Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Обобщенная функциональная структура синтезатораСодержание книги
Поиск на нашем сайте
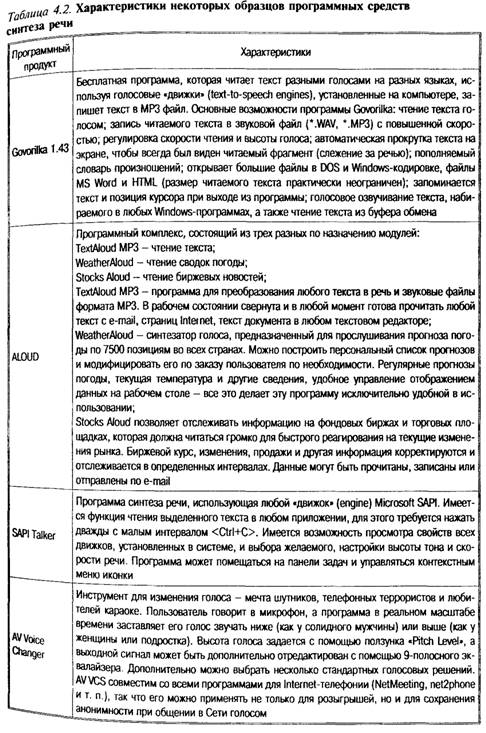
Структура идеализированной системы автоматического синтеза речи состоит из нескольких блоков: • определение языка текста; • нормализация текста; • лингвистический анализ (синтаксический, морфемный и т. д.); • формирование просодических характеристик; • фонемный транскриптор; • формирование управляющей информации; • получение звукового сигнала. Такая схема содержит компоненты, которые можно обнаружить во многих системах. Разработчики конкретных систем уделяют различное внимание отдельным блокам и реализуют их очень по-разному, в соответствии с практическими требованиями. Модуль лингвистической обработки. Прежде всего, текст, подлежащий прочтению, поступает в модуль лингвистической обработки. В нем производится определение языка (в многоязычной системе синтеза), а также отфильтровываются не подлежащие произнесению символы. В некоторых случаях используются спелчекеры (модули исправления орфографических и пунктуационных ошибок). Затем происходит нормализация текста, т. е. осуществляется разделение введенного текста на слова и остальные последовательности символов. К символам относятся, в частности, знаки препинания и символы начала абзаца. Все знаки пунктуации очень информативны. Для озвучивания цифр разрабатываются специальные подблоки. Преобразование цифр в последовательности слов является относительно легкой задачей (если читать цифры как цифры, а не как числа, которые должны быть правильно оформлены грамматически), но цифры, имеющие разное значение и функцию, произносятся по-разному. Для многих языков можно говорить, например, о существовании отдельной произносительной подсистемы телефонных номеров. Пристальное внимание уделяется правильной идентификации и озвучиванию цифр, обозначающих числа месяца, годы, время, телефонные номера, денежные суммы и т. д. (список для различных языков может быть разным). Лингвистический анализ. После процедуры нормализации каждому слову текста (каждой словоформе) необходимо приписать сведения о его произношении, т. е. превратить в цепочку фонем или, иначе говоря, создать его фонемную транскрипцию. Во многих языках, в том числе и в русском, существуют достаточно регулярные правила чтения — правила соответствия между буквами и фонемами (звуками), которые, однако, могут требовать предварительной расстановки словесных ударений. В английском языке правила чтения очень нерегулярны, и задача данного блока для английского синтеза тем самым усложняется. В любом случае при определении произношения имен собственных, заимствований, новых слов, сокращений и аббревиатур возникают серьезные проблемы. Просто хранить транскрипцию для всех слов языка не представляется возможным из-за большого объема словаря и контекстных изменений произношения одного и того же слова во фразе. Кроме того, следует корректно рассматривать случаи графической омонимии: одна и та же последовательность буквенных символов в различных контекстах порой представляет два различных слова/словоформы и читается по-разному (например, ранее приведенный пример слова «замок»). Для языков с достаточно регулярными правилами чтения одним из продуктивных подходов к переводу слов в фонемы является система контекстных правил, переводящих каждую букву/буквосочетание в ту или иную фонему, т. е. автоматический фонемный транскриптор. Однако чем больше в языке исключений из правил чтения, тем хуже работает этот метод. Стандартный способ улучшения произношения системы состоит в занесении нескольких тысяч наиболее употребительных исключений в словарь. Альтернативное подходу «слово—буква—фонема» решение предполагает морфемный анализ слова и перевод в фонемы морфов (т. е. значимых частей слова: приставок, корней, суффиксов и окончаний). Однако в связи с разными пограничными явлениями на стыках морфов разложение на эти элементы представляет собой значительные трудности. В то же время для языков с богатой морфологией, например, для русского, словарь морфов был бы компактнее. Морфемный анализ удобен еще и потому, что с его помощью можно определять принадлежность слов к частям речи, что очень важно для грамматического анализа текста и задания его просодических характеристик. В английских системах синтеза морфемный анализ был реализован в системе МIТа1к, для которой процент ошибок транскриптора составляет 5 %. Особую проблему для данного этапа обработки текста образуют имена собственные. Формирование просодических характеристик. Кпросодическим характеристикам высказывания относятся его тональные, акцентные и ритмические характеристики. Их физическими аналогами являются частота основного тона, энергия и длительность. В речи просодические характеристики высказывания определяются не только составляющими его словами, но также тем, какое значение оно несет и для какого слушателя предназначено, эмоциональным и физическим состоянием говорящего и многими другими факторами. Многие из этих факторов сохраняют свою значимость и при чтении вслух, поскольку человек обычно интерпретирует и воспринимает текст в процессе чтения. Таким образом, от системы синтеза следует ожидать примерно того же, т. е. она сможет понимать имеющийся у нее на входе текст, используя методы искусственного интеллекта. Однако этот уровень развития компьютерной технологии еще не достигнут, и большинство современных систем автоматического синтеза стараются корректно синтезировать речь с эмоционально нейтральной интонацией. Между тем, даже эта задача на сегодняшний день представляется очень сложной. Формирование просодических характеристик, необходимых для озвучивания текста, осуществляется тремя основными блоками, а именно: • расстановки синтагматических границ (паузы); • приписывания ритмических и акцентных характеристик (длительности и энергия); • приписывания тональных характеристик (частота основного тона). При расстановке синтагматических границ определяются части высказывания (синтагмы), внутри которых энергетические и тональные характеристики ведут себя единообразно и которые человек может произнести на одном дыхании. Если система не делает пауз на границах таких единиц, то возникает отрицательный эффект: слушающему кажется, что говорящий (в ном случае — система) задыхается. Помимо этого, расстановка синтагматических границ существенна и для фонемной транскрипции текста. Самое простое решение состоит в том, чтобы ставить границы там, где их диктует пунктуация. Для наиболее простых случаев, когда пунктуационные знаки отсутствуют можно применить метод, основанный на использовании служебных слов. Именно эти методы используются в системах синтеза Pro-Se-2000, Infovox-5A-101 и DECTalk, причем в последней просодически ориентированный словарь, помимо служебных слов, включает еще и глагольные формы. Задача приписывания тональных характеристик обычно ставится достаточно узко. В системах синтеза речи предложению, как правило, приписывается нейтральная интонация. Не предпринималось попыток моделировать эффекты более высокого уровня, такие, как эмоциональная окраска речи, поскольку эту информацию извлечь из текста трудно, а часто и просто невозможно. Некоторые другие реализации Наиболее распространенными системами синтеза речи на сегодня являются те, которые поставляются в комплекте со звуковыми платами. Если компьютер пользователя оснащен какой-либо из них, существует значительная вероятность того, что на нем установлена система синтеза речи (не русской, а английской речи, точнее, ее американского варианта). К большинству оригинальных звуковых плат Sound Blaster прилагается система Сreative Text-Assist, а вместе со звуковыми картами других производителей часто поставляется программа Monologue компании First Byte. TextAssist представляет собой реализацию формантного синтезатора по правилам и базируется на системе DECTalk, разработанной корпорацией Digital Eguipment, который до сих пор остается своего рода стандартом качества для синтеза речи американского варианта английского. Компания Creative Technologies предлагает разработчикам использовать TextAssist в своих программах с помощью специального TextAssistApi (AAPI). Поддерживаемые операционные системы - MS Windows и Windows 95; для Windоws NT также существует версия системы DECTalk, изначально создававшейся для Digital Units. Новая версия TextAssist объявленная фирмой Assotiative Computing Inc, разработанная ё использованием технологий DECTalk и Creative, является в то же время многоязычной системой синтеза, поддерживая английский, немецкий, испанский и французский языки. Это обеспечивается прежде всего использованием соответствующих лингвистических модулей, разработчик которых — фирма Lernout& Hauspie Speech Products, признанный лидер в поддержке многоязычных речевых технологий. Monologue — программа, предназначенная для озвучивания текста, находящегося в буфере обмена MS Windows, использует систему ProVoice. ProVoice — компилятивный синтезатор с использованием оптимального выбора режима компрессии речи и сохранения пограничных участков между звуками, разновидность TD-PSOLA. Рассчитан на американский и британский английский, немецкий, французский, латино-американскую разновидность испанского и итальянский языки. Инвентарь сегментов компиляции — смешанной размерности: сегменты — фонемы или аллофоны. Компания First Byte позиционирует систему ProVoice и программные продукты, основанные на ней, как приложения с низким потреблением процессорного времени. FirstByte также предлагает рассчитанную на мощные компьютеры систему артикуляторного синтеза PrimoVox для использования в приложениях телефонии. Для разработчиков: Monologue Win32 поддерживает спецификацию Microsoft SAPI. MBROLA — так называется система многоязычного синтеза, реализующая особый гибридный алгоритм компилятивного синтеза и работающая как под Windows, так и на платформах Sun4. Впрочем, система принимает на входе цепочку фонем, а не текст, и потому не является, строго говоря, системой синтеза речи по тексту. Формантный синтезатор Tru-Voice фирмы Centigram Communication Corporation(CUIA) близок к описанным выше системам по архитектуре и предоставляемым возможностям, однако он поддерживает больше языков: американский английский, латино-американский, испанский, немецкий, французский, итальянский. Кроме того, в этот синтезатор включен специальный препроцессор, который обеспечивает быструю подготовку для чтения сообщений, получаемых по электронной почте, факсов и баз данных. Engine – «машины» синтеза и распознавания речи «Машина» (в просторечии — «движок») — это пакет программных средств, выполняющих строго определенную задачу и поставляющий интерфейс для использования его возможностей В настоящее время существует целый ряд машин синтеза и Опознавания речи, которые разработаны для использования совместно с MS Speech API. smARTspeak CS — настраиваемая независимая от языка «машина» распознавания речи для набора цифр, указания имен и речевой навигации, т. е. для приложений, используемых в сотовых телефонах и беспроводных устройствах. Созданный для использования в указанных устройствах, smARTspeak CS удовлетворяет потребностям как пользователей, так и разработчиков: иммунитет к фоновому шуму, малые требования к процессору и памяти, совместимость с MS SAPI 5.0, оптимизация для средств быстрой разработки приложений и для интеграции в сертифицированные устройства. Conversay предоставляет решение для речевого взаимодействия с информацией, поставляемой через сеть, включая Internet в случае, когда другие интерфейсы слишком сложны или отсутствуют. Conversay разрабатывает речевую технологию, которая позволяет пользователям взаимодействовать через мобильные устройства привычным для себя способом. Lernout & Hauspie. Система компании L&H позволяет настраивать чтение аббревиатур и слов (ударения). Продукт, активно продвигаемый Microsoft. Digalo. Голосовой «движок» для русского языка Digalo — продукт французской фирмы Elan Informatique. Digalo различает буквы «Е» и «Ё» и виртуозно владеет русской ненормативной лексикой. В основном ошибки в ударениях приходятся на некоторые фамилии и имена, малоупотребительные слова и термины, замечено не всегда корректное озвучивание чисел и очень акцентированное произнесение слов «нет» и «не». Разработчики обещают в дальнейшем сделать возможной корректировку произнесения отдельных слов и слогов. А ctor5. Новый «движок» фирмы Loquendo «Actor 5» предназначен для использования в областях голосовых технологий и сервиса. Синтезирует речь на итальянском, испанском, английском, немецком, мексиканском, бразильском и американском иском диалекте (русского, к сожалению, нет). PC Voice Club. Движок синтеза речи Клуба голосовых технологий при Научном Парке МГУ. При его создании использована базовая технология синтеза речи, разработанная на филологическом факультете МГУ. Синтезатор характеризуется высоким качеством синтеза речи, что позволяет прослушивать тексты без их специальной подготовки. Позволяет синтезировать речь на английском и русском языках. Кроме того, имеет около десятка голосовых типажей (робот, эльф, мышь и пр.) Имеются возможности редактирования голосов. Помимо стандартных функций синтеза речи имеется дополнительная функция встраивания в текст управляющих символов, которые позволяют устанавливать паузы, изменять тембр, тон и длительность звучания. К примеру, можно, отредактировав текст, заставить синтезатор петь. Творческий коллектив радиофизиков и программистов разработал серию программных продуктов под общим названием «Говорящая мышь» Синтезатор русской речи Рассмотрим разработку «Говорящая мышь» упоминавшегося Клуба голосовых технологий. В основе речевого синтеза лежит идея совмещения методов конкатенации и синтеза по правилам. Метод конкатенации при адекватном наборе базовых элементов компиляции обеспечивает качественное воспроизведение спектральных характеристик речевого сигнала, а набор правил — возможность формирования естественного интонационно-просодического оформления высказываний. Существуют и другие методы синтеза, может быть, в перспективе более гибкие, но дающие пока менее естественное озвучивание текста. Это, прежде всего, параметрический (формантный) синтез речи по правилам или на основе компиляции, развиваемый для ряда языков зарубежными исследователями. Однако для реализации этого метода необходимы статистически представительные акустико-фонетические базы данных и соответствующая компьютерная технология, которые пока доступны не всем. Язык формальной записи правил синтеза. Для создания удобного и быстрого режима изменения и верификации правил, включенных в разные блоки синтезирующей системы, был разработан формализованный и в то же время содержательно прозрачный и понятный язык записи правил, который легко компилируется в исходные тексты программ. В настоящее время блок автоматического транскриптора насчитывает около 1000 строк, записанных на формализованном языке представления правил. Интонационное обеспечение. Функция разработанных правил состоит в том, чтобы определить временные и тональные характеристики базовых элементов компиляции, которые при обработке синтагмы выбираются из библиотеки в нужной последовательности специальным процессором (блоком кодировки). Необходимые для этого предварительные операции над синтезируемым текстом: выделение синтагм, выбор типа интонации, определение степени выделенности (ударности-безударности) гласных и символьного звукового наполнения слоговых комплексов осуществляются блоком автоматического транскриптора. Во временной процессор входят также правила, задающие длительность паузы после окончания синтагмы (конечной/неконечной), которые необходимы для синтеза связного текста. Предусмотрена также модификация общего темпа произнесения синтагмы и текста в целом, причем в двух вариантах: в стандартном — при равномерном изменении всех единиц компиляции — ив специальном, дающем возможность изменения длительности только гласных или только согласных. Тональный процессор содержит правила формирования для одиннадцати интонационных моделей: нейтральная повествовательная интонация (точка), точковая интонация, типичная для фокусируемых ответов на вопросы; интонация предложений с контрастивным выделением отдельных слов; интонация специального и общего вопроса; интонация особых противопоставительных или сопоставительных вопросов; интонация обращений, некоторых типов восклицаний и команд; два вида незавершенности, перечислительная интонация; интонация вставочных конструкций. Аллофонная базаданных. Необходимый речевой материал записан в режиме оцифровки счастотой дискретизации 22 кГц сразрядностью 16 бит. В качестве базовых элементов компиляции выбраны аллофоны, оптимальный набор которых и представляет собой акустико-фонетическую базу синтеза. Инвентарь базовых единиц компиляции включает в себя 1200 элементов, который занимает около 7 Мбайт памяти. В большинстве случаев элементы компиляции представляют собой сегменты речевой волны фонемной размерности. Для получения необходимой исходной базы единиц компиляции был составлен специальный словарь, который содержит слова и словосочетания с аллофонами во всех учитываемых контекстах. В нем содержится 1130 словоупотреблений. Лингвистический анализ. На основе данных, полученных от остальных модулей синтеза речи и от аллофонной базы, программа формирования акустического сигнала позволяет осуществлять модификацию длительности согласных и гласных. Она дает возможность модифицировать длительность отдельных периодов на вокальных звуках, используя две или три точки тонирования на аллофонном сегменте, осуществляет модификацию энергетических характеристик сегмента и соединяет модифицированные аллофоны в единую слитную речь. На этапе синтеза акустического сигнала программа позволяет получать разнообразные акустические эффекты — такие, как реверберация, эхо, изменение частотной окраски. Готовый акустический сигнал преобразуется в формат данных, принятый для вывода звуковой информации. Используются два формата: WAV (Waveform Audio File Format), являющийся одним из основных, или VOX (Voice File Format), широко используемый в компьютерной телефонии. Вывод также может осуществляться непосредственно на звуковую карту. Инструментарий синтеза русской речи. Упоминавшийся выше инструментарий синтеза русской речи по тексту позволяет читать вслух смешанные русско-английские тексты. Инструментарий представляет собой набор динамических библиотек (DLL), в который входят модули русского и английского синтеза, словарь ударений русского языка, модуль правил произнесения английских слов. На вход инструментария подается слово или предложение, подлежащее произнесению, с выхода поступает звуковой файл в формате WAV или VOX, записываемый в память или на жесткий диск. В табл. 4.2 приводятся характеристики ряда систем синтеза речи.
SSML Speech Synthesis Markup Language (Язык разметки для синтеза речи) представляет собой основанный на XML язык разметки для приложений, связанных с синтезом речи. Он рекомендован рабочей группой Консорциума WWW по голосовым браузерам (W3C's voice browser working group). SSML часто встраивается в сценарии VoiceXML, чтобы управлять интерактивными системами телефонной связи. Однако он также может использоваться самостоятельно, например, для того, чтобы создавать звучащие документы. Известны также и другие аналогичные изделия включая встроенные речевые команды Apple, или SAPI TTS (разработка Microsoft также на базе языка XML). SSML разработан на базе языка JSML (Sun Microsystems), хотя основные рекомендация были сделаны главным образом производителями синтезаторов речи. SSML охватывает фактически все аспекты синтеза, хотя некоторые области оставлены неопределенными, и таким образом каждый синтезатор может здесь давать собственную интерпретацию текста (SSML не является таким строгим стандартом как С или хотя бы HTML ). Примердокумента SSML:
|
||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 133; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.59.89 (0.01 с.) |