Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Первые системы управления базами данных (начало 70-х гг. )Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Для этого этапа характерно изменение представления о назначении и возможностях систем управления данными. По мере развития средств обработки данных становилось ясно, что прикладные программы желательно сделать независимыми не только от изменений в аппаратных средствах хранения, но также и от добавления к хранимым данным новых полей и новых взаимосвязей. Система должна быть способна обрабатывать новые типы запросов пользователей (рис. 2.4).
Организация хранения и доступа в случае систем управления данными характеризуется следующими особенностями: • различные логические файлы могут быть получены из одних и тех же физических данных. Доступ к одним и тем же данным может осуществляться различными приложениями по различным путям, отвечающим требованиям этих приложений; • данные адресуются на уровне полей и групп. Можно использовать поиск по многим ключам; • физическая структура данных независима от прикладных программ. Ее можно изменять с целью повышения эффективности базы данных, не модифицируя при этом прикладные программы. Использование сложных форм организации данных не требует усложнения прикладных программ; • элементы данных являются общими для различных приложений. Отсутствие избыточности способствует целостности данных. 9. Схемы управления данными в СУБД? (1) — прикладная программа формирует и вещает системе управления базами данных запрос на чтение необходимых данных, содержащихся в базе; (2 — 3) — СУБД отыскивает описание затребованных данных в структуре описания данных прикладного уровня; (4 — 5) — СУБДпо глобальному описанию БД определяет необходимые данные на логическом уровне; (6 — 7) — СУБД по описанию физической структуры БД определяет физическую запись, которую необходимо считать для выборки данных, затребованных прикладной программой; (8 — 9) — СУБД через подсистему управления потоками данных выдает операционной системе запрос на чтение хранимой записи; (10 — 11) — подсистема управления вводом-выводом операционной системы осуществляет физическое чтение записи в системный буфер ОС; (13) — СУБД выделяет необходимую логическую запись, осуществляет форматные преобразования, обусловленные различиями описаний на глобальном и прикладном уровнях, и передает для функциональной обработки приложением данные в рабочий буфер, выделяемый прикладной программой или самой СУБД.
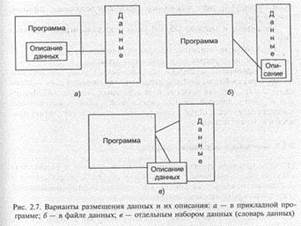
10. Данные и управление их обработкой (типы, форматы, структуры данных, описание и обработка файлов)? Структура информационных единиц, обрабатываемых на ЭВМ,определяетсяследующими понятиями: • тип данных, или совокупность соглашений о программно-аппаратурной форме представления и обработки, а также ввода, контроля и вывода элементарных данных; • структуры данных — способы композиции простых данных в агрегаты и операции над ними; • форматы файлов — представление информации на уровне взаимодействия операционной системы с прикладными программами. Типы данных. Ранние языки программирования — Фортран, Алгол — были ориентированы исключительно на вычисления и не содержали систем типов и структур данных. Типы числовых данных Алгола: INTEGER, REAL — различаются диапазонами изменения, внутренними представлениями и применяемыми командами процессора ЭВМ. Нечисловые данные представлены типом BOOLEAN — логические, имеющие диапазон значений {TRUE, FALSE). Появившиеся позже языки программирования COBOL, PL/1, Pascal уже предусматривают новые типы данных: • символьные; • числовые символьные для вывода; • числовые двоичные для вычислений; • числовые десятичные для вывода и вычислений. Структуры данных. В языке программирования Алгол были определены два типа структур: элементарные данные и массивы. Основным нововведением, появившимся первоначально в Коболе, являются агрегаты данных, представляющие собой именованные комплексы переменных разного типа, описывающих некоторый объект или образующих некоторый достаточно сложный документ. Термин запись подразумевает наличие множества аналогичных по структуре агрегатов, образующих файл, содержащих данные по совокупности однородных объектов. Элементы данных образуют поля, среди которых выделяются элементарные и групповые. Появление СУБД и АИПС приводит к появлению новых разновидностей структур: • множественные поля данных; • периодические групповые поля; • текстовые объекты, имеющие иерархическую структуру. Форматы файлов. В зависимости от типа и назначения файлов и возможностей ОС файл может передаваться в прикладную программу как целое или блоками либо логическими записями. Например, в системе OS/360 основную роль играли два типа файлов: • символьные; • двоичные. В современных системах активно используется значительно большее разнообразие файлов, например, текстовые файлы — обобщенное название для простых и размеченных текстов, ASCII-файлов и других наборов данных символьной информации, которые интерпретируются и обрабатываются текстовыми редакторами, процессорами, анализаторами. Описание и обработка файлов По мере развития средств вычислительной техники и расширения спектра задач, связанных с обработкой на ЭВМ,разработчики и пользователи стали уделять больше внимания информационной стороне вопроса. По-видимому достаточно подробное описание структур данных и установление их связи с файлами было впервые сделано в языке программирования Cobol. Эта проблема была решена следующим образом — файл рассматривается как совокупность записей одинаковой структуры, каждая из которых представляет собой набор разнородных данных. Проблема локализации описания данных. Приемы распознавания программой элементов данных или записей относятся к такому типу взаимодействия программ и данных, когда описание данных размещено в программе, а файл данных организован в соответствии с этим описанием. Однако этот способ может привести к нарушению функционирования или разрушению данных, если из-за ошибок программиста или оператора к программе будет подсоединен «неправильный файл». Для установления независимости программ от данных в некоторых системах описание данных размещают совместно с файлом данных. По такому принципу организован весьма распространенный формат файла данных, происходящий от систем dBase — Clipper — Foxbase — FoxPro, а затем принятый и рядом
других систем. В этом случае в начале файла создается заголовок, содержащий описание полей записи файла, и таким образом, описание данных файла в программе не нужно. Недостатком такого подхода является, например, необходимость использования программистами тех же имен данных, что содержатся в описании файла. Следующим шагом явилось полное отделение описаний от данных и программ и сосредоточение их в специальных файлах — словарях данных), которые относятся к базам данных и системам управления базами данных. 11. Особенности и компромиссы реализаций баз данных? В заключение приведем основные отличительные особенности обработки данных, характерные для файловых систем и систем управления базами данных. Файлыобладают следующими свойствами: • файл, как правило, представляет собой совокупность записей одного типа, доступ к которым определяется типом организации файла и осуществляется только средствами операционной системы; • файл описывают и используют в прикладной программе, работающей с данными. Базы данных имеют следующие особенности: • база данных представляет собой совокупность данных разного типа, причем часто по одним данным получают другие; • база данных существует независимо от конкретной прикладной программы — база создается с целью интеграции данных, объединяющей данные многих приложений. База данных предназначена для совместного, многофункционального использования многими пользователями один раз введенных данных. Надо отметить, что с точки зрения управления данными СУБД оперируют данными на содержательном уровне, хотя физические структуры, используемые для этих целей, могут и совпадать с аналогичными структурами, создаваемые ОС. Коренное же отличие СУБДот файловых систем ОСсостоит в том, что СУБДустанавливает связь между содержанием и адресом, а ОС —между именем и адресом данных. В то же время эта граница постоянно подвергается «атакам» с обеих сторон. Например, ОС-360 с «индексным доступом к данным», IN-PICK, включающая язык поиска записей файлов по содержанию, UNIX,включающая команды сортировки, коррекции или объединения содержимого текстовых файлов, наподобие того, как это осуществляется с таблицами данных в СУБД.Тем не менее, следует признать это скорее исключением, чем правилом и в компетенцию ОС надо относить только связь «имя — адрес», оставляя другие зависимости на ответственность прикладных программ и оболочек СУБД и ГИПС. В общем случае можно сказать, что основные задачи обработки данных, решаемые на основе концепций баз данных, сводятся к следующим вопросам. 1. Каким образом сложные нелинейные структуры данных представить в виде линейных — наиболее соответствующих принципу последовательного представления в машинной памяти? 2. Каким образом организовать данные, чтобы была возможность эффективного внесения, удаления и редактирования данных? 3. Как организовать данные, чтобы использование пространства памяти было достаточно рациональным, а скорость доступа к записям данных высокой? 4. Каким образом организовать данные, чтобы поиск был эффективным и позволял отыскивать записи по нескольким ключам? При этом, с точки зрения прагматики, создание базы данных это, по существу, попытка найти компромисс сразу по нескольким направлениям и сочетаниям нескольких взаимообратных факторов, в том числе следующих: 1) эффективность — простота; 2) скорость выборки — стоимость аппаратных средств; 3) скорость выборки — сложность процедур доступа; 4) плотность данных — время доступа и сложность процедур; 5) независимость данных — производительность; 6) гибкость средств поиска — избыточность данных; 7) гибкость поиска — скорость поиска; 8) сложность процедур доступа — простота обслуживания. 12. Многоуровневые модели предметной области? Обычно отдельная база данных содержит информацию о некоторой предметной области — наборе объектов, представляющих интерес для актуальных или предполагаемых пользователей. То есть, реальный мир отображается совокупностью конкретных и абстрактных понятий, между которыми существуют определенные связи. Выбор для описания предметной области (ПрО) существенных понятий и связей является предпосылкой того, что пользователь будет иметь практически все необходимые ему в рамках задачи знания об объектах предметной области. Однако следует отметить, что пользователь, который хочет работать с базой данных, должен владеть основными понятиями, представляющими предметную область. И в этом смысле абстрагирование позволяет построить такое описание, которое другой человек сможет не только воспринять, но и безошибочно использовать для работы с описаниями экземпляров объектов, хранимых в базе данных. Модель предметной области соотносится с реальными объектами и связями так же, как схема маршрутов городского пассажирского транспорта с фактической траекторией движения автобуса. Схема адекватно отражает действительность на уровне основных понятий — маршрутов и остановок: выбрав по схеме маршрут, пассажир достигнет цели независимо от того, в каком транспортном ряду будет двигаться автобус. Наиболее простой способ представления предметных областей в БД реализуется поэтапно: 1) фиксацией логической точки зрения на данные; 2) определением физического представления данных с учетом выбранных структур хранения данных и архитектуры ЭВМ. Абстрагированное описание предметной области с фиксированной точки зрения будем называть концептуальной схемой. Соответственно, систематизация понятий и связей предметной области называется логическим или концептуальным проектированием. Модель, используемая при абстрагировании — совокупность функциональных характеристик объектов и особенностей представления информации, будем называть моделью данных. Отображение концептуальной схемы на физический уровень будем называть внутренней схемой. Соотношение этих понятий приведено на рис. 3.1. Отражение взгляда отдельного пользователя на концептуальную схему будем называть внешней схемой. Внешняя схема использует те же абстрактные категории, что и концептуальная, а на практике соответствует логической организации данных в прикладной программе, Теоретически вопрос о многообразии уровней абстракции был решен еще в 60 — 70-х гг. Основой для его решения является концепция многоуровневой архитектуры системы базы данных. Например, в отчете CODASYL [24] предусматривался архитектурный уровень подсхемы, который позволял для каждого конкретного приложения строить свое собственное «видение» используемого подмножества базы данных путем определения его «персональной» подсхемы базы данных. В более общем виде этот вопрос решен в архитектурной модели ANSI/ХЗ/SPARC [22]. Здесь на внешнем уровне может поддерживаться совсем иная модель данных, чем на концептуальном уровне. Поддержка разнообразных возможностей абстрагирования в такой системе достигается благодаря средствам определения и поддержки межуровневого отображения моделей данных. Помимо этого, для решения указанной проблемы может использоваться внутри модельная структура, например, механизмы
представлений. В объектных системах для этих целей может использоваться отношение наследования. В общем случае концепция трехуровневого представления не требует более трех уровней, однако с практической точки зрения иногда удобно включать схемы дополнительных уровней. На рис. 3.2 приведены некоторые варианты решений. На рис. 3.2, б выделена логическая схема, учитывающая особенности СУБД. Пример, приведенный на рис. 3.2, в, характерен для варианта распределенной базы данных, объединяющей информацию, представленную разными внутренними схемами. Рассмотренная трехуровневая архитектура обеспечивает выполнение основных требований, предъявляемых к системам баз данных: • адекватность отображения предметной области; • возможность взаимодействия с БД разных пользователей при решении разных прикладных задач;
• обеспечение независимости программ и данных; • надежность функционирования БД и защита от несанкционированного доступа. С точки зрения пользователей различных категорий трехуровневая архитектура имеет следующие достоинства: • системный аналитик, создающий модель предметной области, не обязательно должен быть специалистом в области программирования и вычислительной техники; • администратор баз данных, обеспечивающий отражение концептуальной схемы во внутреннюю, не должен беспокоиться о корректности представления предметной области; • конечные пользователи, используя внешнюю схему, могут не вдаваться полностью в предметную область, обращаясь только к необходимым составляющим. При этом исключается возможность несанкционированного обращения к данным вне объявленных внешней схемой, так как формирование ее находится в сфере деятельности администратора базы данных; • системный аналитик, как и конечный пользователь, не вмешивается во внутреннее представление данных. Это отражает распространенную практику специализации и разделения ответственности. Главное же заключается в том, что работу по проектированию и эксплуатации баз данных можно разделить на три достаточно самостоятельных этапа. Хотя надо отметить, что на практике создание концептуальной схемы не всегда предшествует построению внешней. Иногда трудно с самого начала полностью определить предметную область, но с другой стороны, уже известны требования пользователей. И кроме того, адекватность модели предметной области, в конце концов, должна подтверждаться практикой пользовательских представлений. 13. Идентификация объектов? В задачах обработки информации, и в первую очередь в алгоритмизации и программировании, атрибуты именуют и приписывают им значения. При обработке информации мы, так или иначе, имеем дело с совокупностью объектов, информацию о свойствах каждого из которых надо сохранять как данные, чтобы при решении задач их можно было найти и выполнить необходимые преобразования. Таким образом, любое состояние объекта характеризуется совокупностью актуализированных атрибутов, которые фиксируются на некотором материальном носителе в виде записи — совокупности формализованных элементов данных. Кроме того, в контексте задач хранения и поиска можно говорить, что значение атрибута идентифицирует объект: использование значения в качестве поискового признака позволяет реализовать простой критерий отбора по условию сравнения. Так же как и в реальном мире, отдельный объект всегда уникален. Соответственно, запись, содержащая данные о нем, также должна быть узнаваема однозначно, т. е. иметь уникальный идентификатор, причем никакой другой объект не должен иметь такой же идентификатор. Поскольку идентификатор — суть значение элемента данных, в некоторых случаях для обеспечения уникальности требуется использовать более одного элемента. Например, для однозначной идентификации записей о дисциплинах учебного плана необходимо использовать элементы СЕМЕСТР и НАИМЕНОВАНИЕ ДИСЦИПЛИНЫ, тай как возможно преподавание одной дисциплины в разных семестрах. Предложенная выше схема представляет атрибутивный способ идентификации содержания объекта Она является достаточно естественной для данных, имеющих фактографическую природу и описывающих обычно материальные объекты. Информацию, представляемую такого рода данными, называют хорошо структурированной. Здесь важно отметить, что структурированность относится не только к форме представления данных, но и к способу интерпретации значения пользователем: значение параметра не только представлено в предопределенной форме, но и обычно сопровождается указанием размерности
величины, что позволяет пользователю понимать ее смысл без дополнительных комментариев. Таким образом, фактографические данные предполагают возможность их непосредственной интерпретации. Однако атрибутивный способ практически не подходит для идентификации слабо структурированной информации, связанной с объектами, имеющими обычно идеальную природу — категориями, понятиями, знаковыми системами. Такие объекты зачастую определяются логически и опосредованно — через другие объекты. Для описания таких объектов используются естественные или искусственные языки. Соответственно, для понимания смысла пользователю необходимо использовать соответствующие правила языка, и, более того, часто необходимо уже располагать некоторой информацией, позволяющей идентифицировать и связать получаемую информацию с наличным знанием. То есть процесс интерпретации такого рода данных имеет опосредованный характер и требует использования дополнительной информации, причем такой, которая не обязательно присутствует в формализованном виде в базе данных. Такое разделение нашло отражение в традиционном разделении баз данных на фактографические и документальные. 14. Поиск записей? Программисту или пользователю необходимо иметь возможность обращаться к отдельным, нужным ему записям или отдельным элементам данных. В зависимости от уровня, программного обеспечения прикладной программист может использовать следующие способы. • Задать машинный адрес данных и в соответствии с физическим форматом записи прочитать значение. Это случай, когда программист должен быть «навигатором». • Сообщить системе имя записи или элемента данных, которые он хочет получить, и возможно, организацию набора данных. В этом случае система сама произведет выборку, но для этого она должна будет использовать вспомогательную информацию о структуре данных и организации набора. Такая информация по существу будет избыточной по отношению к объекту, однако общение с базой данных не будет требовать от пользователя знаний программиста и позволит переложить заботы о размещении данных на систему. В качестве ключа, обеспечивающего доступ к записи, можно использовать идентификатор — отдельный элемент данных. Ключ, который идентифицирует запись единственным образом, называется первичным. В том случае, когда ключ идентифицирует некоторую группу записей, имеющих определенное общее свойство, ключ называется вторичным. Набор данных может иметь несколько вторичных ключей, необходимость введения которых определяется практической необходимостью — оптимизацией процессов нахождения записей по соответствующему ключу. Иногда в качестве идентификатора используют составной сцепленный ключ — несколько элементов данных, которые в совокупности, например, обеспечат уникальность идентификации каждой записи набора данных. При этом ключ может храниться в составе записи или отдельно. Например, ключ для записей, имеющих неуникальные значения атрибутов, для устранения избыточности целесообразно хранить отдельно. На рис. 3.4 приведены два таких способа хранения ключей и атрибутов для набора простейшей структуры. Введенное понятие ключа является логическим и его не следует путать с физической реализацией ключа — индексом, обеспечивающим доступ к записям, соответствующим отдельным значениям ключа. Один из способов использования вторичного ключа в качестве входа — организация инвертированного списка, каждый вход которого содержит значение ключа вместе со списком идентификаторов соответствующих записей. Данные в индексе располагаются в возрастающем или убывающем порядке, поэтому алгоритм нахождения
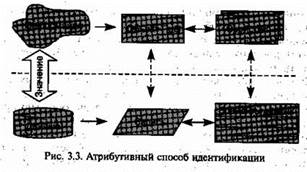
нужного значения довольно прост и эффективен, а после нахождения значения запись локализуется по указателю физического расположения. Недостатком индекса является то, что он занимает дополнительное пространство и его надо обновлять каждый раз, когда удаляется, обновляется или добавляется запись. На рис. 3.5 приведен инвертированный список для предыдущего примера.
В общем случае инвертированный список может быть построен для любого ключа, в том числе составного. В контексте задач поиска можно сказать, что существуют два основных способа организации данных. Первый соответствует примеру, приведенному на рис. 3.3, и представляет прямую организацию массива. Второй способ является инверсией первого, он соответствует рис. 3.4. Прямая организация массива удобна для поиска по условию «Каковы свойства указанного объекта?», а инвертированная — для поиска по условию «Какие объекты обладают указанным свойством?». В [14] приводится следующая типология простых запросов: 1) A(E) =? Каково значение атрибута А для объекта Е? 2) А(?) = V Какие объекты имеют значение атрибута, равное V? 3) ?(Е) = V Какие атрибуты объекта Е имеют значение, равное V? 4) ?(Е) =? Какие значения атрибутов имеет объект Е? 5) А(?) =? Какие значения имеет атрибут А в наборе? 6) ?(?) = V Какие атрибуты объектов набора имеют значение, равное V? Здесь в запросах типов 2, 3, 6 вместо оператора равенства может быть использован другой оператор сравнения. Запросы типа 1 выполняются поиском по «прямому» массиву: доступ к записи производится по первичному ключу. Запросы типа 2 выполняются поиском по инвертированному списку: доступ к записи производится по указателю, выбираемому из списка по значению вторичного ключа. Ответом в этих случаях будет значение атрибута или идентификатора. Запросы типа 3 имеют ответом имя атрибута. Запросы типа 2, 5, 6 относятся к нескольким атрибутам, и в этом случае могут быть построены несколько индексов, облегчающих поиск по этим ключам. Составные условия поиска могут использовать несколько простых условий, обычно связанных логическими операторами. Следует отметить, что в контексте обработки запросов 2-го типа «Какие объекты имеют заданное значение атрибута?» можно выделить три следующих типа архитектур доступа. 1. Системы с вторичными индексами. В этих системах последовательность расположения записей соответствует последовательности значений первичного ключа. Как правило, используется один первичный индекс и несколько вторичных. 2. Системы частично инвертированных файлов. В этих системах записи могут располагаться в произвольной последовательности. В отличие от систем первого типа первичный индекс отсутствует. Вторичные индексы применяются для прямой адресации записей, что существенно облегчает включение в файл новых записей, так как допускается их размещение в любом свободном участке файла. 3. Системы полностью инвертированных файлов. В этих системах предусмотрено наличие файлов, содержащих значения отдельных элементов данных, входящих в состав записей, — допускается раздельное хранение элементов данных записи. Значения элементов данных, составляющих конкретную запись или кортеж, в общем случае могут размещаться в памяти произвольно. Для ускорения процесса поиска в системе используют два набора индексов: индекс экземпляров и индекс данных. С помощью индекса экземпляров можно найти в файле элементы данных, имеющих заданное значение. С помощью индекса данных можно найти записи, связанные с заданными значениями элементов. Такая организация характерна для организации данных документальных информационных систем. 15. Представление предметной области и модели данных? Если бы назначением базы данных было только хранение и поиск данных в массивах записей, то структура системы и самой базы была бы простой. Причина сложности в том, что практически любой объект характеризуется не только параметрами-величинами, но и взаимосвязями частей или состояний. Есть различия и в характере взаимосвязей между объектами предметной области: одни объекты могут использоваться только как характеристики остальных объектов, другие — независимы и имеют самостоятельное значение. Кроме того, сам по себе отдельный элемент данных ничего не представляет. Онприобретает смысл только тогда, когда связан с атрибутом и другими элементами данных. Поэтому физическому размещению данных должно предшествовать описание логической структуры предметной области — построение модели соответствующего фрагмента реального мира, выделяющей только те объекты, которые будут интересны будущим пользователям, и представленные только теми параметрами, которые будут значимы при решении прикладных задач, Такая модель
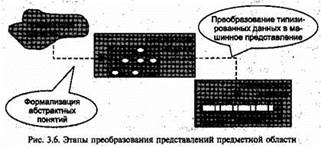
будет иметь очень мало физического сходства с реальностью, но будет полезна как представление пользователя о реальном мире. Причем это представление будет задаваться удобными для пользователя средствами в не адекватной человеку жесткой вычислительной среде с двоичной логикой и числовым представлением информации. Таким образом, прежде чем описывать физическую реализацию объектов и связей между ними, необходимо определить: 1) способ, с помощью которого внешние пользователи представляют объекты и связи; 2) форму и методы внутримашинного представления элементов данных и взаимосвязей; 3) средства, обеспечивающие взаимно однозначные преобразования внешнего и внутримашинного представлений. Такой подход является компромиссом, свойственным языкам программирования: за счет предварительно определяемого множества абстракций, общих для большинства задач обработки данных, обеспечивается возможность построения надежных программ обработки. Пользователь, используя ограниченное множество формальных, но достаточно знакомых понятий, выделяя сущности и связи, описывает объекты и связи предметной области; программист, используя такие типовые Абстрактные понятия, определяет соответствующие информационные структуры. Система управления данными, используя двоичные формы представления типизированных данных, обеспечивает эффективные процедуры хранения и обработки данных. Именно введение промежуточного уровня абстракции позволяет иметь раздельное описание логического и физического представлений, освобождает конечного пользователя от необходимости беспокоиться о деталях внутримашинного представления и обработки, поскольку он может быть уверен, что программистом выбрана наиболее эффективная форма для данной ситуации. Однако эффективность здесь имеет определенные пределы. Чем ближе система абстракций к особенностям вычислительной среды, тем выше эффективность выполнения программы, но вынужденная «специализациях абстракций увеличивает вероятность того, что они станут неподходящими для некоторых других применений. Модель данных должна, так или иначе, дать основу для описания данных и манипулирования данными, а также дать средства анализа и синтеза структур данных. Необходимо отметить, что предметные среды с точки зрения описания целесообразно условно разделить на два полярных случая: 1. Предметная среда характеризуется сравнительно небольшим количеством типов отношений, но каждое отношение само есть большое множество. Эти отношения сравнительно устойчивы, а изменений в пределах каждого множества существенно меньше мощности самого отношения. Например, отношение «вхождения» элементов изделий, содержащееся в конструкторских спецификациях, для среднего предприятия содержит сотни тысяч записей. В этом случае, задав схемы отношений и ориентировочные значения их мощностей, можно достаточно полно представить структуру и масштаб предметной среды. 2. Для предметной среды характерно большое число типов отношений между объектами, но каждое отношение есть множество сравнительно малой мощности. При этом мощность потока изменений для отношений сравнима с мощностью самих отношений. Первый случай характерен для отображения процессов на уровне автоматизированных систем управления предприятиями. Современные системы управления базами данных наиболее эффективны именно в подобном случае, при отображении статических в указанном смысле предметных сред. Обычно при этом речь идет о целых классах объектов, например, о деталях данного типа и не отображается состояние каждой конкретной детали. Второй случай характерен для описания производственного технологического процесса, сучетом временных и пространственных факторов нахождения конкретных объектов. Если в первом случае говорят о реляционной, иерархической или сетевой моделях данных, то во втором — о семантических сетях и фреймах. Основное отличие этих методов заключается в том, что первые задают четкую схему, в рамках которой и отображается предметная область. Подобное построение по сути своей является довольно статичным, требует априорного знания типов отношений, в которых может находиться объект, однако зафиксированная схема базы данных позволяет довольно эффективно организовать поиск необходимой информации. Во втором случае предметная среда отображается в виде однородной сети, любые изменения которой, по вводу как новых классов объектов, так и новых типов отношений, не связаны с какими-либо структурными преобразованиями сети. В силу большого количества типов отношений манипулирование подобной «элементарной» информацией достаточно затруднено, поэтому для данного случая характерно введение большого количества общих понятий, что упрощает работу с таким представлением. В контексте машинного представления модель данных может быть использована следующим образом: • как средство спецификации типов данных и их организации, разрешенных в конкретной БД; • как основа разработки общей методологии построения баз данных; • как основа минимизации влияния эволюции баз данных на уже существующие прикладные программы и работу конечных пользователей; • как основа разработки семейства языков запросов и языков манипулирования данными; • как основа архитектуры СУБД; • как основа изучения динамических свойств различных организаций данных. Таким образом, модель данных — это базовый инструментарий, обеспечивающий на формальном абстрактном уровне конкретные способы представления объектов и связей. Модель базы данных охватывает более широкий спектр понятий. Основное назначение модели базы данных состоит в том, чтобы: • определить ясную границу между логическим и физическим аспектами управления базой данных; • обеспечить конечным пользователям и программистам, создающим БД, возможность и средства общего понимания смысла данных; • определить языковые понятия высокого уровня, обеспечивающие возможность выполнения однотипных операций над большими совокупностями записей как единую операцию. 16. Структура данных (линейные, нелинейные, сетевые)? Линейные структуры К линейным структурам относятся массивы и последовательности. таблицы. Порядок следования элементов таких структур имеет линейный характер и соответствует порядку расположения элементов в памяти: один за другим без каких-либо промежутков. Адрес элемента соответствует его положению и определяется индексом — порядковым номером элемента в последовательности размещения. К элементу имеется прямой доступ, если известен его индекс. Особенностью линейной структуры является то, что при последовательной организации она допускает возможность прямого доступа к произвольному элементу, поскольку условие однородности предполагает, что все элементы занимают расположенные строго последовательно области одинакового размера, что и позволяет достаточно просто вычислять значение физического адреса элемента по значению его индекса. Массив представляет собой совокупность однотипных элементов, причем число элементов массива известно до его размещения, что позволяет строить гибкие многомерные системы адресации. Последовательность, так же, как и массив, представляет собой совокупность однотипных элементов. Однако число элементов до размещения неизвестно. И, хотя каждая конкретная последовательность имеет конечную длину, до начала обработки необходимо считать длину последовательности бесконечной. Принципиальность такого предположения выражается в том, что необходимо предусматривать специальную процедуру использования памяти и, возможно, алгоритм обработки последовательности по частям. Важность рассмотрения такого типа данных обусловлена тем, что именно он превалирует в операциях ввода/вывода с устройствами внешней памяти. Именно последовательный доступ
|
||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 665; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.014 с.) |