Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Реляционная модель данных и операции над отношениямиСодержание книги
Поиск на нашем сайте
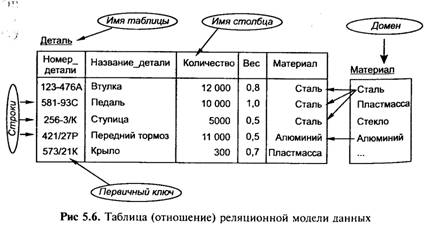
В то время как иерархическая модель в своей основе является формализацией и обобщением пользовательских свойств некоторой конкретной системы (IMS), в случае реляционной модели сначала были разработаны некоторые математические основы и лишь через 5—10 лет появились первые коммерчески эффективные системы. Реляционная модель предложена сотрудником компании IBM Е. Ф. Коддом в 1970 г. В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation — «отношение»). Определения. Перейдем к рассмотрению структурной части реляционной модели данных. Прежде всего необходимо дать несколько определений. Декартово произведение: для заданных конечных множеств D1, D2, …, DN (не обязательно различных) декартовым (прямым) произведением D1 × D2 × …× DN называется множество наборов: {d1 ,d2 …,dN},где d1 D1, d2 D2,..., dN DN. Например, если даны два множество А = {а1, а2, а3} и В={b1, b2}, их декартово произведение будет иметь вид C=A х В = {{а1b1}, {а1,b2}, {а2,b1}, {a2,b2}, {a3,b1,}, {a3 b2}}. Отношение: отношением R, определенным на множества D1, D2,..., DN, называется подмножество декартова произведены D1 х D2 x... х DN. При этом: множества D1, D2,..., DN называются доменами отношения-элементы декартова произведения {d1, d2,..., dN} называются кортежами; число N определяет степень отношения (N= 1 — унарное, N= 2 — бинарное,..., N-арное); количество кортежей называется мощностью отношения; На множестве С из предыдущего примера могут быть определены отношения R1 ={{а1,b2},{а3,b2}} или R2 = {{a1,b1}, {a2,b1},{a1,b2}}. Отношения удобно представлять в виде таблиц. Строки таблицы называются экземплярами отношения, столбцы — атрибутами; каждый атрибут имеет область значений, называемую доменом. На рис. 5.6 представлена таблица (отношение степени 5), содержащая некоторые сведения о деталях автомобилей.
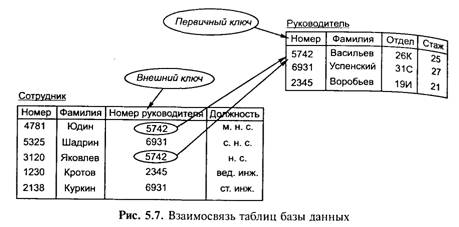
Так, таблица Деталь содержит сведения обо всех деталях, хранящихся на складе, а ее строки являются наборами значений атрибутов конкретных деталей. Каждый столбец таблицы — это совокупность значений конкретного атрибута объекта. Столбец Материал может содержать конечный перечень значений – Сталь, Олово, Цинк, Никель и т. д. В столбце Количество содержатся целые неотрицательные числа, Значения в столбце Вес – вещественные числа, равные весу детали в килограммах. Каждый атрибут определен на домене, поэтому домен, (domain) можно рассматривать как множество допустимых значений данного атрибута. Так, значения в столбце Материал выбираются из множества имен всех возможных материалов —пластмасс, древесины, металлов и т. д. Следовательно, в столбце Материал невозможно появление значения, которого нет в соответствующем домене, например, Вода или Песок. Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы (рис. 5.6). Оно должно быть уникальным в таблице, однако различные таблицы могут иметь столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один столбец; столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от столбцов, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено. Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции — среди них не существует «первой», «второй», «последней». Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом (primary key). В таблице Деталь первичный ключ — это столбец Номер_детали. В нашем примере каждая деталь на складе имеет единственный номер, по которому из таблицы Деталь извлекается необходимая информация. Следовательно, в этой таблице первичный ключ — это столбец Номердетали. В этом столбце значения не могут дублироваться — в таблице Деталь не должно быть строк, меющих одно и то же значение в столбце Номер_детали. Если а лица удовлетворяет этому требованию, она называется отношением (relation). Взаимосвязь таблиц является важнейшим элементом реляционной модели данных. Она поддерживается внешними ключами (external). Рассмотрим пример, в котором база данных хранит информация о рядовых служащих (таблица Служащий) и руководителях (таблица Руководитель) в некоторой организации) Первичный ключ таблицы Руководитель — столбец
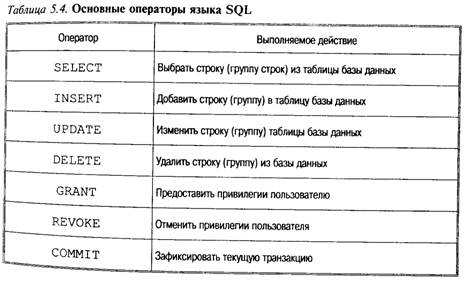
Номер (например, табельный номер). Столбец Фамилия не может выполнять роль первичного ключа, так как в одной организации могут работать два руководителя с одинаковыми фамилиями. Любой служащий подчинен единственному руководителю, что должно быть отражено в базе данных. Таблица Служащий содержит столбец Номер_руководителя, и значения в этом столбце выбираются из столбца Номер таблицы Руководитель (см. рис. 5.7). Столбец Номер_Руководителя является внешним ключом В таблице Служащий. Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют «данные о данных» (метаданные), например, описатели таблиц, столбцов и т. д. Метаданные также представлены в табличной форме и хранятся в словаре данных (DD — data dictionary) или описателе БД (DBD — data base definition) — служебном файле или системной таблице БД. Помимо таблиц в базе данных могут храниться и другие объекты, такие, как экранные формы, отчеты (reports), представления (views) и прикладные программы, работающие с базой данных. Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности (integrity). Для того чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints). Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблицы выбирались только из только из соответствующего домена. На практике учитывали более сложные ограничения целостности, например целебность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Свойства отношений. Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого кортежа первичного ключа. Для каждого отношения, по крайней мере, полный набор его атрибутов является первичным ключом. Однако при определении первичного ключа должно соблюдаться требование минимальности, т. е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа — однозначно определять кортеж. Отсутствие упорядоченности атрибутов. Для ссылки на значение атрибута всегда используется имя атрибута. Атомарность значений атрибутов, т. е. среди значений домена не могут содержаться множества значений (отношения). Реляционная алгебра. Важным отличием РМД является возможность применения формального аппарата, описывающего преобразование и обработку данных в РМД — реляционной алгебры. Операндами реляционной алгебры являются отношения как постоянные, так и переменные. Операции реляционной алгебры включают следующие преобразования отношений. А. Теоретико-множественные операции над несколькими подобными (имеющими одинаковую структуру: число атрибутов, Их имен, домены и т. д.), отношениями, в том числе объедиение, пересечение, разность. Б. Операции над одним отношением: • селекция, или построение отношения-результата из отношения-источника путем отбора экземпляров, удовлетворяющих некоторому критерию отбора. Операция селекции соответствует поиску информации в БД по логическим условиям; (find... with, find...where, locate, см табл. 5.5 • проекция, или построение результирующего отношения п тем отбора части атрибутов всех экземпляров исходного отнощ ния. Данной операции в реальных СУБД соответствует поняти пользовательской подсхемы и операции выдачи необходимы данных (DISPLAY, VIEW, SET FORM TO, REPORT FORM...). В. Операции над несколькими различными отношениями Назовем только естественное соединение (соединение). Операция заключается в поиске в паре (или большем числе) отношений строк, содержащих общий атрибут, и создания из этих строк экземпляра результирующего отношения. В СУБД соединению соответствует поиск связанных данных или логическое (физическое) связывание файлов (FIND...COUPLED, SET RELATION TO, JOIN. Реляционная алгебра позволяет рассматривать операции ввода, вывода, поиска коррекции и удаления данных в БД как вычисление отношений-результатов через исходные отношения. При этом исходным отношением может быть внешний (входной) формат данных, а результирующим — внутренний (хранимый) или, наоборот, исходным — внутренний, а результирующим — внешний (выходной). Язык SQL С целью стандартизации формального описания запросов к базе данных они формулируются на стандартном языке запросов (ЯМД — язык манипулирования данными), которым для многих СУБД является SQL [8]. Появление и развитие этого языка как средства описания доступа к базе данных связано с созданием теории реляционных баз данных. Прообраз языка SQL возник в 1970 г. в рамках научно-исследовательского проекта System/R, работа над которым велась в лаборатории Санта-Тереза фирмы IBM, и со временем развился в стандарт интерфейса с реляционными СУБД и разработчики нереляционных СУБД снабжают свои системы SQL-интерфейсом. Язык SQL имеет официальный стандарт — ANSI/ISO. Боль шинство разработчиков СУБД придерживаются этого стандарта, однако часто расширяют его для реализации новых возможностей обработки данных. SQL не является языком программирования в традиционном представлении. На нем пишутся не программы, а запросы к базе данных. Поэтому SQL — декларативный язык. Это означает, что с его помощью можно сформулировать, что необходимо получить, но нельзя указать, как это следует сделать. В частности, в отличие от процедурных языков программирования (С, Pascal, Fortran), в языке SQL отсутствуют такие операторы, как if-then-else, for, while и т. д. Запрос на языке SQL состоит из одного или нескольких операторов, следующих один за другим и разделенных точкой с запятой. В табл. 5.4 перечислены некоторые операторы, которые входят в стандарт ANSI/ISO SQL.
В запросах на языке SQL используются имена, которые однозначно идентифицируют объекты базы данных. В частности, это – имя таблицы (Деталь), имя столбца (Название_детали), а также имена других объектов в базе, которые относятся к дополнительным типам (например, имена процедур и правил). Наряду с простыми используются также сложные имена — например, квалифицированное имя столбца (qualified column name) определяет имя столбца и имя таблицы, которой он принадлежит (Название_детали. Вес). Каждый столбец в любой таблице хранит данные определенных типов. Различают базовые типы данных — строки символ фиксированной длины, целые и вещественные числа, и дополнительные типы данных — строки символов переменной длины денежные единицы, дату и время, логические данные (значения — Истина и Ложь). В языке SQL можно использовать числовые, строковые, символьные константы и константы типа дата и Время. Рассмотрим несколько примеров. Запрос: определить количество деталей на складе для щсех типов деталей реализуется следующим образом:
Результатом запроса будет таблица с двумя столбцами – название_детали и Количество, которые взяты из исходной таблицы Деталь. По сути, этот запрос позволяет получить проекцию исходной таблицы — из строк таблицы деталь образуются строки, которые включают значения, взятые из двух столбцов — Название_детали и Количество. Запрос: какие детали, изготовленные из стали, хранятся на складе?, сформулированный на языке SQL, выглядит так:
Результатом этого запроса также будет таблица, содержащая только те строки исходной таблицы, которые имеют в столбце Материал значение Сталь. Этот запрос позволяет получить селекцию таблицы Деталь (звездочка в операторе SELECT означает выбор всех столбцов из таблицы). Запрос: определить название и количество деталей на складе, которые изготовлены из пластмассы и весят менее пяти килограммов будет записан следующим образом:
Результат запроса — таблица из двух столбцов — Название_детали, Количество, которая содержит название и число деталей, изготовленных из пластмассы и весящих менее 5 кг. По сути, операция выборки является операцией селекции (найти все строки таблицы Деталь, у которых Материал = `пластмасса` и Вес < 5), а затем – проекции (извлечь Название_детали и Количество из выбранных ранее строк). Одним из средств, обеспечивающих быстрый доступ к таблицам, являются индексы. Индекс — это служебная структура (указатель) базы данных, представляющая собой указатель на конкретную строку таблицы. Он содержит значения, взятые из одного или нескольких столбцов конкретной строки таблицы, и ссылку на эту строку. Значения в индексе упорядочены, что позволяет СУБД выполнять быстрый поиск в таблице. Допустим, что сформулирован запрос к базе данных Склад:
Если индексов для данной таблицы не существует, то для выполнения этого запроса СУБД должна просмотреть всю таблицу Деталь, последовательно выбирая из нее строки и проверяя для каждой из них условие выбора (последовательное сканирование). Для больших таблиц такой запрос будет выполняться очень долго. Если же был предварительно создан индекс по столбцу Номер таблицы Деталь, то время поиска в таблице будет сокращено до минимума. Индекс будет содержать значения из столбца Номер и ссылку на строку с этим значением в таблице Деталь. При выполнении запроса СУБД вначале найдет в индексе значение 'Т145-А8' (и сделает это быстро, так как индекс упорядочен, з его строки невелики), а затем по ссылке в индексе определит физическое расположение искомой строки. Индекс создается оператором SQL CREATE INDEX (СОЗДАТЬ ИНДЕКС). В данном примере оператор
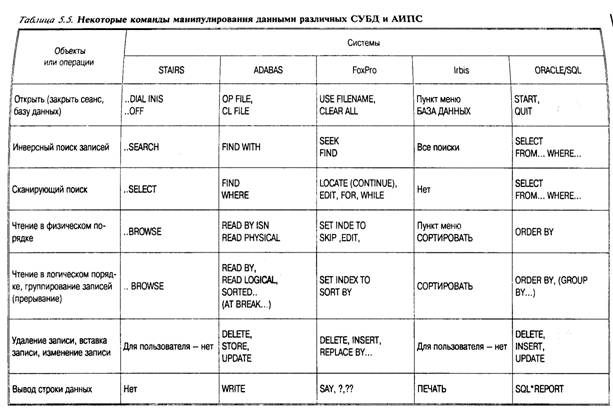
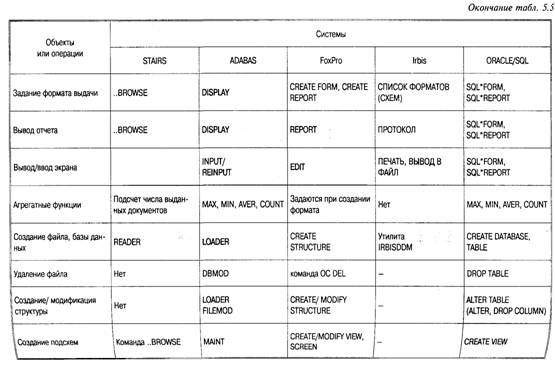
Позволит создать индекс с именем Индекс _детали по столбцу Номер таблицы деталь. Для пользователя СУБД интерес представляют не отдельные операторы языка SQL, а некоторая их последовательность, оформленная как единое целое и имеющая смысл с его точки зрения. Каждая такая последовательность операторов языка SQL реализует определенное действие над базой данных. Оно осуществляется за несколько шагов, на каждом из которых над таблицами базы данных выполняются некоторые операции. Так, в банковской системе перевод некоторой суммы с краткосрочного счета на долгосрочный выполняется в несколько операций. Среди них — снятие суммы с краткосрочного счета, зачисление на долгосрочный счет. Если в процессе выполнения этого действия произойдет сбой, например, когда первая операция будет выполнена, а вторая — нет, то деньги будут потеряны. Следовательно, любое действие над базой данных должно быть выполнено целиком, или не выполняться вовсе. Такое действие получило название транзакции. Язык SQL является реляционно полным, т. е. совокупность операторов языка обеспечивает необходимый минимум операций реляционной алгебры (селекция, проекция, соединение и пр.). Завершая обсуждение языка SQL, еще раз подчеркнем, что это — язык запросов. На нем нельзя написать сколько-нибудь сложную прикладную программу, которая работает с базой данных. Для этой цели в современных СУБД используются языки четвертого поколения (Forth Generation Language — 4GL), обладающие как основными возможностями процедурных языков третьего поколения (3GL), таких, как Си, Паскаль, Ада, так и возможностью встроить в текст программы операторы SQL, а также средствами управления интерфейсом пользователя (меню, формами, вводом пользователя и т. д.). Сегодня язык 4GL — это один из фактических стандартов средств Разработки приложений, работающих с базами данных. Бол подробное описание одного из 4GL (Adabas/Natural) читате может найти, например, в [14]. В табл. 5.5 приводятся некото рые команды манипулирования данными других языков и си тем [14].
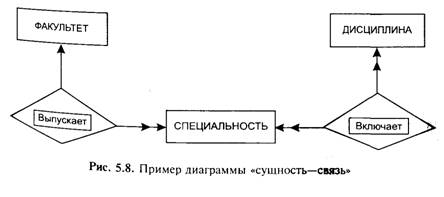
Модел «сущность—связь» Модель сущность—связь или Entity-Relationship (ER) представляет собой обобщение РМД путем разделения отношений, описывающих предметную область на две группы — сущностей и связей. Сущность (Entity) является первичным, устойчивым объектом описываемым некоторой совокупностью атрибутов. Связь (Relationship) является вторичным понятием, характе-пизуюшим взаимодействие в пространстве и времени двух или более сущностей, и также задается рядом атрибутов, среди кото-пых присутствуют идентификаторы взаимосвязанных сущностей. При проектировании БД на основе ER-моделей используют ER-диаграммы. Модель ER является удобным средством описания предметной области перед тем, как перейти к ее представлению в реляционной модели данных. Основные представления о структуре БД в рамках указанной модели заключаются в следующем: а) совокупность сущностей и связей образует концептуальную схему базы данных и отражает структуру предметной области. Элементами схемы являются типы (классы) сущностей и связей; типы состоят из экземпляров, описывающихся значениями атрибутов. На рис. 5.8 приведен пример фрагмента диаграммы «сущность — связь», описывающей учебный процесс вуза. Здесь сущностями являются ФАКУЛЬТЕТ, ДИСЦИПЛИНА, СПЕЦИАЛЬНОСТЬ (с возможными атрибутами, например наименование, продолжительность обучения, ЧИСЛО часов и пр.). Связями являются выпускает, включает (возможные атрибуты — КВАЛИФИКАЦИЯ, СЕМЕСТР ОБУЧЕНИЯ и пр.);
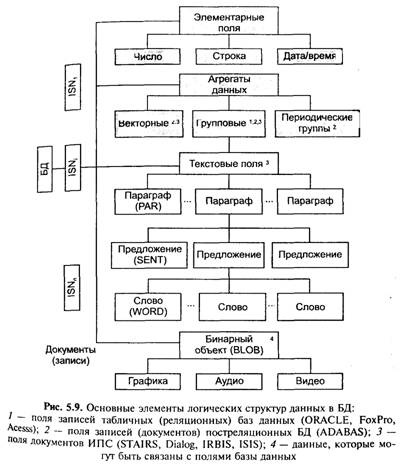
б) концептуальная схема трансформируется в логическую схему, в которой сущностям и связям соответствуют отношения или логические файлы, состоящие соответственно из экземпляров отношений и логических записей. Логическая запись является более общим образом, чем отношение (строка данных), посколыа допускает появление групповых полей (или агрегатных данных), соответствующих некоторым зависимым сущностям (или связям). В повторяющемся групповом поле экземпляр группы есть описание экземпляра сущности (связи) посредством соответствующих атрибутов. Групповые повторяющиеся поля представляет собой элемент иерархической модели данных, который при желании может применяться пользователями; в) следующий уровень — физическая реализация БД в форме файлов операционной системы ЭВМ. При этом в различных конкретных системах логическому файлу может отвечать один или более физических файлов (или наоборот). Физическая запись, как правило, включает одну или более логических записей; г) уровень представлений пользователя описывает БД в виде совокупности пользовательских подсхем, которые применяются для ввода/вывода информации. С представлениями пользователя связаны также понятия маски редактирования (преобразования данных при окончательном представлении пользователю), и кодирования/декодирования (трансляции кодов) — расширения кратких представлений данных и аббревиатур с помощью вспомогательных файлов и кодовых таблиц (по своей сути — операция соединения отношений в РМД). Структуры баз данных Рассмотрим вкратце обобщенные логическую и физическую структуры БД. Логическая структура БД (рис. 5.9) предполагает следующие уровни рассмотрения БД: • база данных (database) — включает одну или несколько подбаз (файлов, таблиц, массивов), каждая из которых состоит из агрегатов данных (записей, документов) — record. Запись идентифицируется внутренним номером (ISN — internal sequential number, BH3 — внутренний номер запис SDN — sequential document number и пр.);
• запись (документ) — совокупность разнотипных и разноструктурных данных, описывающих (относящихся к) объект реального мира, элемент предметной области АИС. Запись состоит из полей (field); • поле — именованный элементарный или составной фрагмент записи (документа), содержащий информацию об определенном аспекте (аспектах) элемента (элементов) предметной области. • элементарные (имеющие фиксированную или ограниченную длину) и не содержащие входящих в них структур данных; • составные (групповые) поля, образующиеся как агрегать элементарных и также имеющие фиксированную и ограниченную длину (реже — переменную или неопределенную, что связано с количеством вхождений элемента в агрегат) • текстовые — поля переменной (неопределенной) длины и сложной внутренней структуры (обычно это иерархическая последовательность типа раздел – подраздел –предложение – слово); • бинарные — данные, интерпретируемые как поля, однако обычно физически не входящие в состав записей БД. Необходимо отметить, что поля данного типа (BLOB — Binary Large Object) фактически являются данными, до обработки которых данная СУБД еще «не доросла» и поэтому работа с ними возлагается на пользователя (прикладные программы). В частности, в системах FoxBase и Clipper большие текстовые (так называемые MEMO) поля также не обрабатываются системой и фактически оказываются в статусе BLOB; • типы данных, определяемые пользователем. Далеко не все современные СУБД поддерживают типы данных, определенные пользователем. Пока только СУБД Ingres включает такой механизм. Эта система предоставляет программисту возможность определять собственные типы данных и операции над ними и использовать их в операторах SQL. Для определения нового типа данных необходимо написать и откомпилировать функции на языке Си, после чего собрать редактором связей некоторые модули Ingres. Отметим, что введение новых типов данных является, по сути, изменением ядра СУБД. Важно также то, что в Ingres типы данных, определяемые пользователем, могут быть параметризованными. Определение нового типа данных сводится к указанию ег имени, размера и идентификатора в глобальной структуре, описывающей типы данных. Чтобы с новым типом данных можн было использовать функции, которые реализуют стандартнь операции (сравнение, преобразование в различные форматы и т. д.), программист должен разработать их самостоятельно (интерфейс функций предопределен). Указатели на эти функции являются элементами глобальной структуры. Как только новый тип данных определен, то все операции выполняются над ним, как над данными стандартного типа. Разрешение пользователю создавать собственные типы данных по сути является одним из шагов развития реляционных СУБД в направлении объектно-реляционных систем. Поля, указанные в заштрихованных прямоугольниках (см. 5.9) относятся к фактографическим АИС, остальные — к документальным. Физическая структура БД в общем случае имеет вид, приведенный на рис. 5.10, и включает следующие компоненты: • файл (файлы) исходных (первичных) данных (текстов, бинарных данных) содержит собственно объекты, подлежащие поиску, обработке и пр.;
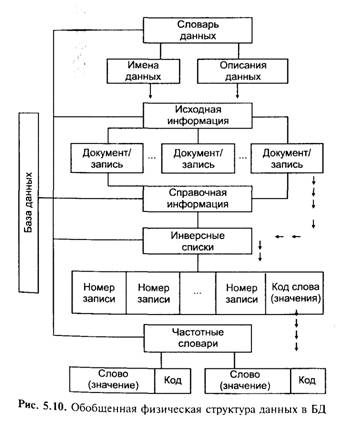
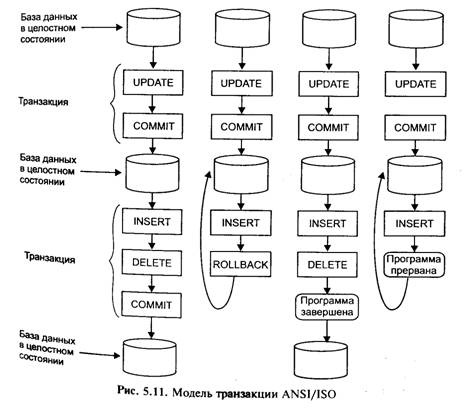
• файл (файлы) вторичной (справочной) информации (регис рационные карты, библиографические реестры и пр.) держит описания исходных элементов (объектов). Важным видом справочных файлов являются классификаторы, кодификаторы, тезаурусы, обеспечивающие полноту и компактность представления информации в БД; • индекс — файл (файлы), связывающий адрес (номер) объекта с его содержанием (значением атрибута объекта) обычно состоит из инверсного списка и частотного словаря, который облегчает составление запросов на поиск и повышает обозримость БД; • словарь данных — файл, содержащий составленное с необходимой степенью подробности описание состава БД, документов, записей, агрегатов данных, их имена, типы и структуры, способы интерпретации и обработки. Изменение содержания БД может осуществляться как в режиме конечного пользователя (диалоговый ввод или коррекция записей/документов по полям) — обычный для СУБД и редкий для АИПС, так и в режиме администратора БД (обычный для АИПС и реже для СУБД), при этом происходит массовый ввод или загрузка записей/документов. При любом виде добавления документа/записи для каждого поля осуществляется анализ, обработка и согласованное помещение документа и его фрагментов в соответствующие физические файлы БД. В конкретных случаях возможна менее полная комплектность приведенной физической схемы: • в фактографических (табличных) БД вторичный файл может являться основным накопителем информации, а текстовые и бинарные данные фигурируют в качестве необязательного приложения; • в справочно-библиографических БД текстовые данные находятся во вторичном файле, а первичный отсутствует; • в БД с полнотекстовым поиском может отсутствовать вторичный файл, а индексирование (построение частотны словарей и инверсных списков) проводится по первичному файлу (страницы или абзацы полных текстов); • может отсутствовать частотный словарь или инверсн список. Надо отметить также вариативность физической реализации и взаимосвязи лингвистического и информационного обеспечения АИС: • словарь данных может физически входить в информационные файлы (первичный или вторичный); • классификаторы, кодификаторы, тезаурусы могут быть оформлены как физическими файлами (файлами ОС), так и входить в состав БД в виде отдельных таблиц (файлов БД, массивов и пр.) на логическом уровне и т. п. Обработка транзакций Транзакция — законченный блок обращений к ресурсу (как правило, базе данных) и некоторых действий над ним, представляет собой последовательность операторов ЯМД, которая рассматривается как некоторое неделимое действие над базой данных, осмысленное с точки зрения пользователя. В то же время это логическая единица работы системы. Транзакция реализует некоторую прикладную функцию, например перевод денег с одного счета на другой в банковской системе. Традиционные транзакции характеризуются четырьмя свойствами: атомарности, согласованности, изолированности, долговечности (прочности) — ACID (Atomicity, Consistency, Isolation, Durability). Иногда традиционные транзакции называют ACID-транзакциями. Упомянутые выше свойства означают следующее: • атомарность — операции транзакции образуют неразделимый, атомарный блок с определенным началом и концом. Этот блок либо выполняется от начала до конца, либо не выполняется вообще. Если в процессе выполнения транзакции произошел сбой, происходит откат (backup, возврат) к исходному состоянию; • согласованность гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другое — транзакция не разрушает взаимной согласованности данных; • изолированность — одновременный доступ транзакций различных приложений к разделяемым ресурсам, координируется таким образом, чтобы эти транзакции не влияли друг на друга. Конкурирующие за доступ к базе данных, транзакции физически обрабатываются последовательно изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно; • долговечность — если транзакция завершена успешно, То те изменения в данных, которые были при этом произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок). Расширенные транзакции допускают формирование из ACID-транзакций иерархических структур. Если конкретная модель ослабляет некоторые из требований ACID, то речь идет об ослабленной транзакции. Возможны два варианта завершения транзакции. Если все операторы выполнены успешно, и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется. Фиксация транзакции — это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. До тех пор, пока транзакция не зафиксирована, возможно аннулирование этих изменений, восстановление базы данных в то состояние, в котором она была на момент начала транзакции. Фиксация означает, что все результаты выполнения транзакции становятся постоянными. Если в процессе выполнения транзакции случилось нечто такое, что делает невозможным ее нормальное завершение, база данных должна быть возвращена в исходное состояние. Откат транзакции — это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны в теле текущей незавершенной транзакции. Каждый оператор в транзакции выполняет свою часть работы, но для успешного завершения всей работы в целом требуется безусловное завершение их всех. Группирование операторов в транзакции сообщает СУБД, что вся эта группа должна быть выполнена как единое целое, причем такое выполнение должно поддерживаться автоматически. В стандарте ANSI/ISO SQL определены модель транзакций и функции операторов commit и rollback. Стандарт определяет, что транзакция начинается с первого SQL-оператора, инииии руемого пользователем или содержащегося в программе. Все по следующие SQL-операторы составляют тело транзакции. Транзакция завершается одним из четырех возможных способов (рис 5.П): • оператор commit означает успешное завершение транзакции; его использование делает постоянными изменения, внесенные в базу данных в рамках текущей транзакции; • оператор rollback прерывает транзакцию, отменяя изменения, сделанные в базе данных в рамках этой транзакции; новая транзакция начинается непосредственно после использования rollback; • успешное завершение программы, в которой была инициирована текущая транзакция, означает успешное завершение транзакции (как будто был использован оператор commit); • ошибочное завершение программы прерывает транзакцию (как будто был использован оператор rollback). Точки сохранения применяются, как правило, в протяженных транзакциях и позволяют разделить транзакцию на несколько небольших осмысленных фрагментов. 11ользовател может зафиксировать работу в любой точке транзакции с тем" чтобы выполнить ее откат к состоянию, соответствующему этой точке. Откат и фиксация транзакций становятся возможными благодаря журналу транзакций. Он используется следующим, образом. Операции над реляционной базой данных суть операции над строками таблиц. Следовательно, для обеспечения отката таблиц к предыдущим состояниям достаточно хранить не состояния всей таблицы, а лишь те ее строки, которые подверглись изменениям.
Важные проблемы многопользовательских СУБД связаны с организацией с помощью механизма транзакций одновременного доступа множества пользователей к одним и тем же данным. Они (проблемы) кратко могут быть сформулированы как потеря изменений, незафиксированные изменения и ряд других, более сложных проблем. Потеря изменений происходит в ситуации, когда две или несколько программ читают одни и те же данные, вносят в них какие-либо изменения и затем пытаются одновременно записать результат по прежнему месту. При этом в базе данных могут быть сохранены изменения, выполненные только одной программой — другие изменения будут потеряны. Проблема незафиксированных изменений возникает в случае, когда в процессе выполнения транзакции одной программой в данные были внесены изменения, которые тут же прочитала другая программа, однако затем в первой программе транзакция была прервана оператором rollback. Может оказаться, что вторая программа прочитала неверные, незафиксированные данные. Очевидно, что необходима определенная дисциплина обработки транзакций, позволяющая устранить проблемы, описанные выше, и им подобные. Такая дисциплина существует и опирается на следующие правила: • в процессе выполнения транзакции пользователь (программа) «видит» только согласованные состояния базы данных. Пользователь никогда не может получить доступ к неза фиксированным изменениям в данных, достигнутым в результате действий другого пользователя (программы); • если две транзакции, А и В, выполняются параллельно, то СУБД полагает, что результат будет такой же, как если бы: – транзакция А выполнялась первой, а за ней была выполнена транзакция В; – транзакция В выполнялась первой, а за ней была выполнена транзакция А. Эта дисциплина известна как сериализация транзакций. Фактически она гарантирует, что каждый пользователь (программа), обращающийся к базе данных, работает с ней так, как будто не существует других пользователей, одновременно с ним обращающихся к тем же данным. Для практической реализации этой дисциплины большинство СУБД используют механизм блокировок. Механизм блокировок разрешает проблемы, связанные с доступом нескольких пользователей к одним и тем же данным. Однако его применение связано с существенным замедлением обработки транзакций, вызванным необходимостью ожидания, когда освободятся данные, захваченные конкурирующей транзакцией. Можно попытаться минимизировать вызванные этим задержки, локализуя фрагменты данных, захватываемые транзакцией. Так, СУБД может блокировать всю базу данных целиком (очевидно, что это неприемлемый вариант), таблицу базы данных, часть таблицы, отдельную строку (уровни блокировки). Современные СУБД используют, как правило, блокировки на уровне частей таблиц (страниц), записей, полей (атрибутов). На практике могут происходить взаимоблокировки нескольких транзакций. Для их предотвращения СУБД периодически проверяет блокировки, установленные активными транзакциями. Если СУБД обнаруживает взаимоблокировки, она выбирает одну из транзакций, вызвавшую ситуацию взаимоблокировки, и прерывает ее. Это освобождает данные для внесения изменений конкурирующей транзакцией, разрешая тупиковую ситуацию. В современной литературе часто встречается термин OLTP (Оn - Line Transaction Processing), который обычно переводят как «оперативная обработка транзакций», т. е. выполнение транзакции в режиме реального времени. Система OLTP обязана учитывать жесткие временные требования, следующие из специфики прикладной области. Например, процедура покупки и оформления авиабилета должна происходить быстро и не задерживать очередь. Система, регистрирующая продажи билетов должна обрабатывать одновременно несколько сотен запросов (транзакций), поступающих от множества продавцов авиабилетов. Требования по скорости обработки запроса могут бьггк очень жесткими, однако вызваны они требованиями реальной жизни. Если говорить о прикладных областях OLTP, то это прежде всего, центры кредитных карточек, системы резервирования авиабилетов и мест в отелях, телекоммуникационные системы и т. д.
|
||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 184; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.94.221 (0.02 с.) |