Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Перспективы систем распознавания речиСодержание книги
Поиск на нашем сайте
Важная задача, которая стоит перед создателями речевых технологий, — выработка единого стандарта на API-интерфейс (Applications Programming Interface), который должен связывать приложения и обеспечивать своевременную передачу управляющих функций. Такой стандарт должен не только позволять строить приложения на базе какой-либо распространенной операционной системы, имеющей соответствующие встроенные функции (первой такой ОС стала OS/2 Warp), но и обеспечивать переносимость систем распознавания речи на другие ОС. ПО для распознавания слитной речи, как правило, не только снабжается собственными текстовыми редакторами, но и способно встраиваться в популярные программы, среди которых MS Word, Excel, Lotus Smart Suite Millennium Edition (Lotus Development) и Word Perfect Suite (Corel). С другой стороны, производители офисных программ стали включать в состав своего ПО системы распознавания речи, как правило, от IBM (Smart Suite), Dragon Dictate (Word Perfect Suite) или Lernout&Hauspie. Современные программы распознавания речи для ПК позволяют диктовать в обычной разговорной манере. Так называемая дискретная надиктовка с частыми остановками и паузами между словами осталась в прошлом. Однако непрерывный процесс расставания речи, дающий точность до 95 % в оптимальных условиях все-таки дает пять неправильных букв на 100 знаков. Около 200 ошибок на странице формата А4 — слишком много для профессиональной работы. Несмотря на все достижения последних лет, средства для распознавания слитной речи все же допускают большое количество ошибок, нуждаются в длительной настройке, требовательны к аппаратной части и к квалификации пользователя и отказываются работать в зашумленных помещениях (а это важно как для шумных офисов, так и для мобильных систем и эксплуатации в условиях телефонной связи). Известно, что спонтанная речь произносится со средней скоростью 2,5 слов в секунду, профессиональная машинопись — 2 слова в секунду, непрофессиональная — 0,4. Таким образом, на первый взгляд, речевой ввод имеет значительное превосходство по производительности. Однако оценка средней скорости диктовки в реальных условиях снижается до 0,5 слова в секунду в связи с необходимостью четкого произнесения слов при речевом вводе и достаточно высоким процентом ошибок распознавания, нуждающихся в корректировке.
Речевой интерфейс естественен для человека и обеспечивает дополнительное удобство при наборе текстов. Однако даже профессионального диктора может не обрадовать перспектива в течение нескольких часов диктовать малопонятливому и немому компьютеру. Кроме того, имеющийся опыт эксплуатации подобных систем свидетельствует о высокой вероятности заболевания голосовых связок операторов, что связано с неизбежной при диктовке компьютеру монотонностью речи. Часто к достоинствам речевого ввода текста относят отсутствие необходимости в предварительном обучении. Однако одно из самых слабых мест современных систем распознавания речи, — чувствительность к четкости произношения, — приводит к потере этого, казалось бы, очевидного преимущества. Печатать на клавиатуре оператор учится в среднем 1—2 месяца. Постановка правильного произношения может занять несколько лет. Кроме того, дополнительное напряжение, следствие сознательных и подсознательных усилий по достижению более высокой распознаваемости, совсем не способствует сохранению нормального режима работы речевого аппарата оператора и значительно увеличивает риск появления специфических заболеваний. Существует и еще одно неприятное ограничение применимости — оператор, взаимодействующий с компьютером через речевой интерфейс, вынужден работать в звукоизолированном отдельном помещении либо пользоваться звукоизолирующим шлемом. Иначе он будет мешать работе своих соседей по офису, которые, в свою очередь, создавая дополнительный шумовой фон, будут значительно затруднять работу речевого распознавателя. Таким образом, речевой интерфейс вступает в явное противоречие с современной организационной структурой предприятий, ориентированных на коллективный труд. Ситуация несколько смягчается с развитием удаленных форм трудовой деятельности, однако еще достаточно долго самая естественная для человека производительная и потенциально массовая форма пользовательского интерфейса обречена на узкий круг применения. Ограничения применимости систем распознавания речи в рамках наиболее популярных традиционных приложений заставляют сделать вывод о необходимости поиска потенциально перспективных для внедрения речевого интерфейса приложений за пределами традиционной офисной сферы, что подтверждается коммерческими успехами узкоспециализированных речевых систем.
Парадоксально, но самый успешный на сегодня проект коммерческого применения распознавания речи — телефонная сеть фирмы АТТ. Клиент может запросить одну из пяти категорий услуг, используя любые слова. Он говорит до тех пор, пока в его высказывании встретится одно из пяти ключевых слов. Эта система в настоящее время обслуживает около миллиарда звонков в год. Системы генерации речи Говоря о речевом интерфейсе, часто делают упор на распознавание речи, забывая о другой его стороне — речевом синтезе. Заглавную роль в этом перекосе сыграло быстрое развитие систем, ориентированных на события в значительной степени подавляющих отношение к компьютеру как активной стороне диалога. Еще относительно недавно подсистемы распознавания и синтеза речи рассматривались как части единого комплекса речевого интерфейса. Обратная распознаванию задача — синтез речи, или Text-to-Speech (TTS), — столь же проста в первом приближении и по-своему не менее сложна по мере достижения вершин. Известно, что синтезированная речь воспринимается человеком хуже, чем живая, причем это особенно заметно при передаче по каналу телефонной связи, т. е. как раз в тех условиях, в которых было бы наиболее заманчиво ее использовать. Тем не менее эксперты отмечают улучшение звучания синтезированной английской речи. В интеллектуальных телефонных системах, таких, как IVR (interactive voice responce) и центры телефонного обслуживания, технологии TTS начинают теснить традиционные наборы записываемых заранее слов и реплик — прежде всего благодаря своей гибкости, простоте переналадки и сокращению требований к объему памяти. Качество речи прямо пропорционально размеру синтезатора и объему потребляемых им ресурсов системы (загрузка процессора, выделение памяти и т. п.) Для характеристики качества речи обычно используют такие понятия, как естественность звучания, фонетическая разборчивость, комфортность восприятия и время привыкания. Естественность звучания характеризует то, насколько близок синтезированный звук к человеческой речи. Пока еще не существует синтезатора, прослушав который, человек не мог бы указать, что это неестественный звук. Однако уровень синтезаторов растет год от года, и неестественность их звучания уже не является сильной помехой восприятию информации. Первые же синтезаторы отличались такими нежелательными эффектами, как металлический призвук, отсутствие интонационного деления Фрагмента речи, резкость звучания или наоборот — слишком затянутые гласные звуки. Фонетическая разборчивость характеризует, насколько слушателю легко или трудно разобрать фонемы, произносимые синтезатором. Здесь надо понимать, что неестественная с металлическим призвуком «речь робота», может обладать высокой фонической разборчивостью, т. е. слушатель с легкостью может фонемы (слоги) произносимых слов. В то же время в с естественной речи разборчивость может быть невысокой (представьте себе бубнящего человека — речь на сто процентов естественная, а ничего не понять). Так происходит потому, что для придания естественности звучания синтезируемая речь проходит дополнительную фильтрацию, в результате чего получает дополнительные обертона (их богатство во многом и определяет близость синтезированной речи к человеческой). Степень фильтрации не всегда адекватно подбирается синтезатором и это ухудшает фонетическую разборчивость.
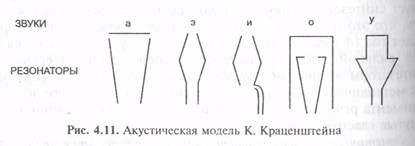
Комфортность восприятия и время привыкания показывают субъективную оценку слушателем качества синтезируемой речи Несмотря на свою субъективность, с точки зрения пользователя это самые главные критерии, по которым оценивается работа синтезатора. Долгое прослушивание синтезированной речи не должно вызывать чрезмерного утомления, а время привыкания должно быть достаточно коротким, чтобы обеспечить легкий переход от одного синтезатора к другому. История проблемы В 1779 г. русский профессор Кристиан Краценштейн (иногда упоминается в источниках как Кристиан Готтлиб) построил акустическую модель, позволяющую создавать гласные звуки, используя различные геометрические формы резонаторов, как это показано на рис. 4.11.
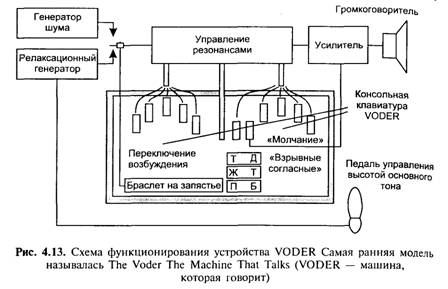
При этом использовался аддитивный синтез (см. гл. 3), как в обычных органах (напомним, что один из регистров органа так и называется — vox humanum — голос человеческий) -В 1791 г. Вольфганг фон Кемпелен (Volfgang von Kempelen) представил акустико-механическую говорящую машину, которая воспроизводила определенные звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным правлением. Затем это изобретение было улучшено ученым Чарльзом Уитстоуном (Charles Wheatstone), и уже могло воспроизводить гласные и большинство согласных звуков. В 1846 г. Джезеф Фабер представил свой говорящий орган, в котором была реализована попытка синтезирования не только речи, но и пения. В конце XVIII в. знаменитый ученый Александр Белл (Alexander Graham Bell) создал собственную «говорящую» механическую модель, очень схожую с конструкцией Уитстоуна. Начиная с 1920 г. наступила эра электрических инструментов, при этом основным видом синтеза оставался аддитивный. Ключевой датой в развитии вокодеров является 1939 г. Именно в этом году ученый-изобретатель Хомер Дадли (Homer. W. Dudley) из Bell Laboratories представил устройство Parallel Bandpass Vocoder, над разработкой которого он трудился три года (рис. 4.12, 4.13).
Voder, представленный в 1939 г., управлялся человеком-оператором. Вот как описывает свои впечатления Ванневар Буш Vannevar Bush) в работе «As We May Think», 1945 г. (см. также [14], с. 171): «На мировой выставке 1939 г. было показано устройство, называемое Voder.
Девушка-оператор нажимала на его клавиши, и Voder воспроизводил звук, похожий на речь. Это происходило без использования человеческих голосов, нажатие на клавиши просто вызывало комбинации нескольких вибраций, созданных электронным способом, которые воспроизводились с помощью громкоговорителя». В 1940 г. Хомер Дадли представил свою новую модель голосового синтезатора, именуемую The Vocoder (аббревиатура от Voice Operated reCorDER). В 1948 г. на выставке «Electronische Musik» (Германия) VODER был представлен как электронный инструмент будущего. Алгоритмические модели синтезаторов речи с того времени практически не изменились. При этом эти системы развивались параллельно с аналоговыми синтезаторами. Методы озвучивания речи Рассмотрим какой-нибудь хотя бы минимально осмысленный текст. Текст состоит из слов, разделенных пробелами и знаками препинания. Произнесение слов зависит от их расположения в предложении, а интонация фразы — от знаков препинания и довольно часто от типа применяемой грамматической конструкции — в ряде случаев при произнесении текста слышится явная пауза, хотя какие-либо знаки препинания отсутствуют. Произнесение зависит и от смысла слова — сравните, например, выбор одного из вариантов «замок» или «замок» для одного и того же слова «замок». Основная классификация стратегий, применяемых при озвучивании речи — это разделение на две группы подходов: • построение действующей модели речепроизводящей системы человека; • моделирование акустического сигнала как таковой. Первый подход известен под названием артикуляторного синтеза. Второй подход представляется на сегодняшний день более простым, поэтому он гораздо лучше изучен и практически более успешен. Внутри него выделяется два основных направления — формантный синтез по правилам и компилятивный синтез. Формантные синтезаторы используют возбуждающий сигнал, который проходит через цифровой фильтр, построенный на нескольких резонаторах, похожих на резонансы голосового тракта. Разделение возбуждающего сигнала и передаточной функции голосового тракта составляет основу классической акустической теории речеобразования. Компилятивный синтез осуществляется путем склейки нужных единиц компиляции из имеющегося инвентаря. На этом принципе построен ряд систем, использующих разные типы единиц и различные методы составления инвентаря. В таких системах необходимо применять обработку сигнала для приведения частоты основного тона, энергии и длительности единиц к тем, которыми должна характеризоваться синтезируемая речь. Кроме того, требуется, чтобы алгоритм обработки сигнала сглаживал разрывы в формантной (и спектральной в целом) структуре на границах сегментов. И системах компилятивного синтеза применяются два разные типа алгоритмов обработки сигнала: LP (Linear Prediction — линейноe предсказание) и PSOLA (Pitch Synchronous Overlap and Add). LP-синтез основан в значительной степени на акустической теории речеобразования, в отличие от PSOLA-синтеза, который действует путем простого разбиения звуковой волны,
составляющей единицу компиляции, на временные окна и их преобразования. Алгоритмы PSOLA позволяют добиваться хорошего сохранения естественности звучания при модификации исходной звуковой волны.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 156; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.148.103.214 (0.015 с.) |