Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
С уровня «строка» до уровня «страница». Формирование электронного документаСодержание книги
Поиск на нашем сайте
Итак, все слова текстового блока распознаны. Пользуясь информацией, полученной при анализе структуры документа, ABBYY FineReader расставляет слова по местам. Из образующихся при этом строк формируются текстовые блоки, размещаемые на странице в точном соответствии с оригиналом. Когда формирование документа завершено, система обращается к пользователю за подтверждением — правильно ли распознана страница (рис. 4.9)? Никакое программное обеспечение оптического распознавания символов никогда не распознает 100 % сканированных символов. В большинстве случаев количество допускаемых FineReader ошибок не превышает 1—3 на страницу при среднем качестве оригинального документа. Исправить пару специально подсвеченных ошибок, конечно, существенно проще и быстрее, чем перепечатывать и форматировать весь документ целиком. В результате пользователь получает точную электронную копию страницы; при необходимости ее можно отредактировать либо сохранить «как есть». Специальный модуль программы может экспортировать результат практически в любой из современных форматов электронных документов. Для сохранения текста удобен формат Microsoft Word, а если исходный документ представлял собой таблицу, то вполне резонно сохранить электронную копию в формате Microsoft Excel. Если же статью предполагается опубликовать в сети Интернет, можно использовать формат HTML или PDF.
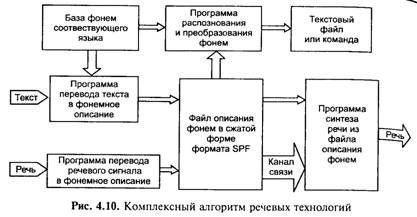
Системы распознавания речи Теоретически машинное распознавание речи, т. е. ее автоматическое представление в виде текста, является крайней степенью сжатия речевого сигнала, Процесс распознавания речи (STT — speech-to-text) в последние годы сделал гигантский скачок вперед. В наибольшей мере его стимулирует отнюдь не желание разработчиков создать пользовательские суперудобства, а существование специфических областей компьютеризации, где голосовые команды являются более приемлемым или даже единственно возможным решением. К ним относятся телефонный доступ к автоматическим справочным системам, управление удаленным компьютером или мобильным портативным устройством, осуществляемое во время движения. Принципы распознавания речи Системы распознавания речи обычно состоят из двух компонент, которые могут быть выделены в блоки или в подпрограммы — акустической и лингвистической. Лингвистическая часть может включать в себя фонетическую, фонологическую, морфологическую, синтаксическую и семантическую модели языка. Акустическая модель отвечает за представление речевого сигнала. Лингвистическая модель интерпретирует информацию, получаемую от акустической модели, и отвечает за представление результата распознавания потребителю. Акустическая модель. Существуют два подхода к построению акустической модели: изобретательский и бионический. Оба подхода имеют свои достоинства и недостатки. Первый базируется на результатах поиска механизма функционирования акустической модели. При втором подходе разработчик пытается понять и смоделировать работу естественных систем. Лингвистическая модель. Лингвистический блок подразделяется на следующие слои (уровни); фонетический, фонологический, морфологический, лексический, синтаксический, семантический. Все уровни содержат априорную информацию о структуре естественного языка, а, как известно, любая априорная информация об интересующем предмете увеличивает шансы принятия верного решения. Поскольку естественный язык несет весьма сильно структурированную информацию, для каждого естественного языка может потребоваться своя уникальная лингвистическая модель (отсюда трудности русификации сложных систем распознавания речи зарубежной разработки). В соответствии с данной моделью на первом (фонетическом) уровне производится преобразование входного (для лингвистического блока) представления речи в последовательность фонем, как наименьших единиц языка. Считается, что в реальном речевом сигнале можно обнаружить лишь аллофоны — варианты фонем, зависящие от звукового окружения. На следующем (фонологическом) уровне накладываются ограничения на комбинаторику фонем (аллофонов) — не все сочетания фонем (аллофонов) встречаются, а те, что встречаются, имеют различную вероятность появления, зависящую еще и от окружения. Для описания этой ситуации используется математический аппарат цепей Маркова. Далее, на морфологическом уровне оперируют со слогопо-добными единицами речи более высокого уровня, чем фонема. Иногда они называются морфемами. Они накладывают ограничение уже на структуру слова, подчиняясь закономерностям моделируемого естественного языка. Лексический уровень охватывает слова и словоформы того или иного естественного языка, т. е. словарь языка, также внося важную априорную информацию о том, какие слова возможны для данного естественного языка. Семантика устанавливает соотношения между объектами действительности и словами, их обозначающими. Она является высшим уровнем языка. При помощи семантических отношений интеллект человека производит как бы сжатие речевого сообщения в систему образов, понятий, представляющих суть речевого сообщения. Российская компания «ИстраСофт» известна пакетом для обучения английскому языку с визуальным контролем произношения «Профессор Хиггинс». Развивая «Хиггинса», сотрудники «ИстраСофт» совершили технологический прорыв, значение которого трудно переоценить: они научились членить слова на элементарные сегменты, соответствующие звукам речи, независимо от диктора и от языка (Существующие системы распознавания Речи не производят сегментации, наименьшей единицей для них является слово.) Демонстрация новой технологии выглядит пока не очень эффектно: это всего-навсего упаковка и распаковка звуковых файлов с записью речи — правда, с высокими коэффициентами сжатия. Если файл был сжат сильно, то после распаковки в нем появляются отчетливо слышные границы между сегментами; использованию программы по прямому назначению они, конечно, мешают, но специалисту позволяют убедиться в правильности членения. В соответствии с этим решение задачи речевых технологий можно представить в виде схемы рис. 4.10. В основе алгоритма лежит выделение фонем из потока слитной речи в режиме реального времени, их кодирование и последующее восстановление, однако у разработчиков нет единого мнения о том, что считать фонемой при машинной обработке речи. Способ, предложенный фирмой «ИстраСофт», допускает сжатие речи в 200 раз, причем при сжатии менее чем в 40 раз качество сигнала практически не падает.
Чтобы создать основанную на новой технологии систему распознавания, необходимо «привязать» сегментацию к конкретному языку с помощью двух словарей — «звукового», сопоставляющего реальным звукам речи определенные фонемы, т. е. смыслоразличительные единицы (на слух мы, как правило, воспринимаем именно фонемы родного языка, не замечая различий между их вариантами, обусловленными, например, позицией), и «фонетико-орфографического», который будет переводить фонемную запись в письменную. Принципиально ничего сложного здесь нет: это вполне рутинная, умеренно трудоемкая техническая задача. Интеллектуальная обработка речи на уровне фонем перспективна не только как способ сжатия, но и как шаг на пути к созданию нового поколения систем распознавания речи. Практическая реализация. Многие научные центры, в том числе и в нашей стране, брались за решение этой проблемы (фундаментальные исследования теории языка, которые велись в 1970-х гг. в СССР, легли в основу многих современных продуктов), но первый серьезный прорыв в области речевых технологий удалось сделать только в 1986 г. в Defense Advanced Research Project Agency (DARPA) — Агентстве перспективных исследований Министерства обороны США. Успех связан с тем, что ученые решили уменьшить число фонетических структур, предлагаемых распознающему устройству. Для реализации этой задачи они применили так называемую крытую марковскую модель» (Hidden Markov Model — НММ), основанную на свойстве марковской цепи генерировать последовательность определенных детерминированных символов при переходах между некоторыми состояниями вероятностного характера (в марковском процессе параметры системы зависят только от предыдущего состояния и «не помнят» более глубокой предыстории) Имея последовательность символов, сгенерированную марковской моделью, можно однозначно восстановить породившую ее последовательность состояний, но лишь только при том условии что каждый символ соответствует одному состоянию. В процессе цифровой обработки речевой сигнал подвергается сначала логарифмическому, а затем обратному преобразованию Фурье, в результате чего отыскивается с десяток первых коэффициентов, несущих наиболее существенную информацию об огибающей спектральной характеристики сигнала. Собственно, современные развитые коммерческие программы распознавания речи и отличаются именно способом реализации механизма выбора из встроенной (или созданной пользователем) базы данных наиболее вероятного набора фонем (минимально значимых элементов, из которых состоит слово). На первом этапе компьютер записывает звук речи в виде цифровой аудиопоследовательности и делит ее на фрагменты длительностью несколько миллисекунд. Программа сравнивает эти аудиофрагменты с записанными в память речевыми образцами. Качество базы данных образцов является наиболее важным условием для безошибочного распознавания речи. Она содержит фрагменты речи различных людей с разными особенностями произношения, такими, как снижение звука, диалект, выделение слогов и произношение. Эта часть системы распознавания речи называется системой, не зависящей от говорящего. Систему, не зависящую от говорящего, дополняет систем распознавания говорящего. В основе последней лежит понятие фонемы — наименьшей акустической единицы языка. В процессе тренировки программное обеспечение распознает наиболее важные признаки произношения пользователем фонем и записывает полученные данные в виде профиля говорящего. Очень важно, чтобы в дальнейшем во время диктовки пользователь по возможности точно выдерживал мелодию реи и произношение. В системе распознавания говорящего при определении «сомнительных слов» используется тот факт, что после определенного слова могут следовать (и имеют при этом смысл) лишь не многие конкретные слова. Владельцам мобильных телефонов этот способ знаком по SMS-сообщениям, при наборе которых нужное слово предлагается автоматически.
|
||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 86; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.249.104 (0.01 с.) |