Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Курс лекций «Инструментальные средства в управлении»Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Курс лекций «Инструментальные средства в управлении» Введение
Одним из основных факторов влияния научно-технического прогресса на все сферы деятельности человека является широкое использование новых информационных технологий (ИТ). Среди наиболее важных и массовых сфер, в которых ИТ играют решающую роль, особое место занимает сфера управления. Под влиянием новых ИТ происходят коренные изменения в технологии управления (автоматизируются процессы обоснования и принятия решений, организация их выполнения), повышается квалификация и профессионализм специалистов, занятых управленческой деятельностью. Сфера применения новых ИТ технологий на базе персональных компьютеров и развитых средств коммуникации весьма обширна. Она включает различные аспекты — от обеспечения простейших функций служебной переписки до системного анализа и поддержки сложных задач принятия решений. Персональные компьютеры, цифровая и оптическая техника, средства массовой информации и различного вида коммуникации (включая спутниковую связь) позволяют учреждениям, предприятиям, фирмам, организациям, трудовым коллективам и отдельным специалистам получать в нужное время и в полном объеме необходимую информацию для реализации профессиональных, образовательных и других целей. Цель учебной дисциплины «Инструментальные средства в управлении» - подготовить будущих менеджеров теоретически и профессионально к новым условиям работы в современной экономике, дать знания основ применения современных технологий и методов решения задач управления в области автоматизированных информационных технологий и информационных систем.
Модуль 1. «Информационное обслуживание управленческой деятельности, инструментальные средства управления
Концепция развития современных инструментальных средств управления
Иерархия задач менеджмента Одной из характерных особенностей нашего времени является возросшая роль функции управления, как производственными процессами, так и другими сферами человеческой деятельности. Жизнедеятельность любой организации[1] (предприятия) напрямую зависит от качества и эффективности управления всеми процессами (производственными, финансовыми, кадровыми и др.), протекающими в ней, т.е. от менеджмента. Менеджмент – это совокупность принципов, методов, форм управления, а также совокупность систем скоординированных мероприятий, направленных на достижение значимых целей организации Целью, в общем понимании, называется желаемое состояние некоторого объекта (например, предприятия) или результаты его деятельности, достигнутые за определенный промежуток времени. Любая организация в период своей жизнедеятельности взаимодействует с внешней средой. Результатом этого взаимодействия могут быть процессы разрушения организации (деградации) или, наоборот, ее развития (усложнения, накопления информации). Для того чтобы процессы, протекающие во время функционирования организации, принимали обратимый характер, необходимо управление. Управление – это всегда целенаправленное воздействие на объект управления, изменяющее его состояние и ведущее к достижению поставленной цели. В деятельности любой организации можно выделить пять видов функциональных процессов, которые являются объектами управления со стороны менеджмента: производство, маркетинг, финансы, работа с кадрами и эккаунтинг (учет и анализ хозяйственной деятельности). Основными функциями управления (менеджмента), которые в настоящее время общепринято считать применимыми ко всем организациям, являются: · планирование, призванное в идеальной форме реализовать цель управления; · организация – создание некой структуры и определение роли и задачи каждого из элементов этой структуры; · мотивация – создание внутреннего побуждения членов организации к необходимым действиям; · контроль, включающий учет, направленный на получение информации о ходе работы организации, · анализ и регулирование, реализующие сопоставление фактических показателей с плановыми и определение их отклонений за допустимые пределы, установление причин отклонений, выявление резервов, нахождение путей исправление сложившейся ситуации и принятие решений по выходу из нее. Все функции управления требуют принятия решений, для всех необходимы коммуникация, обмен информацией. Принятие решений и обмен информацией, в принципе, являются основным содержанием управления вообще. В структуре любой организации можно выделить управляемые процессы - объекты управления (ОУ), и управленческий аппарат – субъекты управления [6], рисунок 1.
Рисунок 1 - Структура системы управления
Задачами субъекта управления являются: · формирование целей; · сохранение основного качества организации в условиях окружающей среды или разработка планов, обеспечивающих ее устойчивое функционирование и достижение поставленных целей; · принятие управленческих решений; · контролирование их выполнения. Задачей объекта управления является выполнение планов, выработанных управленческим аппаратом. Объект и субъект управления подвержены воздействию внешней среды. Внешняя среда – это множество существующих вне системы управления элементов любой природы, оказывающих на нее влияние через внешние воздействия, которые могут носить по отношению к ней как благоприятный, так и неблагоприятный характер. Управленческий аппарат воздействует на объект управления, передавая управленческие сигналы по каналу прямой связи. Поток отчетной информации, отражающий внутреннюю ситуацию на объекте и степень влияние на нее внешней среды, передается субъекту управления по каналам обратной связи. Обратная связь позволяет осуществлять одну из важных функций управления – контролирующую. Совокупность информационных потоков, средств обработки, передачи и хранения данных, а также сотрудников управленческого аппарата, выполняющих операции по переработке данных, составляет информационную систему управления объектом. Информационная система – человеко-машинная система, предназначенная для хранения, поиска, обработки и выдачи информации по запросам пользователя, которая может быть использована в целях управления. Важным принципом построения системы управления предприятием является рассмотрение предприятия как системы с многоуровневой (иерархической) структурой (рисунок 2). Число уровней, число подсистем каждого уровня управления может быть различным. Уровни управления менеджмента определяются сложностью решаемых задач: чем сложнее задача, тем более высокий уровень управления необходим для ее решения. Причем в организации более простых задач, требующих немедленного (оперативного) решения значительно больше, и решаются они на более низком уровне. Если рассматривать поток информации от уровня к уровню, то количество информации, выраженное в числе символов, уменьшается с повышением уровня, но при этом увеличивается ее смысловое (семантическое) содержание. Иерархия уровней управления сверху вниз: 1. стратегический (решения ответственные, долгосрочные). На высшем уровне обеспечивается стратегическое управление, определяются цели и задачи организации, ее внешняя политика, разрабатываются долгосрочные планы и стратегия их выполнения, анализируется рынок, отыскиваются альтернативные стратегии развития в случае неблагоприятных ситуаций;
Ин- Стра- Специальные фор- тегиче- информационные мация ский уро- запросы стратеги- вень управ- ческого ления управления
Тактический Информационные Информация уровень требования для тактиче- управления ского упавления
Информационные Оперативный запросы по Информация опера- уровень управления текущим тивного упарвления операциям
Рисунок 2 - Управленческая и информационная пирамиды
2. тактический. На среднем уровне составляются тактические планы, контролируется их выполнение, разрабатываются управляющие директивы, обеспечивающие достижение поставленных целей.; 3. операционный. Нижний уровень – уровень оперативного управления, на котором происходит реализация планов, составляются отчеты о ходе их выполнения, осуществляются оперативный учет и контроль. В таблице 1 приведены характеристика задач управления различных уровней и реализуемые на этих уровнях функции управления.
Таблица 1 -Типы задач уровней управления
Неструктурированной называется задача, в которой невозможно выделить отдельные элементы, математически описать связи между ними и для решения которых нет известных методов и алгоритмов. Частично структурированная задача – задача, в которой известна часть ее элементов и связей между ними. Структурированная задача – задача, в которой известны все ее элементы и взаимосвязи между ними и содержание которой можно выразить в форме математической модели, имеющей точный алгоритм решения.
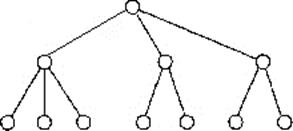
Модели данных Хранимые в базе данные имеют определенную логическую структуру - иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. М одель данных является ядром любой БД, с помощью которой могут быть представлены объекты, предметные области и взаимосвязи между ними. Модель данных – совокупность структур данных и операции их обработки. К числу классических относятся следующие модели данных: · иерархическая, · сетевая, · реляционная. Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных: · постреляционная, · объектно-ориентированная, · многомерная. Разрабатываются также всевозможные системы, основанные на других моделях данных, расширяющих известные модели. В их числе можно назвать - объектно-реляционные, - дедуктивно-объектно-ориентированные, - семантические, - концептуальные и - ориентированные модели. Некоторые из этих моделей служат для интеграции баз данных, баз знаний и языков программирования. В некоторых СУБД поддерживается одновременно несколько моделей данных. Например, в системе ИНТЕРБАЗА для приложений применяется сетевой язык манипулирования данными, а в пользовательском интерфейсе реализованы языки SQL и QBE. Иерархическая и сетевая модели данных стали применяться в системах управления БД в начале 60–х годов. В начале 70–х годов была предложена реляционная модель данных (Эдгар Кодд), которая является на сегодняшний момент самой распространенной. Основное назначение модели данных состоит в том, чтобы дать возможность представить в целом информационную картину без отвлекающих деталей, связанных с особенностями хранения. Оно является инструментом, с помощью которого разрабатывается стратегия получения любых данных, хранящихся в базе данных. 1. Иерархическая модель данных. Представляет собой совокупность элементов, связанных между собой по определенным правилам. Иерархическая модель данных строится по принципу иерархии типов объектов, то есть один тип объекта является главным, а остальные, находящиеся на низших уровнях иерархии, – подчиненными. Между главным и подчиненными объектами устанавливается взаимосвязь «один ко многим». Упрощенно представление связей между данными в иерархической модели показано на рисунке 12.
Рисунок 12 - Представление связей в иерархической модели
Основные понятия иерархической структуры: - узел (элемент) – совокупность атрибутов данных, описывающих некоторый объект (на схеме это вершины графа). Каждый узел, находящийся на более низком уровне, связан только с одним узлом, находящимся на более высоком уровне. Узел может иметь только одного родителя. Иерархическое дерево имеет только одну вершину (корень), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. - уровень; - связь. Узлы и ветви образуют иерархическую древовидную структуру. Наивысший в иерархии узел называется корневым. (это главный тип объекта). Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. Корневой узел находится на первом уровне. Зависимые узлы (подчиненные типы объектов) находятся на втором, третьем и др. уровнях. Объекты, связанные иерархическими отношениями, образуют ориентированный граф. Для описания структуры иерархической БД на некоторых языках программирования используется тип данных "дерево". Тип "дерево" является составным. Он включает в себя подтипы ("поддеревья"), каждый из которых, в свою очередь, является типом "дерево". Каждый из типов "дерево" состоит из одного "корневого" типа и упорядоченного набора (возможно пустого) подчиненных типов. Каждый из элементарных типов, включенных в тип "дерево", является простым или составным типом "запись". Простая "запись" состоит из одного типа, например, числового, а составная "запись" объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). В целом тип "дерево" представляет собой иерархически организованный набор типов "запись". Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа "дерево" (деревьев), содержащих экземпляры типа "запись" (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо. Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов: · представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры); · представление связными линейными списками (методы, использующие указатели и справочники). К основным операциям манипулирования иерархически организованными данными относятся следующие: · поиск указанного экземпляра (элемента) БД; · переход от одного дерева к другому; · переход от одной записи к другой внутри дерева (например, к следующей записи типа Сотрудники); · вставка новой записи в указанную позицию; · удаление текущей записи и т. д. В БД между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют. Достоинства: - эффективное использование памяти; - неплохие показатели временных затрат на выполнение операций; - модель удобна для работы с иерархически упорядоченной информацией, т.е. с теми данными, которые сами по себе имеют иерархическую структуру. Недостатки: - громоздкость для обработки информации с достаточно сложными логическими связями; - сложность понимания для обычного пользователя, - сложность физической реализации для больших древовидных структур. На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС. IMS (Information Management System) фирмы IBM является типичным представителем иерархической системы. Первая версия появилась в 1968 г. 2. Сетевая модель данных. Данные в сетевой модели представлены в виде коллекции записей, а связи – в виде наборов. Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рисунок 13). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).
Рисунок 13 - Представление связей в сетевой модели
Сетевая модель – это граф с записями в виде узлов графа и наборами в виде его ребер. Графы произвольной структуры отражают взаимосвязи между данными в этой модели. Для описания схемы сетевой БД используется две группы типов: "запись" и "связь". Тип "связь" определяется для двух типов "запись": предка и потомка. Переменные типа "связь" являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рисунке 14. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.
Рисунок 14 - Пример схемы сетевой БД
В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие, как элементы и агрегаты данных, записи, наборы, области и т. д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных. К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие: · поиск записи в БД; · переход от предка к первому потомку; · переход от потомка к предку; · создание новой записи; · удаление текущей записи; · обновление текущей записи; · включение записи в связь; · исключение записи из связи; · изменение связей и т. д. Достоинства сетевой модели данных: - эффективное использование затрат памяти (ресурсы) при манипулировании данными; - возможность эффективной реализации по оперативности; - большие возможности в смысле допустимости образования произвольных связей. Недостатки: - высокая сложность и жесткость схемы БД, построенной на ее основе, - сложность для понимания и выполнения обработки информации в БД обычным пользователем, - сложность физической реализации; - жесткость связи между элементами данных накладывает ряд ограничений на удобство манипуляции данными; - ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db VistaIII, СЕТЬ, СЕТОР и КОМПАС. 3. Реляционная модель данных. Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation). Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. На рисунке 15 приведен пример представления отношения СОТРУДНИК.
Рисунок 15 – Представление отношения СОТРУДНИК
Отношение представляет собой двумерную таблицу, содержащую некоторые данные. Сущность есть объект любой природы, данные о котором хранятся в БД. Данные о сущности хранятся в отношении. Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Строкам таблицы соответствуют кортежи, а столбцам - атрибуты отношения, домены, поля. Домен – общая совокупность значений, из которой берется реальное значение атрибутов. К отношениям можно применять систему операций, позволяющую получать одни отношения из других. Например, результатом запроса к реляционной БД может быть новое отношение, вычисленное на основе имеющихся отношений. Поэтому можно разделить обрабатываемые данные на хранимую и вычисляемую части. Одна таблица описывает одну конкретную сущность. Поскольку в рамках одной таблицы не удается описать сложные логические структуры данных из предметной области, применяют связывание таблиц. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. Реляционные модели характеризуются - простотой структуры данных, - удобным для пользователя табличным представлением и - возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: - все столбцы в таблице – однородные (имеют одинаковый тип); - каждый столбец имеет уникальное имя; - одинаковые строки (записи) в таблице отсутствуют; - порядок следования строк и столбцов может быть произвольным. Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица БД имеет составной ключ. Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей), в противном случае нужно ввести в структуру первой таблицы внешний ключ – ключ второй таблицы. Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов. Достоинства: - простота, понятность для пользователя, - удобство физической реализации на ЭВМ, - высокая эффективность обработки данных. Недостатки: - отсутствие стандартных средств идентификации каждой отдельной записи, - сложность описания иерархических и сетевых связей. Реляционный подход приносит относительную простоту работы разработчику информационной системы, поскольку прикладная область часто описывается в терминах таблиц достаточно естественно. Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: · dBaseIII Plus и dBase IY (фирма Ashton-Tate) · DB2 (IBM) · R:BASE (Microrim) · FoxPro ранних версий и FoxBase (Fox Software) · Paradox и dBASE for Windows (Borland) · FoxPro более поздних версий · Visual FoxPro и Access (Microsoft) · Clarion (Clarion Software) · Ingres (ASK Computer Systems) · Oracle (Oracle). К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система HyTech (МИФИ). Надо отметить, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются "чисто" реляционными. 4. Постреляционная модель данных. Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Постреляционная модель данных представляет собой расширенную реляционную модель, снимающая ограничение неделимости данных хранящихся в записях таблицы. Постреляционная модель 1) допускает вложенность полей, т.е. допускает многозначные поля - поля значение которых состоит из подзначений. Многозначными значениями полей может быть еще одна таблица, которая встроена в основную. На рисунке 16 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица НАКЛАДНЫЕ содержит данные о номерах накладных (НОИЕР НАКЛАДНОЙ) и номерах покупателей (НОМЕР ПОКУПАТЕЛЯ). В таблице НАКЛАДНЫЕ_ТОВАРЫ содержатся данные о каждой из накладных: НОМЕР НАКЛАДНОЙ, НАЗВАНИЕ ТОВАРА и КОЛИЧЕСТВО ТОВАРА. Таблица НАКЛАДНЫЕ связана с таблицей НАКЛАДНЫЕ_ТОВАРЫ по полю НОМЕР НАКЛАДНОЙ.
а) НАКЛАДНЫЕ
НАКЛАДНЫЕ_ТОВАРЫ
б) НАКЛАДНЫЕ
Рисунок 16 - Структуры данных реляционной и постреляционной моделей
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц; 2) поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.; 3) не накладывает требования постоянства на длину полей и количество полей в записях таблицы, поддерживая этим гибкую структуру данных и таблиц. Так как постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах. Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. Достоинства постреляционной модели: - возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей, - обеспечение высокой наглядности представления информации, - обеспечение повышенной эффективности обработки информации. Недостаток: трудоемкий сложный процесс обеспечения целостности и непротиворечивости данных, которые хранятся в базе данных. Постреляционная модель данных поддерживается СУБД uniVers, системами Bubba и Dasdb 5. Многомерная модель. Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. С середины 90-х годов интерес к ним стал приобретать массовый характер. Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э. Кодда. В ней сформулированы 12 основных требований к системам класса OLAP (Online Analytical Processing - оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения. В развитии концепций ИС можно выделить следующие два направления: · системы оперативной (транзакционной) обработки. Транзакция - последовательность операций пользователя над БД, которая сохраняет ее логическую целостность; · системы аналитической обработки (системы поддержки принятия решений). Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области были весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (МСУБД). Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: - агрегируемость данных - означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель; - историчность данных предполагает: o обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей. Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки; o обязательность привязки данных ко времени. Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются; - прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам. Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рисунке 17 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей. а)
б)
Рисунок 17 - Реляционное и многомерное представление данных
Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пример трехмерного гиперкуба приведен на рисунке 18. Пользователю и в этих случаях более удобно иметь дело с двухмерными таблицами или графиками. Данные при этом представляют собой "вырезки" (точнее, "срезы") из многомерного хранилища данных, выполненные с разной степенью детализации.
Рисунок 18 – Представление данных в виде гиперкуба
Основные понятия многомерных моделей данных: · измерение (Dimension) - это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы и Годы. В качестве географических измерений широко употребляются Города, Районы, Регионы и Страны. В многомерной модели данных измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба; · ячейка (Cell) или показатель - это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, обычно она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам). В примере на рисунке 17 (б) каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения (Месяц продаж) и Модели автомобиля. На практике зачастую требуется большее количество измерений. Пример трехмерной модели данных приведен на рисунке 19.
Рисунок 19 - Трехмерная модель представления данных
В существующих МСУБД используются два основных варианта (схемы) организации данных: · гиперкубическая. В случае гиперкубической схемы предполагается, что все показатели определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов БД все они имеют одинаковую размерность и совпадающие измерения. Очевидно, в некоторых случаях информация в БД может быть избыточной (если требовать обязательное заполнение ячеек); · поликубическая. В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server. В случае многомерной модели данных применяется ряд специальных операций, к которым относятся: формирование "среза", "вращение", агрегация и детализация: · формирование "среза" (Slice). "Срез" представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование "срезов" выполняется для ограничения исп<
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 506; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.148 (0.02 с.) |