Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели данных. Концептуальная (инфологическая) модель. ER-диаграммы.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Вопрос 1 В настоящее время понятие информация одно из самых употребляемых в науке, технике и других сферах жизни. Точного определения термина, как и многих подобных, дать видимо нельзя. Но дать понятие информации можно и нужно.
Также выделяют разные подвиды информации. Для нашей дисциплины важно выделить такой подвид информации, как данные. Чем, например, данные отличаются от знаний? Или чем данные отличаются от информационного шума? Точное определение и здесь видимо невозможно. Попробуем назвать некоторые свойства, некоторые качества, которые отличают данные от других категорий информации. Рассмотрим, например, обыкновенный текстовый файл данных Книги.txt, в котором хранится список литературы:
Конечно мы, основываясь на собственном опыте, сразу понимаем, что это не информационный шум, а данные. Но как мы это делаем? И как это может сделать, например, компьютер, компьютерная программа? В частности, здесь присутствует код, кодировка, язык. То есть, кроме самой информации известен ещё язык, код, формат, способ её кодирования. В нашем примере, это формат txt, т.е. использован стандартный код ASCII или подобный ему. Если приложение «знает» этот код, то оно может: · верно отобразить текст для человека · редактировать его · осуществлять поиск нужной подстроки · осуществлять позиционирование на нужном месте · перекодировать текст в другой формат и т.п. То есть, осуществлять обработку данных на основе формальных алгоритмов. Для шума отсутствует или неизвестен язык, код, на котором представлена информация. Новые и очень важные качества появляются у данных, если они хранятся не в виде файла, а в виде базы данных. Представим наши данные из файла в виде простейшей базы данных, например, в виде таблицы:
Рисунок 1База данных (пример): Теперь данные структурированы. Однотипные данные объединены и снабжены метаданными. Метаданные это данные, поясняющие исходные данные. Например, все названия книг собраны в одно подмножество (один столбец) и снабжены метаданным «Название». При такой организации данных мы в состоянии написать приложение, которое позволит выполнять запросы к данным, которые невозможно выполнить, если мы имеем данные, организованные лишь в виде обычного файла. Например, возможны следующие запросы невыполнимые в файле: · выдать полную информацию про книги автор, которых Джексон Г. · выдать список всех авторов книг · выдать все книги издательства «Мир», выпущенные после 1992 года · и т.д. Выполнение таких запросов невозможно в принципе при использовании простого файла данных. Самое изощрённое приложение не сможет найти где начинается и заканчивается, например, название книги. Если же мы будем, например, использовать специальные метки в файле, которые разграничивают отдельные разные атрибуты книги, то это уже организация характерная для баз данных. Теперь мы можем дать рабочее определение для базы данных:
Специальные приложения, которые управляют и обслуживают базы данных наз. Системами управления базами данных (СУБД):
Различают локальные и распределённые СУБД. Первые могут работать только на одном компьютере. Вторые обычно работают в компьютерных сетях. При этом возможно ведение нескольких копий одной и той же базы, которые называются реплики.
Различают также: однопользовательские и многопользовательские СУБД. Первые могут работать одномоментно только с одним пользователем. Вторые могут одновременно обслуживать сразу несколько пользователей. Модели данных. Концептуальная (инфологическая) модель. ER-диаграммы. Модели данных В процессе проектирования необходимо пройти три уровня моделирования данных.
Рисунок 2 уровни моделей данных Логическая модель. Виды логических моделей. Логическая (даталогическая) модель. Виды логических моделей: иерархические, сетевые, модели на основе инвертированных список, реляционные, постреляционные, объектно-ориентированные. Логические (даталогические) модели данных Типы даталогических моделей:
Иерархические модели • Сначала стали использовать иерархические модели. • Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. • Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности. Иерархические модели Структуры данных
Рисунок 7 структура данных иерархической модели
Рисунок 8 Фрагмент базы вместе с данными Манипулирование данными Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие: • Найти указанное дерево БД (например, отдел 310); • Перейти от одного дерева к другому; • Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику); • Перейти от одной записи к другой в порядке обхода иерархии; • Вставить новую запись в указанную позицию; • Удалить текущую запись. Ограничения целостности Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Сетевые модели • Также создавались для мало ресурсных ЭВМ. • При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п.
• Один из разработчиков операционной системы UNIX сказал "Сетевая база – это самый верный способ потерять данные". Структуры данных Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи.
Рисунок 9 Структура семантических сетей Манипулирование данными Примерный набор операций может быть следующим: • Найти конкретную запись в наборе однотипных записей (инженера Сидорова); • Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310); • Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову); • Перейти от потомка к предку по некоторой связи (найти отдел Сидорова); • Создать новую запись; • Уничтожить запись; • Модифицировать запись; • Включить в связь; • Исключить из связи; • Переставить в другую связь и т.д. Манипулирование данными Поддерживаются два класса операторов: 1)Операторы, устанавливающие и возвращающие адрес записи, среди которых: • прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа); • операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа. 2)Операторы над адресуемыми записями (например, обновить запись с указанным адресом; удалить запись с указанным адресом; включить запись в указанную таблицу, операция генерирует адрес записи). Ограничения целостности Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Объектно-ориентированная база данных (ООБД) (взял с вики.. в лекциях нету) — база данных, в которой данные моделируются в виде объектов,их атрибутов, методов и классов Характеристики
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
В манифесте ООБД предлагаются обязательные характеристики, которым должна отвечать любая ООБД. Их выбор основан на 2 критериях: система должна быть объектно-ориентированной и представлять собой базу данных.
Обязательные характеристики · Поддержка сложных объектов. В системе должна быть предусмотрена возможность создания составных объектов за счет применения конструкторов составных объектов. Необходимо, чтобы конструкторы объектов были ортогональны, то есть любой конструктор можно было применять к любому объекту. · Поддержка индивидуальности объектов. Все объекты должны иметь уникальный идентификатор, который не зависит от значений их атрибутов. · Поддержка инкапсуляции. Корректная инкапсуляция достигается за счет того, что программисты обладают правом доступа только к спецификации интерфейса методов, а данные и реализация методов скрыты внутри объектов. · Поддержка типов и классов. Требуется, чтобы в ООБД поддерживалась хотя бы одна концепция различия между типами и классами. (Термин «тип» более соответствует понятию абстрактного типа данных. В языках программирования переменная объявляется с указанием ее типа. Компилятор может использовать эту информацию для проверки выполняемых с переменной операций на совместимость с ее типом, что позволяет гарантировать корректность программного обеспечения. С другой стороны класс является неким шаблоном для создания объектов и предоставляет методы, которые могут применяться к этим объектам. Таким образом, понятие «класс» в большей степени относится ко времени исполнения, чем ко времени компиляции.) · Поддержка наследования типов и классов от их предков. Подтип, или подкласс, должен наследовать атрибуты и методы от его супертипа, или суперкласса, соответственно. · Перегрузка в сочетании с полным связыванием. Методы должны применяться к объектам разных типов. Реализация метода должна зависеть от типа объектов, к которым данный метод применяется. Для обеспечения этой функциональности связывание имен методов в системе не должно выполняться до времени выполнения программы. · Вычислительная полнота. Язык манипулирования данными должен быть языком программирования общего назначения. · Набор типов данных должен быть расширяемым. Пользователь должен иметь средства создания новых типов данных на основе набора предопределенных системных типов. Более того, между способами использования системных и пользовательских типов данных не должно быть никаких различий.
Необязательные характеристики: · Множественное наследование · Проверка типов · Распределение · Проектные транзакции
Открытые характеристики: · Парадигмы программирования (процедурное, декларативное) · Система представления · Система типов · Однородность. Реализация — язык программирования — интерфейс. ООБД и её СУБД
Результатом совмещения возможностей (особенностей) баз данных и возможностей объектно-ориентированных языков программирования являются Объектно-ориентированные системы управления базами данных (ООСУБД). ООСУБД позволяет работать с объектами баз данных так же, как с объектами в программировании в ООЯП. ООСУБД расширяет языки программирования, прозрачно вводя долговременные данные, управление параллелизмом, восстановление данных, ассоциированные запросы и другие возможности.
Некоторые объектно-ориентированные базы данных разработаны для плотного взаимодействия с такими объектно-ориентированными языками программирования как Python, Java, C#, Visual Basic.NET, C++, Objective-C и Smalltalk; другие имеют свои собственные языки программирования. ООСУБД используют точно такую же модель, что и объектно-ориентированные языки программирования.
СУБД должна обеспечивать: · Долговременное хранение · Использование внешней памяти · Параллелизм · Восстановление · Нерегламентированные запросы Вопрос 2 Строгое определение понятия "ключ"
Каждое отношение обладает хотя бы одним возможным ключом, поскольку по меньшей мере комбинация всех его атрибутов удовлетворяет условию уникальности. Один из возможных ключей (выбранный произвольным образом) принимается за его первичный ключ. Остальные возможные ключи, если они есть, называются альтернативными ключами. Выбор первичного ключа: Пример 1: Студент (Номер зачетной книжки, Фамилия, Имя, Отчество, Группа, Пол, Дата рождения, Адрес, …)
Пример 2: Блюдо (Номер блюда, Название, Вид, …)
Название = «Заяц в сметанном соусе с картофельными крокетами и салатом из красной капусты»
Целостность Что понимают под целостностью данных в базах данных? Это не тоже самое, что безопасность или надежность хранения данных в БД.
Целостность обеспечивается СУБД за счёт того, что задаются и автоматически поддерживаются правила целостности. Часто эти правила называют - ограничения целостности. Так как СУБД ограничивает действия, которые можно выполнять с данными, запрещая действия приводящие к нарушению согласованности данных.
Все правила целостности для удобства разбивают на виды или группы:
2. Целостность по ссылкам. Внешние ключи
Вопрос 1 В настоящее время понятие информация одно из самых употребляемых в науке, технике и других сферах жизни. Точного определения термина, как и многих подобных, дать видимо нельзя. Но дать понятие информации можно и нужно.
Также выделяют разные подвиды информации. Для нашей дисциплины важно выделить такой подвид информации, как данные. Чем, например, данные отличаются от знаний? Или чем данные отличаются от информационного шума? Точное определение и здесь видимо невозможно. Попробуем назвать некоторые свойства, некоторые качества, которые отличают данные от других категорий информации. Рассмотрим, например, обыкновенный текстовый файл данных Книги.txt, в котором хранится список литературы:
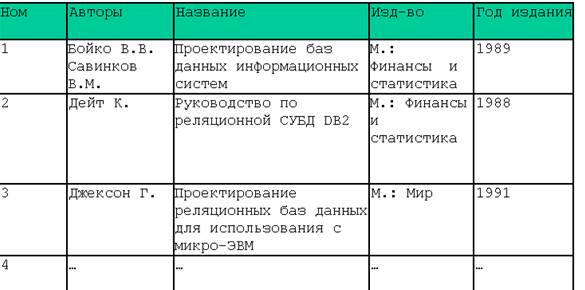
Конечно мы, основываясь на собственном опыте, сразу понимаем, что это не информационный шум, а данные. Но как мы это делаем? И как это может сделать, например, компьютер, компьютерная программа? В частности, здесь присутствует код, кодировка, язык. То есть, кроме самой информации известен ещё язык, код, формат, способ её кодирования. В нашем примере, это формат txt, т.е. использован стандартный код ASCII или подобный ему. Если приложение «знает» этот код, то оно может: · верно отобразить текст для человека · редактировать его · осуществлять поиск нужной подстроки · осуществлять позиционирование на нужном месте · перекодировать текст в другой формат и т.п. То есть, осуществлять обработку данных на основе формальных алгоритмов. Для шума отсутствует или неизвестен язык, код, на котором представлена информация. Новые и очень важные качества появляются у данных, если они хранятся не в виде файла, а в виде базы данных. Представим наши данные из файла в виде простейшей базы данных, например, в виде таблицы:
Рисунок 1База данных (пример): Теперь данные структурированы. Однотипные данные объединены и снабжены метаданными. Метаданные это данные, поясняющие исходные данные. Например, все названия книг собраны в одно подмножество (один столбец) и снабжены метаданным «Название». При такой организации данных мы в состоянии написать приложение, которое позволит выполнять запросы к данным, которые невозможно выполнить, если мы имеем данные, организованные лишь в виде обычного файла. Например, возможны следующие запросы невыполнимые в файле: · выдать полную информацию про книги автор, которых Джексон Г. · выдать список всех авторов книг · выдать все книги издательства «Мир», выпущенные после 1992 года · и т.д. Выполнение таких запросов невозможно в принципе при использовании простого файла данных. Самое изощрённое приложение не сможет найти где начинается и заканчивается, например, название книги. Если же мы будем, например, использовать специальные метки в файле, которые разграничивают отдельные разные атрибуты книги, то это уже организация характерная для баз данных. Теперь мы можем дать рабочее определение для базы данных:
Специальные приложения, которые управляют и обслуживают базы данных наз. Системами управления базами данных (СУБД):
Различают локальные и распределённые СУБД. Первые могут работать только на одном компьютере. Вторые обычно работают в компьютерных сетях. При этом возможно ведение нескольких копий одной и той же базы, которые называются реплики.
Различают также: однопользовательские и многопользовательские СУБД. Первые могут работать одномоментно только с одним пользователем. Вторые могут одновременно обслуживать сразу несколько пользователей. Модели данных. Концептуальная (инфологическая) модель. ER-диаграммы. Модели данных В процессе проектирования необходимо пройти три уровня моделирования данных.
Рисунок 2 уровни моделей данных
|
||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 703; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.21.12.41 (0.009 с.) |