
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Ограничения фоннеймановской архитектурыСодержание книги
Поиск на нашем сайте ПРОЦЕССОР С точки зрения логики, все запоминающие устройства (ЗУ) хранят данные, подготовленные к обработке. Суть обработки сводится к передаче данных через канал в центральный процессор (ЦП) с одновременной проверкой. Если данные требуемые, они обрабатываются и результат возвращается через канал либо на устройство вывода, либо в соответствующее запоминающее устройство. В фоннеймановской архитектуре для обработки огромного объема информации мы располагаем всего лишь одним процессором. При этом возникает ситуация, когда миллиарды байтов (символов) информации находятся в состоянии ожидания передачи через канал и обработки на устройстве весьма ограниченной мощности. Такая ситуация для процессора является тупиковой. Для выхода из тупика необходимо внести на этом уровне два изменения в архитектуру: а) использовать параллельные процессоры; б) приблизить процессоры к данным, а не наоборот, чтобы устранить постоянную передачу данных по каналу. Таким образом, решениями являются: а) параллелизм обработки; б) распределенная логика.
ЗАПОМИНАЮЩИЕ УСТРОЙСТВА В ЗУ фоннеймановской архитектуры обращение происходит по адресу. Для числовой обработки это приемлемо. Но при нечисловой обработке обращение должно осуществляться по содержанию. Поскольку для нечисловой обработки используется та же архитектура, что и для числовой, нужно найти способ организации ассоциативного доступа. Таким способом является эмуляция ассоциативной адресации с помощью основного адресного доступа. При этом создаются специальные таблицы (справочники) для перевода ассоциативного запроса в соответствующий адрес. Таблицы называются списками ссылок, или индексами. Они помогают осуществить доступ к конкретной ячейке памяти. Учитывая миллионы и миллиарды байтов, которые нужно обработать, легко представить себе, с какими издержками связаны списки ссылок. Иными словами, чтобы построить список ссылок, нужно продублировать часть данных и присвоить им соответствующие адреса. Поскольку для очень больших объемов информации ссылки объединяются в достаточно большие файлы, приходится громоздить иерархически связанную систему файлов ссылок. Размер файла ссылок, содержащегося на вершине иерархии, доступен для обработки. И хотя с помощью системы ссылок уменьшается время поиска по сравнению с простым просмотром всех данных, мы проигрываем в другом. В системах, где приходится часто обновлять информацию, необходимо также постоянно реорганизовывать всю систему ссылок. По мере того как происходит изменение, добавление или удаление записей, ссылки перестают указывать на нужные адреса в памяти, следовательно, их нужно изменять. А ведь нечисловая обработка — это не только просмотр, но и обновление данных. В результате полная производительность, которая складывается из производительности по выборке и обновлению, резко уменьшается. Итак, для сохранения высокой производительности нужны новые идеи и решения.
Параллельная обработка Необходимость параллельной обработки может возникнуть по следующим причинам [6]: 1. Велико время решения данной задачи. 2. Мала пропускная способность системы. 3. Необходимо улучшение использования системы. Для распараллеливания необходимо соответствующим образом организовать вычисления. Сюда входят: · составление параллельных программ, то есть отображение в явной форме параллельной обработки с помощью надлежащих конструкций языка, ориентированного на параллельные вычисления; · автоматическое обнаружение параллелизма. Последовательная программа может быть автоматически проанализирована и выявлена явная или скрытая параллельная обработка. Последняя должна быть преобразована в явную. Рассмотрим граф, описывающий последовательность процессов большой программы (рисунок 2.1).
Рисунок 2.1- Граф процессов программы
Из рисунка 2.1 видно, что выполнение процесса Р5 не может начаться до завершения процессов Р2 и Р3 и в свою очередь выполнение процессов Р2 и Р3 не может начаться до завершения процесса Р1. В данном случае для выполнения программы достаточно трех процессоров. Ускорение обработки на многопроцессорной системе определяется отношением времени однопроцессорной обработки к времени многопроцессорной обработки, то есть
При автоматическом обнаружении параллельных вычислений в последовательной программе выявляют явную и скрытую параллельную обработку. Хотя в обоих случаях требуется анализ программы, различие между этими видами обработки состоит в том, что скрытая параллельная обработка требует некоторой процедуры преобразования последовательной программы, чтобы сделать возможным ее параллельное выполнение. При анализе программы строится граф потока данных. Чтобы обнаружить явную параллельность процессов, анализируются множества входных (считываемых) переменных R (Read) и выходных (записываемых) переменных W (Write) каждого процесса. Два процесса i, j (i<>j) могут выполняться параллельно при следующих условиях:
где Æ - пустое множество Это означает, что входные данные одного процесса не должны модифицироваться другим процессом и никакие два процесса не должны модифицировать общие переменные. Явная параллельная обработка может быть обнаружена среди процессов, удовлетворяющих этим условиям. Для использования скрытой параллельной обработки требуются преобразования программных конструкций, таких как: · уменьшение высоты деревьев арифметических выражений; · преобразование линейных рекуррентных соотношений; · замена операторов; · преобразование блоков IF и DO к каноническому виду; · распределение циклов. Проиллюстрируем эти преобразования на простых примерах.
|
||
|
|
Последнее изменение этой страницы: 2021-05-11; просмотров: 198; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.16 (0.006 с.) |


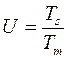 (2.1)
(2.1)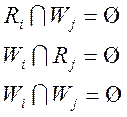 (2.2)
(2.2)


