Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Нормализация данных. Функциональные и многозначные зависимости.Содержание книги
Поиск на нашем сайте Лабораторная работа 1 Тема: Основные типы моделей данных. Реляционная модель данных. Нормализация данных. Цель работы: Провести анализ предметной области, разработать структуру БД, основываясь на понятиях нормализации таблиц, понятиях структурной и информационной целостности и избыточности. Теоретические основы. ОСНОВНЫЕ ТИПЫ МОДЕЛЕЙ ДАННЫХ Системы управления файлами Простейшая база данных организована в виде набора обычных файлов. Эта модель напоминает картотечную организацию документов, при которой папки хранятся в ящиках, а в каждой папке подшито некоторое число страниц. Системы управления файлами нельзя классифицировать как СУБД, так как обычно они являются частью операционной систем и ничего не знают о внутреннем содержимом файлов. Это знание заложено в прикладных программах, работающих с файлами. Вся информация о полях таблиц закодирована в приложении. Другое приложение, обращающееся к тому же файлу, вынуждено дублировать существующий код. По мере увеличения числа приложений растет сложность управления базой данных. Изменения схемы данных приводят к необходимости изменения каждого программного компонента, для которого это актуально. Формирование новых запросов занимает столько времени, что зачастую теряет всякий смысл. Системы управления файлами не могут помешать дублированию информации. Хуже того, не существует механизмов, предотвращающих несогласованность данных. Представьте себе файл, содержащий сведения обо всех служащих компании. В каждой строке есть поле, где записано имя начальника. Под руководством одного начальника работает много служащих, поэтому его имя будет неизбежно повторяться. Если где-то это имя будет записано неправильно, формально получится, что у служащего другой начальник. При замене начальника его имя придется "вылавливать" по всей базе данных. Безопасность обычных файлов контролируется операционной системой. Отдельный файл может быть заблокирован для просмотра или модификации со стороны того или иного пользователя, но это выполняется только на уровне операционной системы. В конкретный момент времени лишь одно приложение может осуществлять запись в файл, что снижает общую производительность. Иерархические базы данных Иерархические базы данных поддерживают древовидную организацию информации. Связи между записями выражаются в виде отношений предок/потомок, а у каждой записи есть ровно одна родительская запись. Это помогает поддерживать ссылочную целостность. Когда запись удаляется из дерева, все ее потомки также должны быть удалены. Иерархические базы данных имеют централизованную структуру, т.е. безопасность данных легко контролировать. К сожалению, определенные знания о физическом порядке хранения записей все же необходимы, так как отношения предок/потомок реализуются в виде физических указателей из одной записи на другую. Это означает, что поиск записи осуществляется методом прямого обхода дерева. Записи, расположенные в одной половине дерева, ищутся быстрее, чем в другой. Отсюда следует необходимость правильно упорядочивать записи, чтобы время их поиска было минимальным. Это трудно, так как не все отношения, существующие в реальном мире, можно выразить в иерархической базе данных. Отношения "один ко многим" являются естественными, но практически невозможно описать отношения "многие ко многим" или ситуации, когда запись имеет несколько предков. До тех пор пока в приложениях будут кодироваться сведения о физической структуре данных, любые изменения этой структуры будут грозить перекомпиляцией. Сетевые базы данных Сетевая модель расширяет иерархическую модель, позволяя группировать связи между записями в множества. С логической точки зрения связь — это не сама запись. Связи лишь выражают отношения между записями. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование. Следуя спецификации CODASYL, сетевая модель поддерживает DDL (Data Definition Language— язык определения данных) и DML (Data Manipulation Language — язык обработки данных). Это специальные языки, предназначенные для определения структуры базы данных и составления запросов. Несмотря на их наличие программист по-прежнему должен знать структуру базы данных. В сетевой модели допускаются отношения "многие ко многим", а записи не зависят друг от друга. При удалении записи удаляются и все ее связи, но не сами связанные записи. В сетевой модели требуется, чтобы связи устанавливались между существующими записями во избежание дублирования и искажения целостности. Данные можно изолировать в соответствующих таблицах и связать с записями в других таблицах. Программисту не нужно заботиться о том, как организуется физическое хранение данных на диске. Это ослабляет зависимость приложений и данных. Но в сетевой модели требуется, чтобы программист помнил структуру данных при формировании запросов. Оптимальную структуру базы данных сложно сформировать, а готовую структуру трудно менять. Если вид таблицы претерпевает изменения, все отношения с другими таблицами должны быть установлены заново, чтобы не нарушилась целостность данных. Сложность подобной задачи приводит к тому, что программисты зачастую отменяют некоторые ограничения целостности ради упрощения приложений. Реляционные базы данных В сравнении с рассмотренными выше моделями реляционная модель требует от СУБД гораздо более высокого уровня сложности. В реляционной модели база данных представляет собой централизованное хранилище таблиц, обеспечивающее безопасный одновременный доступ к информации со стороны многих пользователей. В строках таблиц часть полей содержит данные, относящиеся непосредственно к записи, а часть — ссылки на записи других таблиц. Таким образом, связи между записями являются неотъемлемым свойством реляционной модели. Каждая запись таблицы имеет одинаковую структуру. Например, в таблице, содержащей описания автомобилей, у всех записей будет один и тот же набор полей: производитель, модель, год выпуска, пробег и т.д. Такие таблицы легко изображать в графическом виде. В реляционной модели достигается информационная и структурная независимость. Записи не связаны между собой настолько, чтобы изменение одной из них затронуло остальные, а изменение структуры базы данных не обязательно приводит к перекомпиляции работающих с ней приложений. В реляционных СУБД применяется язык SQL, позволяющий формулировать произвольные, нерегламентированные запросы. Это язык четвертого поколения, поэтому любой пользователь может быстро научиться составлять запросы. К тому же, существует множество приложений, позволяющих строить логические схемы запросов в графическом виде. Все это происходит за счет ужесточения требований к производительности компьютеров. К счастью, современные вычислительные мощности более чем адекватны. Реляционные базы данных страдают от различий в реализации языка SQL, хотя это и не проблема реляционной модели. Каждая реляционная СУБД реализует какое-то подмножество стандарта SQL плюс набор уникальных команд, что усложняет задачу программистам, пытающимся перейти от одной СУБД к другой. Приходится делать нелегкий выбор между максимальной переносимостью и максимальной производительностью. В первом случае нужно придерживаться минимального общего набора команд, поддерживаемых в каждой СУБД. Во втором случае программист просто сосредоточивается на работе в данной конкретной СУБД, используя преимущества ее уникальных команд и функций. Таблицы, строки и столбцы Реляционная модель скрывает детали физического хранения данных. Вся работа ведется на логическом уровне. Так легче выявлять отношения, существующие между элементами данных. Реляционная база данных состоит из таблиц. Можно провести аналогию между базой данных и ящиком картотеки. Таблица в этом случае будет папкой, лежащей в ящике. В MySQL таблице соответствуют три файла на диске, но это имеет значение только тогда, когда приходится заниматься администрированием системы на низком уровне. Доктор Кодд подчеркивал важность освобождения пользователей базы данных от знания особенностей ее физической реализации. Таблица состоит из строк (записей) и столбцов (полей). В столбце хранятся соответствующие значения каждой строки; каких либо "пропусков" или коротких столбцов быть не может. Запись является отдельной сущностью, а поля представляют собой атрибуты записей. Доктор Кодд называл таблицы отношениями, поскольку каждая строка таблицы неявно связана со всеми остальными строками, разделяя с ними общую форму записи. Собственно запись называется кортежем, т.е. набором взаимосвязанных атрибутов. Первичным ключом является значение уникальным образом идентифицирующее каждую строку. Внешний ключ – ключ, значение которого берется из внешней таблицы. Повторять значения первичного ключа нежелательно, поскольку это прямой путь к нарушению целостности. В большинстве реляционных СУБД есть средства контроля внешних столбцов, позволяющие гарантировать занесение в них "правильных" значений. Столбец можно назначить внешним ключом, но MySQL не будет проверять, совпадают ли его значения со значениями указанного первичного ключа. Подобная задача возлагается на приложения. Если СУБД обеспечивает проверку внешних ключей, то она не позволит создавать записи с неправильными значениями внешнего ключа. Возможно также каскадное удаление записей. Например, удаление строки из таблицы может привести к удалению всех записей других таблиц, в которых внешний ключ равен ее первичному ключу. Планируется, что такая функция в скором времени появится и в MySQL. Пока что речь шла только о первичных и внешних ключах. Но помимо них есть еще несколько типов ключей. Суперключ— это совокупность атрибутов, уникальным образом идентифицирующих каждую запись. Ключ-кандидат— это минимальный суперключ. Например, ключ, объединяющий столбцы "Фамилия", "Дата рождения" и т.д, не является кандидатом, поскольку первых двух столбцов достаточно, чтобы идентифицировать каждую запись. Таким образом, первичный ключ представляет собой ключ-кандидат, выбранный для идентификации записей таблицы. У каждой таблицы есть концептуальный набор суперключей. Их подмножеством являются ключи-кандидаты, и только один из кандидатов может стать первичным ключом. Реляционная модель не допускает, чтобы какой-либо атрибут первичного ключа был пустым, поэтому в нашем случае наилучший первичный ключ — столбцы "Фамилия" и "Дата рождения". Первичный ключ является важным средством обеспечения целостности данных. MySQL не допустит, чтобы две записи имели одинаковые значения в столбцах первичного ключа. Когда столбец или группа столбцов помечается как ключ, дополнительно создается индекс. Индекс хранит список значений ключа и указатели на записи, содержащие эти значения. Наличие индекса позволяет СУБД быстро находить нужные записи. В целом индексы ускоряют выполнение операций чтения, но замедляют выполнение операций записи. Это объясняется тем, что при добавлении строк в таблицу или обновлении ключевых столбцов необходимо обновлять индекс. В реляционной модели все ключи, кроме первичного, считаются вторичными. Они используются для ускорения запросов. Внешний ключ является вторичным ключом, который соответствует первичному ключу другой таблицы. Отношения Между таблицами могут существовать отношения трех типов: "один ко многим", "один к одному" и "многие ко многим". Только первый из них необходим для реляционной модели. Для реализации двух других типов требуются определенные табличные преобразования. Отношение "один ко многим" (1:N) является естественным типом отношений в реляционной базе данных. Оно реализуется с помощью внешних ключей, рассмотренных выше. При отношении 1:N любой строке первой таблицы может соответствовать несколько записей второй таблицы. Если проанализировать связь в противоположном отношении, то окажется, что строке второй таблицы соответствует всего одна запись первой таблицы. В идеально спроектированной реляционной базе данных отношение "один к одному" (1:1) не нужно. Если каждой строке одной таблицы соответствует одна строка другой таблицы, то это обычно свидетельствует о том, что обе таблицы нужно объединить в единое целое. Исключение из правила— необычный случай, когда число столбцов таблицы превышает предел, установленный в СУБД. В MySQL этот предел равен 3000, так что маловероятно, чтобы кому-то пришло в голову его превысить. Есть СУБД, где предельное число столбцов гораздо меньше, например 250, но даже этого числа вполне достаточно для большинства приложений. В будущих версиях MySQL жесткий предел будет вообще снят, и создавать столбцы можно будет до тех пор, пока не закончится место на диске. Еще одна причина существования отношения "один к одному" — это случай, когда определенный набор атрибутов применим лишь к небольшому подмножеству записей. В реляционной базе данных нельзя напрямую создать отношение "многие ко многим" (M:N). Его необходимо преобразовать в два отношения 1:N, устанавливаемых с промежуточной таблицей. Выход из положения заключается в декомпозиции, т.е. разбивке отношения M:N на два отношения 1:N. Это означает, что ссылки между двумя таблицами будут вынесены в третью таблицу, содержащую всего два столбца. В них будут сопоставляться первичные ключи основных таблиц. Отношение 1:N, соединяющее столбцы одной и той же таблицы, называется самообъединением. Оно используется для отображения иерархических структур. Подразумевается, что внешний ключ ссылается на родительскую строку собственной таблицы. Внешний ключ и родительский ключ Когда все значения в одном поле таблицы представлены в поле другой таблицы, говорят, что первое поле ссылается на второе. Это указывает на прямую связь между значениями двух полей. Например, каждый из заказчиков в таблице Заказчиков имеет поле snum которое указывает на продавца назначенного в таблице Продавцов. Для каждого порядка в таблице Порядков, имеется один, и только этот продавец и один и только этот заказчик. Это отображается с помощью полей snum и cnum в таблице Порядков. Когда одно поле в таблице ссылается на другое, оно называется - внешним ключом; а поле, на которое оно ссылается, называется - родительским ключом. Так что поле snum таблицы Заказчиков - это внешний ключ, а поле snum на которое оно ссылается в таблице Продавцов - это родительский ключ. Аналогично, пол cnum и snum таблицы Порядков - это внешние ключи, которые ссылаются к их родительским ключам с именами в таблице Заказчиков и таблице Продавцов. Имена внешнего ключа и родительского ключа не обязательно должны быть одинаковыми. В действительности, внешний ключ не обязательно состоит только из одного поля. Подобно первичному ключу, внешний ключ может иметь любое число полей, которые все обрабатываются как единый модуль. Внешний ключ и родительский ключ, на который он ссылается, конечно же, должны иметь одинаковый номер и тип поля, и находиться в одинаковом порядке. Когда поле - является внешним ключом, оно определенным образом связано с таблицей на которую он ссылается. Каждое значение (каждая строка) внешнего ключа должно недвусмысленно ссылаться к одному и только этому значению (строке) родительского ключа. Если это так, то фактически система, как говорится, будет в состоянии справочной целостности. Ограничение FOREIGN KEY SQL поддерживает справочную целостность с ограничением FOREIGN KEY. Эта функция должна ограничивать значения, которые можно ввести в базу данных, чтобы заставить внешний ключ и родительский ключ соответствовать принципу справочной целостности. Одно из действий ограничения внешнего ключа - это отбрасывание значений для полей ограниченных как внешний ключ который еще не представлен в родительском ключе. Это ограничение также воздействует на способность изменять или удалять значения родительского ключа. Ограничение FOREIGN KEY используется в команде CREATE TABLE (или ALTER TABLE), которая содержит поле которое вы хотите объявить внешним ключом. Объявляется родительский ключ, на который будет ссылаться внутри ограничения FOREIGN KEY. Подобно большинству ограничений, оно может быть ограничением таблицы или столбца, в форме таблицы позволяющей использовать многочисленные пол как один внешний ключ. Синтаксис ограничения таблицы FOREIGN KEY: FOREIGN KEY <column list> REFERENCES <pktable> [ <column list> ] Первый список столбцов - это список из одного или более столбцов таблицы, которые отделены запятыми и будут созданы или изменены этой командой. Pktable - это таблица, содержащая родительский ключ. Она может быть таблицей, которая создается или изменяется текущей командой. Второй список столбцов - это список столбцов, которые будут составлять родительский ключ. Пример создания таблицы на примере таблицы Заказчиков с полем snum определенным в качестве внешнего ключа ссылающегося на таблицу Продавцов: CREATE TABLE Customers (cnum integer NOT NULL PRIMARY KEY cname char(10), city char(10), snum integer, FOREIGN KEY (snum) REFERENCES Salespeople (snum); Имейте в виду, что при использовании ALTER TABLE вместо CREATE TABLE, для применения ограничения FOREIGN KEY, значения которые Вы указываете во внешнем ключе и родительском ключе, должны быть в состоянии справочной целостности. Иначе команда будет отклонена. Вариант ограничения столбца ограничением FOREIGN KEY - по другому называется - ссылочное ограничение (REFERENCES), так как он фактически не содержит в себе слов FOREIGN KEY, а просто использует слово REFERENCES, и далее им родительского ключа, подобно этому: CREATE TABLE Customers (cnum integer NOT NULL PRIMARY KEY, cname char(10), city char(10), snum integer REFERENCES Salespeople (snum)); Вышеупомянутое определяет Customers.snum как внешний ключ у которого родительский ключ - это Salespeople.snum. Это эквивалентно такому ограничению таблицы: FOREIGN KEY (snum) REGERENCES Salespeople (snum)Задание на лабораторную работу. 1. В соответсвии с вариантом получите у преподавателя задание к разработке информационной системы. Провести анализ выбранной предметной области, проанализировать существующее ПО для автоматизации деятельности в данной области. 2. Составить технические требования к разрабатываемой системе (какую информацию должна содержать, какие требования предъявляются, кто будет пользоваться этой системой) 3. Разработать инфологическую модель 4. Разработать ER диаграмму 5. Провести нормализацию таблиц до 3 формы Бойса-Кодда. 6. Оформить очет 7. Защитить лабораторную работу
Контрольные вопросы 1. Ообъясните основные принципы построения сетевых моделей данных. Недостатки таких моделей. 2. Объясните основные принципы иерархических баз данных. Опишите недостатки таких моделей данных. 3. Объясните основные принципы построения реляционных баз данных. Достоинства и недостатки таких моделей. 4. Что понимается под «отношениями» в реляционных базах данных. 5. Объясните понятия внешнего и родитеского ключа. 6. Что такое конструкция FOREIGN KEY. Синтаксис и примеры. 7. Понятие нормализации. Цели. 8. Первая и вторая нормальные формы. Функциональная и полная функциональная зависимости. Примеры. 9. Третья нормальная форма. Многозначная зависимость. Примеры. 10. Какие модели архитектур баз данных используются в настоящее время помимо реляционных при современном проектировании баз данных. Опишите основные принципы, достоинства и недостатки. Лабораторная работа 2 Тема: Типы данных MySQL. Извлечение данных из таблиц. Разновидности запросов. Цель работы: Ознакомиться с синтаксисом и использованием оператора SELECT. Теоретическая основа Реляционные операторы Реляционный оператор - математический символ, который указывает на определенный тип сравнения между двумя значениями. Но также имеются другие реляционные операторы. Реляционные операторы которыми располагает SQL: = Равный > Больше чем < Меньше чем >= Больше чем или равно <= Меньше чем или равно < > Не равноЭти операторы имеют стандартные значения для числовых значений. Для значения символа, их определение зависит от формата преобразования, ASCII или EBCDIC. SQL сравнивает символьные значения в терминах основных номеров как определено в формате преобразования. Даже значение символа, такого как "1", который представляет номер, не обязательно равняется номеру, который он представляет. И в ASCII и в EBCDIC, символы - по значению: меньше чем все другие символы которым они предшествуют в алфавитном порядке и имеют один вариант(верхний или нижний). В ASCII, все символы верхнего регистра - меньше чем все символы нижнего регистра, поэтому "Z" < "a", а все номера - меньше чем все символы, поэтому "1" < "Z". То же относится и к EBCDIC. Чтобы сохранить обсуждение более простым, мы допустим, что вы будете использовать текстовый формат ASCII. Скалярное значение может быть символом или числом, хотя очевидно, что только номера используются с арифметическими операторами, такими как(плюс) или *(звезда). Предикаты обычно сравнивают значения скалярных величин, используя или реляционные операторы или специальные операторы SQL чтобы увидеть верно ли это сравнение. Булевы операторы Основные Булевы операторы также распознаются в SQL. Выражения Буля - являются или верными или неверными, подобно предикатам. Булевы операторы связывают одно или более верных/неверных значений и производят единственное верное/или/неверное значение. Стандартными операторами Буля распознаваемыми в SQL являются: AND, OR, и NOT. Существуют другие, более сложные, операторы Буля (типа " исключенный или "), но они могут быть сформированы из этих трех простых операторов - AND, OR, NOT. Булева верна / неверна логика - основана на цифровой компьютерной операции; и фактически, весь SQL может быть сведен до уровня Булевой логики. · AND верны ли они оба. · OR верен ли один из них. · NOT верен или не верен параметр. Оператор IN определяет набор значений, в которое данное значение может или не может быть включено. Оператор BETWEEN похож на оператор IN. В отличии от определения по номерам из набора, как это делает IN, BETWEEN определяет диапазон, значения которого должны уменьшаться что делает предикат верным. ключевое слово BETWEEN указывается с начальным значением, ключевое AND и конечное значение. В отличие от IN, BETWEEN, чувствителен к порядку, и первое значение в предложении должно быть первым по алфавитному или числовому порядку. SQL не делает непосредственной поддержки невключения BETWEEN. Вы должны или определить ваши граничные значения так, чтобы включающая интерпретация была приемлема, или сделать что-нибудь типа этого:По общему признанию, это немного неуклюже, но зато показывает как эти новые операторы могут комбинироваться с операторами Буля чтобы производить более сложные предикаты. В основном, вы используете IN и BETWEEN также как вы использовали реляционные операторы чтобы сравнивать значения, которые берутся либо из набора (для IN) либо из диапазона (для BETWEEN). Также, подобно реляционным операторам, BETWEEN может работать с символьными полями в терминах эквивалентов ASCII. Это означает что вы можете использовать BETWEEN чтобы выбирать ряд значений из упорядоченных по алфавиту значений. Следующий запрос выбирает всех заказчиков чьи имена попали в определенный алфавитный диапазон. SELECT * FROM Customers WHERE cname BETWEEN 'A' AND 'G'; Обратите Внимание что Grass и Giovanni отсутствуют, даже при включенном BETWEEN. Это происходит из-за того что BETWEEN сравнивает строки неравной длины. Строка 'G' более коротка чем строка Giovanni, поэтому BETWEEN выводит 'G' с пробелами. Пробелы предшествуют символам в алфавитном порядке (в большинстве реализаций), поэтому Giovanni не выбирается. То же самое происходит с Grass. Важно помнить это когда вы используете BETWEEN для извлечения значений из алфавитных диапазонов. Обычно вы указываете диапазон с помощью символа начала диапазона и символа конца(вместо которого можно просто поставить z). Оператор LIKE LIKE применим только к полям типа CHAR или VARCHAR, с которыми он используется чтобы находить подстроки. Т.е. он ищет поле символа чтобы видеть, совпадает ли с условием часть его строки. В качестве условия он использует групповые символы(wildkards) - специальные символы которые могут соответствовать чему-нибудь. Имеются два типа групповых символов используемых с LIKE: · символ подчеркивания (_) замещает любой одиночный символ. Например, 'b_t' будет соответствовать словам 'bat' или 'bit', но не будет соответствовать 'brat'. · знак процента (%) замещает последовательность любого числа символов (включая символы нуля). Например '%p%t' будет соответствовать словам 'put', 'posit', или 'opt', но не 'spite'. LIKE может быть удобен, если необходмое значение по части формулировки. Групповые символы подчеркивания, каждый из которых представляет один символ, добавят только два символа к уже существующим 'P' и 'l', поэтому им наподобие Prettel не может быть показано. Групповой символ ' % ' - в конце строки необходим в большинстве реализаций если длина поля sname больше чем число символов в имени Peel (потому что некоторые другие значения sname - длиннее чем четыре символа). В таком случае, значение поля sname, фактически сохраняемое как им Peel, сопровождается рядом пробелов. Следовательно, символ 'l' не будет рассматриваться концом строки. Групповой символ ' % ' - просто соответствует этим пробелам. Это необязательно, если поле sname имеет тип - VARCHAR. Агрегатные функции. Запросы могут производить обобщенное групповое значение полей точно также как и значение одного поля. Это делает с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы. Имеется список этих функций: · COUNT - производит номера строк или не-NULL значения полей которые выбрал запрос. · SUM - производит арифметическую сумму всех выбранных значений данного пол. · AVG - производит усреднение всех выбранных значений данного поля. · MAX - производит наибольшее из всех выбранных значений данного поля. · MIN - производит наименьшее из всех выбранных значений данного поля.
Агрегатные функции используются подобно именам полей в предложении SELECT запроса, но с одним исключением, они берут имена пол как аргументы. Только числовые поля могут использоваться с SUM и AVG. С COUNT, MAX, и MIN, могут использоваться и числовые или символьные поля. Когда они используются с символьными полями, MAX и MIN будут транслировать их в эквивалент ASCII, который должен сообщать, что MIN будет означать первое, а MAX последнее значение в алфавитном порядке. Чтобы найти SUM всех наших покупок в таблицы Порядков, мы можем ввести следующий запрос:
SELECT SUM ((amt)) FROM Orders; Это конечно, отличается от выбора поля при котором возвращается одиночное значение, независимо от того сколько строк находится в таблице. Из-за этого, агрегатные функции и поля не могут выбираться одновременно, пока предложение GROUP BY (описанное далее) не будет использовано. Нахождение усредненной суммы - это похожа операция: SELECT AVG (amt)FROM Orders; Функция COUNT несколько отличается от всех. Функция считает число значений в данном столбце, или число строк в таблице. Когда она считает значения столбца, она используется с DISTINCT чтобы производить счет чисел различных значений в данном поле. Агрегатные функции могут также (в большинстве реализаций) использовать аргумент ALL, который помещается перед именем поля, подобно DISTINCT, но означает противоположное: - включать дубликаты. ANSI технически не позволяет этого для COUNT, но многие реализации ослабляют это ограничение. Различи между ALL и * когда они используются с COUNT: · ALL использует имя_поля как аргумент. · ALL не может подсчитать значения NULL. Пока * является единственным аргументом который включает NULL значения, и он используется только с COUNT; функции отличные от COUNT игнорируют значения NULL в любом случае. Следующая команда подсчитает(COUNT) число не-NULL значений в поле rating в таблице Заказчиков (включая повторения): SELECT COUNT (ALL rating) FROM Customers;
MySQL предоставляет возможность построения агрегатных функций на основе скалярных выражений включающих одно или более полей (В таком случае конструкция DISTINCT не разрешается). Предположим, что таблица Заказов имеет еще один столбец, который хранит предыдущий неуплаченный баланс (поле blnc) для каждого заказчика. Необходимо найти этот текущий баланс, добавлением суммы приобретений к предыдущему балансу. Можно найти наибольший неуплаченный баланс следующим образом: SELECT MAX (blnc + (amt)) FROM Orders; Для каждой строки таблицы, этот запрос будет складывать blnc и amt для этого заказчика и выбирать самое большое значение которое он найдет. Конечно, пока заказчики могут иметь многочисленные заказы, их неуплаченный баланс оценивается отдельно для каждого заказа. Есть вероятность, заказ с более поздней датой будет иметь самый большой неуплаченный баланс. Иначе, старый баланс должен быть выбран как в запросе выше. Фактически, имеются большое количество ситуаций в SQL где вы можете использовать скалярные выражения с полями или вместо полей. Предложение GROUP BY Предложение GROUP BY позволяет вам определять подмножество значений в особом поле в терминах другого поля, и применять функцию агрегата к подмножеству. Это дает вам возможность объединять поля и агрегатные функции в едином предложении SELECT. Например, предположим что вы хотите найти наибольшую сумму приобретений полученную каждым продавцом. Вы можете сделать раздельный запрос для каждого из них, выбрав MAX (amt) из таблицы Заказов для каждого значения пол snum. GROUP BY, однако, позволит Вам поместить их все в одну команду: SELECT snum, MAX (amt) FROM Orders GROUP BY snum;
GROUP BY применяет агрегатные функции независимо от серий групп, которые определяются с помощью значения поля в целом. В этом случае, каждая группа состоит из всех строк с тем же самым значением поля snum, и MAX функция применяется отдельно для каждой такой группы. Это значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода, также как это делает агрегатная функция. Результатом является совместимость, которая позволяет агрегатам и полям объединяться таким образом. Вы можете также использовать GROUP BY с многочисленными полями. Совершенству вышеупомянутый пример далее, предположим что вы хотите увидеть наибольшую сумму приобретений получаемую каждым продавцом каждый день. Чтобы сделать это, вы должны сгруппировать таблицу Заказов по датам продавцов, и применить функцию MAX к каждой такой группе, подобно этому: SELECT snum, odate, MAX ((amt)) FROM Orders GROUP BY snum, odate;
Конечно же, пустые группы, в дни когда текущий продавец не имел закзаов, не будут показаны в выводе. Предложение HAVING Предположим, что в предыдущем примере, необходимо было вывести только максимальную сумму заказов, сумма которых выше $3000.00. В таком случае нельзя использовать агрегатную функцию в предложении WHERE (если вы не используете подзапрос, описанный позже), потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции оцениваются в терминах групп строк. Это означает, что вы не сможете сделать что-нибудь подобно следующему: SELECT snum, odate, MAX (amt)FROM OredersWHERE MAX ((amt)) > 3000.00GROUP BY snum, odate; Это будет отклонением от строгой интерпретации ANSI. Чтобы увидеть максимальную стоимость приобретений свыше $3000.00, вы можете использовать предложение HAVING. Предложение HAVING определяет критерии, используемые для удаления определенной группы из результата, точно также как предложение WHERE делает это для строк. Правильной командой будет следующая: SELECT snum, odate, MAX ((amt)) FROM Orders GROUP BY snum, odate HAVING MAX ((amt)) > 3000.00; Аргументы в предложении HAVING следуют тем же самым правилам, что и в предложении SELECT, состоящей из команд, использующих GROUP BY. Следующая команда будет запрещена: SELECT snum, MAX (amt) FROM Orders GROUP BY snum HAVING odate = 10/03/1988; Поле оdate не может быть вызвано предложением HAVING, потому что оно может иметь больше чем одно значение в результате вывода. Чтобы избежать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля выбранные GROUP BY. Правильный вариант, предложенного выше запроса: SELECT snum, MAX (amt) FROM Orders WHEREodate = 10/03/1990 GROUP BY snum; В строгой интерпретации ANSI SQL, нельзя использовать агрегат агрегата. Предположим, что вы необходимо выяснить, в какой день имелась наибольшая сумма покупок. Если запрос будет похож на: SELECT odate, MAX (SUM (amt)) FROM Orders GROUP BY odate; то команда будет отклонена.
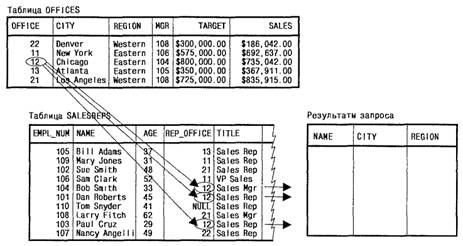
Объединение таблиц Процесс формирования пар строк путем сравнения содержимого соотвествующих столбцов называется объединением таблиц. Таблица, получаемая в результате формирования пар строк, и содержащая данные из обеих таблиц называется объединением двух таблиц. Объединение на основе точного равенства между двумя столбцами называется объединением по равенству. Объединения представляют собой основу многотабличных запросов в SQL. Запросы с использованием отношений предок/потомок. Среди многотабличных запросов наиболее распространены запросы к двум таблицам, связанных при помощи отношения предок/потомок. Можно привести пример на основе соотношения заказов и клиентов. У каждого заказа (потомка) есть соотвествующий ему клиент (предок) и каждый клиент может иметь множество своих заказов. Таблица содержащая внешний ключ называется потомком, а таблица с первичным ключом – это предок. Пример запроса с использованием отношения предок/потомок. Таблица SALESPERS (потомок) содержит столбец REP_OFFICE, который является внешним ключом для таблицы OFFICES (предок). Здесь отношение предок/потомок используется с целью поиска в таблице OFFICE для каждого служащего соответствующей строки, содержащей город и регион, и включения ее в результаты запроса.
Рис. 3.1 Запрос и использование отношения предок/потомок между таблицами OFFICES и SALESPERS Условия для отбора строк. В многотабличном запросе можно комбинировать условие отбора, в котором задаются связанные столбцы, с другими условиями отбора, чтобы еще сузить результаты запроса. Предположим, что требуется повторить предыдущий запрос, но включить в него только офисы, имеющие большие плановые объемы продаж. Вследствствии приминения дополнительного условия отбора количество строк в таблице результата запрос а уменьшится. Несколько связанных столбцов. Таблицы ORDERS и PRODUCTS в учебной базе данных связаны парой составных ключей. Столбцы MFR и PRODUST в таблице ORDERS вместе образуют внешний ключ для таблицы PRODUCTS и связаны с ее столбцами MFR_ID и PRODUCT_ID соотвественно. Чтобы объединить таблицы на основе такого отношения предок/потомок, необходимо задать обе пары связанных столбцов, как показано в примере:
SELECT ORDER_NUM, AMOUNT, DESCRIPTION FROM ORDERS, PRODUCTS WHERE MFR = MFR_ID AND PRODUCT = PRODUCT_ID Условие отбора в данном запросе показывает, что связанные парами строк таблиц ORDERS и PRODUCTS являются те, в которых пары связанных столбцов содержат одни и те же значения. Объединения посредством нескольких столбцов распространены меньше, чем объединения посредством одного столбца, и обычно встречается в запросах с составными ключами, как в приведенном выше примере. Запросы на выборку к трем и более таблицам. SQL позволяет обединить данные из трех или более таблиц, используя ту же самую методику, что и для объединения данных из двух таблиц. Пример:
SELECT ORDER_NUM, AMOUNT, COMPANY, NAME FROM ORDERS, SALESPERS, CUSTOMERS WHERE CUST = CUST_NUM;
Как видно, из рисунка 3.2. в этом запрос
|
||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 300; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.012 с.) |