Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Захист пам'яті за значеннями ключівСодержание книги
Поиск на нашем сайте
Метод дозволяє організувати захист несуміжних областей пам’яті. Пам’ять умовно ділиться на блоки однакового розміру. Кожному блоку ставиться у відповідність деякий код, який називають ключем захисту пам’яті. Кожній програмі, у свою чергу, присвоюють код захисту програми. Умовою доступу програми до конкретного блоку пам’яті служить збіг ключів захисту пам’яті і програми, або рівність одного з цих ключів нулю. Нульове значення ключа захисту програми надає доступ ДО ВСЬОГО адресного простору і використовується лише програмами операційної системи. Розподілом ключів захисту програми відає операційна система. Ключ захисту програми зазвичай представлений у вигляді окремого поля слова стану програми, що зберігається в спеціальному регістрі. Ключі захисту пам’яті зберігаються в спеціальній пам’яті. При кожному зверненні до основної пам’яті схема порівняння проводить порівняння ключів захисту пам’яті і програми. При збігу доступ до пам’яті дозволено. Дії у разі неспівпадіння ключів залежать від того, який вид доступу заборонений: при записі, при читанні або в обох випадках. Якщо з’ясувалося, що даний вид доступу заборонений, то так само як і в методі граничних адрес формується запит переривання і називається відповідна процедура операційної системи. Описаний спосіб є більш гнучким порівняно з попереднім, так як дозволяє звертатися до областей пам’яті, розміщених не підряд. Він був застосований в системі ІВМ 360. Схема захисту пам’яті за описаним способом в системі ІВМ 360 наведена на рис. 10.35.
В цій системі пам’ять складається з блоків. Кожний блок має код - ключ захисту пам’яті (КЗП), Кожна програма теж має код - ключ програми (КП). Ключі захисту пам’яті зберігаються в пам’яті ключів захисту (ПКЗ). Крім того, є іще тригер режиму захисту (ТгРЗ), в якому зберігається розряд режиму захисту (РРЗ). Доступ дозволений, якщо КЗП = КП. Коли КЗП = КП, а РРЗ = 0, то дозволено лише зчитування. Коли ж КЗП = КГІ, а РРЗ = 1, то доступ до пам’яті заборонений. Об’єм блоку рівний 2048 байт. Одночасно обробляється 16 програм і, відповідно, використовується 16 варіантів КЗП і КП, тобто коди є 4-розрядними. КП вказується в спеціальному полі слова стану програми (ССП) або каналу (ССК). Коди КП і КЗП встановлює операційна система.
Кільцева схема захисту пам'яті Захист адресного простору операційної системи від несанкціонованого вторгнення з боку призначених для користувача програм зазвичай організовують шляхом надання системного і призначеного для користувача рівнів привілеїв. Таку структуру прийнято називати кільцевою системою захисту. На рис. 10.36 ця система зображена у вигляді концентричних кіл, де призначений для користувача режим представлений зовнішнім кільцем, а системний - внутрішнім колом. У системному режимі програмі доступні всі ресурси комп’ютера, а можливості призначеного для користувача режиму істотно обмежені. Перемикання з призначеного для користувача режиму в системний здійснюється спеціальною командою. Вперше описаний підхід був застосований в системі МиЬТІСБ на комп’ютері СЕ 645, де крім ключів захисту використовувалась кільцева схема захисту з 32 рівнями привілеїв. У більшості сучасних комп’ютерів число рівнів привілеїв (кілець захисту) невелике, зокрема в процесорах фірми Меі передбачено чотири рівні привілеїв.
В ядрі операційної системи знаходяться програми ініціалізації комп’ютера та керування доступом до пам’яті. Сегменти в внутрішніх кільцях більш захищені, ніж в зовнішніх. Рівні захисту привілеїв задаються двома бітами у відповідних регістрах. Архітектура системної плати Системна, або материнська, плата персонального комп'ютера (System board або Mother board) є основою системного блоку, що визначає архітектуру і продуктивність комп'ютера. На ній встановлюються такі обов'язкові компоненти: - Процесор (и) і співпроцесор. - Пам'ять: постійна (ROM або Flash BIOS), оперативна (DRAM), кеш (SRAM). - Обов'язкові системні засоби введення / виводу. - Інтерфейсні схеми та роз'єми шин розширення. - Кварцовий генератор синхронізації зі схемою формування скидання системи по сигналу PowerGood від блоку живлення або кнопки RESET. Додаткові стабілізатори напруги живлення для низьковольтних процесорів VRM (Voltage Regulation Module). Крім цих суто обов'язкових засобів, на більшості системних плат встановлюють і контролери інтерфейсів для підключення гнучких і жорстких дисків (гое, SCSI), графічний адаптер, аудіо-канал, а також адаптери СОМ-і LPT-портів, «миші» та інші. Контролери, які потребують інтенсивного обміну даними (гое, SCSI, графічний адаптер), використовують переваги локального підключення до шини процесора. Мета розміщення інших контролерів на системній платі ~ скорочення загального числа плат комп'ютера.
Системні плати перших PC, виконаних на процесорах 8088/86, крім процесора містили кілька периферійних БІС (контролери переривань, прямого доступу до пам'яті, контролер шини) і сполучну логіку на мікросхемах малої і середньої ступені інтеграції. Сучасні плати виконуються на основі чіпсетів (Chipset) - наборів з декількох БІС, що реалізують всі необхідні функції зв'язку основних компонентів - процесора, пам'яті та шин розширення. Чіпсет визначає можливості застосування різних типів процесорів, основний і кеш-пам'яті і ряд інших характеристик системи, що визначають можливості її модернізації. Його тип істотно впливає і на продуктивність - при однакових встановлених компонентах продуктивність комп'ютерів, зібраних на різних системних платах - читай, чіпсетах, - може відрізнятися на 30%. Сучасні чіпсети забезпечують сумісність встановлюються на системну плату модулів і дозволяють під час POST виконувати автоматичну ідентифікацію типів (а в деяких випадках і швидкість - наприклад ОЗУ) встановлених компонент
Синхронізація Основний тактовий генератор системної плати виробляє високостабільні імпульси опорної частоти, використовуваної для синхронізації процесора, системної шини та шин введення / виводу. Стандартні частоти генератора: 4,77, 6, 8, 10, 12, 16, 20, 25, 33,3, 40, 50, 60, 66,6, 75, 83,100 МГц і вище. Оскільки швидкодія різних компонентів (процесора, пам'яті, адаптерів для шин ISA, EISA, VLB, PCI) істотно розрізняється, в комп'ютерах на процесорах класу 486 і старше застосовується розподіл опорної частоти для синхронізації шин введення / виводу і внутрішнє множення частоти в процесорах. Розрізняють такі частоти: - Host Bus Clock - частота системної шини (зовнішня частота шини процесора). Ця частота є опорною для всіх інших. - CPU Clock, або Core Speed - внутрішня частота процесора, на якій працює його обчислювальне ядро. Сучасні технології дозволили істотно підвищити граничні частоти інтегральних компонентів, у зв'язку з чим широко застосовується внутрішнє множення частоти на 1,5,2,2,5, 3,3,5,4 і деякі інші значення. - PCI Bus Clock - частота шини PCI, яка повинна становити 25-33,3 МГц (специфікація PCI-2.1 допускає частоту до 66,6 МГц). Вона забезпечується поділом Host Bus Clock на 2 (рідше на 3). - VLB Bus Clock - частота шини VLB, обумовлена аналогічно PCI Bus Clock. Плати з шиною VLB зазвичай мають джампер, перемикається в залежності від того, чи перевищує системна частота значення 33,3 МГц. - ISA Bus Clock, або ATCLK - частота шини ISA, яка повинна бути близька до 8 МГц. Вона зазвичай задається в BIOS Setup через коефіцієнт розподілу системної частоти. Крім цих тактових частот на системній платі присутні і інші - Для синхронізації СОМ-портів, CMOS-годин, таймера, НГМД та інших периферійних адаптерів.
Система шин Основне завдання шин - об'єднати в єдину систему різноманітну номенклатуру модулів, забезпечивши їх високопродуктивну належну роботу. Під належною роботою слід розуміти виконання умови відкритості (extensibility), сумісності (compatibility), однотипності (repeatability), гнучкості flexibility), надійності (reliability), ремонтопридатності (repairability), ефективності та інших, загальносистемних вимог.
Виконання даних умов означає: - Відкритість - можливість розширювати, модернізувати одні рівні системи без порушення інших; - Сумісність - системи з різним виконанням окремих підсистем повинні бути взаємозамінні, сумісність повинна виконуватися на рівні hardware і software; - Однотипності - модернізація системи не повинна приводити до необхідності замінювати використовувані раніше типи пристроїв; - Гнучкість - можливість підключення різних підсистем, пристроїв без порушення функціонування існуючих систем; - Надійність-будь-яка модернізація системи не повинна приводити до зниження надійності, тобто при модернізації слід передбачати певну структурну надмірність; - Ремонтопридатність - модернізація системи не повинна приводити до конструктивних змін, ускладнює її експлуатацію; - Ефективність - виконання перерахованих вище умов повинно бути економічно виправданим. Суть всіх цих вимог можна сформулювати так: заміна одних шин іншими не повинна супроводжуватися появою архітектурних обмежень. На практиці таке буває рідко. Для ПК однією з суттєвих неприємностей є необхідність застосовувати іншу периферію при використанні інших шин розширення. Шини можна розглядати як "хребет" обчислювальної середовища. Практично про комп'ютер, як про ефективну обчислювальної системі, можна говорити тільки при наявності належного узгодження між мікропроцесором, пам'яттю і комунікаційними магістралями. Наявність істотних відмінностей в продуктивності між різними модулями призвело до необхідності використовувати в сучасних ПК систему шин, замість однієї''загальної "шини. Особливості роботи шини У різних шин організація роботи різна. Однак при цьому ряд положень використовуються загальні. Насамперед відзначимо, що загальна організація роботи шини може бути представлена як сукупність механізмів, кожен з яких виконує цілком певну функцію передачі інформації, наприклад, читання з пам'яті, читання з порту, запис в пам'ять, запис в порт і т.д. Безліч таких механізмів кінцеве, але їх тим більше, чим складніша і різнорідною структура комп'ютера (комп'ютер має ієрархічну пам'ять, розвинені системи переривань і захисту, реалізує мультипроцесорний і мультизадачності режими та ін.) Можна уявити організацію управління роботою шини, як перехід від виконання одного механізму до іншого. Початок реалізації конкретного механізму пов'язане з установкою стану шини. Для цієї мети серед шин управління є сукупність сигналів (ліній), які визначають напрямок передачі сигналів (запис або читання), характер переданої інформації (дані або команди), її інформаційну структуру (1-/2-/4-/8-/16 - байтним, пакетна структура), місце звернення (до пам'яті, кеш-пам'яті, до портів вводу-виводу) та ін У відповідність з вибраним станом встановлюється організація використання шини адреси і шини даних. Час, займане виконанням окремого механізму, називається циклом шини. Таким чином для різних механізмів тривалість (довжина) циклів шин різна. Довжина циклу залежить не тільки від особливостей виконуваної передачі, а й від готовності пристроїв брати участь у цій передачі. Будь неготовність буде призводити до затягування відповідних циклів шини. Таким чином тривалість циклу шини є випадковою величиною, а його початок і кінець є асинхронними. Механізм управління шиною повинен мати засоби формування початку циклу, його ведення і закінчення циклу. Природно, що у різних шин ці кошти можуть бути різні.
Для спрощення управління шиною довжина циклу складається з тимчасових квантів однаковій тривалості (задаються сигналами синхронізації шини), званих тактом шини, тобто довжина циклу завжди кратна числу тактів шини. Під час будь-якого такту циклу шини виконуються цілком певні дії. Ці дії можна розбити на дві групи: встановлення стану шини і виконання команд, запропонованих реалізованим механізмом передачі даних. У встановленні стану шини можна відзначити два тимчасових інтервали - час формування сигналів стану і час їх фіксації. У період формування сигналів стану на лініях шини вони можуть з'являтися в різні моменти. У цей період сигнали вважаються недостовірними і вони не використовуються для управління. Період формування можна розглядати як необхідний час затримки для закінчення перехідних процесів сигналів стану. Закінчується цей період спеціальним стробом, який відзначає початок періоду фіксації. Тепер сигнали достовірні і їх можна використовувати для реалізації логіки ухвалення рішення. Тимчасовий такт, в якому розташовується стробирующий сигнал початку фіксації називається тактом стану і позначається Т1. На встановлення стану відводиться тільки один перший такт циклу шини - такт стану Т1. Виконання команд відбувається в період інших тактів, які позначаються Т2. Мінімальна кількість (п) цих тактів один. При п> = 2 всі такти Т2, крім останнього, вважаються тактами очікування і тільки в період останнього такту фіксується закінчення виконуваного циклу шини. Після цього може заново формуватися такт Т1 наступного циклу шини або бути холосте стан, тривалість якого теж кратна тактам шини, що позначаються ть Таким чином перехід від виконання одного механізму передачі до іншого може визначатися переходом від Т2 до Т1 або переходом від Т \ к Т1. Послідовність механізмів передачі може бути представлена у вигляді (записано п'ять циклів шини): Т1Т1Т2... Т2Т1Т2Ть.. т1Т2Ть.. Т1Т1Т2... Т2Т1Т1Т2Т1 і т.д. Єдиний в циклі шини такт Т2 називається командним тактом. Мінімальна тривалість циклу шини складає два такти. Чим коротше довжина циклу шини, тим продуктивніше працює комп'ютер. Використовуються різні апаратні режими ущільнюючі цикли шин, наприклад, конвейеризация шин дозволяє почати виконувати наступний цикл до завершення попереднього. Попереднє початок обробки наступного циклу збільшує період перебування сигналів шини у фіксованому стані, що спрощує вимоги до швидкості реакції пристроїв і забезпечує більш надійну роботу ліній шини.
Розглянемо особливості поведінки сигналів на лініях шини в період тактів Т1 і Т2, Вище зазначалося, що в період такту состояформіруется стан шини. У цей період на шинах адреси повинен бути виставлений адресу звернення. Дія конвейеризации призводить до появи цієї адреси перед тактом Т1. Для двотактних циклів шини в період такту Т2 попереднього циклу шини повинен з'явитися на шині адреси наступну адресу. На шині даних дані, що визначаються виконуваної командою, з'являються в період командного такту Т2. Може виникнути ситуація, коли до моменту появи даних на шинах адреси буде виставлений іншу адресу, що стане причиною збою. Виникає необхідність розв'язати стан шини з реально використовуваним адресою. Для цього вводиться елемент засувки, який фіксує (запам'ятовує) виставлений на шині адресу. Засувка управляється стробом, який надходить в такті Т1. Застосування засувки дозволяє зафіксувати для обслуговування необхідну адресу. Засувка є буфером адреси, наприклад, між шинами А та БА, між шинами А і Ьа, між шинами 8А і ХА. Типова тимчасова діаграма роботи шини представлена на рис. 2.2. Як видно з малюнка, є періоди, коли на шині даних можуть бути недостовірні дані. Тому і для даних потрібна організація розв'язки. Так як по шині даних інформація передається в обох напрямках, то використовуються потужні приемопередатчики, які кроменія Т1 тимчасової розв'язки виконують узгодження підключених пристроїв по потужності. Приймачіпередавачі служать буферами, наприклад, між шинами О и 80, шинами 80 и МО
Пакетний режим передачі. При пакетній передача адреса передається один раз, після чого передається пакет даних з лінійно-зростаючими адресами. Кількість циклів даних в пакеті заздалегідь не визначено, але перед останнім циклом ініціатор обміну при введеному сигналі дозволу обміну (IRDY #) знімає спеціальний сигнал пакетної передачі (FRAME #). Після останньої фази даних ініціатор знімає сигнал 1RDY # і шина переходить у стан спокою. Пакетний режим є стандартним режимом роботи шини PCI. Рис. 2.3. ілюструє роботу шини PCI в пакетному режимі.
Конвеєризація звернень до пам'яті. Даний режим використовується в сучасних високошвидкісних шинах (АВР). При не конвейеризированих зверненнях шини під час реакції пам'яті на запит шина простоює. Конвеєрний доступ дозволяє в цей час передавати такі запити, а потім отримати щільний потік відповідей (переданих даних). Специфікація AGP передбачає можливість постановки в чергу до 256 запитів, при цьому підтримує дві пари черг для операцій запису і читання пам'яті з високим і низьким пріоритетом. Здвоєні передачі даних забезпечують підвищення пропускної здатності шини в 2 рази без зміни тактовою частоти шини. Суть здвоєною передачі даних в тому, що блоки даних передаються як по фронту, так і по спаду сигналу синхронізації (використовується в AGP і в шині АТА в режимі Ultra DMA-33).
Характеристики шин ПК Системні інтерфейси материнської плати (система шин), які мають роз'єми (слоти) для підключення адаптерів периферійних пристроїв (інтерфейсних карт), отримали назву шин розширення. Шини розширення ПК почали свою історію з 8-бітної шини ISA. Її відкритість забезпечила появу широкого спектра плат розширень, що дозволяють використовувати ПК в різних сферах. Шини розширення системного рівня дають можливість встановлювати на них модулі, максимально використовувати такі системні ресурси як обєм пам'яті і ресурси введення-виводу, переривання, канали прямого доступу до пам'яті. За отримання цих можливостей розробникам і виробникам модулів розширення доводиться розплачуватися необхідністю забезпечення точної відповідності протоколів шини, включаючи і досить жорсткі частотні і навантажувальні параметри, а також тимчасові діаграми. Відхилення від цих вимог можуть призводити до проблем сумісності з різними системними платами. Якщо при підключенні до зовнішніх інтерфейсів ці проблеми призведуть до непрацездатності тільки цього пристрою, то некоректна підключення до системної шини може блокувати роботу всього комп'ютера. Розглянемо основні характеристики шин розширення системного рівня. ISA-8 і ISA-16 (Industry Standard Architecture) - є найпоширенішою і найпростішою шиною, основи якої були закладені в ПК IBM PC / XT (ISA-8) і після її удосконалення (ISA-16) вона широко використовується в IBM PC / AT практично для всіх сучасних мікропроцесорів. ISA-8 має розрядність 8 біт даних і 20 біт адреси (максимальне адресний простір -1 Мбайт). У ISA-16 шину розширили до 16 біт даних і 24 біт адреси. У такому вигляді вона існує і понині як найпоширеніша шина для периферійних адаптерів. Шина забезпечує своїм абонентам можливість відображення 8 - або 16-бітних регістрів на простір вводу- виводу і пам'яті. Гранична швидкість передачі даних досягає 16 Мбайт/с. Діапазон адрес вводу / виводу зверху обмежений кількістю біт адреси, які використовуються для дешифрування, при цьому традиційно використовується 10-бітна адресація простору введення / виведення, а в даний час в інтелектуальних пристроях стали застосовувати і 12-бітну адресацію, але при її використанні завжди необхідно враховувати можливість присутності на шині і старих 10-бітових адаптерів, які "відгукнуться" на адресу з відповідними йому битами А (9 - 0) у всій допустимої області 12-бітного адреси чотири рази. У розпорядженні абонентів ISА-8 може бути до 6 ліній запитів переривань ШХ} (для 18А-16 їх число досягає 11) і до трьох 8-бітних каналів БМА (для ISА-16 бути доступними ще три 16-бітових каналу). Всі перераховані ресурси системної шини повинні бути безконфліктно розподілені між абонентами. Задача розподілу ресурсів у старих адаптерах вирішувалася за допомогою джамперів, потім з'явилися програмно конфігуровані пристрої, які витісняються автоматично конфігуруються платами РпР. З появою 32-бітових процесорів робилися спроби розширення розрядності шини, але всі 32-бітові шини ISА не є стандартизованими, крім шини ЕISА. Конструктивно слот шини ISА виконана у вигляді двох щілинних роз'ємів з кроком висновків 2,54 мм (0,1 дюйма), вид яких зображений на рис. 2.4. Підмножина ISА-8 використовує тільки 62-контактний слот (ряди А, В), в ISА-16 застосовується додатковий 36-контактний слот (ряди С, О).
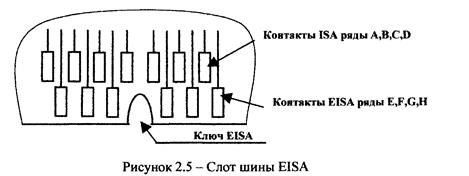
EISA (Extended ISA) - розширена шина ISA, реалізує 32-розрядну архітектуру (32-розрядні шини адреси і даних) і є більш продуктивною, застосовується для підключення високошвидкісних адаптерів, що забезпечують ефективну роботу з файлами або для належної роботи серверів. Шина EISA має: - Розвинену систему переривань, крім переривання по фронту сигналу передбачена система переривання за рівнем сигналу з можливістю програмного вибору схеми переривання; - Розвинену систему роботи каналів ДМ А, яка допускає цикли обміну за 8, 6, 4 і 1 тактів. Цикли підтримують роботу з 8-/16-/32- розрядними пристроями; - Автоматичну конфігурацію системи і плат розширення з раз-діленням раз поділом ресурсів комп'ютера між окремими платами; - Засоби реалізації мультипроцесорної архітектури; - Розвинену систему арбітражу, використовується системний арбітр, який бере участь у реалізації центрального управління; - Виділений адресний діапазон до 4 Кбайт для кожного роз'єму для усунення конфліктів між слотами. Адресний простір шини до 4 <3байт. Гранична швидкість передачі даних в пакетному режимі 33 Мбайт / с. ЕISА - дорога, але виправдовує себе архітектура, що застосовується в багатозадачних системах, на файл-серверах і скрізь, де требуетря високоефективне розширення шини введення / виводу. Перед шиною РСІ у неї є деяка перевага в кількості слотів, яке для однієї шини РСІ не перевищує чотирьох, а у ЕІБА може досягати восьми. Конструктивне виконання забезпечує сумісність з нею і звиЧних ISА-адаптерів (Мал. 2.5). Вузькі додаткові контакти розширення (ряди Е, Р, б, Н) розташовані між ламелями роз'єму А і нижче ламелей А, В, С, О таким чином, що адаптер ISА, не має додаткових ключових прорізів у крайовому роз'ємі, не дістає до них. Установка карт ЕISА в слоти ISА неприпустима, оскільки її специфічні ланцюга потраплять на контакти ланцюгів ISА, в результаті чого системна плата виявиться непрацездатною.
MCA (Micro Channel Architecture) - мікроканальна архітектура була розроблена фірмою IBM для своїх комп'ютерів PS/2, починаючи з моделі 50. Шина MCA абсолютно несумісна з ISA / EISA. Шина більш швидкодіюча ніж шина ISA. Для мікропроцесорів, які застосовують 32-/64- розрядні шини даних може використовуватися 32 - розрядна шина MCA, яка в 2,5 рази більш продуктивна, ніж використовувані шини ISA в ШМ PC / AT. Архітектура MCA пристосована для виконання пакетної процедури обміну. Реалізація пакетного режиму обміну забезпечує граничну швидкість 40 Мбайт / сек, у той час як звичайний (4-байтний) обмін по шині MCA забезпечує швидкість 20 Мбайт / сек. MCA володіє більш досконалої захистом, що зменшує конфліктні ситуації при одночасному зверненні до шини пристроїв, подібних DMA. На відміну від інших шин MCA допускає обробку послідовності переривань сигналів, розподіляючи їх серед кількох виділених карт (feature cards), які можуть працювати одночасно без взаємодії один з одним. Арбітражний механізм, званий керуючим шини (bus master), забезпечує повний контроль роботи шини без участі процесора, при цьому прискорює обмін інформацією з пам'яттю, що важливо для роботи DMA. MCA підтримує архітектуру блоку управління системи (SCB-system control bloc), при якій для мікропроцесора створюються невеликі програми (звані SCB), що містять спеціальні програмовані інструкції і дані. Мікропроцесор може замовити керуючому шиною (bus master) виконати роботу, визначену SCB і повернути йому результат. При цьому процесор може встановити більш підходящий момент для виконання свого завдання. Цей підхід використовується для реалізації мультипроцесорної архітектури великих комп'ютерів. При всій прогресивності архітектури (щодо ISA) шина MCA не користується популярністю через вузькість кола виробників MCA-пристроїв і повної їх несумісності з масовими ISA-системами. Однак MCA ще знаходить застосування в потужних файл-серверах, де потрібне забезпечення високонадійного продуктивного введення / виводу.
Шина PCMCIA, VBL PCMCIA (Personal Computer, Card International Association) - шина розширення, використовувана для портативних комп'ютерів, так як за габаритними та інших причин шини ISA, EISA і MCA тут не прийнятні. Технічно PCMCIA це не шина в розглянутому вище значенні, а більше схожа на паралельний або послідовний порт. Найбільш важливі характеристики шини-малі розміри, вага, низьке споживання енергії адаптерний картами. Шина PCMCIA має такі ж слоти як і комп'ютер сімейств PS / 2 і IBМ / РС і має додатково адаптери для зв'язку з ISA і MCA. Стандарти PCMCIA передбачають реалізацію сумісності з різними апаратними та операційними системами. В даний час стандарт PCMCIA допускає використання карт пам'яті, введення-виведення для модемів, мережевих комунікацій, жорстких дисків, радіозв'язку, різних адаптерів емуляції. Кількість і функціональна різноманітність цих карт безперервно зростає. VLB (Video Equipment Standard Association / VESA / Local Bus) - локальна шина для підключення високопродуктивних підсистем, таких як відеографіческіе підсистеми, підсистеми мережевих комунікацій тощо, до локальної шини мікропроцесора. Ця шина використовується одночасно з шиною ISA як основний для решти периферії. Стандарт VLB орієнтований на 486 процесор і обмежується додаванням до локальної шини мікропроцесора кількох контрольних сигналів. Однак безпосередній вихід на процесор високошвидкісних пристроїв через можливі системних порушень обмежує кількість пристроїв, що підключаються до такої шині. До VLB можна підключати до 3-х контролерів високошвидкісних периферійних пристроїв. Конструктивно VLB це короткий з'єднувач типу MCA (112 контактів), який має 32 лінії для передачі даних і 30 ліній адреси. Для МП Pentium розроблений новий стандарт VLB, який передбачає використання 64-розрядної шини даних і допускає до п'яти роз'ємів розширення. Максимальна швидкість обміну складає 132 Мбайт / с в пакетному режимі. Шина PCI PCI (Peripheral Component Interconnect) local bus - шина з'єднання периферійних компонентів. Називаючись локальної, ця шина займає особливе місце в сучасній PC-архітектурі, будучи мостом між системною шиною процесора і шиною вводу / виводу ISA / EISA чи MCA. Ця шина розроблялася з розрахунку на Pentium-системи, має 32-розрядну шину адреси і 32 (в специфікації PCI 2.1 64) - розрядну шину даних. При частоті шини 33 (66 у версії 2.1) МГц теоретична максимальна швидкість досягає 132/264 Мбайт / с для 32/64 біт в пакетному режимі. PCI має мультиплексованих шину адреси / даних AD і деякі лінії управління використовуються для різних цілей, що дозволило зменшити число цих ліній і спростити шину. Протокол квітірованія забезпечує надійність обміну - ініціатор завжди отримує інформацію про відпрацювання пакета цільовим пристроєм. Засобом підвищення надійності (достовірності) є застосування контролю паритету: лінії AD (31 - 0) і С / ВЕ # (3 - 0) і у фазі адреси, і у фазі даних захищені бітом паритету PAR. Арбітражем запитів на використання шини займається спеціальний функціональний вузол, що входить до складу чіпсета системної плати. Кожен пристрій-ініціатор має пару сигналів - REQ # для запиту на управління шиною і GNT # - підтвердження надання керування шиною. Схема пріоритетів (фіксований, циклічний, комбінований) визначається програмуванням арбітра. Адресація пам'яті, портів і конфігураційних регістрів різна. Байти шини AD, що несуть дійсну інформацію, вибираються сигналами С / ВЕ (3 - 0) в фазах даних (всередині пакету ці сигнали можуть змінювати стан). У циклах звернення до пам'яті адреса, вирівняний по межі подвійного слова, передається по лініях AD (31 - 2), лінії AD (1 - 0) задають порядок чергування адрес в пакеті (00 - лінійне инкрементирования, 01 - чергування адрес з урахуванням довжини рядка кеш-пам'яті, 1х - зарезервовано). У циклах звернення до портів введення / виводу для адресації будь-якого байта використовуються всі лінії AD (31 - 0). У циклах конфігураційної запису / зчитування пристрій вибирається індивідуальним сигналом EDSEL #, конфігураційні регістри вибираються подвійними словами, використовуючи лінії AD (7 - 2), при цьому AD (1 - 0) = 00. Команди шини PCI (типи циклів) визначаються значеннями біт C / BE # в фазі адреси такі: -Підтвердження переривання (РІС контролер передає вектор переривання по шині AD); - Спеціальний цикл декодується вмістом ліній AD (15 - 0) і використовується для вказівки на відключення (Shutdown), останов (Halt) процесора або специфічні функції процесора, пов'язані з кешем і трасуванням; - Читання і запис введення / виводу. Порти PCI можуть бути 8 - або 16 - бітними. Для адресації портів на шині РС1 доступні всі 32 біта адреси, але процесори х86 можуть використовувати тільки молодші 16 біт. Крім того, на адресний простір PCI впливає і 10-бітове декодування адреси, прийняте в традиційній шині ISA, в результаті чого кожен адреса порту на шині ISA має 64 псевдоніма, зміщених одна від одної на 1 К. Порти з адресами 0CF8h і OCFCh зарезервовані під регістри адреси і даних для доступу до конфігураційного простору. Звернення до порту даних призведе до генерації шинного циклу конфігураційного читання або запису за попередньо записаному адресою; - Читання і запис пам'яті. Шина AD містить адреси подвійних слів, і лінії ADO, AD1 не повинні декодувати; - Конфигурационное читання і запис. Ці команди адресуються до конфігураційному простору (не відбивається ні на простір пам'яті ні на простір введення / виводу) і забезпечують доступ до 256-байтним структурам. Звернення йде подвійними словами. Структура містить ідентифікатор пристрою і виробника, стан і команду, інформацію про використовувані ресурси та обмеження на використання шини; - Множинне читання пам'яті використовується для читання великих блоків пам'яті без кешування. - Двоадресного цикл застосовується, коли фізична шина має всього 32 біта адреси, а потрібна передача з 64-бітної адресацією. У цьому випадку молодші 32 біти адреси передаються в циклі даного типу, а за ним слідує звичайний цикл, який визначає тип обміну і несе старші 32 біти адреси; - Читання рядка пам'яті використовується для читання більш ніж двох 32 - бітних блоків даних (зазвичай читання до кінця рядка кеша). У такому випадку цей цикл забезпечує обмін, більш ефективний, ніж ланцюжок звичайних пакетних читань. - Запис з інвалідаціей застосовується при передачі як мінімум одного рядка кеша і дозволяє оновлювати вміст основної пам'яті, економлячи цикли зворотного запису. Слоти PCI з кроком 0,05 дюйма мають для 32-розрядних даних 124 контакту (А1-А62, В1-В62) і 188 контактів (А1-А94, В1-У94) для 64 - розрядні даних. На одній шині PCI може бути не більше чотирьох пристроїв (отже, і слотів). Для підключення шини PCI до інших шинам застосовуються спеціальні апаратні засоби - мости міни PCI (PCI Bridge). Головний міст (Host Bridge) використовується для підключення PCI до системної шини (шині процесора або процесорів). Ad-hoc міст (Peer-to-Peer Bridge) використовується для з'єднання двох шин PCI. Дві і більше шини PCI застосовуються в потужних серверних платформах ~ додаткові шини PCI дозволяють збільшити кількість підключаються. Для підключення шин ISA / EISA використовуються спеціальні мости, що входять в чіпсети більшості системних плат. Кожен міст програмується - йому вказуються діапазони адрес просторів пам'яті і введення / виводу, відведені абонентам його шин. Якщо адреса цільового пристрою поточної транзакції на одній шині (стороні) моста відноситься до шини протилежної сторони, міст перенаправляє транзакцію на відповідну шину і виконує дії за погодженням протоколів цих шин. Таким чином, сукупність мостів, розташованих навколо шини PCI, виконує маршрутизацію (routing) звернень по всім пов'язаним шинам. Автоконфігурірованія пристроїв (вибір адрес, запитів переривань) підтримується засобами BIOS і орієнтоване на технологію Plug and Play. Стандарт PCI визначає для кожного слота конфігураційне простір розміром до 256 однобайтних регістрів, не приписаних ні до простору пам'яті, ні до простору введення / виведення. Доступ до них здійснюється за спеціальними циклами шини Configuration Read і Configuration Write, вироблюваним контролером при звертанні процесора до регістрів контролера шини PCI, розташованим в його просторі введення / виведення. Після апаратного скидання (або за включення живлення) пристрої PCI не відповідають на звернення до простору пам'яті і введення / виводу, вони доступні тільки для операцій конфігураційного зчитування та запису. У цих операціях пристрої вибираються за індивідуальними сигналам IDSEL #, пристрої повідомляють про потреби в ресурсах і можливих діапазонах їх переміщення. Після розподілу ресурсів, що виконується програмою конфігурування (під час POST), в пристрої записуються параметри конфігурації, і тільки після цього до них стає можливим доступ по командам звернення до пам'яті і портів введення / виводу.
AGP, FireWire, JTAG, JC AGP (Accelerated Graphic Port) - прискорений графічний порт, розроблений на базі шини PCI 2.1. Цей порт є 32 - розрядну шину з тактовою частотою 66 МГц (точніше, 66,66...), за складом сигналів нагадує шину PCI. Місце AGP в архітектурі комп'ютера ілюструє рис. 2.1. Чіпсет пов'язує AGP з пам'яттю і системною шиною процесора, не натикаючись на що стала вже «вузьким місцем» шину PCI. Підвищення швидкодії порту забезпечується наступними трьома факторами: 1) Конвеєризація операцій звернення до пам'яті. Специфікація AGP передбачає можливість постановки в чергу до 256 запитів, але при конфігуруванні РпР уточнюються реальні можливості конкретної системи. AGP підтримує дві пари черг для операцій запису і читання пам'яті з високим і низьким пріоритетом. У процес передачі даних будь-якого запиту може втрутитися наступний запит, в тому числі і запит в режимі PCI. 2) Здвоєна передача даних, яка забезпечує при частоті тактування шини в 66 МГц пропускну здатність до 532 Мбайт / с (режим «х2»), за рахунок того, що 4-байтним блоки даних передаються як по фронту, так і по спаду сигналу синхронізації. Замовити режим х2 може тільки графічна карта, якщо, звичайно, вона його підтримує. 3) демультиплексування (поділ) ший адреси і даних. Демультиплексирование увазі наявність двох полноразрядних шин адреси і даних. Однак реалізація такого варіанту була б занадто дорогою. Тому в AGP шину адреси в демультіплексірованном режимі представляють 8 ліній SBA (Side Band Address), за якими за три такти синхронізації передаються 6 байт (4 байта адреси, 1 байт - довжина запиту і 1 байт - команда). За кожен такт передаються по два байти - один з фронту, інший по спаду тактового сигналу. Підтримка демультіплексірованной адресації не є обов'язковою для карти з портом AGP, але хост-контролер, природно, повинен її підтримувати. Альтернативою такому способу подачі адреси є звичайний - по мультиплексованих 32-х розрядної шині AD. - Fire Wire (він же IEEE 1394) - високопродуктивна послідовна шина підключення зовнішніх пристроїв, призначена в основному для підключення відеоапаратури. За допомогою цієї ж шини можливо і об'єднання декількох комп'ютерів в локальну мережу. Системні плати з цією шиною поки ще рідкість. Крім шин розширення, сучасні системні плати можуть мати і допоміжні шини, використовувані для тестування і передачі конфігураційної інформації. До них відносяться наступні: - JTAG - послідовний інтерфейс тестування, реалізований в більшості процесорів старших поколінь, а також входить у спеці-сифікацію роз'єму шини PCI. JC - послідовна шінат використовувана для передачі конфігураційної інформації нових модулів пам'яті DIMM, а також у цифровому каналі зв'язку з монітором (DDC). На системних платах поширене поєднання слотів: ISA + PCI, ISA + VLB, EISA + PCI, EISA + VLB. Шина MCA зазвичай тримається особняком. Слот «Media BUS», що доповнює слот PCI сигналами шини ISA, застосовується, мабуть, тільки фірмою ASUSTek.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-08-01; просмотров: 359; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.189.186.95 (0.018 с.) |