Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение реляционной схемыСодержание книги
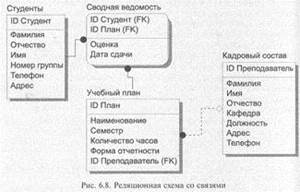
Поиск на нашем сайте Следующий этап проектирования — построение даталогической модели. В рассматриваемом случае задача этого этапа — преобразование ER-диаграммы в реляционную схему. Реляционный подход, в основе которого лежит принцип разделения данных и связей, обеспечивает, с одной стороны, независимость данных, а с другой — более простые способы хранения и обновления. Первые шаги преобразования состоят в превращении каждой сущности в отношение. Связь типа М:М, которую называют «сущность — связь», тоже превращается в отдельное отношение. Каждое свойство становится атрибутом — столбцом соответствующей таблицы. После реализации этих шагов получаем реляционную схему, изображенную на рис. 6.7, где представлены таблицы «Студенты», «Сводная ведомость», «Учебный план» и «Кадровый состав», отображающие соответственно сущности «Студент», «Сводная ведомость», «Дисциплина учебного плана» и «Преподаватель». Далее необходимо преобразовать связи во внешние ключи. Связь «многие ко многим», реализуемая отношением «Сводная ведомость», должна содержать уникальные идентификаторы сущностей — участников связи. При этом, если для однозначной идентификации студента достаточно добавить в таблицу столбец ID Студент, то однозначная идентификация дисциплины потребует добавления в таблицу столбцов Наименование, Семестр и Форма отчетности.Хранение всей этой информации явно приведет к избыточности данных и их потенциальной противоречивости
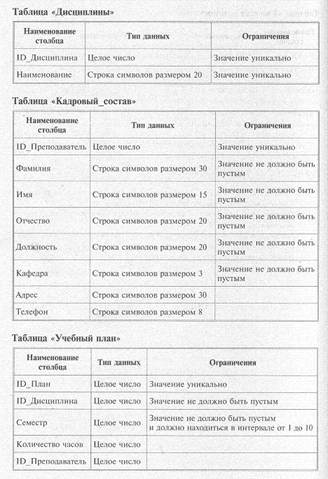
Для ликвидации избыточности и потенциальной противоречивости данных добавим в таблицу «Учебный план» столбец 1Р План, содержимое которого будет однозначно идентифицировать каждую строку таблицы. Теперь этот новый столбец станет первичным ключом, и одноименный столбец должен быть добавлен в таблицу «Сводная ведомость». Связь «Читает» предполагает добавление в таблицу «Учебный план» столбца 1Р Преподаватель. Реляционная схема со связями представлена на рис. 6.8.
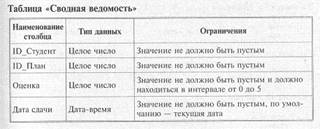
Нормализация таблиц Все построенные таблицы находятся в первой нормальной форме, так как каждый столбец таблицы неделим и в рамках одной таблицы нет столбцов с одинаковыми по смыслу значениями. Таблица «Сводная ведомость» через столбцы ID Студент и ID План связывает информацию о студенте с информацией о конкретной дисциплине и фиксирует оценку, полученную студентом, Оценка и дата сдачи экзамена однозначно зависят от содержимого столбцов 1Р Студент и 1Р План, которые представляют собой составной первичный ключ. Таким образом, все таблицы имеют первичные ключи, которые однозначно определяют строки и не избыточны, и можно говорить о том, что таблицы находятся во второй нормальной форме. Рассмотрим подробнее таблицу «Учебный план», которая содержит перечень дисциплин текущего учебного плана. Первичным ключом таблицы служит столбец 1Р План, который однозначно характеризует каждую дисциплину учебного плана с точностью до семестра, т. е. для дисциплин, протяженность изучения которых более одного семестра, в таблице будет отведено столько строк, сколько семестров длится изучение дисциплины. Тогда хранение наименований дисциплин в таблице «Учебный план» становится избыточным: например, если изучение английского языка длится шесть семестров, то наименование «Английский язык» будет повторено в шести записях и есть вероятность сделать шесть различных ошибок при вводе одного и того же наименования. Чтобы избежать этого, проведем декомпозицию отношения «Учебный план», выделив наименования дисциплин в отдельное отношение. В результате получим дополнительную таблицу «Дисциплины» со столбцами 1РДисциплина и Наименование, а столбец Наименование в таблице «Учебный план» заменим столбцом Дисциплина, сформировав тем самым вторичный ключ, связывающий новую таблицу с таблицей «Учебный план». Теперь можно говорить о базе данных «Сессия», реляционная схема которой представлена следующими пятью таблицами: • «Студенты» — содержит по одной строке для каждого из студентов; • «Учебный план» — содержит по одной строке для отдельной дисциплины отдельного семестра; • «Дисциплины» — содержит по одной строке для наименования дисциплины; • «Сводная ведомость» — содержит по одной строке для каждого результата сдачи отдельным студентом отдельной дисциплины; • «Кадровый состав» — содержит по одной строке для каждого из преподавателей. На рис. 6.9 в графической форме изображены перечисленные таблицы, их столбцы, первичные и внешние ключи. Задание первичных и внешних ключей сопровождается построением дополнительных структур — индексов, обеспечивающих быстрый доступ к данным через значение ключа. Все таблицы базы данных «Сессия» находятся в третьей нормальной форме: • каждый столбец таблицы неделим, и в рамках одной таблицы нет столбцов с одинаковыми по смыслу значениями; • первичные ключи однозначно определяют запись и не избыточны, все поля каждой из таблиц зависят от ее первичного ключа; • значение любого поля, не входящего в первичный ключ, не зависит от значения другого поля, тоже не входящего в первичный ключ. Следующий этап проектирования — определение доменов данных, хранящихся в столбцах таблиц. Параллельно с заданием типа необходимо сформулировать ограничения целостности, связанные с типом, — перечень допустимых значений типа. Исходя из особенностей данных и их функционального назначения, требуется задать способ представления и границы возможных изменений для каждого из столбцов таблиц. При этом необходимо ответить на вопрос: данные каких типов должны храниться в столбцах и какова их максимальная длина. Далее, в каждой таблице должны быть выделены столбцы, которые обязательно должны быть заполнены при создании отдельной строки таблицы. Задание такого ограничения целостности не позволит, например, ввести в таблицу «Студенты» строку, в которой не указан номер группы. Если подобные ограничения целостности не будут заданы, в таблице могут появиться строки, которые не будут учтены при выполнении функций по обработке данных: появление в таблице «Студенты» строки без номера группы приведет к ошибке при формировании ведомости. Следующий важный момент — задание для столбцов значений по умолчанию. Значение по умолчанию впоследствии будет автоматически вводиться в указанный столбец для каждой строки таблицы. Например, в столбец Дата сдачи таблицы «Сводная ведомость» при заполнении очередной строки может автоматически заноситься текущая дата. Ниже, на рис. 6.10 представлены таблицы базы данных «Сессия» с типами данных столбцов и предлагаемыми ограничениями целостности. Все примеры использования языка SQL, рассматриваемые в следующей главе, будут построены на основе этой учебной базы данных «Сессия».
34. Основные понятия и компоненты SQL (инструкция и имена, типы данных, встроенные функции, значения NULL)? Инструкции и имена SQL представлен множеством инструкций, каждая из которых предписывает СУБД выполнить определенное действие: создать таблицу, извлечь данные, добавить в таблицу новые данные и т. п. Инструкция SQL начинается с команды — ключевого слова, описывающего действие, выполняемое инструкцией. Типичными являются команды CREATE (создать), INSERT (добавить), SELECT (выбрать), DELETE (удалить). Следом за командой указывается одно или несколько предложений. Предложение описывает данные, с которыми должна работать инструкция, или уточняет действие, выполняемое инструкцией. Предложения в инструкции делятся на обязательные и необязательные. Каждое предложение начинается с ключевого слова, например — WHERE (где), FROM (откуда), INTO(куда). Многие предложения в качестве параметров содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения. У каждого объекта в базе данных есть уникальное имя. Имена используются в инструкциях SQL и указывают, над каким объектом базы данных инструкция должна выполнить действие. В соответствии со стандартом ANSI/ISOимена в SQL могут содержать от 1 до 18 символов, начинаться с буквы и не должны включать пробелов или специальных символов пунктуации. В стандарте SQL2 максимальное число символов в имени увеличено до 128. На практике в различных СУБД поддержка именования реализована по-разному: в DB2, например, имена пользователей не могут превышать восьми символов, а имена таблиц и столбцов могут быть более длинными. В различных СУБД также существуют и различные подходы к использованию в именах специальных символов. В инструкциях SQL могут использоваться как полные имена объектов, так и короткие. Полное имя таблицы содержит имя пользователя и короткое имя таблицы, разделенные точкой: <Имя пользователя>.<Имя таблицы> При этом уникальность именования таблицы сохраняется в случае, если в рамках одной базы данных разные пользователи создают таблицы с одинаковыми именами. Полное имя столбца в свою очередь состоит из полного имени таблицы, которой принадлежит столбец, и короткого имени столбца, разделенных точкой: <Имяпользователя>.<Имя таблицы>.<Имя столбца> или <Имя таблицы>.<Имя столбца> В рамках одной таблицы не может быть определено двух столбцов с одинаковыми именами, но в разных таблицах это возможно. При этом в инструкциях SQLнеобходимо использовать полное именование столбцов. Типы данных Современные СУБДпозволяют обрабатывать данные разнообразных типов, среди которых наиболее распространенными можно назвать следующие. Целые числа. В столбцах, имеющих такой тип данных, обычно хранятся данные о количестве и возрасте сотрудников, идентификаторы. Десятичные числа. Встолбцах данного типа хранятся числа, имеющие дробную часть с фиксированным количеством знаков после запятой, например курсы валют и проценты. Числа с плавающей запятой.Числа с плавающей запятой представляют больший диапазон действительных значений, чем десятичные числа. Строки символов постоянной длины. Встолбцах, имеющих этот тип данных, хранятся имена и фамилии, географические названия, адреса и т. п. Строки символов переменной длины.Столбцы этого типа позволяют хранить символьные строки, длина которых изменяется в заданном диапазоне. Денежные величины.Наличие отдельного типа данных для хранения денежных величин позволяет, правильно форматировать их и снабжать признаком валюты перед. выводом на экран. Дата и время. Поддержка особого типа данных для значений дата/время широко распространена в различных СУБД.Как правило, с этим типом данных связаны особые операции и процедуры обработки. Булевы величины. Столбцы такого типа данных позволяют хранить логические значения True (1) и False (0). Длинный текст. Многие СУБД поддерживают хранение в столбцах текстовых строк длиной до 32КБ или 64КБ символов, а в некоторых случаях и больше. Это позволяет хранить в базе данных целые документы. Неструктурированные потоки байтов. Современные СУБД позволяют хранить и извлекать не структурированные потоки байтов переменной длины. Такой тип данных обычно используется для хранения графических и видеоизображений, исполняемых файлов и других неструктурированных данных. Встроенные функции Язык SQL содержит так называемые встроенные функции, которые реализуют некоторые наиболее распространенные алгоритмы. Основной особенностью этих функций является возможность их использования при построении выражений. Встроенные функции, доступные при работе с SQL, можно условно разделить на следующие группы: • математические функции; • строковые функции; • функции для работы с величинами типа дата-время; • функции конфигурирования; • системные функции; • функции системы безопасности; • функции управления метаданными; • статистические функции. В табл. 7.1 приведены наиболее часто используемые функции первых трех групп.
Значения HULL При заполнении таблиц базы данных отдельные элементы в них могут отсутствовать. Например, при заполнении таблицы «Студенты» или «Кадровый состав» может быть не задан для некоторых строк номер телефона, тем не менее, строка должна быть введена в таблицу и должна участвовать в запросах на выдачу информации. SQL поддерживает обработку не определенных данных с помощью использования так называемого отсутствующего значения. Это значение показывает, что в конкретной строке конкретный элемент данных отсутствует. При этом NULL не является значением данных и в связи с этим не имеет определенного типа. Это всего лишь признак, показывающий, что значение элемента данных не задано. Правила обработки значений NULL в различных инструкциях и предложениях включены в синтаксис языка. 35. Ограничения целостности SQL (первичный ключ таблицы, внешний ключ таблицы, определение уникального столбца, определения проверочных ограничений, определение значения по умолчанию)? Первичный ключ таблицы Всякая таблица обычно содержит один или несколько столбцов, значение или совокупность значений которых уникально идентифицируют каждую строку в таблице. Этот столбец называется первичным ключом таблицы. Если в первичный ключ входит более одного столбца, значения в пределах одного столбца могут дублироваться, но любая совокупность значений всех столбцов первичного ключа при этом должна быть уникальна. Например, в таблице «Дисциплины» один столбец определен как первичный ключ, для таблицы «Сводная ведомость» задан составной первичный ключ — в него входят значения столбцов ID_ Студент и IP_ Дисциплина. Таблица может иметь только один первичный ключ, причем никакой столбец, входящий в первичный ключ, не может хранить значение NULL. Еще одним назначением первичного ключа является обеспечение ссылочной целостности данных в нескольких таблицах. Естественно,
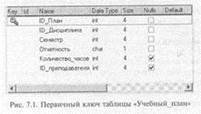
это может быть реализовано только при наличии соответствующих внешних ключей(FOREIGN KEY) в других таблицах. Если по столбцу строится первичный ключ, столбцу должен быть приписан атрибут PRIMARY KEY, например, описание столбца ID_ План для таблицы «Учебный_план» может выглядеть так: ID_Дисциплина INTEGER NOT NULL PRIMARY KEY Первичный ключ может быть также построен с помощью отдельного предложения PRIMARY KEY — путем включения имени (имен) ключевого столбца в качестве параметров. Например, первичный ключ для таблицы «Сводная_ведомость» может быть задан следующим образом: PRIMARY KEY
Внешний ключ таблицы Внешний ключ строится в дочерней таблице для соединения родительской и дочерних таблиц БД. Это ограничение целостности предназначено для организации ссылочной целостности данных. Внешний ключ связывается с потенциальным первичным ключом в другой таблице. Внешний ключ при этом может ссылаться либо на столбец с ограничением целостности PRIMARY KEY, либо на столбец с ограничением целостности UNIQUE. Таблицу, в которой определен внешний ключ, будем называть зависимой, а таблицу с первичным ключом — главной. Ссылочная целостность данных двух таблиц обеспечивается следующим образом: в зависимую таблицу нельзя вставить строку, если внешний ключ не имеет соответствующего значения в главной таблице, а из главной таблицы нельзя удалить строку, если значение первичного ключа используется в зависимой таблице. Например, если строка наименования дисциплины удалена из таблицы «Дисциплины», а идентификатор этой дисциплины используется в таблице «Учебный план», то относительная целостность между этими двумя таблицами будет нарушена — строки таблицы «Учебный план» с удаленным идентификатором останутся «осиротевшими». Ограничение FOREIGN KEY предотвращает возникновение подобных ситуаций — удаление строки первичного ключа не состоится. Столбцы внешнего ключа могут содержать значения типа NULL, однако при этом проверка на ограничение FOREIGN KEY будет пропускаться. Задать внешний ключ можно как при создании, так и при изменении таблиц. Синтаксис определения внешнего ключа следующий: FOREIGN KEY (<список столбцов внешнего ключа>) REFERENCES <имя родительской таблицы> [[<список столбцов родительской таблицы>] [ON DELETE {NO ACTION CASCADE SET DEFAULT SET NULL}] [0N UPDATE {NO ACTION CASCADE SET DEFAULTS SET NULL}] Список столбцов внешнего ключа определяет столбцы дочерней таблицы, по которым строится внешний ключ. Имя родительской таблицы определяет таблицу, в которой описан первичный. На этот ключ должен ссылаться внешний ключ дочерней таблицы для обеспечения ссылочной целостности. Список столбцов родительской таблицы, определяющий ссылочную целостность, необязателен при ссылке на первичный ключ родительской таблицы. При ссылке в родительской таблице на столбец с атрибутом UNIQUE этот список лучше привести. Параметры ON DELETE, ON UPDATE задают способы изменения подчиненных записей дочерней таблицы при удалении или изменении поля связи в записи родительской таблицы. Перечислим эти способы: • NO ACTION — запрещает удаление изменение родительской записи при наличии подчиненных записей в дочерней таблице; • CASCADE — при удалении записи родительской таблицы происходит удаление всех подчиненных записей в дочерней таблице; при изменении поля связи в записи родительской таблицы происходит изменение на то же значение поля внешнего ключа у всех подчиненных записей в дочерней таблице; • SET DEFAULT — в поле внешнего ключа записей дочерней таблицы заносится значение этого поля по умолчанию, указанное при определении поля (параметр DEFAULT); • SET NULL — в поле внешнего ключа записей дочерней таблицы заносится значение NULL. Установим связь между таблицами «Студенты», «Учебный_план» и «Сводная_ведомость». ALTER 'ТАВОТЕ Сводная_ведомость ADD FOREIGN KEY(ID_План) REFERENCES Учебный_план ALTER ТАВLЕ Сводная_ведомость ADD FOREIGN KEY (ID_Студент) REFERENCES СтудентыХотя в рассмотренном примере имена столбцов первичного и внешнего ключей в обеих таблицах совпадают, это не является обязательным. Первичный ключ может быть определен для столбца с одним именем, в то время как столбец, на который наложено ограничение FOREIGN KEY, может иметь совершенно другое имя. Однако лучше давать таким столбцам идентичные названия, чтобы показать связь между ними.
Ограничение целостности UNIQUEпредназначено для того, чтобы обеспечить уникальность значений в столбце. Если столбцу приписан атрибут UNIQUE,это означает, что в столбце не могут содержаться два одинаковых значения. Дляограничения целостности PRIMARY KEYавтоматически гарантируется уникальность значений. Однако в каждой таблице можно определить всего один первичный ключ. Если же необходимо дополнительно обеспечить уникальность значений еще в одном или более столбцах помимо первичного ключа, то нужно использовать ограничение целостности UNIQUE. Ограничение целостности UNIQUE,в отличие от PRIMARYKEY, допускает существование значения NULL.При этом к значению NULL также предъявляется требование уникальности, поэтому в столбце с ограничением целостности UNIQUEдопускается существование лишь единственного значения NULL. Таким образом, ограничение UNIQUEиспользуется в том случае, когда столбец не входит в состав первичного ключа, но, тем не менее, его значение всегда должно быть уникальным. Например, для таблицы «Дисциплины» первичный ключ строится по номеру дисциплины ID_ Дucциплина, введенному для сокращения объема первичного ключа и времени поиска по нему. Однако и название дисциплиныдолжно быть уникальным, для чего ему приписан атрибут UNIQUE: CREATE TABLE Дисциплины (ID_Дисциплина INTEGER NOT NULL PRIMARY KEY, Наименование VARCHAR (20) NOT NULL UNIQUE) Уникальность может быть определена и на уровне таблицы: CREATE TABLE Дисциплины (ID_Дисциплина INTEGER НОТ NULL, Наименование VARCHAR (20) NOT NULL, PRIMARY KEY (ID Дисциплина), UNIQUE (Наименование))
|
||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 523; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.008 с.) |