Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели данных: реляционная, иерархическая, сетеваяСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Понятие «данные» в концепции БД – это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Модель данных – совокупность взаимосвязанных структур данных и операций над этими структурами. Вид модели и используемые в ней типы структур данных отражают концепцию организации и обработки данных, используемую в СУБД, поддерживающей модель, или в языке системы программирования, на котором создается прикладная программа обработки данных. Выбор модели данных возлагается на пользователя, создающего информационную базу, и зависит от многих факторов, в том числе от имеющегося технического и программного обеспечения, определяется сложностью автоматизируемых задач и объемом информации.
В пособии мы будем останавливаться только на трех моделях данных: иерархической, сетевой и реляционной. а) Иерархическая модель данных. Относится к теоретико-графовым моделям данных, которые отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Является наиболее простой среди всех даталогических моделей. Основными информационными единицами в иерархической модели являются: база данных, сегмент и поле. Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента, или тип записи, и экземпляр сегмента, или экземпляр записи. Тип сегмента – это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающий сотрудника организации, мы должны выделить те характеристики сотрудника, которые могут однозначно его идентифицировать в рамках БД предприятия. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической БД. Каждая физическая БД удовлетворяет следующим иерархическим ограничениям: 1. в каждой физической БД существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента; 2. каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов; 3. каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским) сегментом.
В иерархической модели непосредственный доступ по ключу, как правило, возможен только к объекту высшего уровня, который не подчинен другим объектам. К другим объектам доступ осуществляется по связям от объекта на вершине модели. Структура объекта (поля, сегмента) может быть иерархической (в виде древа) или линейной. Рассмотрим пример иерархической БД. Допустим, что наша организация занимается производством и продажей компьютеров, в рамках производства мы комплектуем компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько базовых моделей, которые мы продаем без предварительных заказов по наличию на складе. В организации существуют несколько филиалов и несколько складов, на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции. Какие задачи нам надо решать в ходе разработки приложения? · При приеме заказа мы должны выяснить, какую модель заказывает заказчик: типичную или индивидуальную комплектацию. · Если заказывается типичная модель, то выясняется, какая модель и есть ли она в наличии, если модель есть, то надо уменьшить количество компьютеров данной модели в данном филиале на покупаемое количество. На этом будем считать заказ выполненным, однако при оформлении заказа может потребоваться задание полной спецификации покупаемого изделия. · Если заказывается индивидуальная модель, то требуется описать весь состав новой модели (рис. 1.3.). ·
Рис. 1.3. Состав модели
Для того чтобы можно было принимать заказы на индивидуальные модели, нам понадобится информация о наличии конкретных деталей на складе, в этом случае нам необходимо второе дерево – Склады (см. рис. 1.4). Для доступа к БД у пользователя должна быть сформирована специальная среда окружения, поддерживающая в явном виде имеющиеся навигационные операции. Для этого в ней должны храниться: 1. шаблоны всех записей логических БД, доступных пользователю; 2. указатели на текущий экземпляр сегмента данного типа – для всех видов сегментов. Язык манипулирования данными в иерархической модели поддерживает в явном виде навигационные операции. Эти операции связаны с перемещением указателя, который определяет текущий экземпляр конкретного сегмента.
Рис. 1.4. Дерево базы данных Склады
Все операторы в языке манипулирования данными можно разделить на три группы: 1. операторы поиска данных; 2. операторы поиска данных с возможностью модификации; 3. операторы модификации данных. б) Сетевая модель данных. Относится к теоретико-графовым моделям данных, которые отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Базовыми объектами модели являются: элемент данных, агрегат данных, запись, набор данных. Элемент данных – минимальная информационная единица, доступная пользователю с использованием СУБД. Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа. Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа вектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом:
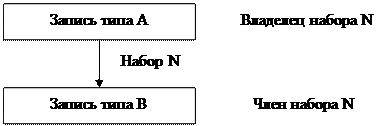
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию «сегмент» в иерархической модели. Для записи, так же, как и для сегмента, вводятся понятия типа записи и экземпляра записи. Набором называется двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи – членом того же набора. Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение «многие-ко-многим» между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора. В сетевых моделях непосредственный доступ по ключу может обеспечиваться к любому объекту независимо от уровня, на котором он находится в модели. Возможен также доступ по связям от любой точки доступа. Все операции манипулирования данными в сетевой модели делятся на навигационные операции и операции модификации. Навигационные операции осуществляют перемещение по БД путем прохождения по связям, которые поддерживаются в схеме БД. В этом случае результатом является новый единичный объект, который получает статус текущего объекта. Операции модификации осуществляют как добавление новых экземпляров отдельных типов записей, так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию отдельных составляющих внутри конкретных экземпляров записей.
в) Реляционная модель данных. Появление теоретико-множественных моделей в системах БД было предопределено настоятельной потребностью пользователей в переходе от работы с элементами данных, как это делается в графовых моделях, к работе с некоторыми макрообъектами. Основной моделью в этом классе является реляционная модель данных. Эта модель данных является совокупностью простейших двумерных таблиц – отношений, именно поэтому модель получила название реляционной (от англ. «relation» – отношение). Реляционная модель представляет базу данных в виде множества взаимосвязанных отношений. Таблица является основным типом структуры данных (объектом) реляционной модели. Структура таблицы определяется совокупностью столбцов. В каждой строке таблицы содержится по одному значению в соответствующем столбце. В таблице не может быть двух одинаковых строк. Общее число строк не ограничено. Столбец соответствует некоторому элементу данных – атрибуту, который является простейшей структурой данных. В таблице на могут быть определены множественные элементы, группа или повторяющаяся группа, как в рассмотренных выше сетевых и иерархических моделях. Каждый столбец таблицы должен иметь имя соответствующего элемента данных (атрибута). Один или несколько атрибутов, значения которых однозначно идентифицируют строку таблицы, являются ключом таблицы. В реляционном подходе к построению БД используется терминология теории отношений. Простейшая двумерная таблица определяется как отношение. Столбец таблицы со значениями соответствующего атрибута называется доменом, а строки со значениями разных атрибутов – кортежем. В этой модели, так же, как и в остальных, поддерживаются иерархические связи между отношениями. В каждой связи одно отношение может выступать как основное, а другое отношение выступает в роли подчиненного. Это означает, что один кортеж основного отношения может быть связан с несколькими кортежами подчиненного отношения. Для поддержки этих связей оба отношения должны содержать наборы атрибутов, по которым они связаны. В основном отношении это первичный ключ отношения (Primary key), который однозначно определяет кортеж основного отношения. В подчиненном отношении для моделирования связи должен присутствовать набор атрибутов, соответствующий первичному ключу основного отношения. Однако здесь этот набор атрибутов уже является вторичным ключом, то есть он определяет множество кортежей подчиненного отношения, которые связаны с единственным кортежем основного отношения. Данный набор атрибутов в подчиненном отношении принято называть внешним ключом (Foreign key). Операции обработки данных включают операции над строками (кортежами) таблиц (отношений) и операции над отношениями, осуществляющие обработку данных нескольких отношений. Операциями, выполняемыми на уровне строк отношений, являются: · включение – добавляет в таблицу новую строку; · удаление – удаляет из таблицы строку; · обновление – осуществляет изменение значений атрибутов в строках. Основными операциями над отношениями реляционной модели данных являются традиционные операции над множествами: · Объединение – выполняется над двумя совместимыми отношениями R1 и R2. В результате операции объединения строится новое отношение R=R1 U R2. Отношение R имеет тот же состав атрибутов и совокупность кортежей исходных отношений. Причем в эту совокупность не включаются дубликаты. Пример: Таблица R1:
Таблица R2:
Таблица R:
В новое отношение R не вошел кортеж К22, так как он дублирует кортеж К11. · Пересечение – операция выполняется над двумя совместимыми отношениями R1 и R2. Результирующее отношение RP=R1ÇR2 содержит одинаковые кортежи, которые есть в каждом из двух исходных. Для таблиц из примера:
· Вычитание – операция выполняется над двумя совместимыми отношениями R1, R2 с идентичным набором атрибутов. В результате операции вычитания строится новое отношение RV = R1 - R2 с идентичным набором атрибутов, содержащее только те кортежи первого отношения R1, которые не повторяются во втором отношении R2. Для таблиц из примера:
· Декартово произведение – операция выполняется над двумя отношениями R1 и R2, имеющими в общем случае разный состав атрибутов. В результате операции образуется новое соотношение RD=R1*R2, которое включает все атрибуты исходных отношений. Число кортежей декартова произведения равно произведению количеств кортежей в исходных отношениях. · Выбор – операция выполняется над одним отношением R. Для отношения R по заданному условию (предикату) осуществляется выборка подмножества кортежей. Результирующее отношение имеет ту же структуру, но число его кортежей будет меньше (или равно) исходному. · Проекция – операция выполняется над одним отношением R. Операция проекции формирует новое отношение (RPR) с заданным подмножеством атрибутов и последовательностью исходного отношения R. Оно может содержать меньше кортежей, так как после отбрасывания в исходном отношении R части атрибутов могут образоваться кортежи, дублирующие друг друга. Дублирующие кортежи из результирующего отношения исключаются. · Соединение – выполняется для заданного условия соединения над двумя логически связанными отношениями. Исходные отношения R1 и R2 имеют разные структуры, в которых есть одинаковые атрибуты – внешние ключи. Операция соединения формирует новое отношение, структура которого является совокупностью всех атрибутов исходных отношений. Результирующие кортежи формируются объединением каждого кортежа из R1 с теми кортежами R2, для которых выполняется условие. · Деление – операция выполняется над двумя отношениями R1 и R2, имеющими в общем случае разные структуры и некоторые одинаковые атрибуты. В результате операции образуется новое отношение, структура которого получается исключением из множества атрибутов отношения R1 множества атрибутов отношения R2. Результирующие строки не должны содержать дубликаты. Рассмотренные выше операции в той или иной мере реализуются в средствах СУБД, обеспечивающих обработку реляционных таблиц. К таким средствам относятся средства запросов и другие языковые конструкции. Развитие реляционного подхода привело к созданию реляционных языков. Например, язык SQL, реализованный в большинстве СУБД, является более чем реляционно-полным, так как, кроме операций реляционной алгебры, он содержит полный набор операторов над строками – «включить», «удалить» и «обновить», а также реализует арифметические операции и операции сравнения. Рассматриваемая в последующих главах СУБД Microsoft Access является примером системы управления реляционными базами данных.
Понятие отношения В реляционных базах данных отношения (межтабличные связи) позволяют не создавать избыточные данные. Существуют отношения трех типов. Тип отношения в создаваемой связи зависит от способа определения связываемых столбцов: · при отношении «один-к-одному» каждой записи ключевого поля в первой таблице соответствует только одна запись в связанном поле другой таблицы и наоборот (большинство данных, связанных таким образом, может быть помещено в одну общую таблицу). Отношения этого типа используются не очень часто. Иногда его можно использовать для разделения таблиц, содержащих много полей, для отделения части таблицы по соображениям безопасности, а также для выделения сведений, относящихся к подмножеству записей в главной таблице; · чаще всего используется отношение «один-ко-многим». Оно означает, что одной записи в первой таблице соответствует несколько записей во второй, но запись во второй таблице не может иметь больше одной связанной записи в первой таблице, то есть на стороне «один» должно выступать ключевое поле, содержащее уникальные, неповторяющиеся значения, а значения на стороне «многие» могут повторяться. Например, одно издательство может выпустить несколько книг, но одну книгу может выпустить только одно конкретное издательство; · отношение «многие-ко-многим» означает, что одной записи в первой таблице могут соответствовать несколько записей во второй таблице, а одной записи во второй таблице могут соответствовать несколько записей в первой. Такое отношение содержит в себе неопределенность, разрешить которую можно только с помощью третьей (связующей) таблицы. Первичный ключ связующей таблицы состоит из двух полей, которые являются внешними ключами первой и второй таблиц. Можно сказать, что отношение «многие-ко-многим» представляет собой два отношения «один-ко-многим» с третьей таблицей. Например, каждый автор может написать несколько книг, а каждая книга может иметь несколько авторов, но авторский коллектив каждой книги уникален, так же, как и список книг, написанных конкретным автором.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 856; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.184.236 (0.011 с.) |






 Стоимость
Стоимость
 Количество на складе
Количество на складе