
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Виконання команд на рівні регістрів процессора.Содержание книги
Поиск на нашем сайте
Для глибшого розуміння послідовності виконання команди розглянемо детальніше структуру регістрової (надоперативної) пам’яті процесора. Ця пам’ять (рис. 3.3) складається з регістрів з закріпленими операціями, та регістрів зального призначення. Тут РгА, РгК і РгД - відповідно регістри адреси, команд і даних. РгА зберігає адресу даного або команди при зверненні до основної пам’яті. РгД зберігає операнд при його запису або зчитуванні з основної пам’яті. В ролі операнда може бути дане, команда або адреса. РгК зберігає команду після її зчитування з основної пам’яті. ПЛ - програмний лічильник, який підраховує команди та зберігає адресу поточної команди. Комп’ютер з архітектурою Джона фон Неймана має один програмний лічильник.
Більшість комп’ютерів мають в складі процесора тригери для зберігання бітів стану процесора, або, як їх іще називають, прапорців. Кожен прапорець має спеціальне призначення. Частина прапорців вказує на результати арифметичних і логічних операцій: додатній результат (Р), від’ємний результат (ІЯ), нульовий результат (X), перенос (С), арифметичне переповнення (V), і т. д. Б системі команд комп’ютера є команди, які вказують процесору коли встановити чи скинути ці тригери. Інша частина прапорців вказує режими захисту пам’яті. Існують також прапорці, які вказують пріоритети виконуваних програм. Б деяких процесорах додаткові тригери служать для зберігання кодів умов, формуючи регістр кодів умов. Бзяті разом описані прапорці формують слово стану програми (ССП), а відповідні тригери - регістр ССП. Регістри загального призначення (РЗП) є програмно доступними. Зазвичай їх називають регістровим файлом. Вони можуть використовуватись програмістом в якості регістрів для зберігання вхідних та вихідних даних, а також проміжних результатів обчислень, в якості адресних та індексних регістрів при виконанні операцій модифікації адрес. Наприклад, в процесорі ІЛіта.ЯРЛКС II є дві групи регістрових файлів: 32 64-роз- рядні регістри загального призначення та 32 регістри для даних з рухомою комою, які можуть зберігати або 32-розрядні дані одинарної точності, або 64-розрядні дані подвійної точності. В процесорі РепПит II є лише 8 32-розрядних та б 16-розрядних регістрів загального призначення. Зв’язки між вузлами процесора і основною пам’яттю показано на рис. 3.4. Як видно з рисунка, процесор взаємодіє з основною пам’яттю через регістри адрес та даних. Крім того, пристрій керування формує сигнали задання режимів роботи пам’яті.
Виходячи з наведеної вище інформації про вузли процесора та його зв’язки з основною пам’яттю, розглянемо детальніше виконання команд на прикладі виконання операції додавання слова, яке знаходиться в пам’яті за адресою 9, з вмістом регістра РгО регістрової пам’яті процесора, коли результат операції засилається в пам’ять за адресою 9. Програма обчислень знаходиться також в пам’яті. Операцію можна записати наступним чином: [Комірка 9]:= [Комірка 9] + [РгО]. Послідовність дій при виконанні цієї операції буде наступною: 1. Рг А:= ПЛ. Значення із програмного лічильника, тобто адреса команди, записується в регістр адреси РгА. 2. Зчитування із комірки [РгА] основної пам’яті команди додавання двох чисел в регістр даних РгД. 3. Рг К:= Рг Д. Перезапис команди додавання двох чисел з регістра даних в регістр команди РгК. 4. РгА:= [А РгК]. Запис адреси числа із регістра команди до регістра адреси (ця адреса рівна 9). 5. Зчитування із комірки [РгА] основної пам’яті даного і засилання його в регістр РгД. 6. Рг Д:- [РгД] + [РгО]. Виконання в АЛП операції [РгД] + [РгО] і засилання результату в РгД. 7. Запис в комірку 9 основної пам’яті даного із регістра РгД. 8. ПЛ:= ПЛ +1. Прирощення на одиницю вмісту програмного лічильника. Подібним чином виконуються інші команди, включаючи команди взаємодії з пристроями введення-виведення. Конвеєрне виконання команд Конвеєрне виконання команд подібне до роботи конвеєра складальної лінії на заводі, наприклад автомобільному. На складальній лінії вироби проходять через однакові виробничі стадії. Одночасно на лінії знаходиться кількість виробів, рівна кількості виробничих стадій. Проходячи через всі виробничі стадії, виріб приймає кінцеві параметри. Час виготовлення одного виробу є рівним часу його проходження через всі виробничі стадії, але при виготовленні багатьох виробів, скажемо п, час, який припадає на виготовлення всіх виробів, є рівним: Т = 1:т + 1:(n - 1) = і(т + n- 1), де т - кількість виробничих стадій, І - час виконання однієї виробничої стадії, а час, який припадає на виготовлення одного виробу, є рівним: Тв = і(т + n - 1)/n. При п >> т час Тв, який припадає на виготовлення одного виробу, наближається до часу 1 виконання однієї виробничої стадії. Подібно до виготовлення виробу, команда також має кілька послідовних стадій виконання, як це показано на рис. 3.2. Тому логічним виглядає використання і тут принципу конвеєра. Для початку розглянемо поділ процесу виконання команди на дві стадії: вибірку та виконання. В процесі стадії виконання команди є проміжки часу, коли немає звернень до пам’яті. Цей час може бути використаним для вибірки наступної команди паралельно з виконанням поточної команди. На рис. 3.13 показано цей підхід.
Конвеєр має два незалежних яруси. Перший ярус виконує операцію вибірки та буфе- ризації (короткотермінового запам’ятовування) команди. Коли другий ярус звільняється від роботи, перший ярус передає йому буферизовану команду. Коли в другому ярусі виконується команда, в першому ярусі вибирається наступна команда. Така операція називається попередньою вибіркою команди (instruction prefetch) або суміщенням вибірки (fetch overlap). Зрозуміло, що описаний процес прискорює виконання команди. Якби операції вибірки та виконання мали однаковий час виконання, то цикл виконання команди міг би бути зменшеним вдвоє. Однак це не зовсім так через наступні причини: 1. Стадія виконання значно довша стадії вибірки, оскільки вона вимагає виконання операцій зчитування та запису операндів та самої операції. Тому перший ярус повинен чекати деякий час, поки звільниться його буфер. 2. При появі команди умовного переходу адреса наступної команди до завершення поточної команди невідома. Тому перший ярус змушений чекати до завершення роботи другого ярусу. Після цього вже другий ярус повинен чекати на завершення роботи першим ярусом. Час, який втрачається через другу причину, може бути зменшений шляхом використання механізму передбачення. Тут може бути використане наступне правило: коли команда умовного переходу поступає з ярусу вибірки на ярус виконання, в ярусі вибірки проводиться вибірка із пам’яті наступної команди після команди умовного переходу. Тоді в випадку відсутності умовного переходу втрат часу не буде. Коли ж буде умовний перехід, то вибрана команда повинна бути знехтувана і вибрана нова команда. Хоча розглянуті дві причини знижують потенційну ефективність двоярусного конвеєра, в цілому виграш незаперечний. Для подальшого підвищення продуктивності потрібно збільшувати кількість ярусів конвеєра. Розглянемо поділ виконання команди на наступні стадії: ■ Вибірка команди (ВК): зчитування в буфер очікуваної наступною команди. ■ Дешифрування команди (ДК): визначення типу вибраної команди та специфікаторів операндів. * Визначення адрес даних (ВА): обчислення адрес даних, необхідних для виконання команди з врахуванням можливості використання різних способів адресації. ■ Вибірка операндів (ВО): зчитування даних із пам’яті в регістри процесора. * Виконання команди (КВ): виконання вказаної операції та, при наявності, запам’ятовування результату в визначеному регістрі. * Запис результату (ЗР): запам’ятовування результату в пам’яті. При такому поділі час тривалості різних стадій виконання команди буде приблизно рівним. Тоді, як видно з табл. 3.5, шестиярусний конвеєр може зменшити час виконання команд з 54 тактів до 14 тактів
Часова діаграма в табл. 3.5 показує, що кожна команда виконується шляхом проходження через 6 ярусів конвеєра. Разом з тим, не для кожної команди це потрібно Наприклад, команда вибірки не вимагає виконання операції ЗО. Однак при її виконанні можна зробити шостий ярус конвеєра прозорим Також на діаграмі показано, що всі стадії виконуються паралельно. В першу чергу тут прийнято, що не виникає конфліктів при зверненні до пам’яті. Наприклад, операції ВК, ВО та ЗО передбачають звернення до пам’яті. Діаграма допускає, що всі ці звернення можуть здійснюватись одночасно. Більшість систем пам’яті цього не допускають, тому звернення розносяться в часі. Іноді потрібне число може знаходитись в кеш пам’яті, а стадії ВО та ЗО відсутні. Тому конфлікти при зверненні до пам’яті не завжди сповільнюють конвеєр Декілька інших факторів обмежують ріст продуктивності за рахунок використання конвеєра ■ неоднаковість часу шести стадій виконання команди приводить до простою деяких з них, як це мало місце в двоярусному конвеєрі; ■ поява команди умовного переходу може звести нанівець декілька вибірок команд ■ подібною до команди умовного переходу є команда переривання Табл. 3.6 відображає вплив умовного переходу при виконанні тих же операцій, що й в табл..
Тут прийнято, що команда 3 є умовним переходом до команди 15. Поки команда З виконується, неможливо взнати, яка команда буде наступною. Конвеєр буде вибирати наступні команди (4,5,6,7) і виконувати їх. Наявність умовного переходу визначиться в кінці сьомого такту. Після цього конвеєр повинен звільнитись від непотрібних команд (очиститись). На 8 такті команда 15 поступить в конвеєр і дальше він почне заповнюватись знову. При цьому від 9 до 12 тактів не буде завершено виконання жодної команди. Це є розплата ефективністю за причини неможливості передбачити перехід.
На рис. 3.14 показано блок-схему виконання команди в шестиярусному конвеєрі з врахуванням переходів та переривань.
В шестиярусному конвеєрі команд появляється й інша проблема, якої не було в двоярусному конвеєрі. Стадія ВА може залежати від вмісту регістра, який змінюється попередньою командою, що знаходиться в конвеєрі. З’являється новий конфлікт, для усунення якого необхідна відповідна логіка. Таким чином, конфлікти конвеєра можуть бути трьох типів: ■ Конфлікт ресурсів, наприклад, одночасна потреба доступу до пам’яті. Цей конфлікт вирішується шляхом розділення доступу до ресурсу в часі, або шляхом введення додаткового ресурсу, наприклад, кількох блоків пам’яті. ■ Залежність між даними, коли результат виконання деякої команди, яка іще не завершена, є операндом для наступної команди. Для подолання даного конфлікту існує декілька шляхів. Це може бути введення „пустої” операції пор (яка не виконує дій, але дозволяє ліквідувати конфлікт), введення зв’язків між ярусами конвеєра, що прискорює доступ до потрібного операнда, а також застосування компілятора, здатного передбачати такого типу конфлікти та перевпорядковувати команди програми. ■ Наявність умовних переходів. В сучасних комп’ютерах для зменшення впливу на ефективність конвеєра цього конфлікту використовується спеціальна логіка передбачення переходу, яка дозволяє знайти вітку, якою програма піде після переходу. Інший підхід - виконання обох віток переходу до того часу, поки напрям переходу стане відомим. 24. Класифікація архітектури комп'ютера за типом адресованої пам'яті. Як видно з рис. 3.1, крім коду операції до складу команди входить адресна частина. Цією частиною визначається місце знаходження даних, над якими виконується операція, задана кодом операції. Даних може бути декілька, і, крім того, вони можуть знаходитись в основній пам’яті, в регістрах процесора чи в запам’ятовуючих елементах інших вузлів комп’ютера. Тому і формати команд в цих випадках будуть різними. Можна здійснити класифікацію архітектури комп’ютера за типом адресованої пам’яті. Залежно від того, який тип пам’яті адресується, розрізняють наступні типи архітектур комп’ютера: стекова, акумуляторна, на основі регістрів загального призначення. В стековій архітектурі (рис. 3.15) операнд завжди знаходиться в вершині стека - спеціальному регістрі пам’яті, з якого загружається в регістр процесора, або через нього результат операції загружається в пам’ять. Стек представляє собою пам’ять з детермінованою вибіркою, яка працює за принципом „останній прийшов - перший вийшов” (LIFO - Last In First Out). Стек виконує дві операції: push - вштовхування даних в стек, pop - виштовхування даних з стеку
Інформація може бути занесеною в вершину стека з пам’яті або з регістра АЛП процесора. Перевага стекової архітектури - відсутність в команді адресної частини. З іншого боку, стекова архітектура не передбачає довільного доступу до комірок пам’яті, тому часто важко створити для неї ефективну програму. Крім того, стек не дозволяє підвищити продуктивність комп’ютера за рахунок розпаралелення, оскільки наявна лише одна вершина стека. Стекова архітектура була реалізована в наступних комп’ютерах: В5500, В6500 фірми Burroughs, НР2116Р, НРЗ 000/70 фірми Hewlett-Packard, JEM 1, JEM 2 фірми ajile Systems. В акумуляторній архітектурі (рис. 3.16) операнд завжди знаходиться в акумуляторі спеціальному регістрі процесора. В цей же регістр записується і результат операції. - Оскільки адреса одного із операндів визначена, в команді достатньо вказати лише адресу другого операнда. Перевага даної архітектури - короткі команди. Вона була реалізована в комп’ютерах IBM 7090, DEC PDP-8 та інших.
Архітектура на основі регістрів загального призначення може мати такі різновидності як: архітектура типу пам’ять-пам’ять, регістр-пам’ять та регістр-регістр. В архітектурі типу пам’ять:пам’ять (рис. 3.17) операнди поступають на вхідні регістри АЛП процесора прямо з пам’яті. Результат операції також записується прямо в пам’ять. Оскільки час звернення до пам’яті є більшим часу звернення до регістрів, ця архітектура характеризується низькою швидкодією. Прикладом таких комп’ютерів є сім’ї IBM System/370 та DEC VAX.
Архітектура типу регістр-пам’ять (рис. 3.18) передбачає вибірку та подачу в АЛП одного із операндів з пам’яті, а іншого - з регістра, тому характеризується вищою швидкодією ніж попередня. Тут в процесорі наявна регістрова пам’ять, причому регістри є програмно доступними.
В архітектурі типу регістр-регістр (рис. 3.19) дані в АЛП поступають лише з регістрів процесора, результати виконання операцій також записуються в регістри, а обмін між цими регістрами і пам’яттю здійснюється паралельно з роботою АЛП. Ця архітектура характеризується високою швидкодією, оскільки операції виконуються в АЛП з їх читанням-записом до регістрів, які є значно швидшими пам’яті. Крім того, для цієї архітектури характерною є фіксована довжина команд та однакова кількість тактів для виконання всіх команд.
Будь-який із регістрів загального призначення може бути використаний в якості акумулятора, адресного регістра, індексного регістра, стекового регістра, а в деяких машинах навіть в якості програмного лічильника. Більшість сучасних комп’ютерів побудовані на основі описаної архітектури. Це, зокрема, комп’ютерігРепІіит, SPARC, Power PC, ARM та інші. Разом з тим, за регістрами можуть бути закріплені конкретні функції - один набір служить в якості індексних регістрів, інший призначений для зберігання арифметичних операндів і т. д. Таким чином організовані регістри в комп’ютерах сім’ї CDC 6000/7000.
25. Безпосередня адресація. Пряма адресація. Непряма адресація. Безпосередня адресація При безпосередній адресації операнд знаходиться безпосередньо в адресній частині команди (рис. 3.22), розрядність якої рівна розрядності операнда.
Це найшвидший спосіб знаходження операнда, оскільки для його отримання потрібне лиш одне звернення до пам’яті. Він використовується для задания констант, наперед відомих чисел або початкових значень змінних. Недоліком є те, що розрядність операнда обмежується розрядністю поля адреси в команді, яке в більшості випадків є значно меншим розрядності даних. Пряма адресація При прямій (або абсолютній) адресації в адресному полі прямо вказується місце розміщення операнда, тобто виконавча адреса операнда. При цьому можливі два випадки: пряма адресація основної пам’яті ОП, та пряма адресація регістрів регістрового файлу процесора. В першому випадку адреса А комірки основної пам’яті із адресної частини АЧ команди поступає на адресні входи основної пам’яті ОП (рис. 3.23 а) і у вказану комірку в режимі запису записується операнд із регістра даних РгД, а в режимі зчитування зчитується операнд в регістр даних РгД. В другому випадку адреса К регістра регістрового файлу процесора із адресної частини АЧ команди поступає на адресні входи регістрового файлу процесора (рис. 3.23 Ь), і у вказаний регістр в режимі запису записується операнд із регістра даних РгД, а в режимі зчитування зчитується операнд в регістр даних РгД.
Якщо основна пам’ять може зберігати М слів, то, використовуючи двійкове кодування, необхідно т біт для представлення адрес всіх комірок пам’яті, де ш =]Ц? М[. Значення в дужках означає більше ціле. Якщо регістровий файл має N регістрів, то, використовуючи двійкове кодування, необхідно п біт для представлення адрес всіх регістрів, де п -]1о§ 2 КГ[. Оскільки число регістрів значно менше кількості комірок пам’яті, то і роз- рядність адреси для їх адресації буде значно меншою, а відповідно значно меншою буде і розрядність команди в цілому. Нехай для прикладу кількість виконуваних в комп’ютері команд рівна 256, тобто розрядність коду операції рівна 8 бітів, ємність основної пам’яті рівна 1ГБ, тобто розрядність адреси рівна ЗО бітів, а кількість регістрів регістрового файлу процесора рівна 64, тобто розрядність адреси рівна 6 бітів. На рис. 3.24 показано формати двоадресних команд при прямій адресації основної пам’яті та регістрового файлу процесора для наведеного прикладу.
Як видно з рисунка, в першому випадку розрядність команди рівна 68 бітів, тоді як в другому випадку розрядність команди рівна 20 бітів, тобто менша в 3,4 рази. Для того, щоб розпізнати який тип пам’яті адресується - основна пам’ять чи регістровий файл процесора, до команди вводиться спеціальне поле типу пам’яті ТП, як це показано на рис. 3.25.
Непряма адресація При непрямій адресації в адресному полі вказується місце розміщення адреси операнда, а виконавча адреса знаходиться наступним чином: А = [А1], де А1 - адреса комірки пам’яті, в якій зберігається виконавча адреса. Адреса А із адресної частини АЧ команди поступає на адресні входи основної пам’яті ОП (рис. 3.26), з відповідної комірки основної пам’яті ОП вибирається адреса операнда, по якій в відповідну комірку або регістр в режимі запису записується операнд із регістра даних РгД, а в режимі зчитування зчитується операнд в регістр даних РгД. Якщо пам’ять може зберігати М слів, то, використовуючи двійкове кодування, необхідно ш біт для представлення всіх адрес, де т =]1о§2М[. Значення в дужках означає більше ціле. Для вибірки операнда необхідно здійснити два звернення до ОП.
Для зберігання адрес операндів можна використати регістровий файл процесора (рис. 3.27). Якщо регістровий файл може зберігати N слів, то, використовуючи двійкове кодування, необхідно п біт для представлення непрямої адреси в адресній частині команди, де п =]к^ М[, а розрядність регістрів буде рівною т =]к^,М[. Значення в дужках означає більше ціле. Для вибірки операнда необхідно здійснити одне звернення до регістрової пам’яті і одне звернення до основної пам’яті ОП. Такий підхід дозволяє при малій розрядності адресної частини команди п звертатися до пам’яті великої ємності маючи велику розрядність регістрів т.
Потрібно відзначити, що використання регістрової пам’яті також дозволяє суттєво прискорити процес визначення ефективної адреси, оскільки час вибірки з неї значно менший порівняно з часом вибірки з основної пам’яті. Можливе використання так званої багаторівневої або каскадної непрямої адресації, коли для знаходження ефективної адреси потрібно виконати кілька звернень до пам'яті. Кількість кроків звернення до пам’яті, необхідних при і-рівневій непрямій адресації, називається рангом гі. Розрізняють перший, другий і т. д. ранги. Пряма адресація - це адресація нульового рангу (гО). Непряма адресація служить для зменшення довжини програми з великою кількістю змінних адрес.
|
||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-01; просмотров: 741; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.224.73.157 (0.012 с.) |


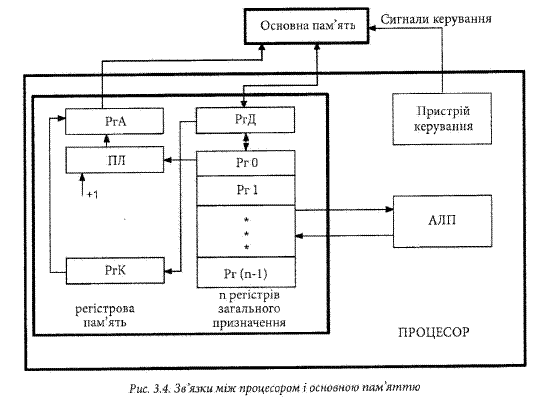



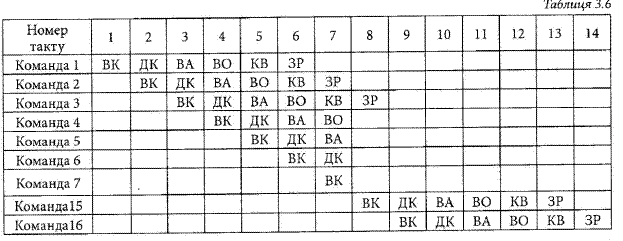

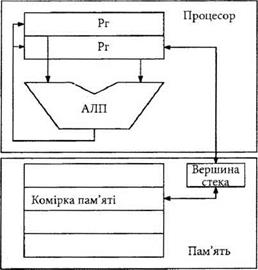 Рис. 3.15. Стекова архітектура
Рис. 3.15. Стекова архітектура
 Рис. 3.16. Акумуляторна архітектура
Рис. 3.16. Акумуляторна архітектура
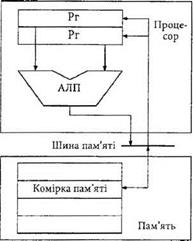
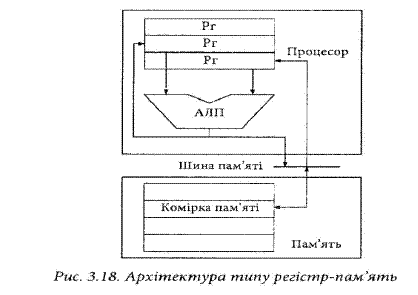
 Рис. 3.19. Архітектура типу регістр-регістр
Рис. 3.19. Архітектура типу регістр-регістр

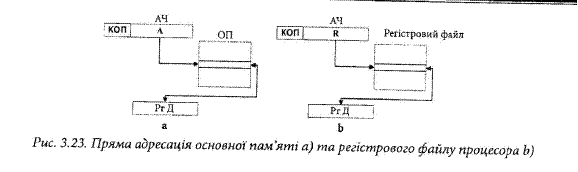


 Рис. 3.26. Непряма адресація основної пам’яті, яка вимагає здійснення двох звернень
Рис. 3.26. Непряма адресація основної пам’яті, яка вимагає здійснення двох звернень
 Рис. 3.27. Непряма адресація основної пам’яті з використанням регістрового файлу процесора
Рис. 3.27. Непряма адресація основної пам’яті з використанням регістрового файлу процесора



