Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Технологии распределенной обработки информацииСодержание книги
Поиск на нашем сайте
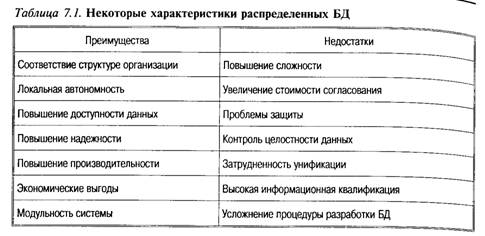
Основное назначение БД — многоцелевое параллельное использование данных, уже предопределяет наличие средств, которые должны обеспечить практически одновременный и независимый доступ к одним и тем же данным. При этом данные могут быть размешены как на одном, так и на нескольких компьютерах. Стремление к интеграции и управляемости (обеспечению целостности) естественно порождает стремление к централизации. Однако на практике наблюдается и стремление к децентрализации, в значительно большей степени отражающей организационную структуру предметной области и технологию порождения и использования хранимых данных. Разные фрагменты данных порождаются и используются обычно в разных подразделениях и организациях, зачастую — географически разобщенных. Разработка распределенных баз и технологий распределенной обработки существенно расширяет возможности, как создания, так и использования данных. Распределенные базы данных Следует отметить, что общая тенденция развития технологий обработки данных вполне соответствует этапам развития средств вычислительной техники и информационных технологий, и в первую очередь — сетевых. Распределенные системы Классификация. Следует выделить два класса систем распределенной обработки и системы распределенных данных: • системы распределенной обработки в основном отражают структуру и свойства многопользовательских операционных систем с базой данных, размещенной на центральном компьютере; • системы распределенных данных обеспечивают обработку распределенных запросов, когда при обработке одного запроса используются информационные ресурсы, размещенные на различных ЭВМ сети. При этом, как и ранее, следует говорить как о распределенных файловых системах, так и о распределенных базах данных. Для распределенных баз данных свойственны следующие характеристики: • база данных — это логически связанные, разделяемые на некоторое количество фрагментов данные; • фрагменты распределяются по разным узлам, которые связаны между собой сетевыми соединениями; • может быть предусмотрена репликация фрагментов; • доступ к данным на каждом узле происходит под управлением СУБД, которая на каждом узле должна поддерживать работу как локальных приложений, так и глобальных. Основные условия и требования к распределенной обработке данных: • прозрачность относительно расположения данных (СУБД должна представлять все данные так, как если бы они были локальными); • гетерогенность системы (СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью); • прозрачность относительно сети (СУБД должна одинаково работать в условиях разнородных сетей); • поддержка распределенных запросов (пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах); • поддержка распределенных изменений (пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в разных системах); • поддержка распределенных транзакций (СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов как в отдельных системах, так и в сети); • безопасность (СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа); • универсальность доступа (СУБД должна обеспечивать единую методику доступа ко всем данным). Поясним некоторые из этих требований: Прозрачность расположения. Прозрачный (для пользователя) доступ к удаленным данным предполагает использование в прикладных программах такого интерфейса с сервером БД, который позволяет переносить данные в сети с одного узла на другой, не требуя при этом модификации текста программы. Иными словами доступ к информационным ресурсам должен быть полностью прозрачен относительно расположения данных. Любой пользователь или любая прикладная программа оперирует с одной или несколькими базами данных. В том случае, когда прикладная программа и сервер БД выполняются на одном и том же узле, проблемы расположения не возникает. Для получения доступа к базе данных пользователю или программе достаточно указать имя базы, например: SQL Dbname. Однако в том случае, когда прикладная программа запускается на локальном узле, а база данных находится на удаленном, возникает проблема идентификации удаленного узла. Для того чтобы получить доступ к базе данных на удаленном узле, необходимо указать имя удаленного узла и имя базы данных. Если использовать жестко фиксированное имя узла в паре «имя_узла, имя_БД», то прикладная программа становится зависимой от расположения БД. Например, обращение к БД «host:stock», где первый компонент — имя узла, будет зависимым от расположения. Одно из возможных решений этой проблемы состоит в использовании виртуальных имен узлов. Управление ими обеспечивается специальным программным компонентом СУБД — сервером имен (Name Server), который адресует запросы клиентов к серверам. Прозрачность сети. Клиент и сервер взаимодействуют по сети с конкретной топологией; для поддержки взаимодействия всегда используется определенный протокол. Следовательно, оно должно быть организовано таким образом, чтобы обеспечивать независимость как от используемого сетевого аппаратного обеспечения, так и от протоколов сетевого обмена. Чтобы обеспечить прозрачный доступ пользователей и программ к удаленным данным в сети, объединяющей разнородные компьютеры, коммуникационный сервер должен поддерживать как можно r лее широкий диапазон сетевых протоколов (TCP/IP, DECnet SNA, SPX/IPX, NetBIOS, AppleTalk и др.). Автоматическое преобразование форматов данных. Как толь ко несколько компьютеров различных моделей под управлением различных операционных систем соединяются в сеть, сразу возникает вопрос о согласовании форматов представления данных Действительно, в сети могут быть компьютеры, отличающиеся разрядностью (16-, 32- и 64-разрядные процессоры), порядком следования байт в слове, представлением чисел с плавающей точкой и т. д. Задача коммуникационного сервера состоит в том чтобы на уровне обмена данными обеспечить согласование форматов между удаленным и локальным узлами с тем, чтобы данные, извлеченные сервером из базы на удаленном узле и переданные по сети, были правильно истолкованы прикладной программой на локальном узле. Автоматическая трансляция кодов. В неоднородной компьютерной среде при взаимодействии клиента и сервера возникает также задача трансляции кодов. Сервер может работать с одной кодовой таблицей (например, EBCDIC), клиент — с другой (например, ASCII), при этом происходит рассогласование трактовки кодов символов. Поэтому, если на локальном узле используется одна кодовая таблица, а на удаленном — другая, то при передаче запросов по сети и при получении ответов на них необходимо обеспечить трансляцию кодов. Решение этой задачи также ложится на коммуникационный сервер. Однако ни одна из существующих СУБД не достигает этого идеала вследствие следующих практических проблем: • низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки; • обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего» и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных; • необходимо обеспечить совместимость данных стандартного типа, для хранения которых в разных системах используются разные физические форматы и кодировки; • трудности выбора схемы размещения системных каталогов. Если каталог будет храниться в одной системе, то удаленный доступ будет замедлен. Если будет размножен, то изменения придется распространять и синхронизировать; • необходимо обеспечить совместимость СУБД разных типов и поставщиков; • увеличение потребностей в ресурсах для координации работы приложений с целью обнаружения и устранения тупиковых ситуаций в распределенных транзакциях. Типы распределенных СУБД В общем случае режимы работы с БД можно классифицировать по следующим признакам: • многозадачность — однопользовательский или многопользовательский; • правило обслуживания запросов — последовательное или параллельное; • схема размещение данных — централизованная или распределенная БД. Распределенные СУБД подразделяются на однородные и разнородные. В однородных системах все узлы используют один и тот же тип СУБД. В разнородных системах на узлах могут функционировать различные типы СУБД, использующие разные модели данных. Однородные системы значительно проще проектировать и сопровождать, добавляя новые узлы к уже существующей распределенной системе и повышая производительность системы за счет параллельной обработки информации. Разнородные системы обычно возникают в тех случаях, когда узлы, уже эксплуатирующие свои собственные системы с базами данных, со временем интегрируются в распределенную систему. В разнородных системах для организации взаимодействия между различными типами СУБД требуется обеспечить преобразование предаваемых сообщений, для чего каждый из узлов должен иметь возможность формулировать запросы на языке той СУБД, которая используется на их локальном узле или система должна взять на себя выполнение всех необходимых преобразований. Очевидны следующие преимущества и недостатки распределенных баз данных (табл. 7.1).
Распределенная СУБД должна иметь следующий набор функциональных возможностей: • расширенные службы установки соединений должны обеспечивать доступ к удаленным узлам и позволять передавать запросы и данные между узлами, входящими в сеть; • расширенные средства ведения каталога, позволяющие сохранять сведения о распределении данных в сети; • средства обработки распределенных запросов, включая механизмы оптимизации запросов и организации удаленного доступа к данным; • расширенные функции управления защитой, позволяющие обеспечить соблюдение правил авторизации и прав доступа к распределенным данным; • расширенные функции управления параллельным выполнением, позволяющие поддерживать целостность копируемых данных; • расширенные функции восстановления, учитывающие вероятность отказов в работе отдельных узлов и отказов линий связи. Соответственно, программные средства, обеспечивающие целевую (функциональную) обработку данных, должны быть организованы таким образом, чтобы обеспечить более эффективное использование совокупных вычислительных ресурсов за счет специализированного разделения функций обработки между центральным процессом СУБД и клиентскими функционально-ориентированными процедурами.
|
||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 93; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.149.249.84 (0.011 с.) |