Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Создание запроса. Комманда selectСодержание книги Поиск на нашем сайте
В самой простой форме, команда SELECT просто инструктирует базу данных о том, что нужно извлечь информацию из таблицы. Например, можно вывести таблицу Продавцов напечатав следующее: SELECT snum, sname, sity, comm. FROM Salespeople; Другими словами, эта команда просто выводит все данные из таблицы. Большинство СУБД будут также показывать при выводе заголовки столбцов (как выше на рисунке), а некоторые позволяют детальное форматирование вывода, но это уже вне стандартной спецификации. Вот детальные пояснения для каждой части этой команды: · SELECT - Ключевое слово, которое сообщает базе данных, что эта команда - запрос. Все запросы начинаются этим словом, сопровождаемым пробелом. · snum, sname. Это - список столбцов из таблицы, которые выбираются запросом. Любые столбцы, не перечисленные здесь, не будут включены в вывод команды. Это не значит, что они будут удалены или их информация будет стерта из таблиц, потому что запрос не воздействует на информацию в таблицах; он только показывает данные. · FROM Salespeople. FROM - ключевое слово, подобно SELECT, которое должно быть представлено в каждом запросе. Оно сопровождается пробелом и затем именем таблицы используемой в качестве источника информации. В данном случае - это таблица Продавцов (Salespeople). · Точка с запятой используется во всех интерактивных командах SQL, чтобы сообщать базе данных, что команда заполнена и готова выполниться. В некоторых системах наклонная черта влево (\) в строке, также является индикатором конца команды. Естественно, запросу такого характера не обязательно упорядочивать вывод каким-либо особым способом. Та же сама команда, выполненная с теми же самыми данными, но в разное время может вывести строки в другом порядке. Обычно, строки выдаются в том порядке, в котором они найдены в таблице. Это не обязательно будет тот порядок, в котором данные вводились или сохранялись. DISTINCT (отличие) – аргумент, который обеспечивает способом устранять двойные значения из предложения SELECT. Предположим, что нужно знать, какие продавцы в настоящее время имеют свои порядки в таблице Порядков. Под порядком будет пониматься запись в таблицу Порядков, регистрирующую приобретения сделанные в определенный день определенным заказчиком у определенного продавца на определенную сумму. Не нужно знать, сколько порядков имеет каждый; нужен только список номеров продавцов (snum). Поэтому можно ввести:
SELECT snum FROM Orders; Для получения списка без дубликатов, для удобочитаемости, вы можете ввести следующее: SELECT DISTINCT snum FROM Orders; Другими словами, DISTINCT следит за тем, какие значения были ранее, так, чтобы они не были продублированы в списке. Это - полезный способ избежать избыточности данных. Если вы не хотите потерять некоторые данные, вы не должны безоглядно использовать DISTINCT, потому что это может скрыть какую-то проблему или какие-то важные данные. DISTINCT может указываться только один раз в данном предложении SELECT. Если предложение выбирает многочисленные поля. DISTINCT опускает строки, где все выбранные поля идентичны. Строки, в которых некоторые значения одинаковы, а некоторые различны - будут сохранены. DISTINCT, фактически, приводит к показу всей строки вывода, не указывая полей. Вместо DISTINCT, можно указать – ALL, дублирование строк вывода сохранится. Таблицы имеют тенденцию становиться очень большими, поскольку с течением времени, в них добавляется все большее и большее строк. Поскольку обычно бывают нужны только определенные строки, SQL дает возможность устанавливать критерии, определяющие какие строки будут выбраны для вывода. WHERE - предложение команды SELECT, которое позволяет вам устанавливать предикаты, условие которых может быть или верным или неверным для любой строки таблицы. Команда извлекает только те строки из таблицы, для которых указанное условие верно. Например: SELECT sname, city FROM Salespeople WHERE city = "LONDON"; Когда в запросе есть предложение WHERE, СУБД просматривает всю таблицу по одной строке и исследует каждую строку, чтобы определить верно ли заданное условие. Следовательно, для записи Peel, программа рассмотрит текущее значение столбца city, определит, что оно равно "London", и включит эту строку в вывод. Запись для Serres не будет включена, и так далее. Пример с числовым полем в предложении WHERE. Поле rating таблицы Заказчиков предназначено, чтобы разделять заказчиков на групы основанные на некоторых критериях, которые могут быть получены в итоге через этот номер. Возможно это - форма оценки кредита или оценки основанной на сумме предыдущих приобретений. Такие числовые коды могут быть полезны в реляционных базах данных как способ подведения итогов сложной информации. Мы можем выбрать всех заказчиков с рейтингом 100, следующим образом:
SELECT * FROM Customers WHERE rating = 100; Реляционные операторы Реляционный оператор - математический символ, который указывает на определенный тип сравнения между двумя значениями. Но также имеются другие реляционные операторы. Реляционные операторы которыми располагает SQL: = Равный > Больше чем < Меньше чем >= Больше чем или равно <= Меньше чем или равно < > Не равноЭти операторы имеют стандартные значения для числовых значений. Для значения символа, их определение зависит от формата преобразования, ASCII или EBCDIC. SQL сравнивает символьные значения в терминах основных номеров как определено в формате преобразования. Даже значение символа, такого как "1", который представляет номер, не обязательно равняется номеру, который он представляет. И в ASCII и в EBCDIC, символы - по значению: меньше чем все другие символы которым они предшествуют в алфавитном порядке и имеют один вариант(верхний или нижний). В ASCII, все символы верхнего регистра - меньше чем все символы нижнего регистра, поэтому "Z" < "a", а все номера - меньше чем все символы, поэтому "1" < "Z". То же относится и к EBCDIC. Чтобы сохранить обсуждение более простым, мы допустим, что вы будете использовать текстовый формат ASCII. Скалярное значение может быть символом или числом, хотя очевидно, что только номера используются с арифметическими операторами, такими как(плюс) или *(звезда). Предикаты обычно сравнивают значения скалярных величин, используя или реляционные операторы или специальные операторы SQL чтобы увидеть верно ли это сравнение. Булевы операторы Основные Булевы операторы также распознаются в SQL. Выражения Буля - являются или верными или неверными, подобно предикатам. Булевы операторы связывают одно или более верных/неверных значений и производят единственное верное/или/неверное значение. Стандартными операторами Буля распознаваемыми в SQL являются: AND, OR, и NOT. Существуют другие, более сложные, операторы Буля (типа " исключенный или "), но они могут быть сформированы из этих трех простых операторов - AND, OR, NOT. Булева верна / неверна логика - основана на цифровой компьютерной операции; и фактически, весь SQL может быть сведен до уровня Булевой логики. · AND верны ли они оба. · OR верен ли один из них. · NOT верен или не верен параметр. Оператор IN определяет набор значений, в которое данное значение может или не может быть включено. Оператор BETWEEN похож на оператор IN. В отличии от определения по номерам из набора, как это делает IN, BETWEEN определяет диапазон, значения которого должны уменьшаться что делает предикат верным. ключевое слово BETWEEN указывается с начальным значением, ключевое AND и конечное значение. В отличие от IN, BETWEEN, чувствителен к порядку, и первое значение в предложении должно быть первым по алфавитному или числовому порядку. SQL не делает непосредственной поддержки невключения BETWEEN. Вы должны или определить ваши граничные значения так, чтобы включающая интерпретация была приемлема, или сделать что-нибудь типа этого:По общему признанию, это немного неуклюже, но зато показывает как эти новые операторы могут комбинироваться с операторами Буля чтобы производить более сложные предикаты. В основном, вы используете IN и BETWEEN также как вы использовали реляционные операторы чтобы сравнивать значения, которые берутся либо из набора (для IN) либо из диапазона (для BETWEEN).
Также, подобно реляционным операторам, BETWEEN может работать с символьными полями в терминах эквивалентов ASCII. Это означает что вы можете использовать BETWEEN чтобы выбирать ряд значений из упорядоченных по алфавиту значений. Следующий запрос выбирает всех заказчиков чьи имена попали в определенный алфавитный диапазон. SELECT * FROM Customers WHERE cname BETWEEN 'A' AND 'G'; Обратите Внимание что Grass и Giovanni отсутствуют, даже при включенном BETWEEN. Это происходит из-за того что BETWEEN сравнивает строки неравной длины. Строка 'G' более коротка чем строка Giovanni, поэтому BETWEEN выводит 'G' с пробелами. Пробелы предшествуют символам в алфавитном порядке (в большинстве реализаций), поэтому Giovanni не выбирается. То же самое происходит с Grass. Важно помнить это когда вы используете BETWEEN для извлечения значений из алфавитных диапазонов. Обычно вы указываете диапазон с помощью символа начала диапазона и символа конца(вместо которого можно просто поставить z). Оператор LIKE LIKE применим только к полям типа CHAR или VARCHAR, с которыми он используется чтобы находить подстроки. Т.е. он ищет поле символа чтобы видеть, совпадает ли с условием часть его строки. В качестве условия он использует групповые символы(wildkards) - специальные символы которые могут соответствовать чему-нибудь. Имеются два типа групповых символов используемых с LIKE: · символ подчеркивания (_) замещает любой одиночный символ. Например, 'b_t' будет соответствовать словам 'bat' или 'bit', но не будет соответствовать 'brat'. · знак процента (%) замещает последовательность любого числа символов (включая символы нуля). Например '%p%t' будет соответствовать словам 'put', 'posit', или 'opt', но не 'spite'. LIKE может быть удобен, если необходмое значение по части формулировки. Групповые символы подчеркивания, каждый из которых представляет один символ, добавят только два символа к уже существующим 'P' и 'l', поэтому им наподобие Prettel не может быть показано. Групповой символ ' % ' - в конце строки необходим в большинстве реализаций если длина поля sname больше чем число символов в имени Peel (потому что некоторые другие значения sname - длиннее чем четыре символа). В таком случае, значение поля sname, фактически сохраняемое как им Peel, сопровождается рядом пробелов. Следовательно, символ 'l' не будет рассматриваться концом строки. Групповой символ ' % ' - просто соответствует этим пробелам. Это необязательно, если поле sname имеет тип - VARCHAR.
Агрегатные функции. Запросы могут производить обобщенное групповое значение полей точно также как и значение одного поля. Это делает с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы. Имеется список этих функций: · COUNT - производит номера строк или не-NULL значения полей которые выбрал запрос. · SUM - производит арифметическую сумму всех выбранных значений данного пол. · AVG - производит усреднение всех выбранных значений данного поля. · MAX - производит наибольшее из всех выбранных значений данного поля. · MIN - производит наименьшее из всех выбранных значений данного поля.
Агрегатные функции используются подобно именам полей в предложении SELECT запроса, но с одним исключением, они берут имена пол как аргументы. Только числовые поля могут использоваться с SUM и AVG. С COUNT, MAX, и MIN, могут использоваться и числовые или символьные поля. Когда они используются с символьными полями, MAX и MIN будут транслировать их в эквивалент ASCII, который должен сообщать, что MIN будет означать первое, а MAX последнее значение в алфавитном порядке. Чтобы найти SUM всех наших покупок в таблицы Порядков, мы можем ввести следующий запрос:
SELECT SUM ((amt)) FROM Orders; Это конечно, отличается от выбора поля при котором возвращается одиночное значение, независимо от того сколько строк находится в таблице. Из-за этого, агрегатные функции и поля не могут выбираться одновременно, пока предложение GROUP BY (описанное далее) не будет использовано. Нахождение усредненной суммы - это похожа операция: SELECT AVG (amt)FROM Orders; Функция COUNT несколько отличается от всех. Функция считает число значений в данном столбце, или число строк в таблице. Когда она считает значения столбца, она используется с DISTINCT чтобы производить счет чисел различных значений в данном поле. Агрегатные функции могут также (в большинстве реализаций) использовать аргумент ALL, который помещается перед именем поля, подобно DISTINCT, но означает противоположное: - включать дубликаты. ANSI технически не позволяет этого для COUNT, но многие реализации ослабляют это ограничение. Различи между ALL и * когда они используются с COUNT: · ALL использует имя_поля как аргумент. · ALL не может подсчитать значения NULL. Пока * является единственным аргументом который включает NULL значения, и он используется только с COUNT; функции отличные от COUNT игнорируют значения NULL в любом случае. Следующая команда подсчитает(COUNT) число не-NULL значений в поле rating в таблице Заказчиков (включая повторения): SELECT COUNT (ALL rating) FROM Customers;
MySQL предоставляет возможность построения агрегатных функций на основе скалярных выражений включающих одно или более полей (В таком случае конструкция DISTINCT не разрешается). Предположим, что таблица Заказов имеет еще один столбец, который хранит предыдущий неуплаченный баланс (поле blnc) для каждого заказчика. Необходимо найти этот текущий баланс, добавлением суммы приобретений к предыдущему балансу. Можно найти наибольший неуплаченный баланс следующим образом:
SELECT MAX (blnc + (amt)) FROM Orders; Для каждой строки таблицы, этот запрос будет складывать blnc и amt для этого заказчика и выбирать самое большое значение которое он найдет. Конечно, пока заказчики могут иметь многочисленные заказы, их неуплаченный баланс оценивается отдельно для каждого заказа. Есть вероятность, заказ с более поздней датой будет иметь самый большой неуплаченный баланс. Иначе, старый баланс должен быть выбран как в запросе выше. Фактически, имеются большое количество ситуаций в SQL где вы можете использовать скалярные выражения с полями или вместо полей. Предложение GROUP BY Предложение GROUP BY позволяет вам определять подмножество значений в особом поле в терминах другого поля, и применять функцию агрегата к подмножеству. Это дает вам возможность объединять поля и агрегатные функции в едином предложении SELECT. Например, предположим что вы хотите найти наибольшую сумму приобретений полученную каждым продавцом. Вы можете сделать раздельный запрос для каждого из них, выбрав MAX (amt) из таблицы Заказов для каждого значения пол snum. GROUP BY, однако, позволит Вам поместить их все в одну команду: SELECT snum, MAX (amt) FROM Orders GROUP BY snum;
GROUP BY применяет агрегатные функции независимо от серий групп, которые определяются с помощью значения поля в целом. В этом случае, каждая группа состоит из всех строк с тем же самым значением поля snum, и MAX функция применяется отдельно для каждой такой группы. Это значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода, также как это делает агрегатная функция. Результатом является совместимость, которая позволяет агрегатам и полям объединяться таким образом. Вы можете также использовать GROUP BY с многочисленными полями. Совершенству вышеупомянутый пример далее, предположим что вы хотите увидеть наибольшую сумму приобретений получаемую каждым продавцом каждый день. Чтобы сделать это, вы должны сгруппировать таблицу Заказов по датам продавцов, и применить функцию MAX к каждой такой группе, подобно этому: SELECT snum, odate, MAX ((amt)) FROM Orders GROUP BY snum, odate;
Конечно же, пустые группы, в дни когда текущий продавец не имел закзаов, не будут показаны в выводе. Предложение HAVING Предположим, что в предыдущем примере, необходимо было вывести только максимальную сумму заказов, сумма которых выше $3000.00. В таком случае нельзя использовать агрегатную функцию в предложении WHERE (если вы не используете подзапрос, описанный позже), потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции оцениваются в терминах групп строк. Это означает, что вы не сможете сделать что-нибудь подобно следующему: SELECT snum, odate, MAX (amt)FROM OredersWHERE MAX ((amt)) > 3000.00GROUP BY snum, odate; Это будет отклонением от строгой интерпретации ANSI. Чтобы увидеть максимальную стоимость приобретений свыше $3000.00, вы можете использовать предложение HAVING. Предложение HAVING определяет критерии, используемые для удаления определенной группы из результата, точно также как предложение WHERE делает это для строк. Правильной командой будет следующая: SELECT snum, odate, MAX ((amt)) FROM Orders GROUP BY snum, odate HAVING MAX ((amt)) > 3000.00; Аргументы в предложении HAVING следуют тем же самым правилам, что и в предложении SELECT, состоящей из команд, использующих GROUP BY. Следующая команда будет запрещена: SELECT snum, MAX (amt) FROM Orders GROUP BY snum HAVING odate = 10/03/1988; Поле оdate не может быть вызвано предложением HAVING, потому что оно может иметь больше чем одно значение в результате вывода. Чтобы избежать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля выбранные GROUP BY. Правильный вариант, предложенного выше запроса: SELECT snum, MAX (amt) FROM Orders WHEREodate = 10/03/1990 GROUP BY snum; В строгой интерпретации ANSI SQL, нельзя использовать агрегат агрегата. Предположим, что вы необходимо выяснить, в какой день имелась наибольшая сумма покупок. Если запрос будет похож на: SELECT odate, MAX (SUM (amt)) FROM Orders GROUP BY odate; то команда будет отклонена.
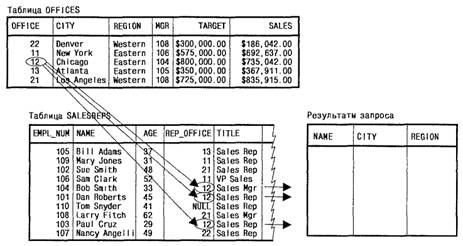
Объединение таблиц Процесс формирования пар строк путем сравнения содержимого соотвествующих столбцов называется объединением таблиц. Таблица, получаемая в результате формирования пар строк, и содержащая данные из обеих таблиц называется объединением двух таблиц. Объединение на основе точного равенства между двумя столбцами называется объединением по равенству. Объединения представляют собой основу многотабличных запросов в SQL. Запросы с использованием отношений предок/потомок. Среди многотабличных запросов наиболее распространены запросы к двум таблицам, связанных при помощи отношения предок/потомок. Можно привести пример на основе соотношения заказов и клиентов. У каждого заказа (потомка) есть соотвествующий ему клиент (предок) и каждый клиент может иметь множество своих заказов. Таблица содержащая внешний ключ называется потомком, а таблица с первичным ключом – это предок. Пример запроса с использованием отношения предок/потомок. Таблица SALESPERS (потомок) содержит столбец REP_OFFICE, который является внешним ключом для таблицы OFFICES (предок). Здесь отношение предок/потомок используется с целью поиска в таблице OFFICE для каждого служащего соответствующей строки, содержащей город и регион, и включения ее в результаты запроса.
Рис. 3.1 Запрос и использование отношения предок/потомок между таблицами OFFICES и SALESPERS Условия для отбора строк. В многотабличном запросе можно комбинировать условие отбора, в котором задаются связанные столбцы, с другими условиями отбора, чтобы еще сузить результаты запроса. Предположим, что требуется повторить предыдущий запрос, но включить в него только офисы, имеющие большие плановые объемы продаж. Вследствствии приминения дополнительного условия отбора количество строк в таблице результата запрос а уменьшится. Несколько связанных столбцов. Таблицы ORDERS и PRODUCTS в учебной базе данных связаны парой составных ключей. Столбцы MFR и PRODUST в таблице ORDERS вместе образуют внешний ключ для таблицы PRODUCTS и связаны с ее столбцами MFR_ID и PRODUCT_ID соотвественно. Чтобы объединить таблицы на основе такого отношения предок/потомок, необходимо задать обе пары связанных столбцов, как показано в примере:
SELECT ORDER_NUM, AMOUNT, DESCRIPTION FROM ORDERS, PRODUCTS WHERE MFR = MFR_ID AND PRODUCT = PRODUCT_ID Условие отбора в данном запросе показывает, что связанные парами строк таблиц ORDERS и PRODUCTS являются те, в которых пары связанных столбцов содержат одни и те же значения. Объединения посредством нескольких столбцов распространены меньше, чем объединения посредством одного столбца, и обычно встречается в запросах с составными ключами, как в приведенном выше примере. Запросы на выборку к трем и более таблицам. SQL позволяет обединить данные из трех или более таблиц, используя ту же самую методику, что и для объединения данных из двух таблиц. Пример:
SELECT ORDER_NUM, AMOUNT, COMPANY, NAME FROM ORDERS, SALESPERS, CUSTOMERS WHERE CUST = CUST_NUM;
Как видно, из рисунка 3.2. в этом запросе используется два внешних ключа таблицы ORDERS. Столбец CUST является внешним ключом для таблицы CUSTOMERS; он свзявает каждый заказ с клиентом, сделавшим его. Столбец REP является внешним ключом для таблицы SALESPERS, связывая каждый заказ со служащим, принявшим его. Проще говоря, запрос связывает каждый заказ с соответствующим клиентом и служащим.
Рис. 3.2. Запрос к трем таблицам. Прочие объединения таблиц по равенству. Большое количество многотаблицчных запросов основано на отношении предок/потомок, но в SQL не требуется, чтобы связанные столбцы представляли собой пару «внешний ключ – первичный ключ». Любые два столбца из двух таблиц могут быть связанными, если только они имеют сравнимые типа данных.
Рис. 3.3 Объединение, в котором не используются внешние и первичные ключи Объединение таблиц по неравенству. Термин «объединение» применяется к любому запросу, который объединяет данные из таблиц базы данных путем сравнения значений в двух столбцах этих таблиц. Самыми распространенными являются объединения, созданные на основе равенства связанных столбцов (объединения по равенству). Кроме того, SQL позволяет объединять таблицы с помощью других операций сравнений. Например, больше или меньше. Операторы сравнения. Реляционные операторы, иначе называемые операторами сравнения возращают булевы значение TRUE и FALSE. Если булево значение стоит в списке возвращаемых столбцов или в правой части оператора присваивания, то оно будет преобразовано в 1 (TRUE) или О (FALSE). Операторы сравнения представлены в таблице ниже. Таблица 1.
Операторы IN и NOT IN принимают в скобках группу разделенных запятыми значений, задающих допустимое множество. Если левый операнд совпадает с одним из значений в скобках, результат проверки будет истинным. В списке должны быть указаны литералы или имена столбцов. В отличие от некоторых СУБД, в MySQL не допускается указывать в скобках запрос. Операторы LIKE и NOT LIKE сравнивают левый операнд с шаблоном, указанным в правом операнде. Метасимвол % в шаблоне соответствует произвольному числу символов, а метасимвол _ — одиночному символу. Остальные символы воспринимаются буквально. Если необходимо выполнить сравнение с самим символом % или _, его нужно защитить от интерпретации с помощью обратной косой черты. Строка шаблона анализируется дважды. При этом на первом проходе последовательности \$, \_ и \\ будут заменены соответствующими литералами, а вот остальные управляющие последовательности не распознаются, поэтому \n превратится в n, а не в символ новой строки. Проверка обычных управляющих последовательностей выполняется на втором проходе. Это означает, что в данном случае символы обратной косой черты необходимо удваивать. Таким образом, чтобы вставить в шаблон символ табуляции, следует записать \\\t. Обратной косой черте соответствует запись \\\\. Всего этого можно избежать, если воспользоваться предложением ESCAPE, которое задает символ, служащий началом управляющих последовательностей в данном конкретном операторе LIKE. В листинге 10.8 приведены примеры выражений с оператором LIKE, каждое из которых является истинным. Выражения с оператором LIKE чувствительны к регистру символов только в том когда левый операнд помечен ключевым словом BINARY.. Оператор сравнивает левый операнд с регулярным выражением, стоящим справа. В регулярных выражениях применяется специальный язык описания шаблонов, спецификация которого содержится в стандарте 1003.2. Они всегда чувствительны к регистру символов. Регулярные выражения также подвержены двойному синтаксическому анализу, но предложение ESCAPE в операторе REGEXP не поддерживается. На самом верхнем уровне регулярное выражение состоит из одного или нескольких блоков, разделенных вертикальной чертой Этот символ аналогичен оператору OR в SQL, т.е. сравниваемая строка может соответствовать любой из ветвей. Изменение порядка выводимых строк (ORDER BY) Порядок выводимых строк может быть изменен с помощью опционального (дополнительного) предложения ORDER BY в конце SQL-запроса. Это предложение имеет вид: ORDER BY <порядок строк> [ASC | DESC]
Порядок строк может задаваться одним из двух способов: · именами столбцов · номерами столбцов. Способ упорядочивания определяется дополнительными зарезервированными словами ASC и DESC. Способом по умолчанию - если ничего не указано - является упорядочивание "по возрастанию" (ASC). Если же указано слово "DESC", то упорядочивание будет производиться "по убыванию". Преобразование типов (CAST) В SQL имеется возможность преобразовать значение столбца или функции к другому типу для более гибкого использования операций сравнения. Для этого используется функция CAST. Типы данных могут быть конвертированы в соответствии со следующей таблицей: Из типа данных В тип данных NUMERIC CHAR, VARCHAR, DATE CHAR, VARCHAR NUMERIC, DATE DATE CHAR, VARCHAR, DATE Соединение (JOIN) Операция соединения используется в языке SQL для вывода связанной информации, хранящейся в нескольких таблицах, в одном запросе. В этом проявляется одна из наиболее важных особенностей запросов SQL - способность определять связи между многочисленными таблицами и выводить информацию из них в рамках этих связей. Операции соединения подразделяются на два вида - внутренние и внешние. Оба вида соединений задаются в предложении WHERE запроса SELECT с помощью специального условия соединения. Внешние соединения (о которых мы поговорим позднее) поддерживаются стандартом ANSI-92 и содержат зарезервированное слово "JOIN", в то время как внутренние соединения (или просто соединения) могут задаваться как без использования такого слова (в стандарте ANSI-89), так и с использованием слова "JOIN" (в стандарте ANSI-92). Связывание производится, как правило, по первичному ключу одной таблицы и внешнему ключу другой таблицы - для каждой пары таблиц. При этом очень важно учитывать все поля внешнего ключа, иначе результат будет искажен. Соединяемые поля могут присутствовать в списке выбираемых элементов. Предложение WHERE может содержать множественные условия соединений. Условие соединения может также комбинироваться с другими предикатами в предложении WHERE. Внешние соединения Существует два вида внешнего соединения: LEFT JOIN и RIGHT JOIN. В левом соединении (LEFT JOIN) запрос возвращает все строки из левой таблицы (т.е. таблицы, стоящей слева от зарезервированного словосочетания "LEFT JOIN") и только те из правой таблицы, которые удовлетворяют условию соединения. Если же в правой таблице не найдется строк, удовлетворяющих заданному условию, то в результате они замещаются значениями null. Для правого соединения - все наоборот. Запрос: получить список сотрудников и название их отделов, включая сотрудников, еще не назначенных ни в какой отдел SELECT first_name, last_name, department FROM employee e LEFT JOIN department d ON e.dept_no = d.dept_no Соотнесенные подзапросы Когда используются подзапросы в SQL, есть возможность обратиться к внутреннему запросу таблицы в предложении внешнего запроса FROM, сформировав тем самым соотнесенный подзапрос. Например, имеется один способ найти всех заказчиков в Заказах на 3-е Октября SELECT * FROM Customers outer WHERE 10/03/1990 IN (SELECT odate FROM Orders inner WHERE outer.cnum = inner.cnum);В вышеупомянутом примере, "внутренний" (inner) и "внешний" (outer), это псевдонимы. Так как значение в поле cnum внешнего запроса меняется, внутренний запрос должен выполняться отдельно для каждой строки внешнего запроса. Задание на лабораторную работу. 1. Для разработанной и реализованной базы данных составить текстовое описание будущих запросов. Запросы должны учитывать специфику базы данных, не являются простыми и должны быть направлены на реализацию функциональных возможностей оператора select. 2. Утвердить у преподавателя текстовое описание запросов к базе данных 3. Описать схему прохождения таблиц запросом (количество участвующих атрибутов, ключей, таблиц и их взаимосвязи) для каждого из описанных запросов. 4. Заполнить по 10-15 записей в таблицы, используемых при запросах. 5. Реализовать запросы на языке SQL. Получить данные. 6. Оформить отчет 7. Защитить лабораторную работу.
Контрольные вопросы
1. Что такое подзапрос? 2. По каким принципам взаимодействия между собой таблиц описываются мнотогабличные запросы? 3. Что такое агрегатные функции? Особенности, примеры использования. 4. В каких случаях используются операторы ANY и SOME? 5. Конструкция Inner Join. 6. Что такое вложенные запросы и чем они отличаются от подзапросов? 7. Команда UPDATE. Принципы использования команды в запросах. 8. Использование подзапросов с оператором DELETE. 9. Использование подзапросов с оператором INSERT. 10. Использование команды UPDATE для многих столбцов. 11. Какие четыре основых типа данных существует в MySQL? 12. Опишите основные конструкции и особенности типа данных TIMESTAMP, чем он отличается от типа данных DATE и TIME? 13. Что такое специализированные типы данных, опишите их особенности? 14. Синтаксис и способы задания размерности типов данных для полей таблиц MYSQL? 15. Опишите синтаксис и основные конструкции команды CREATE TABLE? 16. Опишите синтаксис и основные конструкции команды CREATE INDEX? 17. Опишите синтаксис и основные конструкции команды ALTER INDEX? 18. Чем оператор DELETE отличается от оператора DROP? 19. Что такое конструкция CHECK? 20. Чем конструкция UNIQUE отличается от INDEX? 21. Что значит конструкция DEFAULT? Напишите пример в СУБД с ее использованием и покажите как она работает?
Лабораторная работа 3 Тема: Виртуальные таблицы в MYSQL. Создание представлений. Цель работы: Научиться работать с представлениями. Узнать о возможностях и ограничениях представлений.
Теоретические основы Типы таблиц, с которыми вы имели дело до сих пор, назывались - базовыми таблицами. Это - таблицы, которые содержат данные. Однако имеется другой вид таблиц: - виртуальные таблицы или представления. Представления - это таблицы, содержание которых выбирается или получается из других таблиц. Они работают в запросах и операторах DML точно также как и основные таблицы, но не содержат никаких собственных данных. Представления - подобны окнам, через которые вы просматриваете информацию (как она есть, или в другой форме, как вы потом увидите), которая фактически хранится в базовой таблице. Представление - это фактически запрос, который выполняется всякий раз, когда представление становится темой команды. Вывод запроса при этом в каждый момент становится содержанием представления. Команда CREATE VIEW Представление создается командой CREATE VIEW. Она состоит из слов CREATE VIEW, имени представления которое нужно создать, слова AS (КАК), и далее запроса, на основе которого создается данное представление. Синтаксис Create view.
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] [DEFINER = { user | CURRENT_USER }] [SQL SECURITY { DEFINER | INVOKER }] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION] Представления значительно расширяют возможности управление данными. Это - способ дать публичный доступ к некоторой, но не всей информации в таблице.
|
|||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 279; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.188.141 (0.018 с.) |