Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Векторные конвейерные процессорыСодержание книги
Поиск на нашем сайте
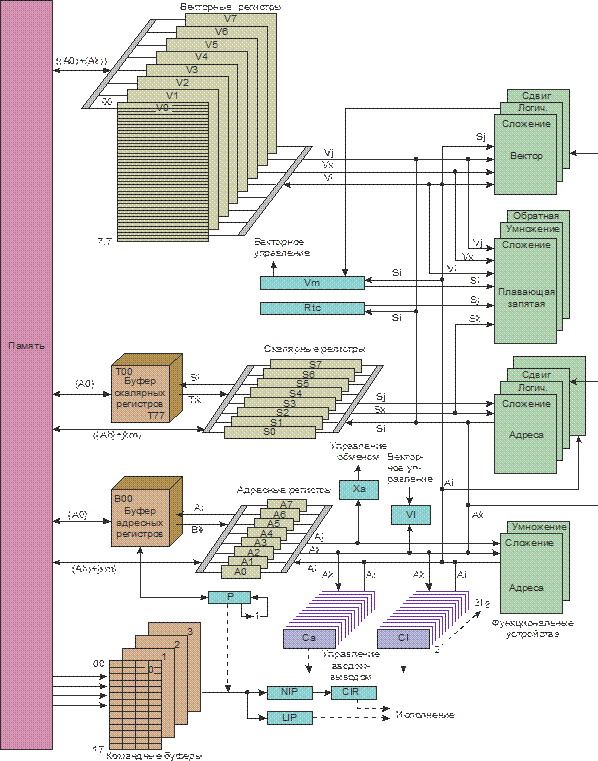
Архитектура машины Cray-1 На рисунке 2.13 приведена блок-схема машины Cray-1. Всего имеется 12 функциональных устройств [2, 11]. Они разделены на группы в зависимости от типа выполняемых ими операций и адресуемых регистров. Выполняют вычисление адресов, логические, скалярные и векторные операции над целыми числами, операции с плавающей запятой над скалярами и векторами. Большинство простых операций центрального процессора выполняется за один такт, который составляет 12.5 нс. Производительность однопроцессорной машины Cray-1 составляет примерно 100*106 операций с плавающей точкой в секунду (100 Мфлопс). В более новых и более мощных моделях машинах системы Cray, выпускаемых фирмой Silicon Grafics, использовались от 2 до 8 процессоров и производительность составляла от 1 до 2,5 Гфлопс. С 1998 года фирма Silicon Grafics приступила к выпуску векторной масштабируемой (то есть с изменяемой конфигурацией) суперЭВМ серии Cray SV1. В суперкомпьютере используются векторные процессоры, пиковая производительность которых достигает 4 Гфлопс. Пиковая производительность заключенного в один корпус узла составляет 32 Гфлопс. Общее число процессоров системы может быть больше 1000. Согласно планам, объявленным компанией, вслед за первым поколением Cray SV1 появится векторный масштабируемый суперкомпьютер второго поколения, пиковая производительность которого составит десятки терафлопс.
Рисунок 2.13-Функциональные блоки и регистры машины CRAY-1
Многопроцессорные векторные суперкомпьютеры Cray SV1 Рынок современных многопроцессорных векторных (векторно-параллельных) суперкомпьютеров достаточно узок. На этом поле «играют» только избранные — прежде всего это американская компания SGI, производящая компьютеры с маркой Cray, и японские NEC и Fujitsu [11]. Все прогнозы об уходе компьютеров этой архитектуры с рынка пока не оправдались. Векторные процессоры NEC SX-5 и Cray SV-1 по-прежнему значительно опережают по производительности вычислений с плавающей запятой самые быстродействующие микропроцессоры. И все же рискну предположить, что доля векторных систем в парке установленных суперкомпьютеров будет постепенно уменьшаться. В то же время сохраняются серьезные задачи, в которых применение векторных систем весьма эффективно. Сray SV1, последнее поколение векторных систем SGI/Cray, о котором было объявлено еще в 1998 году, можно считать наследником мини-суперкомпьютеров Cray J90, представленных в 1994 году.
Рисунок 2.14 – Внешний вид суперЭВМ Сray SV1
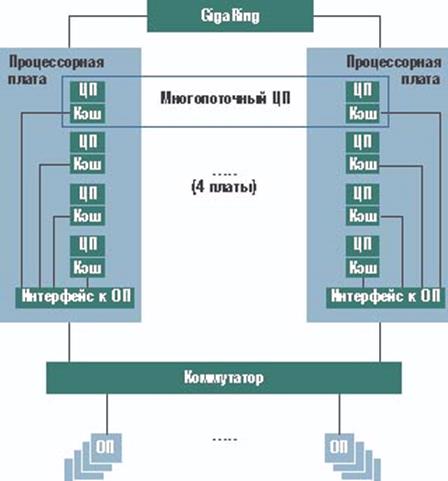
Внешний вид суперЭВМ Cray SV1 представлен на рисунке 2.14, а общая архитектура - на рисунке 2.15. Ее анализ стоит начать с главного козыря SV1 — ее центрального процессора. «Базовые» процессоры SV1 имеют по два векторных конвейера, каждый из которых может выполнять две операции с плавающей запятой за один такт. При тактовой частоте в 250 МГц это дает производительность 1 GFLOPS, что в пять раз выше, чем у 100-мегагерцевого Cray J90, но по-прежнему уступает RISC-микропроцессорам. В 1999 году появилась версия Cray SV1 с 300-мегагерцевым процессором с производительностью уже 1,2 GFLOPS, но и это ниже, чем у некоторых RISC-микропроцессоров.
Рисунок 2.15 – Архитектура Cray SV1-1A с коммутатором 4х4
Однако, из обычных процессоров Cray SV1 можно сконфигурировать так называемые многопоточные процессоры путем объединения четырех стандартных двухконвейерных процессоров в один. При этом все векторные регистры отдельных процессоров становятся общими, число конвейеров становится равным восьми, а пиковая производительность — 4/4,8 GFLOPS для процессоров на 250/300 МГц соответственно. Вот это уже превышает возможности RISC-микропроцессоров, не перешагнувших границу 2 GFLOPS. Многопоточные процессоры побеждают по производительности также и Cray T90 (1,8 GFLOPS), хотя сильно отстают от японских конкурентов — NEC SX-5 (8 GFLOPS, см. таблицу) и Fujitsu VPP5000 (9,6 GFLOPS). Оценка производительности процессора SV1 на тестах Linpack (536 MFLOPS при N = 100, 996 MFLOPS при N = 1000) подтверждает это соотношение. Не стоит забывать и об отношении стоимоcть/производительность, которое для Cray SV1 очень хорошее. Известно, что одним из основных преимуществ векторно-параллельных суперкомпьютеров перед многопроцессорными системами на базе «серийных» RISC-микропроцессоров является гораздо более высокая пропускная способность памяти. Резкое повышение производительности центрального процессора при сохранении пропускной способности оперативной памяти в Cray SV1 делает эту характеристику потенциально узким местом. Известно, что одним из основных преимуществ векторно-параллельных суперкомпьютеров перед многопроцессорными системами на базе «серийных» RISC-микропроцессоров является гораздо более высокая пропускная способность памяти. Резкое повышение производительности центрального процессора при сохранении пропускной способности оперативной памяти в Cray SV1 делает эту характеристику потенциально узким местом. IDC в своем отчете отмечает, что SGI следует работать над увеличением пропускной способности памяти. Длина строки кэша равна 8 байт, что эквивалентно одному элементу векторного регистра. Если в Cray J90 восемь векторных регистров по 64 элемента в каждом, то есть всего 512 элементов, то емкость векторного кэша SV1 — уже 32К элементов. Однако для оптимизации использования векторного кэша существующие векторные приложения для компьютеров Cray предыдущих поколений должны быть переработаны. На каждой процессорной плате размещается по четыре процессора, которые разделяют общий интерфейс к оперативной памяти. На процессорной плате имеется также интерфейс к каналу ввода/вывода GigaRing с пропускной способностью 1 Гбайт/с. Шкаф SV1 содержит систему с симметрично-многопроцессорной архитектурой, основанной на коммутаторе 8х8 c конструктивом backplane. Его восемь портов используются для подсоединения восьми процессорных плат, а другие восемь портов — для подсоединения оперативной памяти. Соответственно SMP-система SV1 может масштабироваться до 32 двухконвейерных центральных процессоров. Общее число каналов GigaRing на систему может при этом достигать восьми. При конфигурировании многопоточных центральных процессоров каждый такой восьмиконвейерный процессор объединяет в себе четыре двухконвейерных — по одному из четырех разных процессорных плат (см. рисунок). Поэтому многопоточный ЦП обменивается данными с ОП сразу через четыре интерфейса ОП, и ПС ОП для такого ЦП составляет 25,6 Гбайт/с. В обычном шкафу SV1 можно сконфигурировать до шести многопоточных процессоров плюс восемь обычных двухконвейерных. Возможность создания различных смешанных конфигураций, отличающихся числом процессоров разных типов, позволяет точно подстроить конфигурацию SV1 под конкретные особенности задач пользователя. Однако суммарная пиковая производительность SV1 при такой переконфигурации не меняется (до 32/38 GFLOPS при 250/300 МГц соответственно). Оперативная память SV1 построена по технологии DRAM и имеет емкость от 2 до 32 Гбайт. Она может включать 256, 512 и 1024 банка; соответственно максимальный уровень расслоения (чередования адресов) оперативной памяти, используемого для повышения ее пропускной способности, равен 1024. Кроме SMP-систем SV1, SGI предлагает также кластеры на их основе. Основным «строительным блоком» кластера являются четырехузловые системы. До восьми таких блоков можно объединить, доведя общее число процессоров до 1024 (192 многопоточных). Это позволяет иметь суперкомпьютерную систему с емкостью оперативной памятью свыше 1 Тбайт и производительностью свыше 1 TFLOPS (отметим, что самые мощные массивно-параллельные системы, в том числе от самой SGI, этот рубеж превзошли еще раньше). Такие высокие характеристики масштабирования векторных многопроцессорных систем — одна из наиболее привлекательных черт Cray SV1, на что указывает и сама аббревиатура SV (Scalable Vector). Топология кластера может быть различной, но SGI предполагает, что для «маленьких» конфигураций будут чаще использоваться соединения «точка-точка», а для больших — двухмерный тор. Вообще-то Cray SV1 использует воздушное охлаждение, но в кластерных конфигурациях возможно и водяное охлаждение. Стоимость минимальной конфигурации SV1-1A (восемь двухконвейерных центральных процессоров) составляет 500 тыс. долл., а такой же, но с возможностью расширения SV1-1 — 1 млн. долл. Очевидно, что соотношение стоимость/производительность для таких систем выглядит весьма привлекательно.
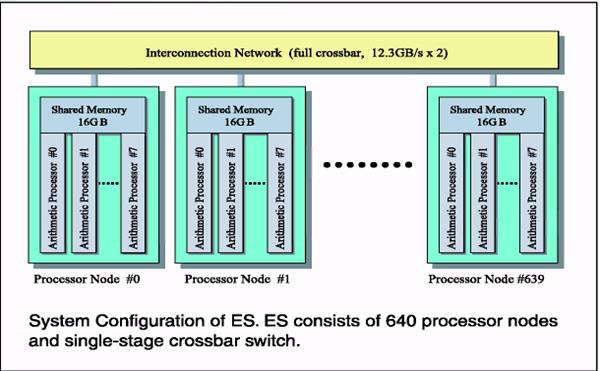
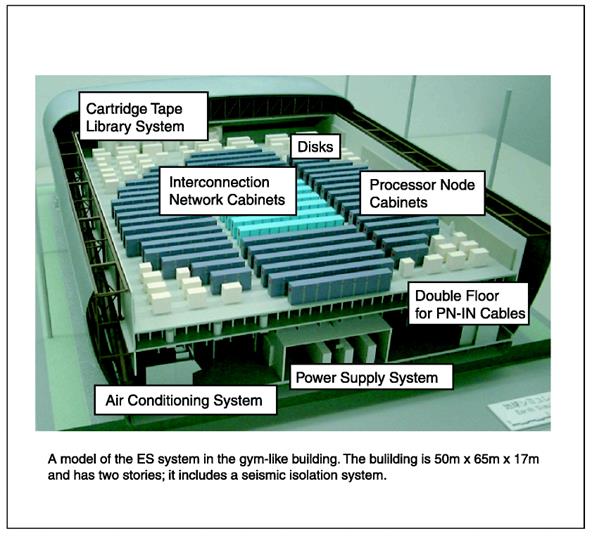
Суперкомпьютер Earth Simulator (ES) Earth Simulator (ES) - мультипроцессорная компьютерная система с распределенной памятью, состоящая из 640 процессорных узлов (PNs), связанных через 640x640 одноступенчатых перекрестных переключателей, образующих внутреннюю высокоскоростную коммутирующую сеть. Каждый PN - система с общей памятью, состоящая из 8 арифметических процессоров векторного типа (APs), оперативной памяти на 16 Гбайт (MS), блока управления удаленного доступа (RCU) и процессора ввода - вывода. Пиковая производительность каждого арифметического процессора (AP) – 8 Gflops. ES в целом, таким образом, состоит из 5120 APs с 10 ТВ оперативной памяти и пиковой производительностью - 40 Tflop/s. На конец 2002 года это - самая высокая производительность в мире.
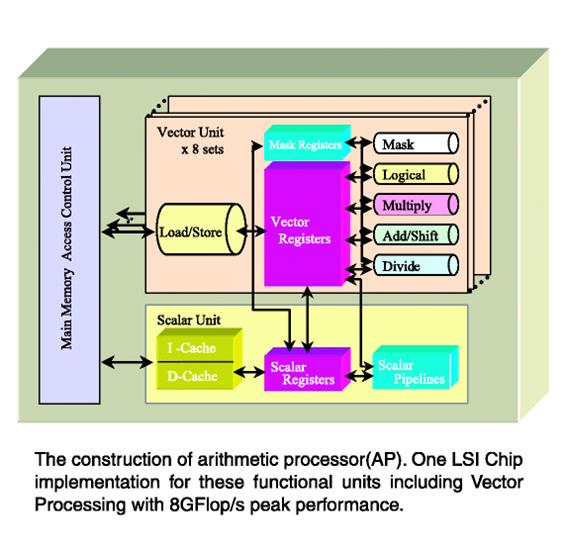
Каждый арифметический процессор (AP) состоит из суперскалярного модуля (SU), векторного модуля (VU) и модуля управления доступом к оперативной памяти, выполненной на отдельной большой интегральной схеме. Арифметический процессор работает на тактовой частоте 500 MHz. Каждый суперскалярный модуль снабжен суперскалярным процессором с кэшем команд на 64 КБ, кэшем данных на 64 КБ и 128 универсальными скалярными регистрами. Здесь выполняются такие операции, как организация ветвлений, предвыборка данных и восстановление сбойных команд. Векторный модуль состоит из 8 наборов, содержащих по 72 векторных регистра, каждый из которых может иметь до 256 векторных элементов, и по шести типов векторных конвейеров:
сложение/сдвиг, умножение, деление, логические операции, маскировка и загрузка/сохранение. VU и SU поддерживают формат данных с плавающей точкой стандарта IEEE 754. Блок управления удаленного доступа (RCU) непосредственно связан с внутренней высокоскоростной коммутирующей сетью и управляет двунаправленной передачей данных между узлами со скоростью 12.3GB/s в каждом направлении. Таким образом, полная полоса пропускания сети – 8 TB/s. Несколько режимов передачи данных, включая доступ к трехмерным подмассивам и косвенные режимы доступа, реализованы аппаратными средствами. В операции доступа к данным подмассива, данные перемещаются от одного PN к другому в единой аппаратной операции за относительно короткое время. Система оперативной памяти (MS) разделена на 2048 банков, и последовательность номеров банков соответствует увеличению адресов слотов в памяти. Поэтому пиковая производительность была получена при обращении к непрерывным данным, расположенным в памяти в порядке возрастания адресов.
Earth Simulator (ES) был разработан как национальный проект Национальным агентством космического развития Японии, Научно-исследовательским институтом атомной энергии Японии и Центром морской науки и технологии Японии. Установлен и введен в эксплуатацию к концу февраля 2002 в Центре моделирования Земли в Йокогаме. Суперкомпьютер размещен на площади 50x65 m.
Ассоциативный процессор
Отсутствие ассоциативных возможностей в фоннеймановской архитектуре приводит к семантическому разрыву между ассоциативной моделью обращения пользователя и обращением по адресу на физическом уровне. Другими словами, необходимы дополнительные средства (т. е. система ссылок — индексов) для определения местонахождения искомых данных [2]. Рассмотрим пример из реальной жизни. Предположим, что в некотором кинотеатре нужно «присматриваться к зрителям». Для этого кассир должен вписать.в план зрительного зала (который представляет собой ряды квадратов, соответствующие местам) имя владельца билета (а не только лица, приобретшего билет). При такой системе учета в кинотеатре появится возможность в случае острой необходимости обнаружить требуемого человека во время просмотра фильма. Достаточно обратиться к администратору, сообщить ему имя нужного человека и в ответ получить номер ряда и места, на котором сидит разыскиваемый зритель. Если это так, то можно (даже в темноте) добраться до указанного места и привлечь внимание нужного зрителя. А что делать, если зритель поменялся с соседом или сел на другое свободное место? Если некоторые зрители опоздали к началу сеанса и сели на первые попавшиеся свободные места? Информация, которую имеет администратор, окажется неверной, что приведет к ошибкам поиска. +Администратор располагает системой адресуемой памяти. Если же у нас была бы система ассоциативного доступа, мы просто объявили бы по радио имя разыскиваемого зрителя. Может случиться, что в зале находятся несколько человек с нужным именем (либо один или даже никого); аналогичная ситуация может иметь место и при поиске ячеек памяти, содержимое которых соответствует поисковому признаку. Следовательно, требуется уметь обрабатывать множественные отклики (многозначный ответ) системы. Этот пример хорошо поясняет принцип работы ассоциативной памяти, но с точки зрения затрат на реализацию эта аналогия не годится. Установка системы с громкоговорителем стоит, вероятно, не больше чем годовой оклад администратора. А ассоциативная память стоит гораздо больше, чем адресуемая. Тем не менее в обоих случаях устранение ссылок и средств их поддержания значительно упрощает систему. Таким образом, в ассоциативной памяти параллельный поиск идет сразу по большой группе ячеек и в итоге поисковому признаку может удовлетворять содержимое нескольких ячеек. Возможности выполнения различных видов поиска и разнообразие структур ассоциативной памяти объясняют, почему для обозначения этого устройства существует так много синонимов: память с параллельным поиском, запоминающее устройство с многозначным ответом, память с распределенной логикой, логико-запоминающее устройство и т.д. Очевидно, что параллельный поиск и другие свойства данной системы делают ее «интеллектуальной» по сравнению с адресной памятью.
|
|||||
|
|
Последнее изменение этой страницы: 2021-05-11; просмотров: 330; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.008 с.) |