Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели реального времени (управляемые событиями)Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
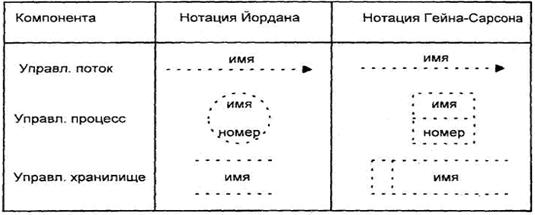
Расширения реального времени используются для дополнения модели функционирования данных (иерархии DFD) средствами описания управляющих аспектов в системах реального времени. Для этих целей применяются символы, представленные на рис. 2.1.
Рис. 2.1. Расширения реального времени
1. Управляющий процесс - это объект расширения DFD для реального времени, который представляет собой интерфейс между DFD и спецификациями управления. Его имя указывает на тип управляющей деятельности, вырабатываемой спецификацией. Фактически управляющий процесс представляет собой преобразователь входных управляющих потоков в выходные управляющие потоки; при этом точное описание этого преобразования должно задаваться в спецификации управления. 2. Управляющее хранилище - это объект расширения DFD для реального времени, который представляет "срез" управляющего потока во времени. Содержащаяся в нем управляющая информация может использоваться в любое время после ее занесения в хранилище, при этом соответствующие данные могут быть использованы в произвольном порядке. Имя управляющего хранилища должно идентифицировать его содержимое и быть существительным. Управляющее хранилище отличается от традиционного хранилища тем, что может содержать только управляющие потоки, все другие их характеристики идентичны. 3. Управляющий поток - это объект расширения DFD для реального времени, который представляет собой поток, через который проходит управляющая информация. Его имя не должно содержать глаголов, а только существительные и прилагательные. Обычно управляющий поток имеет дискретное, а не непрерывное значение. Это может быть, например, сигнал, представляющий состояние или вид операции. Логически управляющий процесс есть некий командный пункт, реагирующий на изменения внешних условий, передаваемые ему с помощью управляющих потоков, и продуцирующий в соответствии со своей внутренней логикой выполняемые процессами команды. При этом режим выполнения процесса зависит от типа управляющего потока. Имеются следующие типы управляющих потоков. 1. Т-поток (trigger flow). Является потоком управления процессом, который может вызывать выполнение процесса. При этом процесс как бы включается одной короткой операцией. Это - аналог выключателя света, единственным нажатием которого "запускается" процесс горения лампы. 2. А-поток (activator flow). Является потоком управления процессом, который может изменять выполнение отдельного процесса. Используется для обеспечения непрерывности выполнения процесса до тех пор, пока поток "включен" (т.е. течет непрерывно), с "выключением" потока выполнение процесса завершается. Это аналог переключателя лампы, которая может быть как включена, так и выключена. 3. E/D-поток (enable/disable flow). Является потоком управления процессом, который может переключать выполнение отдельного процесса. Течение по Е-линии вызывает выполнение процесса, которое продолжается до тех пор, пока не возбуждается течение по D-линии. Это аналог выключателя с двумя кнопками: одна - для включения света, другая для его выключения. Отметим, что можно использовать три типа таких потоков: Е-поток, D-поток, E/D-поток. Иногда возникает необходимость в представлении одного и того же фрагмента данных потоками различных типов. Например, поток данных СКОРОСТЬ МАШИНЫ в отдельных случаях может использоваться как управляющий для контроля критического значения. Для обеспечения этого используется узел изменения типа (рис. 2.2): поток данных является входным для этого узла, а управляющий поток - выходным.
Рис. 2.2. Узел изменения типа
Словарь данных
Диаграммы потоков данных обеспечивают удобное описание функционирования компонент системы, но не снабжают аналитика средствами описания деталей этих компонент, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных задач предназначены текстовые средства моделирования, служащие для описания структуры преобразуемой информации и получившие название словарей данных. Словарь данных представляет собой определенным образом организованный список всех элементов данных системы с их точными определениями. Это дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ. Определения элементов данных в словаре осуществляются следующими видами описаний: - описание значений потоков и хранилищ, изображенных на DFD-диаграмме. - описание композиции агрегатов данных, движущихся вдоль потоков. Иначе говоря, комплексных данных, которые могут расчленяться на элементарные символы (например, АДРЕС ПОКУПАТЕЛЯ содержит ПОЧТОВЫЙ ИНДЕКС, ГОРОД, УЛИЦУ и т.д.). - описание композиции групповых данных в хранилище; - описание деталей отношений между хранилищами; - специфицирование значений и областей действия элементарных фрагментов информации в потоках данных и хранилищах. Для каждого потока данных в словаре необходимо хранить имя потока, его тип и атрибуты. Информация по каждому потоку состоит из ряда словарных статей. Каждая из этих словарных статей начинается с ключевого слова - заголовка соответствующей статьи, которому предшествует символ "@". По типу потока в словаре содержится информация, идентифицирующая: - простые (элементарные) или групповые (комплексные) потоки; - внутренние (существующие только внутри системы) или внешние (связывающие систему с другими системами) потоки; - потоки данных или потоки управления; - непрерывные (принимающие любые значения в пределах определенного диапазона) или дискретные (принимающие определенные значения) потоки. Атрибуты потока данных включают: - имена-синонимы потока данных в соответствии с узлами изменения имени; - БНФ-определение в случае группового потока; - единицы измерения потока; - диапазон значений для непрерывного потока, его типичное значение и информацию по обработке экстремальных значений; - список значений и их смысл для дискретного потока; - список номеров диаграмм различных типов, в которых поток встречается; - список потоков, в которые данный поток входит (как элемент БНФ-определения); - комментарий, включающий дополнительную информацию (например, о цели введения данного потока). Форма Бэкуса-Наура (БНФ) - метаязык, используемый для спецификации синтаксисов различных языков, в том числе и языков систем баз данных. Этот язык был разработан для спецификации синтаксиса языка Алгол-60, среди создателей которого были и авторы БНФ. БНФ-нотация позволяет формально описать расщепление/объединение потоков. Поток может расщепляться на собственные отдельные ветви, на компоненты потока-предка или на то и другое одновременно. При расщеплении/объединении потока существенно, чтобы каждый компонент потока-предка являлся именованным. Если поток расщепляется на подпотоки, необходимо, чтобы все подпотоки являлись компонентами потока-предка. И наоборот, при объединении потоков каждый компонент потока-предка должен, по крайней мере однажды, встречаться среди подпотоков. Отметим, что при объединении подпотоков нет необходимости осуществлять исключение общих компонент, а при расщеплении подпотоки могут иметь такие общие (одинаковые) компоненты. Важно понимать, что точные определения потоков содержатся в словаре данных, а не на диаграммах. Например, на диаграмме может иметься групповой узел с входным потоком X и выходными подпотоками Y и Z. Однако это вовсе не означает, что соответствующее определение в словаре данных обязательно должно выглядеть как X=Y+Z. Это определение может быть следующим: Х=А+В+С; Y=A+B; Z=B+C. Такие определения хранятся в словаре данных в так называемой БНФ-статье. БНФ-статья используется для описания компонент данных в потоках данных и в хранилищах. Синтаксис БНФ-статьи имеет вид: @БНФ = <простой оператор>! <БНФ-выражение>. Здесь выражение в угловых скобках <простой оператор> есть текстовое описание, ограниченное с двух сторон косыми чертами "/", а <БНФ-выражение> есть выражение в форме Бэкуса-Наура, допускающее следующие операции отношений: = - означает "композиция из"; + - означает "И"; [!] - означает "ИЛИ". () - означает, что компонент в скобках необязателен; {} - означает итерацию компонента в скобках; "" - означает литерал. Итерационные скобки могут иметь нижний и верхний пределы, например: 3 {болт} 7 - от 3 до 7 итераций; 1 {болт} - 1 и более итераций; {шайба} 3 - не более 3 итераций. БНФ-выражение может содержать произвольные комбинации операций: @БНФ = [ винт! болт + 2 {гайка} 2 + (прокладка)! клей ]. Приведем пример описания потока данных. БНФ-описание потока данных: @ИМЯ = ВОСЬМЕРИЧНАЯ ЦИФРА @ТИП = дискретный поток @БНФ=["0"!"1!"2"!"3"!"4"!"5"!"6"!"7"]
|
||||
|
|
Последнее изменение этой страницы: 2017-02-08; просмотров: 708; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.128.168.219 (0.011 с.) |