> N-C*C-C.
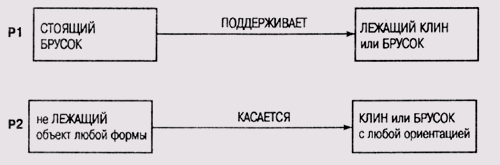
Выходная информация программы INTSUM передается программе эвристического поиска RULEGEN, которая играет в Meta-DENDRAL, ту же роль, что и программа CONGEN в DENDRAL. Но в отличие от CONGEN, она формирует не гипотезы о структурах молекул, а более общие гипотетические правила расщепления, которые, например, могут предполагать и множественные разрывы связей в молекулах. Эти правила должны охватывать все случаи, представленные в обучающей выборке, сформированной программой INTSUM. После того как будет сформировано множество гипотетических правил, в дело вступает программа RULEMOD, на которую возложено выполнение последней фазы процесса, — фазы тестирования и модификации правил. Разделение нагрузки между программами RULEGEN и RULEMOD следующее: программа RULEGEN выполняет сравнительно поверхностный поиск в пространстве правил и формирует при этом приблизительные и избыточные правила, а программа RULEMOD выполняет более глубокий поиск и уточняет набор гипотетических правил. Алгоритм работы программы RULEMOD и по сей день представляет определенный интерес, хотя со времени ее создания прошло более 30 лет. Задачи, которые решает эта программа, типичны для всех программ тонкой настройки правил. (1) Устранение избыточности. Данные, поступающие на вход программы (гипотетические правила), могут быть переопределены, т.е. несколько правил, сформированных на предыдущем этапе, объясняют одни и те же факты. Обычно в окончательный набор правил нужно включить только часть из них. При выполнении этой задачи также удаляются правила, которые вносят противоречие во всю совокупность или порождают некорректные предсказания. (2) Слияние правил. Иногда несколько правил, взятых в совокупности, объясняют сразу множество фактов, и эту совокупность имеет смысл объединить в одно, более общее правило, которое будет включать все позитивные свидетельства и не содержать ни одного негативного. Если удастся отыскать такое совокупное правило, то им заменяются в окончательном наборе все его исходные компоненты. (3) Специализация правила. Иногда оказывается, что слишком общее правило порождает некорректные предсказания, т.е. в его "зону охвата" попадают и негативные свидетельства. В таком случае нужно попытаться добавить в правило уточняющие компоненты, которые помогут исключить из "зоны охвата" правила негативные свидетельства, но сохранят охват всех позитивных свидетельств. В результате правило станет более специализированным. (4) Обобщение правила. Поскольку порождение правил выполняется на основе обучающей выборки ограниченного объема, то среди сформированных правил могут оказаться и такие, в которых специализация выходит за рамки разумного. Программа пытается сохранить только минимальный набор условий в левой части правила, необходимый для обеспечения корректности правила на данной тестовой выборке. (5) Отбор правил в окончательный набор. После обобщения и специализации правил в наборе вся совокупность может снова стать избыточной. Поэтому программа снова повторяет процедуру устранения избыточности, описанную в п. 1. Все описанные процедуры могут итеративно повторяться до тех пор, пока пользователь не будет удовлетворен сформированным набором правил. Единственное, что после этого еще остается сделать пользователю — присвоить правилам веса. Ниже в этой главе мы покажем, как на практике выполняется формирование набора правил. Качество правил, сформированных системой Meta-DENDRAL, проверялось на наборе структур, не включенных в обучающую выборку. Они также сравнивались с теми правилами, которые имеются в опубликованных источниках, и анализировались опытными специалистами по спектрометрии органических соединений. Программа успешно "открыла" опубликованные правила и, более того, нашла новые. Способность сформированных правил предсказать вид спектра соединений, ранее ей неизвестных, поразила специалистов. Однако ни DENDRAL, ни Meta-DENDRAL не стали коммерческими программными продуктами, хотя многие идеи, рожденные в процессе работы над этим проектом, и нашли широкое применение в компьютерной химии. Различные модули этих программ были включены в состав других программных комплексов, в частности в системы управления базой данных химических соединений [Feigenbaum and Buchanan, 1993]. Пространство версий В этом разделе мы рассмотрим одну из методик обучения, которая получила в литературе наименование пространство версий (version space) [Mitchell, 1978], [Mitchell, 1982], [Mitchell, 1997]. Эта методика была реализована во второй версии системы Meta-DENDRAL. При выводе общего правила масс-спектрометрии из набора примеров, демонстрирующих, как определенные молекулы расщепляются на фрагменты, в этой версии Meta-DENDRAL интенсивно используется механизм обучения концептам, о котором мы рассказывали выше. В работе [Mitchell, 1978] так формулируется проблема обучения концептам. "Концепт можно представить как образец, который обладает свойствами, общими для всех экземпляров этого концепта. Задача состоит в том, чтобы при заданном языке описания образцов концептов и наличии обучающей выборки — наборе позитивных и негативных экземпляров целевого концепта и способе сопоставления данных из обучающей выборки и гипотез описания концепта — построить описание концепта, совместимого со всеми экземплярами в обучающей выборке". В этом контексте "совместимость" означает, что сформированное описание должно охватывать все позитивные экземпляры и не охватывать ни один негативный экземпляр. Для того чтобы "рассуждать" о правилах, касающихся масс-спектрометрии, система Meta-DENDRAL должна располагать языком представления концептов и отношений между ними в этой предметной области. В Meta-DENDRAL это объектно-ориентированный язык (см. главу 6), который описывает сеть с помощью узлов и связей между ними. Узлы представляют атомы в структуре молекулы, а связи — химические связи в молекуле. В этом языке некоторый экземпляр в обучающей выборке соответствует образцу в том случае, если сопоставимы все их узлы и связи и удовлетворяются все ограничения, специфицированные в описании образца. В контексте проблемы обучения концептам пространство версий есть не что иное, как способ представления всех описаний концептов, совместимых в оговоренном выше смысле со всеми экземплярами в обучающей выборке. Главное достоинство использованной Митчеллом (Mitchell) методики представления и обновления пространств версий состоит в том, что версии могут строиться последовательно одна за другой, не оглядываясь на ранее обработанные экземпляры или ранее отвергнутые гипотезы описаний концептов. Митчелл отыскал ключ к решению проблемы эффективного представления и обновления пространств версий, заметив, что пространство поиска допустимых описаний концептов является избыточным. В частности, он пришел к выводу, что можно выполнить частичное упорядочение образцов, сформированных описаниями концептов. Самым важным является отношение "более специфичный чем или равный", которое формулируется следующим образом. "Образец Р1 более специфичен или равен образцу Р2 (это записывается в форме Р2 =< Р2) тогда и только тогда, когда Р1 сопоставим с подмножеством всех образцов, с которыми сопоставим образец Р2". Рассмотрим следующий простой пример из обучающей программы для "мира блоков" [Winston, 1975, а]. На рис. 20.1 образец Р1 более специфичен, чем образец Р2, поскольку ограничения, специфицированные в образце Р1, удовлетворяются только в том случае, если удовлетворяются более слабые ограничения, специфицированные в образце Р2. Можно посмотреть на эту пару образцов и с другой точки зрения: если в некотором экземпляре удовлетворяются ограничения, специфицированные в образце Р1, то обязательно удовлетворяются и условия, специфицированные в образце Р2, но не наоборот.
Рис. 20.1. Отношения между образцами Обратите внимание на следующий нюанс. Для того чтобы программа смогла выполнить упорядочение представленных образцов, она должна быть способна разобраться в смысле множества понятий и отношений между ними, которые специфичны для данной предметной области. Программа должна понимать, что если В — это "брусок", то, значит, В — это одновременно и "объект произвольной формы", т.е. в программу должны быть заложены определенные критерии, которые помогут ей выделить категории сущностей, представленных узлами в языке описания структуры образцов. Программа должна знать, что если А "поддерживает" В, то, следовательно, А "касается" В в мире блоков, т.е. программа должна обладать способностью разобраться в избыточности отношений между объектами в предметной области. Программа должна понимать логический смысл таких терминов, как "не", "любой" и "или", и то как они влияют на ограничения или разрешения в процессе сопоставления образцов. Все эти знания необходимы программе для того, чтобы она смогла сопоставить образец Р1 с Р2, т.е. узлы и связи в одном образце с узлами и связями в другом, и выяснить, что любое ограничение, специфицированное в Р1, является более жестким, более специфичным, чем соответствующее ему ограничение в образце Р2. Если программа сможет во всем этом разобраться, то открывается путь к представлению пространств версий в терминах большей "специфичности" или большей "общности" образцов в этом пространстве. Тогда программа может рассматривать некоторое пространство версий как содержащее: множество максимально специфических образцов; множество максимально обобщенных образцов;
|
||||
|
|
Последнее изменение этой страницы: 2021-07-18; просмотров: 58; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.72.24 (0.009 с.) |