Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Ускорение вычислений при помощи технологий SLI и CrossFireСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Для повышения производительности видеосистем ПК ведущие фирмы-производители предлагают варианты объединения нескольких (на текущий момент – двух) видеоплат в одну видеосистему. Для фирмы nVIDIA – это технология SLI (Scalable Link Interface), а для фирмы ATi –технология CrossFire. NVIDIA SLI. Интерфейс SLI (Scalable Link Interface - масштабируемый интерфейс соединения) определяет многопроцессорную графическую технологию, реализованную в последних продуктах фирмы nVIDIA. Использование SLI позволяет повысить производительность 3D-приложений за счет объединения двух графических ускорителей. На данный момент технология реализована для семейств GeForce 6600/6800 использующих интерфейс PCI Express x16. Для объединения плат используется мостовая схема (симметричное или изотропное подключение). Похожая технология использовалась в графических ускорителях Voodoo 2 фирмы 3Dfx, которая была приобретена фирмой nVIDIA. У фирмы 3Dfx эта технология носила название Scan Line Interface, так как распараллеливание вычислений в видеосистеме осуществлялось за счет обработки нечетных строк экрана на одной видеоплате, а четных – на другой. У фирмы nVIDIA использует мостовое соединение видеоплат и распараллеливание осуществляется по другому принципу: одна плата обрабатывает верхнюю часть экрана, а другая – нижнюю. При этом граница разделения экрана может изменяться в зависимости от содержимого экрана таким образом, чтобы равномерно загрузить обе платы (динамическая регулировка нагрузки). Технология nVIDIA SLI позволяет увеличить производительность видеосистемы до 200%. ATi CrossFire. Основная цель технологии CrossFire (Перекрестный Огонь) — организация совместной работы двух графических ускорителей над построением изображения. Причем, архитектура должна быть не только эффективной (высокий КПД, низкая стоимость дополнительных схем и т.п.), но и удобной в использовании (совместимость с уже существующими программами и даже с уже существующими аппаратными решениями, прозрачность, простота и надежность). Несколько ускорителей (в варианте для пользователей ПК их два) формируют собственную часть изображения, и выводят её через трансмиттеры в общепринятом цифровом стандарте DVI. Затем информация попадает в «черный» ящик под названием Composing Engine, устройство, которое собственно и осуществляет совмещение результатов работы ускорителей для получения финального изображения. На выходе из этого ящика — вновь стандартный цифровой DVI сигнал, но на этот раз — уже окончательного кадра, собранного из двух порций данных, рассчитанных обоими VPU.
Для устранения проблем с синхронизацией, Composing Engine содержит собственную буферную память, что позволяет этому устройству накапливать данные асинхронно, и, затем, по мере готовности обоих ускорителей, формировать и выдавать результирующий кадр. Таким образом, четкая синхронизация работы VPU (Vertex Processing Unit) не требуется, достаточно двух фактов — каждый VPU должен знать, какую часть данных ему надо рассчитать, и каждый VPU должен закончить передачу рассчитанных данных в Composing Engine. После этого будет осуществлена передача кадра на устройство вывода в формате DVI или (если нам нужен аналоговый сигнал) на внешний графический DAC, преобразующий цифровой DVI поток в стандартный аналоговый VGA сигнал. В настоящее время можно выделить три основных алгоритма, применяемых для распределения данных между потоками в различных потребительских и профессиональных видеосистемах.
Конец 84 вопроса.
Виды растровой развертки. Растровая развертка - это процесс вывода на устройство отображения геометрических образов, представленных в виде дискретных элементов. Подобное представление называется растровым образом или просто растром. В том случае, если растр хранится во внешнем файле, он называется дискретным списком. Существует четыре способа организации растровой развертки: 1) аппаратная растровая развертка в реальном времени; 2) групповое кодирование; 3) клеточное кодирование; 4) растровая развертка с использованием буфера экрана. Аппаратная растровая развертка в реальном времени. Данный способ развертки наименее требовательный к объему памяти. Информация о растре хранится в виде визуальных атрибутов и геометрических характеристик. К визуальным атрибутам относят цветояркостные показатели. К геометрическим атрибутам относят координаты пикселей, углы наклона длин отрезков, описание символьных данных. Все эти данные хранятся в файле типа дисплейный список, в независимом от аппаратуры виде. В каждом цикле своей работы дисплейный процессор, обслуживающий устройство отображения, производит считывание информации из этого файла и построение на экране. Достоинства заключаются в низком требовании к объему памяти и удобстве коррекции дисплейного списка. Недостатки: высокие требования к быстродействию дисплейного процессора и пропускной способности канала передачи графической информации, а также ограничения на размер дисплейного списка, вызванные тем, что дисплейный процессор за один такт работы может обработать конечное количество графических данных.
Область применения. Так как на работу процессора накладываются такие же требования, то подобный способ растровой развертки может применяться только в специализированных устройствах (летные и навигационные тренажеры). Групповое кодирование. При групповом кодировании растр рассматривается, как линейная последовательность пикселей, при этом создается возможность выделять группы однородных пикселей и заменять их двойкой чисел. Первое число определяет длину однородной последовательности, второе – цвет. Кроме хранения графических данных, данный метод позволяет сжимать данную информацию. Достоинство заключается в экономии памяти для простых растров и экономии памяти при пересылке растровых данных. Недостатки заключаются в сложности коррекции растра и в эффективном сжатии только для простых изображений. Область применения: простейшие форматы представления растровых данных, составляющая более сложных алгоритмов сжатия. Клеточное кодирование растровых данных. Использование клеточного кодирования позволяет в несколько раз уменьшить объем растровой информации. Происходит это за счет того, что целые фрагменты растра описываются одним или двумя байтами. Элемент растра, при помощи которого осуществляется клеточное кодирование, называется текселом. Наиболее распространенным примером клеточного кодирования является алфавитно-цифровые режимы работы мониторов, при этом происходит следующее сжатие информации:
В общем случае для клетки размером NxM существует 2nm возможных вариантов заполнения. Количество базовых вариантов можно значительно сократить, если использовать операции сдвига, поворота и отражения, например, для клетки 8х8 число шаблонов сократится до 108. Достоинства: 1) экономия памяти при хранении растровой информации; 2) высокое быстродействие отображения растровой информации (обычно кодировка клеток хранится либо в ПЗУ, либо в ОЗУ, а их отображение заключается в простом переносе строки бит из одной части памяти в другую).
Недостатки: 1) невозможность получения рисунков сложной конфигурации; 2) невозможность передачи большого числа цветов. Область применения: Устаревшие алфавитно-цифровые текстовые режимы на мало производительных компьютерах. Растровая развертка с использованием буфера экрана. Буфер кадра представляет собой непрерывную область памяти, в которой хранится и из которой отображается полное изображение экрана. Буфер кадра может располагаться:
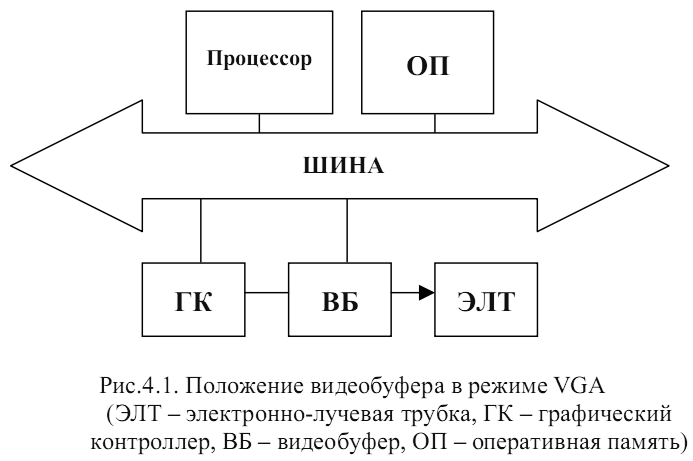
1) на диске (не используется из-за низкого быстродействия); 2) в оперативной памяти (используется чаще всего); 3) в регистровой памяти (не используется из-за высокой цены). Расположение видеобуфера в стандартном режиме работы видео-системы представлено на рис.4.1.
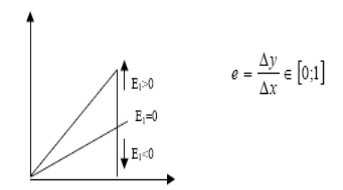
Достоинства: 1) низкая стоимость (определяется низкой стоимостью элементной базы оперативной памяти); 2) высокое быстродействие. Недостаток: 1) отсутствие полноценного высокоскоростного канала связи с вычислительным ядром. Область применения: большинство современных видеосистем персональных и профессиональных компьютеров. Конец 18 вопроса. Существует два вида реализации этого алгоритма: вещественный и целочисленный. Вещественный служит базой для построения целочисленного алгоритма. Работа вещественного алгоритма базируется на расчете дополнительной переменной – оценки отложения точки аппроксимации от истинного направления (обозначим эту оценку как е).
Для удобства работы величину е изменяют таким образом, чтобы она в крайних точках имела значения с противоположенными значениями:
Недостатки: 1) наличие операций деления. 2) вещественный характер вычислений. Для того, чтобы работать в одной области определения с растровыми данными, осуществляется переход к целочисленным значениям оценки е:
Алгоритм основанный на данном вычисление оценки, позволяет эффективно реализовать растровые разложения отрезка как на аппаратном, так и на программном уровнях.
|
||||||||
|
|
Последнее изменение этой страницы: 2016-04-21; просмотров: 429; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.216.40.40 (0.01 с.) |


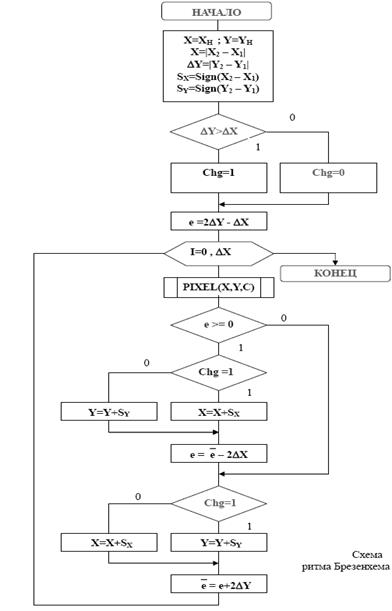
 Рассмотрим работу алгоритма в I квадранте:
Рассмотрим работу алгоритма в I квадранте: