Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основы технологии интеграции распределенных данныхСодержание книги
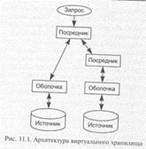
Поиск на нашем сайте Одна из главных задач, которую призваны решать системы управления — это интеграция данных из различных источников, в том числе со слабоструктурированными данными. Системы интеграции данных должны обрабатывать запросы, для ответа на которые может потребоваться извлечение и обобщение данных из различных источников. При этом возможны следующие варианты: • регулярные источники, где представление и организация данных в той или иной степени формализованы, хотя при этом могут использоваться различные модели данных и интерфейсы доступа к ним, или данные источника могут быть неструктурированными; • источники уникальные, т. е. взаимодействовать с источником можно только через предоставляемый им интерфейс и нет никакой возможности повлиять на его внутренние процессы. Теоретически и практически возможны два подхода к решению задачи интеграции данных — создание хранилищ данных и виртуальных хранилищ. При использовании первого подхода хранилище физически или логически объединяет данные из различных источников, и затем все запросы обрабатываются с использованием этих данных. В этом случае актуальность данных не гарантируется, поскольку никакой синхронизации с источником не происходит, но преимущество заключается в том, что объединение централизованно и, следовательно, время выполнения запроса невелико. При использовании второго подхода данные хранятся в источниках, а запросы к системе интеграции транслируются в запросы или операции, понятные источнику. Данные, полученные в ответ на эти запросы к источникам, объединяются и предоставляются пользователю. Преимущество виртуальных хранилищ заключается в гарантии того, что пользователь получает только актуальные данные. Но поскольку источники могут значительно отличаться, возникают трудности, связанные с оптимизацией запросов, и необходимы дополнительные расходы на конвертирование данных, что существенно снижает общую производительность системы. Для построения систем, объединяющих большое количество источников, содержание которых часто изменяется, наиболее предпочтительным является виртуальный подход. Рассматривая типичную организацию виртуального хранилища, выделим два уровня — логический и физический. Логический уровень определяется выбором модели данных и языка запросов для этой модели. Выбранная модель используется для представления данных, извлекаемых из всех источников. Таким образом, пользователь системы интеграции получает возможность унифицированного доступа ко всем данным. Важным требованием к модели данных является обеспечение прозрачности доступа к внешним источникам, т. е. пользователь видит внешние данные как локальные и в выбранной им модели, не заботясь об управлении доступом к источнику. Физический уровень. Ключевым понятием организации виртуального хранилища являются средства преобразования данных. На рис,. 11.1 приведена типичная архитектура, основанная на распространенной концепции посредников. Основными компонентами, обеспечивающими возможность интегральной обработки распределенных данных, являются «оболочка» и «посредник». Оболочка используется для хранения информации о внешнем источнике и организации доступа к нему. При получении запроса оболочка обращается к источнику через предоставляемый им интерфейс. Полученные от источника данные конвертируются во внутренний формат данных хранилища
Очевидно, что для каждого источника необходима своя оболочка. Посредник осуществляет интеграцию данных из различных источников, используя различные оболочки. Посредник может взаимодействовать как с оболочками, так и с другими посредниками. Таким образом, предоставляется возможность построения сложной сети взаимодействующих между собой посредников, что позволит обобщать данные различными способами для удовлетворения нужд различных приложений. Важно отметить, что посредник не содержит данных — интеграция происходит, как правило, за счет использования технологии представлений. Поскольку при использовании предложенной архитектуры задача построения виртуального хранилища сводится к созданию оболочек и посредников, необходимо иметь средства, позволяющие легко их генерировать. С этой целью разрабатываются специальные декларативные языки, с помощью которых описываются оболочки и посредники. По этим описаниям и происходит их генерация.
|
||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 362; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.006 с.) |