Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Архитектура процессоров. Cisc и riscСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Уч. год Заочное обучение
Прежде чем начать изучение jk триггера, вспомним принципы работы RS-триггера. Напомню, что в этом триггере есть запрещённые комбинации входных сигналов. Одновременная подача единичных сигналов на входы R и S запрещены. Очень хотелось бы избавиться от этой неприятной ситуации. Таблица истинности jk триггера практически совпадает с таблицей истинности синхронного RS-триггера. Для того чтобы исключить запрещённое состояние, его схема изменена таким образом, что при подаче двух единиц jk триггер превращается в счётный триггер. Это означает, что при подаче на тактовый вход C импульсов этот триггер изменяет своё состояние на противоположное. Таблица истинности jk триггера приведена в таблице 1. Таблица 1. Таблица истинности jk триггера.
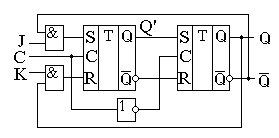
Один из вариантов внутренней схемы JK-триггера приведен на рисунке 1. Эта схема удобна для изучения принципов работы данного триггера в счетном режиме.
Для реализации счетного режима в схеме введена перекрестная обратная связь с выходов второго триггера на входы R и S первого триггера. Благодаря обратной связи на входах R и S первого триггера никогда не может возникнуть запрещенная комбинация, а то, что она перекрестная, вводит новый режим работы — счетный. При подаче на входы j и k логической единицы одновременно JK-триггер переходит в счетный режим, подобно T триггеру. Приводить временные диаграммы работы JK-триггера не имеет смысла, так как они совпадают с приведёнными ранее временными диаграммами RS- и T-триггера. Условно-графическое обозначение JK-триггера приведено на рисунке 2.
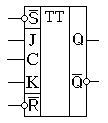
На этом рисунке приведено обозначение типовой цифровой микросхемы К1554ТВ9, выполненной по ТТЛ технологии. В промышленно выпускающихся микросхемах обычно кроме входов j и k реализуются входы RS-триггера, которые позволяют устанавливать jk триггер в заранее определённое исходное состояние. В названиях отечественных микросхем для обозначения jk триггера присутствуют буквы ТВ. Например, микросхема К1554ТВ9 содержит в одном корпусе два jk триггера. В качестве примеров иностранных микросхем, содержащих jk триггеры можно назвать такие микросхемы, как 74HCT73 или 74ACT109. Так как jk триггер является универсальной схемой, то рассмотрим несколько примеров ее использования. Начнем с примера использования этого триггера в качестве обнаружителя коротких импульсов.
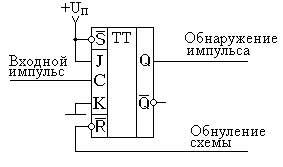
В данной схеме при поступлении на вход "C" импульса триггер переходит в единичное состояние, которое затем может быть обнаружено последующей схемой (например, микропроцессором). Для того, чтобы привести схему в исходное состояние, необходимо подать на вход R уровень логического нуля. Теперь рассмотрим пример построения на jk триггере ждущего мультивибратора. Один из вариантов подобной схемы приведен на рисунке 4.
Схема работает подобно предыдущей схеме. Длительность выходного импульса определяется постоянной времени RC цепочки. Диод VD1 предназначен для быстрого восстановления исходного состояния схемы (разряда емкости C). Если быстрое восстановление схемы не требуется, например, когда длительность выходных импульсов гарантированно меньше половины периода следования входных импульсов, то диод VD1 можно исключить из схемы ждущего мультивибратора. В качестве последнего примера применения универсального jk триггера, рассмотрим схему счетного T-триггера. Схема счетного триггера приведена на рисунке 5.
В схеме, приведенной на рисунке 5, для реализации счетного режима работы триггера на входы J и K подаются уровни логической единицы. Если эти входы вывести в качестве отдельного входа, то они образуют отдельный вход разрешения счета T
Одним из наиболее распространенных способов классификации ЭВМ является систематика Флинна (Flynn), в рамках которой основное внимание при анализе архитектуры вычислительных систем уделяется способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных. При таком подходе различают следующие основные типы систем (см. [2, 31, 59]):
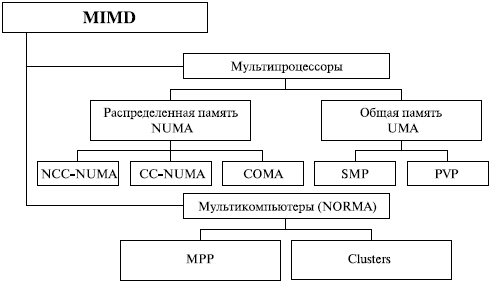
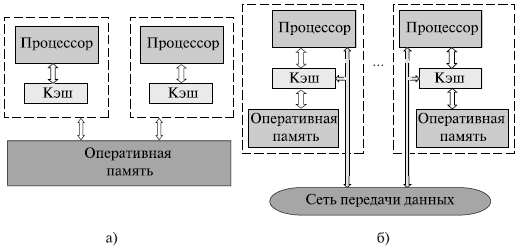
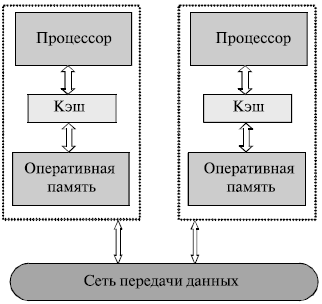
Следует отметить, что хотя систематика Флинна широко используется при конкретизации типов компьютерных систем, такая классификация приводит к тому, что практически все виды параллельных систем (несмотря на их существенную разнородность) оказываются отнесены к одной группе MIMD. Как результат, многими исследователями предпринимались неоднократные попытки детализации систематики Флинна. Так, например, для класса MIMD предложена практически общепризнанная структурная схема (см. [24, 75]), в которой дальнейшее разделение типов многопроцессорных систем основывается на используемых способах организации оперативной памяти в этих системах (см. рис. 1.4). Такой подход позволяет различать два важных типа многопроцессорных систем – multiprocessors (мультипроцессоры или системы с общей разделяемой памятью) и multicomputers (мультикомпьютеры или системы с распределенной памятью). Мультипроцессоры Для дальнейшей систематики мультипроцессоров учитывается способ построения общей памяти. Первый возможный вариант – использование единой (централизованной) общей памяти (shared memory) (см. рис. 1.5 а). Такой подход обеспечивает однородный доступ к памяти (uniform memory access или UMA) и служит основой для построения векторных параллельных процессоров (parallel vector processor или PVP) и симметричных мультипроцессоров (symmetric multiprocessor или SMP). Среди примеров первой группы - суперкомпьютер Cray T90, ко второй группе относятся IBM eServer, Sun StarFire, HP Superdome, SGI Origin и др.
Одной из основных проблем, которые возникают при организации параллельных вычислений на такого типа системах, является доступ с разных процессоров к общим данным и обеспечение, в связи с этим, однозначности (когерентности) содержимого разных кэшей (cache coherence problem). Дело в том, что при наличии общих данных копии значений одних и тех же переменных могут оказаться в кэшах разных процессоров. Если в такой ситуации (при наличии копий общих данных) один из процессоров выполнит изменение значения разделяемой переменной, то значения копий в кэшах других процессоров окажутся не соответствующими действительности и их использование приведет к некорректности вычислений. Обеспечение однозначности кэшей обычно реализуется на аппаратном уровне – для этого после изменения значения общей переменной все копии этой переменной в кэшах отмечаются как недействительные и последующий доступ к переменной потребует обязательного обращения к основной памяти. Следует отметить, что необходимость обеспечения когерентности приводит к некоторому снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров. Наличие общих данных при параллельных вычислениях приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так, например, если изменение общих данных требует для своего выполнения некоторой последовательности действий, то необходимо обеспечить взаимоисключение (mutual exclusion), чтобы эти изменения в любой момент времени мог выполнять только один командный поток. Задачи взаимоисключения и синхронизации относятся к числу классических проблем, и их рассмотрение при разработке параллельных программ является одним из основных вопросов параллельного программирования. Общий доступ к данным может быть обеспечен и при физически распределенной памяти (при этом, естественно, длительность доступа уже не будет одинаковой для всех элементов памяти) (см. рис. 1.5 б). Такой подход именуется неоднородным доступом к памяти (non-uniform memory access или NUMA). Среди систем с таким типом памяти выделяют:
Использование распределенной общей памяти (distributed shared memory или DSM) упрощает проблемы создания мультипроцессоров (известны примеры систем с несколькими тысячами процессоров), однако возникающие при этом проблемы эффективного использования распределенной памяти (время доступа к локальной и удаленной памяти может различаться на несколько порядков) приводят к существенному повышению сложности параллельного программирования. Мультикомпьютеры Мультикомпьютеры (многопроцессорные системы с распределенной памятью) уже не обеспечивают общего доступа ко всей имеющейся в системах памяти (no-remote memory access или NORMA) (см. рис. 1.6). При всей схожести подобной архитектуры с системами с распределенной общей памятью (рис. 1.5б), мультикомпьютеры имеют принципиальное отличие: каждый процессор системы может использовать только свою локальную память, в то время как для доступа к данным, располагаемым на других процессорах, необходимо явно выполнить операции передачи сообщений (message passing operations). Данный подход применяется при построении двух важных типов многопроцессорных вычислительных систем (см. рис. 1.4) - массивно-параллельных систем (massively parallel processor или MPP) и кластеров (clusters). Среди представителей первого типа систем — IBM RS/6000 SP2, Intel PARAGON, ASCI Red, транспьютерные системы Parsytec и др.; примерами кластеров являются, например, системы AC3 Velocity и NCSA NT Supercluster.
Следует отметить чрезвычайно быстрое развитие многопроцессорных вычислительных систем кластерного типа – общая характеристика данного подхода приведена, например, в обзоре [19]. Под кластером обычно понимается (см. [60,76]) множество отдельных компьютеров, объединенных в сеть, для которых при помощи специальных аппаратно-программных средств обеспечивается возможность унифицированного управления (single system image), надежного функционирования (availability) и эффективного использования (performance). Кластеры могут быть образованы на базе уже существующих у потребителей отдельных компьютеров либо же сконструированы из типовых компьютерных элементов, что обычно не требует значительных финансовых затрат. Применение кластеров может также в некоторой степени устранить проблемы, связанные с разработкой параллельных алгоритмов и программ, поскольку повышение вычислительной мощности отдельных процессоров позволяет строить кластеры из сравнительно небольшого количества (несколько десятков) отдельных компьютеров (lowly parallel processing). Тем самым, для параллельного выполнения в алгоритмах решения вычислительных задач достаточно выделять только крупные независимые части расчетов (coarse granularity), что, в свою очередь, снижает сложность построения параллельных методов вычислений и уменьшает потоки передаваемых данных между компьютерами кластера. Вместе с этим следует отметить, что организация взаимодействия вычислительных узлов кластера при помощи передачи сообщений обычно приводит к значительным временным задержкам, и это накладывает дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ. Отдельные исследователи обращают особое внимание на отличие понятия кластера от сети компьютеров (network of workstations или NOW). Для построения локальной компьютерной сети, как правило, используют более простые сети передачи данных (порядка 100 Мбит/сек). Компьютеры сети обычно более рассредоточены, и пользователи могут применять их для выполнения каких-либо дополнительных работ. В завершение обсуждаемой темы можно отметить, что существуют и другие способы классификации вычислительных систем (достаточно полный обзор подходов представлен в [2, 45,59], см. также материалы сайта http://www.parallel.ru/computers/taxonomy/). При рассмотрении темы параллельных вычислений рекомендуется обратить внимание на способ структурной нотации для описания архитектуры ЭВМ, позволяющий с высокой степенью точности описать многие характерные особенности компьютерных систем.
Архитектура ЭВМ включает в себя как структуру, отражающую состав ПК, так и программно – математическое обеспечение. Структура ЭВМ - совокупность элементов и связей между ними. Основным принципом построения всех современных ЭВМ является программное управление. Основы учения об архитектуре вычислительных машин были заложены Джон фон Нейманом. Совокупность этих принципов породила классическую (фон-неймановскую) архитектуру ЭВМ. Фон Нейман не только выдвинул основополагающие принципы логического устройства ЭВМ, но и предложил ее структуру, представленную на рисунке 1.
Положения фон Неймана:
Один из важнейших принципов – принцип хранимой программы – требует, чтобы программа закладывалась в память машины так же, как в нее закладывается исходная информация. Арифметико-логическое устройство и устройство управления в современных компьютерах образуют процессор ЭВМ. Процессор, который состоит из одной или нескольких больших интегральных схем называется микропроцессором или микропроцессорным комплектом. Процессор – функциональная часть ЭВМ, выполняющая основные операции по обработке данных и управлению работой других блоков. Процессор является преобразователем информации, поступающей из памяти и внешних устройств. Запоминающие устройства обеспечивают хранение исходных и промежуточных данных, результатов вычислений, а также программ. Они включают: оперативные (ОЗУ), сверхоперативные СОЗУ), постоянные (ПЗУ) и внешние (ВЗУ) запоминающие устройства. Оперативные ЗУ хранят информацию, с которой компьютер работает непосредственно в данное время (резидентная часть операционной системы, прикладная программа, обрабатываемые данные). В СОЗУ хранится наиболее часто используемые процессором данные. Только та информация, которая хранится в СОЗУ и ОЗУ, непосредственно доступна процессору. Внешние запоминающие устройства (накопители на магнитных дисках, например, жесткий диск или винчестер) с емкостью намного больше, чем ОЗУ, но с существенно более медленным доступом, используются для длительного хранения больших объемов информации. Например, операционная система (ОС) хранится на жестком диске, но при запуске компьютера резидентная часть ОС загружается в ОЗУ и находится там до завершения сеанса работы ПК. ПЗУ (постоянные запоминающие устройства) и ППЗУ (перепрограммируемые постоянные запоминающие устройства) предназначены для постоянного хранения информации, которая записывается туда при ее изготовлении, например, ППЗУ для BIOS. В качестве устройства ввода информации служит, например, клавиатура. В качестве устройства вывода – дисплей, принтер и т.д. В построенной по схеме фон Неймана ЭВМ происходит последовательное считывание команд из памяти и их выполнение. Номер (адрес) очередной ячейки памяти, из которой будет извлечена следующая команда программы, указывается специальным устройством – счетчиком команд в устройстве управления.
Так исторически сложилось, что поначалу совершенствование процессоров было направлено на то, чтобы сконструировать по возможности более функциональный компьютер, который позволил бы выполнять как можно больше разных команд. Во-первых, так было удобнее для программистов (компиляторы языков высокого уровня еще только начинали развиваться, и все по-настоящему важные программы писались на ассемблере), а во-вторых, использование сложных команд зачастую позволяло сильно сократить размеры написанной на ассемблере программы. А где меньше команд – меньше оперативной памяти, меньше время выполнения программы. Надо признать, что достигнутые на этом пути успехи действительно впечатляли - в некоторых версиях компьютеров выразительность ассемблерного листинга зачастую не уступала выразительности программы, написанной на языке высокого уровня. Одной-единственной машинной командой можно было сказать практически все, что угодно. К примеру, такие компьютеры как VAX фирмы DEC, аппаратно поддерживали команды "добавить элемент в очередь", "удалить элемент из очереди" и даже "провести интерполяцию полиномом"; а знаменитое семейство процессоров Motorola 68k почти для всех команд поддерживало до двенадцати режимов адресации оперативной памяти, вплоть до взятия в качестве аргумента команды "данных, записанных по адресу, записанному вон в том регистре, со смещением, записанным вот в этом регистре". Отсюда и общее название соответствующих архитектур: CISC - Complex Instruction Set Computers ("компьютеры с набором команд на все случаи жизни"). На практике это привело к тому, что подобные команды оказалось сложно не только выполнять, но и просто декодировать (выделять из машинного кода новую команду и отправлять ее на исполнительные устройства). Чтобы машинный код CISC-компьютеров из-за сложных команд не разрастался до огромного размера, машинные команды в большинстве этих архитектур имели: неоднородную структуру (разное расположение и размеры кода операции и ее операндов); сильно отличающуюся длину (в архитектуре IA-32/64, например, длина команд варьируется от 1 до 16 байт). Еще одной проблемой стало то, что при сохранении приемлемой сложности ядра процессора многие команды оказалось принципиально невозможно выполнить "чисто аппаратно", и поздние CISC-процессоры были вынуждены обзавестись специальными блоками, которые "на лету" заменяли некоторые сложные команды на последовательности более простых команд. В результате все CISC-процессоры оказались весьма трудоемкими в проектировании и изготовлении. Но что самое печальное, к моменту расцвета CISC-архитектур стало ясно, что все эти конструкции изобретались в общем-то зря - исследования программного обеспечения того времени наглядно показали, что даже программисты, пишущие на ассемблере, все эти "сверхвозможности" почти не использовали, а компиляторы языков высокого уровня - и не пытались использовать.
К началу 80-х годов оказалось, что трудно наращивать частоту процессоров, прежде всего из-за недостаточного быстродействия памяти для хранения микропрограмм, аппаратуру процессора невозможно реализовать в виде одной или нескольких микросхем достаточно большой интеграции. Стало очевидным, что архитектуры CISC нужно упрощать - и на свет появились RISC-архитектуры (Reduced Instruction Set Computer). Шаг первый. CISC Так уж исторически сложилось, что поначалу совершенствование процессоров было направлено на то, чтобы сконструировать по возможности более функциональный компьютер, который позволил бы выполнять как можно больше разных инструкций. Во-первых, так было удобнее для программистов (компиляторы языков высокого уровня еще только начинали развиваться, и все по-настоящему важные программы писались на ассемблере), а во-вторых, использование сложных инструкций зачастую позволяло сильно сократить размеры написанной на ассемблере программы. А где меньше инструкций – меньше и затраченное на исполнение программы время. Надо признать, что достигнутые на этом пути успехи действительно впечатляли - в последних версиях ЭВМ выразительность ассемблерного листинга зачастую не уступала выразительности программы, написанной на языке высокого уровня. Одной-единственной машинной инструкцией можно было сказать практически все, что угодно. К примеру, такие машины, как DEC VAX, аппаратно поддерживали инструкции "добавить элемент в очередь", "удалить элемент из очереди" и даже "провести интерполяцию полиномом" (!); а знаменитое семейство процессоров Motorola 68k почти для всех инструкций поддерживало до двенадцати (!) режимов адресации памяти, вплоть до взятия в качестве аргумента инструкции "данных, записанных по адресу, записанному вон в том регистре, со смещением, записанным вот в этом регистре". Отсюда и общее название соответствующих архитектур: CISC - Complex Instruction Set Computers ("компьютеры с набором инструкций на все случаи жизни"). На практике это привело к тому, что подобные инструкции оказалось сложно не только выполнять, но и просто декодировать (выделять из машинного кода новую инструкцию и отправлять ее на исполнительные устройства). Чтобы машинный код CISC-компьютеров из-за сложных инструкций не разрастался до огромного размера, машинные инструкции в большинстве этих архитектур имели неоднородную структуру (разное расположение и размеры кода операции и ее операндов) и сильно отличающуюся длину (в x86, например, длина инструкций варьируется от 1 до 15 байт). Еще одной проблемой стало то, что при сохранении приемлемой сложности процессора многие инструкции оказалось принципиально невозможно выполнить "чисто аппаратно", и поздние CISC-процессоры были вынуждены обзавестись специальными блоками, которые "на лету" заменяли некоторые сложные команды на последовательности более простых. В результате все CISC-процессоры оказались весьма трудоемкими в проектировании и изготовлении. Но что самое печальное, к моменту расцвета CISC-архитектур стало ясно, что все эти конструкции изобретались в общем-то зря - исследования программного обеспечения того времени, проведенные IBM, наглядно показали, что даже программисты, пишущие на ассемблере, все эти "сверхвозможности" почти никогда не использовали, а компиляторы языков высокого уровня - и не пытались использовать. К началу восьмидесятых годов классические CISC полностью исчерпали себя. Расширять набор инструкций в рамках этого подхода дальше не имело смысла, наоборот - технологи столкнулись с тем, что из-за высокой сложности CISC-процессоров оказалось трудно наращивать их тактовую частоту, а из-за "тормознутости" оперативной памяти тех времен зашитые в память процессора расшифровки сложных инструкций зачастую работают медленнее, чем точно такие же цепочки команд, встречающиеся в основной программе. Короче говоря, стало очевидным, что CISC-процессоры нужно упрощать - и на свет появился RISC, Reduced Instruction Set Computer. Шаг 2. RISC Точно так же, как когда-то CISC-процессоры проектировались под нужды asm-программистов, RISC проектировался в расчете на типовой код, генерируемый компиляторами. Для начала разработчики свели к минимуму набор инструкций и к абсолютному минимуму - количество режимов адресации памяти; упаковав все, что осталось, в простой и удобный для декодирования регулярный машинный код. В частности, в классическом варианте RISC из инструкций, обращающихся к оперативной памяти, оставлены только две (Load - загрузить данные в регистр и Store - сохранить данные из регистра; так называемая Load/Store-архитектура), и нет ни одной инструкции вроде вычисления синуса, косинуса или квадратного корня (их можно реализовать "вручную"), не говоря уже о более сложных[Канонический пример - инструкция INDEX, выполнявшаяся на VAX медленнее, чем вручную написанный цикл, выполняющий ровно тот же объем работы]. Да что там синус с косинусом - в некоторых RISC-процессорах пытались отказаться даже от трудно реализуемого аппаратного умножения и деления! Правда, до таких крайностей ни один коммерческий RISC, к счастью, не дошел, но как минимум две попытки (ранние варианты MIPS и SPARC) предприняты были. Второе важное усовершенствование RISC-процессоров, целиком вытекающее из Load/Store-архитектуры, - увеличение числа GPR (регистров общего назначения). Варианты, у которых меньше шестнадцати GPR, - большая редкость, причем почти все эти регистры полностью равноправны, что позволяет компилятору свободно распоряжаться ими, сохраняя большую часть промежуточных данных именно там, а не в стеке или оперативной памяти. В некоторых архитектурах, типа SPARC, "регистровость" возведена в абсолют, в некоторых - оставлена на разумном уровне; однако почти любой RISC-процессор обладает куда большим набором регистров, чем даже самый продвинутый CISC. Для сравнения: в классическом x86 IA-32 всего восемь регистров общего назначения, причем каждому из них приписано то или иное "специальное назначение" (скажем, в ESP хранится указатель на стек) затрудняющее или делающее невозможным его использование. Среди прочих усовершенствований, внесенных в RISC, - такие нетривиальные идеи, как условные инструкции ARM или режимы работы команд. Например, некий модификатор в архитектуре PowerPC и некоторых других показывает, должна ли инструкция выставлять по результатам своего выполнения определенные флаги, которые потом может использовать инструкция условного перехода, или не должна. Это позволяет разнести в пространстве инструкцию, выполняющую вычисление условия, и инструкцию собственно условного перехода - что в конвейерных архитектурах зачастую позволяет процессору не "гадать", будет совершен переход или нет, а сразу достоверно это знать. В классическом CISC они почти не встречаются, поскольку на момент разработки соответствующих наборов инструкций ценность этих решений была сомнительной (они выйдут на сцену только в конвейеризированных процессорах). "В чистом виде" идею "легкого" RISC-процессора можно встретить у компании ARM с ее невероятно простыми и тем не менее весьма эффективными 32-разрядными CPU. Но простота далеко не главный показатель в процессоре, и как самоцель подход RISC в целом себя, наверное, не оправдал бы - резко уменьшившаяся сложность CPU и сопутствующее увеличение тактовой частоты и ускорение исполнения инструкций хорошо уравновешивались возросшими размерами программ и сильно упавшей их вычислительной плотностью (средним количеством вычислений на единицу длины машинного кода). К счастью, в то же время, когда начались разработки первых коммерческих RISC-процессоров, был сделан следующий шаг – введён конвейер.
Операти́вная па́мять (англ. Random Access Memory, RAM, память с произвольным доступом; ОЗУ ( оперативное запоминающее устройство ); комп. жарг. память, оперативка) — энергозависимая часть системы компьютерной памяти, в которой во время работы компьютера хранится выполняемый машинный код (программы), а также входные, выходные и промежуточные данные, обрабатываемые процессором. Обмен данными между процессором и оперативной памятью производится:
Содержащиеся в современной полупроводниковой оперативной памяти данные доступны и сохраняются только тогда, когда на модули памяти подаётся напряжение. Выключение питания оперативной памяти, даже кратковременное, приводит к искажению либо полному разрушению хранимой информации. Энергосберегающие режимы работы материнской платы компьютера позволяют переводить его в режим сна, что значительно сокращает уровень потребления компьютером электроэнергии. В режиме гибернации питание ОЗУ отключается. В этом случае для сохранения содержимого ОЗУ операционная система (ОС) перед отключением питания записывает содержимое ОЗУ на устройство постоянного хранения данных (как правило, жёсткий диск). Например, в ОС Windows XP содержимое памяти сохраняется в файл hiberfil.sys, в ОС семейства Unix — на специальный swap-раздел жёсткого диска. В общем случае, ОЗУ содержит программы и данные ОС и запущенные прикладные программы пользователя и данные этих программ, поэтому от объёма оперативной памяти зависит количество задач, которые одновременно может выполнять компьютер под управлением ОС. Оперативное запоминающее устройство, ОЗУ — техническое устройство, реализующее функции оперативной памяти. ОЗУ может изготавливаться как отдельный внешний модуль или располагаться на одном кристалле с процессором, например, в однокристальных ЭВМ или однокристальных микроконтроллерах. Содержание
История См. также: История вычислительной техники В 1834 году Чарльз Бэббидж начал разработку аналитической машины. Одну из важных частей этой машины он называл «складом» (store), эта часть предназначалась для хранения промежуточных результатов вычислений. Информация в «складе» запоминалась в чисто механическом устройстве в виде поворотов валов и шестерней. ЭВМ первого поколения можно считать ещё полуэкспериментальными, поэтому в них использовалось множество разновидностей и конструкций запоминающих устройств, основанных на различных физических принципах:
В качестве ОЗУ использовались также магнитные барабаны, обеспечивавшие достаточно малое для ранних компьютеров время доступа; также они использовались в качестве основной памяти для хранения программ и данных. Второе поколение требовало более технологичных, дешёвых и быстродействующих ОЗУ. Наиболее распространённым видом ОЗУ в то время стала память на магнитных сердечниках. Начиная с третьего поколения большинство электронных узлов компьютеров стали выполнять на микросхемах, в том числе и ОЗУ. Наибольшее распространение получили два вида ОЗУ:
Статическая и динамическая память не сохраняли информацию при отключении питания. Сохранять информацию при отключении питания способна энергонезависимая память. Сейчас применяются два основных вида ОЗУ:
В SRAM бит данных хранится в виде состояния триггера. Этот вид памяти является более дорогим в расчёте на хранение 1 бита, но, как правило, имеет наименьшее время доступа и меньшее энергопотребление, чем DRAM. В современных компьютерах часто используется в качестве кэш-памяти процессора. DRAM хранит бит данных в виде заряда конденсатора. Однобитовая ячейка памяти содержит конденсатор и транзистор. Конденсатор заряжается до более высокого или низкого напряжения (логические 1 или 0). Транзистор выполняет функцию ключа, подключающего конденсатор к схеме управления, расположенного на том же чипе. Схема управления позволяет считывать состояние заряда конденсатора или изменять его. Так как хранение 1 бита информации в этом виде памяти дешевле, чем в SRAM, DRAM сейчас преобладает в компьютерах. Статические и динамические ОЗУ являются энергозависимыми, так как информация в них теряется при отключении питания. Энергонезависимые (постоянная память, ПЗУ) устройства сохраняют информацию вне зависимости от наличия питания. К ним относятся флэш-накопители, карты памяти для фотоаппаратов и портативных устройств и т. д. В устройствах управления энергозависимой памяти (SRAM или DRAM) часто включают специальные схемы для обнаружения и/или исправления ошибок. Это достигается введением избыточных битов в хранимые машинные слова, используемые для проверки (например, биты чётности) или коррекции ошибок. Точнее, термин RAM относится только к устройствам твёрдотельной памяти DRAM или SRAM — основной памяти большинства современных компьютеров. Для оптических дисков термин DVD-RAM не совсем корректен, так
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-06-29; просмотров: 790; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.117.107 (0.014 с.) |