Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Области использования файлов
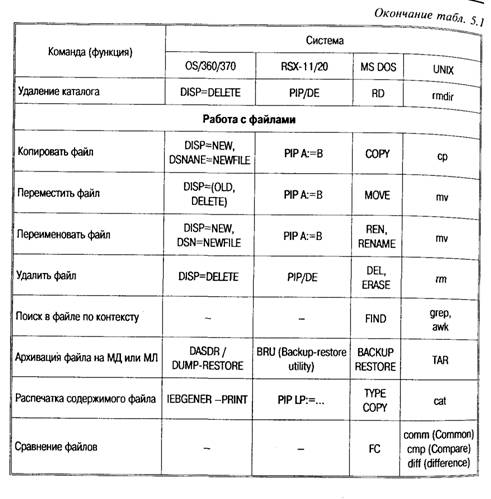
Прежде всего, файлы применяются для хранения текстовых данных: документов, текстов программ и т. д. Такие файлы обычно образуются и модифицируются с помощью различных текстовых редакторов. Структура текстовых файлов обычно очень проста: это либо последовательность записей, содержащих строки текста, либо последовательность байтов, среди которых встречаются специальные символы разметки (например, символы конца строки). Файлы с текстами программ являются входными параметрами компиляторов, которые, в свою очередь, формируют файлы, содержащие объектные модули [9]. С точки зрения файловой системы, объектные файлы также обладают абсолютно стандартной структурой — это последовательности записей или байтов. Система программирования накладывает на эту структуру более сложную и специфичную для этой системы структуру объектного модуля. Подчеркнем, что логическая структура объектного модуля неизвестна файловой системе, а поддерживается программами системы программирования. Заметим, что в отмеченных выше случаях вполне достаточно тех средств защиты файлов и синхронизации параллельного доступа, которые обеспечивают системы управления файлами. Очень редко возникает потребность параллельной модификации файлов, и, как правило, каждый пользователь может обойтись своей частной копией. Другими словами, файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам. В перечисленных выше случаях использования файлов это даже хорошо, потому что при разработке любой новой прикладной системы, опираясь на простые, стандартные и сравнительно дешевые средства файловой системы, можно реализовать те структуры хранения, которые наиболее естественно соответствуют специфике данной прикладной области. В табл. 5.1 приведены типичные команды обращения к файловым системам, характерные для различных ОС.
Файловая система NTFS Структура файловой системы. Как и любая другая система, NTFS делит все полезное пространство диска на кластеры — блоки данных, используемые единовременно. NTFS поддерживает различные размеры кластеров — от 512 байт до 64 Кбайт, стандартом считается кластер размером 4 Кбайт.
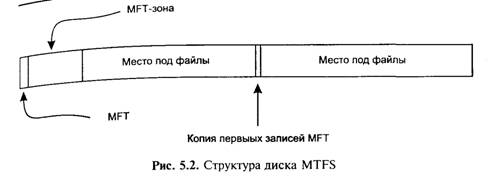
Диск NTFS условно делится на две части (рис. 5.2). Первые 12 % диска отводятся под так называемую MFT-зону — пространство, в котором размещен метафайл MFT (Master File Table). Запись каких-либо данных в эту область невозможна-MFT-зона всегда держится пустой — это делается для того, что бы главный служебный файл (MFT) не фрагментировался при своем расширении. Остальные 88 % диска представляют собой пространство для размещения файлов.
Свободное место диска, однако, включает в себя все физически свободное место – незаполненные участки MFT-зоны туда тоже включаются. Механизм использования MFT-зоны таков: когда файлы уже нельзя записывать в обычное пространство, MFT-зона сокращается, освобождая место для записи файлов. При освобождении участка обычной области MFT-зона может снова расшириться. Структура MFT. Каждый элемент файловой системы NTFS представляет собой файл, даже служебная информация. Как уже говорилось, главный файл NTFS называется MFT, или Master File Table — общая таблица файлов, которая размещается в MFT-зоне и представляет собой централизованный каталог всех остальных файлов диска. MFT поделен на записи фиксированного размера (обычно 1 Кбайт), и каждая запись соответствует какому-либо файлу. Первые 16 файлов носят служебный характер и недоступны операционной системе — они называются метафайлами, причем самый первый из них — сам MFT. Эти первые 16 элементов MFT — единственная часть диска, имеющая фиксированное положение. Остальная часть MFT-файла может сполагаться, как и любой другой файл, в произвольных местах иска — восстановить его положение можно с помощью его самого, используя за основу первый элемент MFT. Все пространство тома NTFS представляет собой либо файл, либо часть файла. Главная таблица файлов содержит по крайней мере одну запись для каждого файла тома, включая одну запись адя самой себя. Все файлы на томе NTFS идентифицируются номером файла, который определяется позицией файла в MFT. Каждый фай и каталог на томе NTFS определяется набором атрибутов. Базовая единица распределения дискового пространства для файловой системы NTFS — кластер. Размер кластера выражается в байтах и всегда равен целому количеству физических секторов. В качестве адреса файла NTFS использует номер кластера не физическое смещение в секторах или байтах.
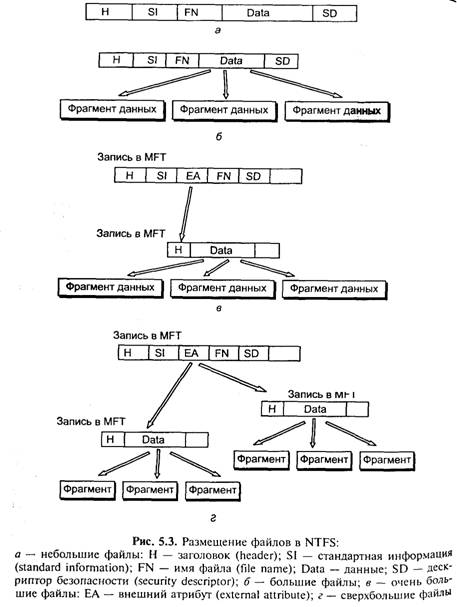
Загрузочный сектор тома NTFS располагается в начале тома а его копия — в середине тома. Загрузочный сектор состоит из стандартного блока параметров BIOS, количества секторов в томе, а также начального логического номера кластера основной копии MFT и зеркальной копии MFT. Каждый атрибут файла NTFS состоит из полей: тип атрибута, длина атрибута, значение атрибута и, возможно, имя атрибута. Имеется системный набор атрибутов, определяемых структурой тома NTFS. Системные атрибуты имеют фиксированные имена и коды их типа, а также определенный формат. Могут применяться также атрибуты, определяемые пользователями. Их имена, типы и форматы задаются исключительно пользователем. Атрибуты файлов упорядочены по убыванию кода атрибута, причем атрибут одного и того же типа может повторяться несколько раз. Существует два способа хранения атрибутов файла — резидентное хранение в записях таблицы MFT и нерезидентное хранение вне ее. Сортировка может осуществляться только по резидентным атрибутам. Файлы NTFS состоят, по крайней мере, из атрибутов, приведенных в табл. 5.2. Размещение файлов. Небольшие файлы (small). Если файл имеет небольшой размер, то он может целиком располагаться внутри одной записи MFT размером 2 Кбайт (рис. 5.3,а) Из-за того, что файл может иметь переменное количество атрибутов, а также из-за переменного размера атрибутов нельзя наверняка утверждать, что файл уместится внутри записи. Однако, обычно файлы размером менее 1500 байт помещаются внутри записи MFT. Большие файлы (Large). Если файл не вмещается в одну запись MFT, то этот факт отображается в значении атриоу та «данные», который содержит признак того, что файл являете нерезидентным и находится вне таблицы M FT. В этом случае а рибут «данные» содержит номер кластера для первого кластер каждого фрагмента данных (data run), а также количество непрерывных кластеров в каждом фрагменте (рис. 5.3, б).
Очень большие файлы (huge). Если файл настолько велик, что его атрибут данных не помещается в одной записи, то этот атРибут становится нерезидентным, т. е. он размещается в другой записи таблицы MFT, ссылка на которую помещена в исходной записи о файле (рис. 5.3, в). Эта ссылка называется внешним атрибутом (external attribute). Нерезидентный атрибут содержит указатели на фрагменты данных.
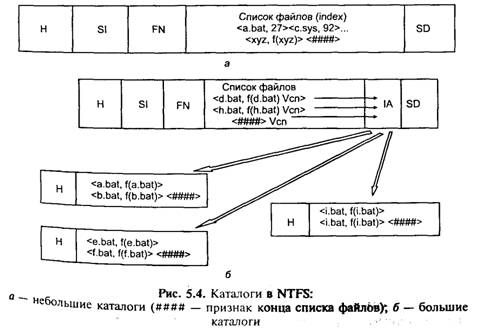
Сверхбольшие файлы (extremely huge). Для сверхбольших файлов внешний атрибут может указывать на несколько нерезидентных атрибутов (рис. 5.3, г). Кроме того, внешний атрибут, как и любой другой атрибут, может храниться в нерезиной форме, поэтому в NTFS не может быть атрибутов слишком большой длины, которые система не может обработать. Каталоги. Каждый каталог NTFS представляет собой один вход в таблицу MFT, который содержит список файлов специальной формы, называемый индексом (index). Индексы позволяют сортировать файлы для ускорения поиска, основанного на рачении определенного атрибута. В файловых системах FAT и HPFS используется сортировка файлов по имени. NTFS позволяет использовать для сортировки любой атрибут, если он хранится в резидентной форме. Имеется две формы списка файлов.
Небольшие списки файлов (small indexes). Если количество файлов в каталоге невелико, то список файлов может быть резидентным в записи в MFT, являющейся каталогом. В этом случае он называется небольшим каталогом (рис. 5.4, а). Небольшой список файлов содержит значения атрибутов файла. По умолчанию — это имя файла, а также номер записи MTF, содержащей начальную запись файла. Большие списки файлов (large index). По мере того, как каталог растет, список файлов может потребовать нерезидентной формы хранения. Однако начальная часть списка всегда остается резидентной в корневой записи каталога в табл це MFT (рис. 5.4, б).
Имена файлов резидентной части списка файлов являются узлами В-дерева. Остальные части списка файлов размещаются вне MFT. Для их поиска используется специальный атрибут «размещение списка» (Index Allocation — IA), представляющий собой набор номеров кластеров, которые указывают на остальные части списка. Одни части списков являются листьями дерева, а другие — промежуточными узлами, т. е. содержат наряду с именами файлов атрибут Index Allocation, указывающий на списки файлов более низких уровней. Имена файлов NTFS поддерживает имена файлов длиной до 255 символов. Имена файлов NTFS используют набор символов UNICODE с 16-битовыми символами. NTFS автоматически генерирует поддерживаемое MS-DOS имя для каждого файла. Таким образом, файлы NTFS могут использоваться в сети операционными системами MS-DOS и OS/2. Поскольку NTFS использует набор символов UNICODE для имен файлов, существует возможность использования некоторых запрещенных в MS-DOS символов. Для генерации короткого имени файла в стиле MS-DOS NTFS удаляет все запрещенные символы, точки (кроме одной), а также любые пробелы из длинного имени файла. Далее имя файла усекается до 6 символов, добаштяется тильда (~) и номер. Расширение имени файла усекается до 3 символов. Короткие имена файлов с длинными русскими именами образуются по особой схеме, в зависимости от типа используемой файловой системы. Другие особенности ФС Надежность NTFS. NTFS является восстанавливаемой (recoverable) файловой системой, которая может привести себя в корректное состояние при практически любых реальных сбоях. Любая современная файловая система основана на таком понятии, как транзакция — действие, совершаемое целиком и корректно или не совершаемое вообще. Журналирование — средство, позволяющее существенно сократить число ошибок и сбоев системы. Опыт показывает, что NTFS восстанавливается в полностью корректное состояние даже при сбоях в очень загруженные дисковой активностью моменты. Она гарантирует согласованность данных тома, используя стандартную процедуру регистрации транзакций. Каждая операция ввода-вывода, которая изменяет файл на томе NTFS, рассматривается файловой системой как транзакция.
При модификации файла специальная компонента файловой системы — сервис регистрации файлов (Log File Service) — фиксирует всю информацию, необходимую для по-торения (redo) или отката (undo) транзакции в специальном файле с именем $LogFile. Если транзакция не завершается нормально, то NTFS пытается закончить транзакцию (повторить) или производит ее откат. Для обеспечения сохранности пользовательских данных используется программная поддержка массивов RAID (Redundant Array of Inexpensive/Independent Disks — см. рис. 5.16) [24, 25]. В сочетании с поддержкой зеркализации дисков или расщепления с контролем четности (RAID 5) NTFS может выдержать любой одиночный сбой. В Windows NT поддерживаются уровни 0, 1 и 5. В RAID 0 данные расщепляются на блоки по 64 Кбайт, поддерживается от 2 до 32 дисков. RAID 1 осуществляется на уровне разделов, т. е. зеркализируются именно разделы. При отказе зеркализованного раздела администратор должен отменить отношения зеркализации, чтобы использовать оставшийся раздел как отдельный том. Затем можно использовать свободный раздел на другом диске, чтобы вновь установить зеркальные отношения. Зеркализации может быть подвергнут любой раздел, включая загрузочный (Boot Partition). В принципе зеркализация является более дорогим способом, чем Другие, так как коэффициент использования дискового пространства составляет только 50 %, с другой стороны, для небольших сетей это весьма приемлемый вариант, так как для его реализации достаточно только двух дисков. RAID 5 требует минимум трех дисков (максимум 32 диска), поддерживает файловые системы FAT, NTFS, причем загрузочный раздел не может быть расщеплен. Если отказывает диск, входящий в состав массива RAID 5, то компьютер может продолжать работу и получать доступ к данным. Однако данные отказавшего диска будут в течение всего времени регенерироваться на основании данных других дисков, и производительность си темы может упасть. Можно воссоздать данные отказавшего диска на новом диске. Для этого нужно иметь свободный раздел на каком-либо работоспособном диске равного или большего раз мера, чем отказавший. Затем запускается процедура восстанет ления данных из пункта Regenerate меню Fault Tolerance утилиты Disk Manager. NTFS поддерживает также «горячее» переназначение секторов, когда при возникновении ошибки из-за наличия плохого сектора данные переписываются в новый хороший сектор, а сбойный исключается из работы. Администратор уведомляется с помощью утилиты просмотра событий Event Viewer о всех событиях, связанных с обработкой сбойных секторов, а также о потенциальной угрозе потери данных, если избыточная копия также отказывает.
Сжатие. NTFS имеет встроенную поддержку сжатия дисков — то, для чего раньше приходилось использовать Stacker или DoubleSpace. Любой файл или каталог в индивидуальном порядке может храниться на диске в сжатом виде — этот процесс прозрачен для приложений. Сжатие файлов осуществляется с высокой скоростью, однако при этом часто возникает отрицательный эффект — фрагментация сжатых файлов. Сжатие осуществляется блоками по 16 кластеров и использует так называемые виртуальные кластеры — гибкое решение, позволяющее добиться полезных эффектов, например, половина файла может быть сжата, а половина — нет. Это достигается благодаря тому, что хранение информации о компрессированности определенных фрагментов очень похоже на обычную фрагментацию файлов. Сжатый файл имеет «виртуальные» кластеры, реальной информации в которых нет. Как только система обнаруживает та виртуальные кластеры, это означает, что данные предыдущего блока, кратного 16 кластерам, должны быть разжаты, а получившиеся данные должны заполнить виртуальные кластеры.
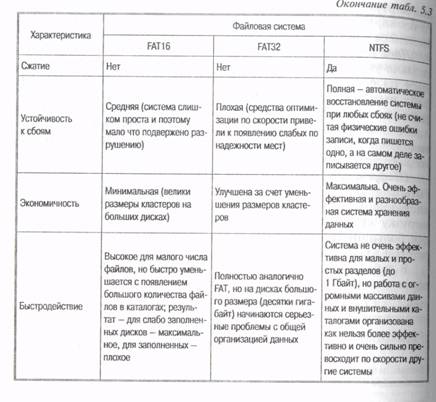
Hard Link — один и тот же файл может иметь два имени (несколько указателей файла-каталога или разных каталогов ссылаются на одну и ту же MFT-запись). Допустим, один и тот же файл имеет имена l.txt и 2.txt, и если пользователь удалит файл l.txt, останется файл 2.txt, наоборот, если сотрет 2.txt – останется файл 1.txt, т. е. оба имени с момента создания файла равноправны. Файл физически удаляется лишь тогда, когда будет удалено его последнее имя. Шифрование (NT 5). Каждый файл или каталог может также быть зашифрован, что не даст возможность прочесть его другой инсталляцией ОС NT. В сочетании со стандартным паролем на загрузку системы, эта возможность обеспечивает достаточную для большинства применений безопасность избранных пользователем важных данных. В табл. 5.3 приведены некоторые характеристики ФС ряда различных ОС.
Базы данных и СУБД Множество функций управления данными ФС оказывается недостаточным для решения задач поддержки информационных систем. Предположим, что мы хотим реализовать простую информационную систему, осуществляющую учет сотрудников некоторой организации. Система должна выдавать списки сотрудников в соответствии с указанными номерами отделов, поддерживать функции регистрации перевода сотрудника из одного отдела в другой, приема на работу новых сотрудников и увольнения работающих. Для каждого отдела должна поддерживаться возможность получения имени руководителя этого отдела, обшей численности отдела, общей суммы выплаченной в последний раз зарплаты и т. д. Для каждого сотрудника должна поддерживаться возможность выдачи номера удостоверения по полному имени сотрудника, выдачи полного имени по номеру удостоверения, получения информации о текущем соответствии занимаемой должности сотрудника и о размере зарплаты. Предположим, что мы решили реализовать эту информационную систему на основе файловой системы и пользоваться при этом одним файлом, расширив базовые возможности файловой системы за счет специальной библиотеки функций. Поскольку минимальной информационной единицей в нашем случае является сотрудник, естественно потребовать, чтобы в этом файле содержалась одна запись для каждого сотрудника. Очевидно, что поля таких записей должны содержать полное имя сотрудника (сотр_имя), номер его удостоверения (сотр_номер), информацию о его соответствии занимаемой должности (СОТР_статус — для простоты «да» или «нет»), размер зарплаты (СОТР_ЗАРП), номер отдела (СОТР_ОТД_НОМЕР). Поскольку мы хотим ограничиться одним файлом, эта же запись должна содержать имя руководителя отдела (сотр_отд_рук). Для выполнения функций нашей информационной системы требуется возможность многоключевого доступа к этому файлу по уникальным ключам (не дублируемым в разных записях) СОТР_ИМЯ и СОТР_НОМЕР. Кроме того, должна обеспечиваться возможность выбора всех записей с общим заданным значением СОТР_ОТД_НОМЕР, т. е. доступ по неуникальному ключу. Чтобы получить численность отдела или общий размер зарплаты, информационная система должна будет каждый раз выбирать все записи о сотрудниках отдела и подсчитывать соответствующие общие значения. Таким образом, для реализации даже такой простой системы на базе файловой системы: • во-первых, требуется создание достаточно сложной надстройки, обеспечивающей многоключевой доступ к файлам; • во-вторых, неизбежны существенная избыточность хранения (для каждого сотрудника данного отдела повторяется имя руководителя отдела) и выполнение массовой выборки и вычислений для получения сводной информации об отделах. Вообще, согласованность данных является ключевым понятием баз данных. На самом деле, если информационная система поддерживает согласованное хранение информаци в нескольких файлах, можно говорить о том, что она подцержи вает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна обладать некоторыми собственными данными (метаданными) и даже знаниями, определяющими целостность данных. Далее, представим себе, что в первоначальной реализации информационной системы, основанной на использовании библиотек расширенных методов доступа к файлам, обрабатывается операция регистрации нового сотрудника. Следуя требованиям согласованного изменения файлов, информационная система вставила новую запись в файл сотрудники и приступает к модификации файла отделы, но именно в этот момент произошло аварийное выключение электрического питания. Очевидно, что после перезапуска системы ее база данных будет находиться в рассогласованном состоянии. Потребуется выяснить это (а для этого нужно явно проверить соответствие информации в файлах сотрудники и отделы) и привести информацию в согласованное состояние. Системы управления базами данных (СУБД) берут такую работу на себя. Прикладная система обязана знать, какое состояние данных является корректным, но всю техническую работу принимает на себя СУБД. Наконец, представим себе, что мы хотим обеспечить параллельную (например, многотерминальную) работу с базой данных сотрудников. Если опираться только на использование файлов, то для обеспечения корректности изменений на все время модификации любого из двух файлов доступ других пользователей к этому файлу будет блокирован (вспомните возможности файловых систем для синхронизации параллельного доступа). Таким образом, зачисление на работу Петра Ивановича Сидорова существенно затормозит получение информации о сотруднике Иване Сидоровиче Петрове, даже если они будут работать в разных отделах. Реальные СУБД обеспечивают гораздо более тонкую синхронизацию параллельного доступа к данным. Типология БД Классификация баз и банков данных может производиться азличным признакам, среди которых выделяют следующие. По форме представляемой информации выделяют: • фактографические; • документальные; • мультимедийные, в той или иной степени соответствующие цифровой, символьной и другим (не цифровой и не символьной) формам представления информации в вычислительной среде. К последним можно отнести картографические, видео, аудио, графические и другие БД. По типу хранимой (немультимедийной) информации выделяют: • фактографические; • документальные; • лексикографические БД. Лексикографические базы — классификаторы, кодификаторы, словари основ слов, тезаурусы, рубрикаторы и т. д., обычно используемые в качестве справочных совместно с документальными или фактографическими БД. Документальные базы по уровню представления информации подразделяются на: полнотекстовые (так называемые «первичные» документы), библиографические и реферативные («вторичные» документы, отражающие на адресном и содержательном уровне первичный документ). По типу используемой модели данных выделяют три классических класса БД: • иерархические; • сетевые; • реляционные. Развитие технологий обработки данных привело к появлению постреляционных, объектно-ориентированных, темпоральных БД, в той или иной степени соответствующих трем упомянутым классическим моделям. По топологии хранения данных различают локальные и распределенные БД. По типологии доступа и характеру использования хранимой информации БД могут быть разделены на специализированные и итерированные. По функциональному назначению (характеру решаемых с помощью БД задач и, соответственно, характеру использовани данных) выделяют операционные и справочно-информацион ные БД. К последним можно отнести ретроспективные БД (электронные каталоги библиотек, БД статистической информации и т. д.), используемые для информационной поддержки основной деятельности, и не предполагающие внесение изменений в существующие записи, например по результатам этой деятельности. Операционные БД предназначены для управления различными технологическими процессами. В этом случае данные не только извлекаются из БД, но и изменяются (в том числе добавляются), в том числе в результате этого использования. По сфере возможного применения различают универсальные и специализированные (или проблемно-ориентированные) системы. По степени доступности выделяют общедоступные и БД с ограниченным доступом пользователей. В последнем случае говорят об управляемом доступе, индивидуально определяющем не только набор доступных данных, но и характер операций, которые доступны пользователю. По назначению содержащейся информации выделяют БД • деловой информации (социальная, коммерческая и другая информация, кадастры, регистры); • информации для специалистов (экономическая, правоохранительная и др информация); • массовой информации. По способу доступа существуют БД: • размещенные на хостах (доступные через сети); • тиражируемые в коммуникативных форматах; • тиражируемые с программными средствами (включая - CD-ROM); • локальные. Представленная классификация не является полной и исчерпывающей. Она в большей степени отражает исторически сложившееся состояние дел в сфере деятельности, связанной с разработкой и применением БД. Таким образом, СУБД решают множество проблем, которые затруднительно или вообще невозможно решить при использовании файловых систем. При этом существуют: • приложения, для которых вполне достаточно файлов; • приложения, для которых необходимо решать, какой уровень работы с данными во внешней памяти для них требуется;. • приложения, для которых безусловно нужны базы данных.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 66; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.71.142 (0.049 с.) |