Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основные методы оптического распознавания
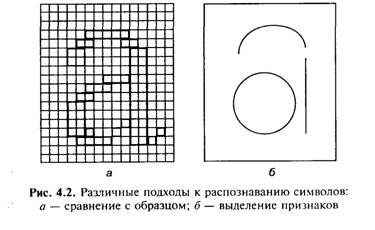
Один из самых ранних методов оптического распознавания символов базировался на сопоставлении матриц или сравнении с образцом букв. Большинство шрифтов имеют формат Times, Courier или Helvetica и размер от 10 до 14 пунктов (точек). Программы оптического распознавания символов, которые используют метод сопоставления с образцом, имеют точечные рисунки для каждого символа каждого размера и шрифта (рис. 4.2, а). Сравнивая базу данных точечных рисунков с рисунками отсканированных символов, программа пытается их распознавать. Эта ранняя система успешно работала только с непропорциональными шрифтами (подобно Courier), где символы в тексте хорошо отделены друг от друга. Сложные документы с различными шрифтами оказываются уже вне возможностей таких программ.
Выделение признаков было следующим шагом в развитии оптического распознавания символов. При этом распознавание символов основывается на идентификации их универсальных особенностей, чтобы сделать распознавание символов независимым от шрифтов. Если бы все символы могли быть идентифицированы, используя правила, по которым элементы букв (например, окружности и линии) присоединяются друг к другу, то индивидуальные символы могли быть описаны независимо от их шрифта. Например: символ «а» может быть представлен как состоящий из окружности в центре снизу, прямой линии справа и дуги окружности сверху в центре (рис. 4.2, б). Если отсканированный символ имеет эти особенности, он может быть правильно идентифицирован как символ «а» программой оптического распознавания. Выделение признаков было шагом вперед сравнительно с соответствием матриц, но практические результаты оказались весьма чувствительными к качеству печати. Дополнительные пометки на странице или пятна на бумаге существенно снижали точность обработки. Устранение такого «шума» само по себе стало целой областью исследований, пытающейся определить, какие биты печати не являются частью индивидуальных символов. Если шум идентифицирован, достоверные символьные фрагменты могут тогда быть объединены в наиболее вероятные формы символа. Некоторые программы сначала используют сопоставление с образцом и/или метод выделения признаков для того, чтобы распознать столько символов, сколько возможно, а затем уточняют результат, используя грамматическую проверку правильности написания для восстановления нераспознанных символов. Например, если программа оптического распознавания символов неспособна распознать символ «е» в слове «th~ir», программа проверки грамматики может решить, что отсутствующий символ — «е».
Современные технологии оптического распознавания намного совершеннее, чем более ранние методы. Вместо того чтобы только идентифицировать индивидуальные символы, современные методы способны идентифицировать целые слова. Эту технологию, предложенную Caere, называют прогнозирующим оптическим распознаванием слов (Predictive Optical Word Recognition — POWR). Используя более высокие уровни контекстного анализа, метод POWR способен устранить проблемы, вызванные шумом. Компьютер анализирует тысячи или миллионы различных способов, которыми точки изображения могут быть собраны в символы слова. Каждой возможной интерпретации приписывается некоторая вероятность, после чего используются нейронные сети и прогнозирующие методы моделирования, заимствованные от исследований в области искусственного интеллекта. Они предполагают использование «экспертов» — алгоритмов, разработанных специалистами в различных областях распознавания символов. Один «эксперт» может знать многое о начертаниях шрифта, другой — о словарной информации, третий — об ухудшении качества от «зашумленности» и пр. На каждой стадии исследования привлекается новый набор «экспертов» с учетом близости их «областей знаний» к специфической ситуации и статистики успеха в подобных ситуациях. Окончательный итог — то, что система POWR способна идентифицировать слова способом, который близко напоминает человеческое визуальное распознавание. Практически, методика значительно улучшает точность распознавания слов во всех типах документа. Все возможные интерпретации слова оцениваются, комбинируя все источники доказательства, от информации пикселя нижнего уровня до контекстных особенностей высокого уровня, в результате чего выбирается самая вероятная интерпретация.
Технологии Finereader Хотя системы оптического распознавания символов существовали в течение долгого времени, их выгоды только сейчас начали по достоинству оценивать. Первые разработки были чрезвычайно дорогостоящими (в терминах программного обеспечения и оборудования), неточны и трудны для использования. За несколько последних лет системы оптического распознавания полностью преобразились. Современное программное обеспечение распознавания символов очень удобно в использовании, обладает высокой точностью и находится на пути к распространению на все виды рабочих сред в массовом масштабе. Типичным представителем данного семейства программ является ABBYY FineReader, технологический процесс которого включает следующие шаги (рис. 4.3): • сканирование исходного документа (страницы); • разметку областей (ручную или автоматическую), требующих различные виды обработки (страницы разворота книги, таблицы, рисунки, колонки текста и пр.); • распознавание — создание и вывод на экран текстового файла (с вставленными рисунками и таблицами, если это необходимо); • контроль правильности (ручной, автоматический, полуавтоматический); • вывод информации в выходной файл в заданном формате (.DOC или.RTF для Word,.XSL для Excel и пр.). Данные, полученные на каждом этапе (изображение, текстовый файл), сохраняются под «общей вывеской» пакета (страницы с номером), что позволяет в любой момент вернуться и повторить разметку, распознавание и пр.
Если нет необходимости сохранять цветовую информацию оригинала документа (например, для последующей обработки системами оптического распознавания символов), изображение лучше всего сканировать в режиме grayscale (полутоновое изображение). При этом файл будет занимать одну треть объема сравнительно со сканированием в цвете RGB. Можно использовать также режим штриховой графики (line art), однако при этом часто теряются подробности, существенные для точности последующего процесса распознавания символов. Рассмотрим основные принципы функционирования программного продукта. Принципы IPA (целостности, целенаправленности, адаптивности). Пользователь помещает документ в сканер, нажимает кнопку, и через небольшое время в компьютер поступает электронное изображение, «фотография» страницы. На ней присутствуют все особенности оригинала, вплоть до мельчайших подробностей. Это изображение содержит всю необходимую для OCR-системы информацию об исходном документе. Принцип целостности (integrity), согласно которому объект рассматривается как целое, состоящее из связанных частей. Связь частей выражается в пространственных отношениях между ними, и сами части получают толкование только в составе предполагаемого целого, т. е. в рамках гипотезы об объекте. Принцип целенаправленности (purposefulness): любая интерпретация данных преследует определенную цель. Согласно этому принципу, распознавание представляет собой процесс выдвижения гипотез о целом объекте и целенаправленной их проверки. Принцип адаптивности (adaptability) подразумевает способность системы к самообучению. Полученная при распознавании информация упорядочивается, сохраняется и используется впоследствии при решении аналогичных задач. Преимущество самообучающихся систем заключается в способности «спрямлять» путь логических рассуждений, опираясь на ранее накопленные знания.
Вместо полных названий этих принципов часто употребляют аббревиатуру IPA, составленную из первых букв соответствующих английских слов. Преимущества системы распознавания, работающей в соответствии с принципами IРА, очевидны — именно они способны обеспечить максимально гибкое и осмысленное поведение системы. Например, на этапе распознавания символов изображение, согласно принципу целостности, будет интерпретировано как некий объект, только если на нем присутствуют все структурные части этого объекта, и эти части находятся в соответствующих отношениях. Иначе говоря, FineReader не пытается принимать решение, перебирая тысячи эталонов в поисках наиболее подходящего. Вместо этого выдвигается ряд гипотез относительно того, на что похоже обнаруженное изображение, затем каждая гипотеза целенаправленно проверяется. Допуская, что найденный объект может быть буквой «A», FineReader будет искать именно те особенности, которые должны быть у изображения этой буквы. Как и следует поступать, исходя из принципа целенаправленности. Причем проверять, верна ли выдвинутая гипотеза, система будет, опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
|
|||||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 346; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.59.187 (0.006 с.) |