Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Лабораторная Работа №11 методы эффективного кодирования информацииСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Цель работы Изучить алгоритм Хаффмена для оптимального префиксного кодирования алфавита с минимальной избыточностью.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе.
Теоретические сведения Алгоритм Хаффмена (англ. Huffman) – алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью был разработан в 1952 году доктором Массачусетского технологического института Дэвидом Хаффменом. Он более практичен и никогда по степени сжатия не уступает методу Шеннона-Фэно, более того, он сжимает максимально плотно. Этот метод кодирования состоит из двух основных этапов: Построение оптимального кодового дерева. Построение отображения код-символ на основе построенного дерева. Алгоритм кодирования может быть представлен следующим образом: Символы первичного алфавита m1 выписывают в порядке убывания вероятностей. Последние n0 символов объединяют в новый символ, вероятность которого равна сумме этих символов, удаляют эти символы и вставляют новый символ в список остальных на соответствующее место (по вероятности). n0 вычисляется из системы:
где a – целое число, m1 и m2 – мощность первичного и вторичного Последние m2 символов снова объединяют в один и вставляют его в соответствующей позиции, предварительно удалив символы, вошедшие в объединение. Предыдущий шаг повторяют до тех пор, пока сумма всех m2 символов не станет равной 1. Этот процесс можно представить как построение дерева, корень которого – символ с вероятностью 1, получившийся при объединении символов из последнего шага, его m2 потомков — символы из предыдущего шага и т.д. Каждые m2 элементов, стоящих на одном уровне, нумеруются от 0 до m2-1. Коды получаются из путей (от первого потомка корня и до листка). При декодировании можно использовать то же самое дерево, считывается по одной цифре и делается шаг по дереву, пока не достигается лист – тогда выводится символ, стоящий в листе и производится возврат в корень. Для двоичного кода описанная методика значительно упрощается. В этом случае n0=m2=2, а полученное в результате построения дерево называется двоичным. Рассмотрим применение алгоритма Хаффмена для последовательности «aa bbb cccc ddddd» (таблица 1, таблица 2). Энтропия исходного сообщения равна:
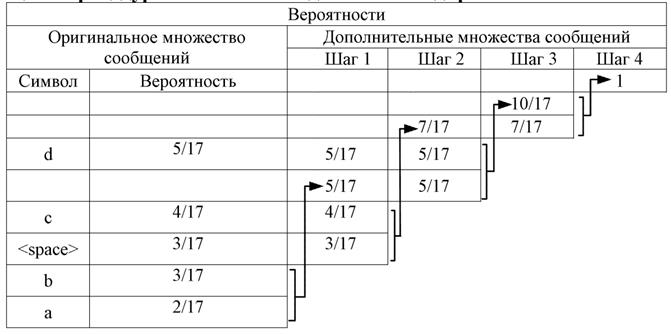
Таблица 1. Процедура оптимального двоичного кодирования
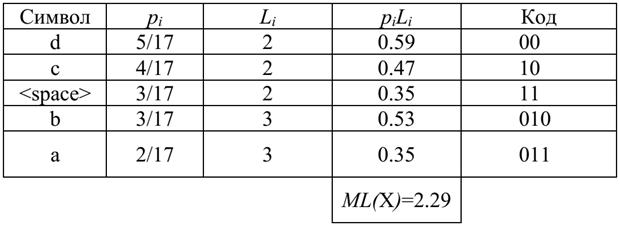
Таблица 2. Результат кодирования по методу Хаффмена
Отметим, что в ряде случаев вместо таблицы, отражающей процедуру d5 c4 <space>3 b3 a2, осуществляя с помощью скобок группировку символов. Например, первый d5 (b3 + a2)5 c4 <space>3
[d5 + (b3 + a2)5]10 + (c4 + <space>3)7
Полученные соотношения удобно представлять в виде дерева, по которому можно составить код для каждого символа (рис. 1).
Рисунок 1 – Кодовое дерево
Средняя длина сообщения, кодирующего заданную последовательность, равна:
Оборудование ПЭВМ IBMPC, операционная система Windows, OooWriter, MSWord.
Задание на работу Построить кодовое дерево и код Хаффмена для последовательности
Подсчитайте энтропию исходного сообщения и среднюю длину кодирующего сообщения.
7. Контрольные вопросы 1. Какова суммарная вероятность всех символов, участвующих в кодировании по методу Хаффмена? 2. Сколько раз кодеру Хаффмена необходимо просматривать сжимаемый текст для получения окончательного результата? 3. Может ли среднее количество бит на единицу сообщения для кодирования по методу Хаффмена быть меньше энтропии сообщения? Почему? 4. Нужно ли при кодировании по методу Хаффмена кроме сжатого сообщения передавать какую-либо дополнительную информацию? Поясните ответ. 5. Какой вариант сжатия – обратимое или необратимое – реализует алгоритм Хаффмена? 6. Почему кодирование по Хаффмену называется префиксным?
|
||||||||||||||||
|
|
Последнее изменение этой страницы: 2019-11-02; просмотров: 590; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.15 (0.011 с.) |