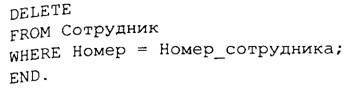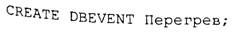Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Эволюция серверов баз данныхСодержание книги
Поиск на нашем сайте В период создания первых СУБД технология «клиент—сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия такого типа, в современных же системах он жизненно необходим. Первое время доминировала модель, в которой управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе (рис. 7.2, а). Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала структуре «один к одному» (рис. 7.2, б), т. е. сервер обслуживал запросы ровно одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу — шаг, позволяющий, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети (рис. 7.2, в). Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы. Проблемы, возникающие в модели «один к одному», решаются в архитектуре систем с выделенным сервером, способным обрабатывать запросы от многих клиентов. Сервер обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис. 7.2, г). Логически каждый клиент связан с сервером отдельной нитью (thread) или потоком, по которому пересылаются запросы.
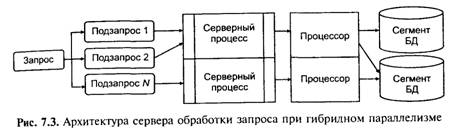
Такая архитектура получила название многопотоковой (multi-threaded). Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей. С другой стороны, возможность взаимодействия с одним сервером многих клиентов позволяет в полной степени использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что сильно уменьшав потребности в памяти и общее число процессов операционную системы, например, системой с архитектурой «один к одному» будет создано 50 копий процессов СУБД для 50 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один сервер. Однако такое решение привносит новую проблему. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три. В некоторых системах эта проблема решается заменой выделенного сервера на диспетчер или виртуальны й сервер (virtual server) (рис. 7.2, д), который теряет право монопольно распоряжаться данными, выполняя только функции диспетчеризации запросов к актуальным серверам. Таким образом, в архитектуру системы добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки (load balancing) и ограничивает возможности управления взаимодействием «клиент—сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, по- вторых, серверы становятся равноправными — невозможно устанавливать приоритеты для обслуживания запросов. Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если два эти условия выполнены, то есть основание говорить о многопотоковой архитектуре с несколькими серверами (multi-threaded, multi-server architecture), представленной на рис. 7.2, е. Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности серверной машины, Может быть достигнуто двумя путями: • снижением суммарного расхода памяти и вычислительных ресурсов за счет буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур; • распараллеливанием процесса обработки запроса — использованием разных процессоров для параллельной обработки изолированных подзапросов и/или для одновременного обращения к частям базы данных, размещенным отдельных физических носителях. Таким образом, типология распределенных баз данных определяется схемой распределения данных между узлами и схемой распараллеливания процессов обработки запросов. Рассмотрим архитектуры, реализующие следующие модели совместной обработки клиентских запросов. Как уже отмечалось, для однопроцессорных архитектур возможны схемы следующих типов: • однопотоковые архитектуры — «один к одному», когда для обслуживания каждого запроса запускается отдельный серверный процесс. В этом случае, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будет запущен отдельный процесс, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы; • многопотоковые архитектуры, когда обработку всех запросов выполняет один серверный процесс (использующий один процессор), взаимодействующий со всеми клиентами и монопольно управляющий ресурсами. Либо в том случае, когда для работы СУБД используются многопроцессорные платформы, обслуживание запросов может быть физически распределено для параллельной обработки между процессорами. В общем случае для повышения оперативности за счет распараллеливания процесса обработки отдельного клиентского запроса в мультисерверной архитектуре можно использовать следующие подходы: • размещение хранимых данных БД на нескольких физических носителях (сегментирование базы). Для обработки запроса в этом случае запускаются несколько серверных процессов (использующих обычно отдельные процессоры), каждый из которых независимо от других выполняет одинаковую последовательность действий, определяемую существом запроса, но с данными, принадлежащими разным сегментам базы. Полученные таким образом результаты объединяются и передаются клиенту. Такой тип распараллеливания называют моделью горизонтального параллелизма; • запрос обрабатывается по конвейерной технологии. Для этого запрос разбивается на взаимосвязанные по результатам подзапросы, каждый из которых может быть обслужен отдельным серверным процессом независимо от обработки других подзапросов. Получаемые результаты объединяются согласно схеме декомпозиции запроса и передаются клиенту. Такой тип распараллеливания называют моделью вертикального параллелизма. Схема обработки клиентского запроса, построенная с использованием обеих моделей параллелизма (гибридная модель), приведена на рис. 7.3.
Отдельно необходимо упомянуть «интеграционный» подход — использование мультибазовой СУБД, которая размещается над существующими системами баз данных и файловыми системами и позволяет пользователям рассматривать совокупность баз данных (и, возможно, под управлением разнотипных СУБД) как единую базу. Мультибазовая СУБД поддерживает глобальную схему, на основании которой пользователи могут формировать запросы и модифицировать данные. Мультибазовая СУБД работает только с глобальной схемой, тогда как локальные СУБД могут использовать собственные схемы представления и обработки «своих» данных. Активный сервер В распределенных БД возникают следующие проблемы: • база данных в любой момент времени должна правильно отражать состояние предметной области —данные должны быть взаимно непротиворечивыми. Пусть, например, база данных Кадры хранит сведения о рядовых сотрудниках, отделах, в которых они работают, и их руководителях. Нужно учесть следующие правила: каждый сотрудник должен быть подчинен реальному руководителю; если руководитель уволился, то все его сотрудники переходят в подчинение другому, а отдел реорганизуется; во главе каждого отдела должен стоять реальный руководитель; если отдел сокращен, то его руководитель переводится в резерв на выдвижение и т. д.; • база данных должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Завод может нормально работать только в том случае, если на складе имеется достаточный запас деталей определенной номенклатуры. Следовательно как только количество деталей некоторого типа станет меньше минимально допустимого, завод должен докупить их в нужном количестве; • необходим постоянный контроль за состоянием базы данных, отслеживание всех изменений и адекватная реакция на них. Например, в автоматизированной системе управления производством датчики контролируют температуру инструмента; она периодически передается в базу данных и там сохраняется; как только температура инструмента превышает максимально допустимое значение, он отключается; • необходимо, чтобы возникновение некоторой ситуации в базе данных четко и оперативно влияло на ход выполнения прикладной программы. Многие программы требуют оперативного оповещения обо всех происходящих в базе данных изменениях. Так, в системах автоматизированного управления производством необходимо моментально уведомлять программы о любых изменениях параметров технологических процессов, когда последние хранятся в базе данных. Почтовая служба требует оперативного уведомления получателя, как только получено новое сообщение; • важная функция — контроль типов данных. В базе данных каждый столбец в любой таблице содержит данные некоторых типов. Тип данных определяется при создании таблицы. Каждому столбцу присваивается один из стандартных типов данных, разрешенных в СУБД. Концепция активного сервера опирается на следующие принципы: • процедуры базы данных; • правила (триггеры); • события в базе данных. Процедуры базы данных. Вразличных СУБД они носят название хранимых (stored), присоединенных, разделяемых и т. д. Ниже используется терминология, принятая в СУБД Ingres. Использование процедур базы данных преследует четыре цели: • обеспечивается новый независимый уровень централизованного контроля доступа к данным, осуществляемый администратором базы данных; • одна и та же процедура может использоваться несколькими прикладными программами — это позволяет существенно сократить время написания программ за счет оформления их общих частей в виде процедур базы данных. Процедура компилируется и помещается в базу данных, становясь доступной для многократных вызовов. Так как план ее выполнения определяется единожды при компиляции, то при последующих вызовах процедуры фаза оптимизации пропускается, что существенно экономит вычислительные ресурсы системы; • значительное снижение трафика сети в системах с архитектурой «клиент—сервер». Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры. В процедуре, как правило, концентрируются повторяющиеся фрагменты из нескольких прикладных программ (рис. 7.4). Если бы эти фрагменты остались частью программы, они загружали бы сеть посылкой полных SQL-запросов; • процедуры базы данных в сочетании с правилами, о которых речь пойдет ниже, предоставляют администратору мощные средства поддержки целостности базы данных. Процедура обычно хранится непосредственно в базе данных и контролируется ее администратором. Она имеет параметры и возвращает значение. Процедура базы данных создается оператором CREATE PROCEDURE (СОЗДАТЬ ПРОЦЕДУРУ) И содержит определения переменных, операторы SQL (например, SELECT, INSERT), операторы проверки условий (if/then/else), операторы цикла (for, while), а также некоторые другие.
Пусть, например, необходимо разработать процедуру, которая переводила бы рядового сотрудника в резерв на выдвижение на руководящую должность. Процедура Назначение перемещает строки из таблицы Сотрудник, которая содержит сведения о сотрудниках, в таблицу Резерв для всех сотрудников с указанным номером. Номер сотрудника представляет собой целое число (тип integer), который не может иметь пустое значение, является параметром процедуры и передается ей при вызове из прикладной программы оператором execute procedure (выполнить процедуру):
Правила Механизм правил (триггеров) позволяет программировать обработку ситуаций, возникающих при любых изменениях в базе данных. Правило придается таблице базы данных и применяется при выполнении над таблицей операций включения, удаления или обновления строк. Одна из целей механизма правил — отражение некоторых внешних правил деятельности организации. Пусть, например, в базе данных Склад содержится таблица Деталь, хранящая сведения о наличии деталей на складе завода. Одно из правил деятельности завода заключается в том, что недопустима ситуация, когда на складе число деталей любого типа становится меньше некоторого числа (например, 1000). Это требование может быть описано правилом Проверить_деталь. Оно применяется в случае обновления столбца количество таблицы Деталь: если новое значение в столбце меньше 1000, то выполняется процедура Заказать_деталь. В качестве параметров ей передаются номер детали данного типа и остаток (число деталей на складе):
Таким образом, если возникает ситуация, когда на складе количество деталей какого-либо типа становиться меньше требуемого, запускается процедура базы данных, которая заказывает недостающее количество деталей этого типа. Заказ сводится к посылке письма (например, по электронной почте), на завод или в цех, который изготавливает данные детали. Все это происходит автоматически, без вмешательства пользователя. Важнейшая цель механизма правил — обеспечение целостности базы данных. Один из аспектов целостности — целостность по ссылкам (referential integrity) — относится к связи двух таблиц между собой. Допустим, таблица Руководитель содержит сведения о начальниках, а таблица Сотрудник — о сотрудниках некоторой организации (см. рис. 5.6). СтолбецНомер_руководителя является внешним ключом таблицы Сотрудник и ссылкой на таблицу Руководитель. Для обеспечения целостности ссылок должны быть учтены два требования. Во-первых, если в таблицу Сотрудник добавляется новая строка, значение столбца номер руководителя должно быть взято из множества значений столбца Номер таблицы Руководитель (сотрудник может быть подчинен только реальному руководителю). Во-вторых, при удалении любой строки из таблицы Руководитель в таблице Сотрудник не должно остаться ни одной строки, в которой в столбце Номер_руководителя было бы значение, тождественное значению столбца Номер в удаляемой строке (все сотрудники, если их руководитель уволился, должны перейти в подчинение другому). Для того чтобы учесть эти требования, должны быть созданы правила, их реализующие. Первое правило Добавить_сотрудника срабатывает при включении строки в таблицу Сотрудник; его применение заключается в вызове процедуры Проверить_руководителей, устанавливающей, существует ли среди множества значений столбца Номер таблицы Руководитель значение, тождественное значению поля Номер_руководителя добавляемой строки. Если это не так, процедура должна ее отвергнуть. Второе правило применяется при попытке удалить строку из таблицы Руководитель; оно состоит в вызове процедуры, которая сравнивает значения в столбце Номер_руководителя таблицы Сотрудник со значением поля Номер в удаляемой строке. В случае совпадения значение в столбце Номер_руководителя обновляется.
Механизм правил позволяет реализовать и более общие ограничения целостности. Пусть, например, таблица Сотрудник содержит информацию о сотрудниках, в том числе имя и название отдела, в котором они работают. Таблица Отдел хранит для каждого отдела количество работающих в нем сотрудников в столбце Количество_сотрудников. Одно из ограничений целостности заключается в том, что это количество должно совпадать с числом строк для данного отдела в таблице Сотрудник. Чтобы это ограничение, можно использовать правило Добавить_сотрудника, которое применяется при включении строки в таблицу Сотрудник и запускает процедуру Новый_сотрудник. Она, в свою очередь, обновляет значение столбца Количество_сотрудников, увеличивая его на единицу. Параметр процедуры — название отдела.
Разумеется, на практике с помощью механизма правил реализуются более сложные и изощренные ограничения целостности. Аналогом правил послужили триггеры (triggers), которые впервые появились в СУБД Sybase и впоследствии были реализованы в том или ином виде и под тем или иным названием в большинстве многопользовательских СУБД. События в базе данных. Механизм событий в базе данных (database events) позволяет прикладным программам и серверу базы данных уведомлять другие программы о наступлении в базе данных определенного события и тем самым синхронизировать их работу. Операторы языка SQL, обеспечивающие уведомление, часто называют сигнализаторами событий в базе данных (database event alerters). Функции управления событиями целиком ложатся на сервер базы данных. Рисунок 7.5 иллюстрирует один из примеров использования механизма событий: различные прикладные программы и процедуры вызывают события в базе данных, а сервер оповещает монитор прикладных программ об их наступлении. Реакция монитора на события заключается в выполнении действий, которые предусмотрел его разработчик. Механизм событий используется следующим образом. Вначале в базе данных для каждого события создается флажок, состояние которого будет оповещать прикладные программы о том, что некоторое событие имело место (оператор create dbevent - создать событие). Далее, во все прикладные программы, на ход выполнения которых может повлиять это событие, включается оператор register dbevent (зарегистрировать событие), который оповещает сервер базы данных, что программа заинтересована в получении сообщения о наступлении события.
Теперь любая прикладная программа или процедура базы данных может вызвать событие оператором RAISE dbevent (вызвать событие). Как только событие произошло, каждая зарегистрированная программа может получить его, для чего она должна запросить очередное сообщение из очереди событий (оператор get dbevent — получить событие) и запросить информацию о событии, в частности его имя (оператор SQLINQUIRE_SQL). Следующий пример иллюстрирует обработку всех событии из очереди:
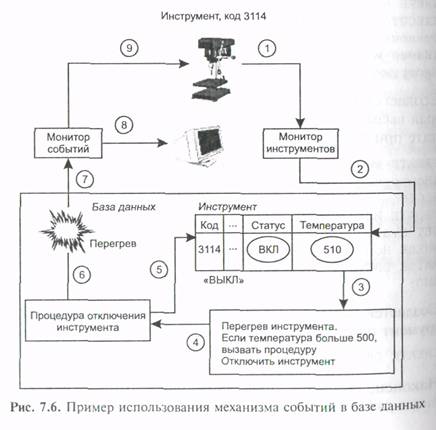
Рассмотрим пример из производственной системы, иллюстрирующий использование механизма событий в базе данных совместно с правилами и процедурами. События используются для определения ситуации, когда рабочий инструмент нагревается до температуры свыше допустимой и должен быть отключен. Создается правило, которое применяется всякий раз, когда новое значение температуры инструмента заносится в таблицу Инструмент. Как только оно превосходит 500 градусов, правило вызывает процедуру Отключить__инструмент.
Создается процедура базы данных Отключить_инструмент, которая вызывает событие Перегрев; она будет выполнена в результате применения правила, определенного на шаге 1.
Создается событие Перегрев, которое будет вызвано, когда инструмент перегреется:
Наконец создается прикладная программа Монитор_Инструментов, которая следит за состоянием инструментов. Она регистрируется сервером в качестве получателя события Перегрев с помощью оператора register dbevent. Если событие произошло, программа посылает сообщение пользователю и сигнал необходимый для отключения инструмента:
Описанные выше конструкции в совокупности определяют логику работы (рис. 7.6).
Прикладная программа Монитор_Инструментов периодически регистрирует с помощью датчиков текущие значения параметров множества различных инструментов и заносит в таблицу Инструмент новое значение температуры для данного инструмента. Всякий раз, когда это происходит, т. е. обновляется значение столбце Температура таблицы Инструмент, применяется правило Перегрев_инструмента. Применение правила состоит в проверке нового значения температуры. Если оно превышает максимально допустимое, то запускается процедура Отключить_инструмент. В том случае, когда используются традиционные методы опроса БД, логика работы была бы совершенно иной. Пришлось бы разработать дополнительную программу, которая периодически выполняла бы операцию выборки из таблицы Инструмент по критерию Температура > 500. Это очень сильно сказалось бы на эффективности, поскольку операция select является ресурсоемкой. Разумеется, пример приведен лишь для иллюстрации схемы срабатывания механизма «правило — процедура — событие».
|
||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 244; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.3 (0.015 с.) |