Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Переход к реляционной модели данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Инфологическая модель используется на ранних стадиях разработки проекта. Если понимать язык условных обозначений, которые соответствуют категориям ER-модели, то ее можно легко «читать», следовательно, она доступна для анализа программистам-разработчикам, которые будут разрабатывать отдельные приложения. Она имеет однозначную интерпретацию, в отличие от некоторых предложений естественного языка, и поэтому здесь не может быть никакого недопонимания со стороны разработчиков. Все специалисты всегда предпочитают выражать свои мысли на некотором формальном языке, который обеспечивает однозначную их трактовку. Таким языком для программистов раньше был язык алгоритмов. Любой алгоритм имел однозначную интерпретацию. Он мог быть реализован на разных языках программирования, но сам алгоритм был и оставался одним и тем же. В первые годы развития вычислительной техники широко издавались сборники алгоритмов для широко распространенных математических задач. Эти сборники программистами прочитывались как увлекательные детективные романы, и они все настоящим программистам были понятны, хотя специалисты других профилей смотрели на эти сборники как на издания на иностранных, неведомых им, языках. Для описания алгоритмов могли использоваться разные формализмы. Одним из таких формализмов был метаязык, в котором использовались слова на естественном языке и каждый мог прочесть эти слова, но смысл самого алгоритма мог понять только тот, кто владел знаниями трактовки алгоритмов. Вот таким условным общепринятым языком описания базы данных и стал язык ER-модели. Для ER-модели существует алгоритм однозначного преобразования ее в реляционную модель данных, что позволило в дальнейшем разработать множество инструментальных систем, поддерживающих процесс разработки информационных систем, базирующихся на технологии баз данных. И во всех этих системах существуют средства описания инфологической модели разрабатываемой БД с возможностью автоматической генерации той даталогической модели, на которой будет реализовываться проект в дальнейшем. Рассмотрим правила преобразования ER-модели в реляционную. 1. Каждой сущности ставится в соответствие отношение реляционной модели данных. При этом имена сущности и отношения могут быть различными, потому что на имена сущностей могут не накладываться дополнительные синтаксические ограничения, кроме уникальности имени в рамках модели. Имена отношений могут быть ограничены требованиями конкретной СУБД, чаще всего эти имена являются идентификаторами в некотором базовом языке, они ограничены по длине и не должны содержать пробелов и некоторых специальных символов. Например, сущность может быть названа «Книжный каталог», а соответствующее ей отношение желательно назвать, например, BOOKS (без пробелов и латинскими буквами). 2. Каждый атрибут сущности становится атрибутом соответствующего отношения. Переименование атрибутов должно происходить в соответствии с теми же правилами, что и переименование отношений в п.1. Для каждого атрибута задается конкретный допустимый в СУБД тип данных и обязательность или необязательность данного атрибута (то есть допустимость или недопустимость MULL значений для него).
Рис. 7.7. Преобразование сущности СОТРУДНИК к отношению EMPLOYEE 3. Первичный ключ сущности становится PRIMARY KEY соответствующего отношения. Атрибуты, входящие в первичный ключ отношения, автоматически получают свойство обязательности (NOT NULL).
Рис. 7.8. Свойства атрибутов отношения EMPLOYEE 4. В каждое отношение, соответствующее подчиненной сущности, добавляется набор атрибутов основной сущности, являющейся первичным ключом основной сущности. В отношении, соответствующем подчиненной сущности, этот набор атрибутов становится внешним ключом (FOREING KEY). 5. Для моделирования необязательного типа связи на физическом уровне у атрибутов, соответствующих внешнему ключу, устанавливается свойство допустимости неопределенных значений (признак NULL). При обязательном типе связи атрибуты получают свойство отсутствия неопределенных значений (признак NOT NULL). 6. Для отражения категоризации сущностей при переходе к реляционной модели возможны несколько вариантов представления. Возможно создать только одно отношение для всех подтипов одного супертипа. В него включают все атрибуты всех подтипов. Однако тогда для ряда экземпляров ряд атрибутов не будет иметь смысла. И даже если они будут иметь неопределенные значения, то потребуются дополнительные правила различения одних подтипов от других. Достоинством такого представления является то, что создается всего одно отношение.
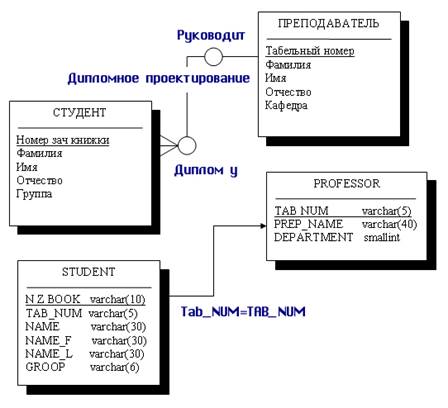
Рис. 7.9. Преобразование взаимосвязанных сущностей СТУДЕНТ и ПРЕПОДАВАТЕЛЬ к взаимосвязанным отношениям STUDENT и PROFESSOR 7. При втором способе для каждого подтипа и для супертипа создаются свои отдельные отношения. Недостатком такого способа представления является то, что создается много отношений, однако достоинств у такого способа больше, так как вы работаете только со значимыми атрибутами подтипа. Кроме того, для возможности переходов к подтипам от супертипа необходимо в супертип включить идентификатор связи. 8. Дополнительно при описании отношения между типом и подтипами необходимо указать тип дискриминатора. Дискриминатор может быть взаимоисключающим (М/Е, mutually exclusive) или нет. Если установлен данный тип дискриминатора, то это значит, что один экземпляр сущности супертипа связан только с одним экземпляром сущности подтипа и для каждого экземпляра сущности супертипа существует потомок. Кроме того, необходимо указать для второго способа, наследуется ли только идентификатор супертипа в подтипы или наследуются все атрибуты супертипа. 9. Если мы зададим наследование только идентификатора, то мы получим следующее преобразование (см. рис. 7.10 и 7.11).
Рис. 7.10. Исходная модель взаимосвязи супертипа и подтипов
Рис.7.11. Результирующая модель с наследованием только идентификатора суперсущности Разрешение связей типа «многие-ко-многим». Так как в реляционной модели данных поддерживаются между отношениями только связи типа «один-ко-мно-гим», а в ER-модели допустимы связи «многие-ко-многим», то необходим специальный механизм преобразования, который позволит отразить множественные связи, неспецифические для реляционной модели, с помощью допустимых для нее категорий. Это делается введением специального дополнительного связующего отношения, которое связано с каждым исходным связью «один-ко-мно-гим», атрибутами этого отношения являются первичные ключи связываемых отношений. Так, например, в схеме «Библиотека» присутствует связь такого типа между сущностью «Книги» и «Системный каталог». Для разрешения этой неспецифической связи при переходе к реляционной модели должно быть введено специальное дополнительное отношение, которое имеет всего два атрибута: ISBN (шифр книги) и KOD (код области знаний). При этом каждый из атрибутов нового отношения является внешним ключом (FORKING KEY), а вместе они образуют первичный ключ (PRIMARY KEY) новой связующей сущности. На рис. 7.12 представлена реляционная модель, соответствующая представленной ранее на рис. 7.6 инфологической модели «Библиотека». Теория нормализации, которую мы рассматривали ранее применительно к реляционной модели, применима и к модели «сущность—связь». Поэтому нормализацию можно проводить и на уровне мифологической (семантической) модели и смысл ее аналогичен нормализации реляционной модели. Алгоритм приведения семантической модели к 5-й нормальной форме может быть следующим:
Рис. 7.12. Результирующая модель с наследованием всех атрибутов суперсущности Шаг 1. Проанализировать схему на присутствие сущностей, которые скрыто моделируют несколько разных взаимосвязанных классов объектов реального мира (именно это соответствует ненормализованным отношениям). Если такое выявлено, то разделить каждую из этих сущностей на несколько новых сущностей и установить между ними соответствующие связи, полученная схема будет находиться в первой нормальной форме. Перейти к шагу 2. Шаг 2. Проанализировать все сущности, имеющие составные первичные ключи, на наличие неполных функциональных зависимостей непервичных атрибутов от атрибутов возможного ключа. Если такие зависимости обнаружены, то разделить данные сущности на 2, определить для каждой сущности первичные ключи и установить между ними соответствующие связи. Полученная схема будет находиться во второй нормальной форме. Перейти к шагу 3. Шаг 3. Проанализировать неключевые атрибуты всех сущностей на наличие транзитивных функциональных зависимостей. При обнаружении таковых расщепить каждую сущность на несколько таким образом, чтобы ликвидировать транзитивные зависимости. Схема находится в третьей нормальной форме. Перейти к шагу 4. Шаг 4. Проанализировать все сущности на наличие детерминантов, которые не являются возможными ключами. При обнаружении подобных расщепить сущность на две, установив между ними соответствующие связи. Полученная схема соответствует нормальной форме Бойса—Кодда. Перейти к шагу 5. Шаг 5. Проанализировать все сущности на наличие многозначных зависимостей. Если обнаружатся сущности, у которых имеется более одной многозначной зависимости, то расщепить такие сущности на две, установив между ними соответствующие связи. Полученная схема будет находиться в четвертой нормальной форме. Перейти к шагу 6.
Рис. 7.13. Реляционная схема «Библиотека» Шаг 6. Проанализировать сущности на наличие в них зависимостей проекции-соединения. При обнаружении таковых расщепить сущность на требуемое число взаимосвязанных сущностей и установить между ними требуемые связи. Полученная таким образом схема будет находиться в пятой нормальной форме и, будучи формально преобразованной к реляционной схеме по указанным выше принципам, даст реляционную схему также в пятой нормальной форме. · Глава 8. Принципы поддержки целостности в реляционной модели данных o Общие понятия и определения целостности o Операторы DDL в языке SQL с заданием ограничений целостности o Средства определения схемы базы данных o Средства изменения описания таблиц и средства удаления таблиц o Понятие представления операции создания представлений § Горизонтальное представление § Вертикальное представление § Сгруппированные представления § Объединенные представления § Ограничение стандарта SQL1 на обновление представлений ГЛАВА 8. Принципы поддержки целостности в реляционной модели данных Одним из основополагающих понятий в технологии баз данных является понятие целостности. В общем случае это понятие прежде всего связано с тем, что база данных отражает в информационном виде некоторый объект реального мира или совокупность взаимосвязанных объектов реального мира. В реляционной модели объекты реального мира представлены в виде совокупности взаимосвязанных отношений. Под целостностью будем понимать соответствие информационной модели предметной области, хранимой в базе данных, объектам реального мира и их взаимосвязям в каждый момент времени. Любое изменение в предметной области, значимое для построенной модели, должно отражаться в базе данных, и при этом должна сохраняться однозначная интерпретация информационной модели в терминах предметной области. Мы отметили, что только существенные или значимые изменения предметной области должны отслеживаться в информационной модели. Действительно, модель всегда представляет собой некоторое упрощение реального объекта, в модели мы отражаем только то, что нам важно для решения конкретного набора задач. Именно поэтому в информационной системе «Библиотека» мы, например, не отразили место хранения конкретных экземпляров книг, потому что мы не ставили задачу автоматической адресации библиотечных стеллажей. И в этом случае любое перемещение книг с одного места на другое не будет отражено в модели, это перемещение несущественно для наших задач. С другой стороны, процесс взятия книги читателем или возврат любой книги в библиотеку для нас важен, и мы должны его отслеживать в соответствии с изменениями в реальной предметной области. И с этой точки зрения наличие у экземпляра книги указателя на его отсутствие в библиотеке и одновременное отсутствие записи о конкретном номере читательского билета, за которым числится этот экземпляр книга, является противоречием, такого быть не должно. И в модели данных должны быть предусмотрены средства и методы, которые позволят нам обеспечивать динамическое отслеживание в базе данных согласованных действий, связанных с согласованным изменением информации. Именно этим вопросам и посвящена данная глава. Общие понятия и определения целостности Поддержка целостности в реляционной модели данных в ее классическом понимании включает в себя 3 аспекта. Во-первых, это поддержка структурной целостности, которая трактуется как то, что реляционная СУБД должна допускать работу только с однородными структурами данных типа «реляционное отношение». При этом понятие «реляционного отношения» должно удовлетворять всем ограничениям, накладываемым на него в классической теории реляционной БД (отсутствие дубликатов кортежей, соответственно обязательное наличие первичного ключа, отсутствие понятия упорядоченности кортежей). В дополнение к структурной целостности необходимо рассмотреть проблему неопределенных Null значений. Как уже указывалось раньше, неопределенное значение интерпретируется в реляционной модели как значение, неизвестное на данный момент времени. Это значение при появлении дополнительной информации в любой момент времени может быть заменено на некоторое конкретное значение. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно неопределенное значение никогда не считается равным другому неопределенному значению. Для выявления равенства значения некоторого атрибута неопределенному применяют специальные стандартные предикаты: <имя атрибута>IS NULL и <имя атрибута> IS NOT NULL. Если в данном кортеже (в данной строке) указанный атрибут имеет неопределенное значение, то предикат IS NULL принимает значение TRUE (Истина), а предикат IS NOT NULL — FALSE (Ложь), в противном случае предикат IS NULL принимает значение FALSE, а предикат IS NOT NULL принимает значение TRUE. Ведение Null значений вызвало необходимость модификации классической двузначной логики и превращения ее в трехзначную. Все логические операции, производимые с неопределенными значениями, подчиняются этой логике в соответствии с заданной таблицей истинности. Таблица 8.1. Таблица истинности для логических операций с неопределенными значениями,
В стандарте SQL2 появилась возможность сравнивать не только конкретные значения атрибутов с неопределенным значением, но и результаты логических выражений сравнивать с неопределенным значением, для этого введена специальная логическая константа UNKNOWN. В этом случае операция сравнения выглядит как: Логическое выражение> IS {TRUE | FALSE | UNKNOWN} Во-вторых, это поддержка языковой целостности, которая состоит в том, что реляционная СУБД должна обеспечивать языки описания и манипулирования данными не ниже стандарта SQL. He должны быть доступны иные низкоуровневые средства манипулирования данными, не соответствующие стандарту. Именно поэтому доступ к информации, хранимой в базе данных, и любые изменения этой информации могут быть выполнены только с использованием операторов языка SQL. В-третьих, это поддержка ссылочной целостности (Declarative Referential Integrity, DRI), означает обеспечение одного из заданных принципов взаимосвязи между экземплярами кортежей взаимосвязанных отношений: · кортежи подчиненного отношения уничтожаются при удалении кортежа основного отношения, связанного с ними. · кортежи основного отношения модифицируются при удалении кортежа основного отношения, связанного с ними, при этом на месте ключа родительского отношения ставится неопределенное Null значение. Ссылочная целостность обеспечивает поддержку непротиворечивого состояния БД в процессе модификации данных при выполнении операций добавления или удаления. Кроме указанных ограничений целостности, которые в общем виде не определяют семантику БД, вводится понятие семантической поддержки целостности. Структурная, языковая и ссылочная целостность определяют правила работы СУБД с реляционными структурами данных. Требования поддержки этих трех видов целостности говорят о том, что каждая СУБД должна уметь это делать, а разработчики должны это учитывать при построении баз данных с использованием реляционной модели. И эти требования поддержки целостности достаточно абстрактны, они определяют допустимую форму представления и обработки информации в реляционных базах данных. Но с другой стороны, эти аспекты никак не касаются содержания базы данных. Для определения некоторых ограничений, которые связаны с содержанием базы данных, требуются другие методы. Именно эти методы и сведены в поддержку семантической целостности. Давайте рассмотрим конкретный пример. То, что мы можем построить схему базы данных или ее концептуальную модель только из совокупности нормализованных таблиц, определяет структурную целостность. И мы построили нашу схему библиотеки из пяти взаимосвязанных отношений. Но мы не можем с помощью перечисленных трех методов поддержки целостности обеспечить ряд правил, которые определены в нашей предметной области и должны в ней соблюдаться. К таким правилам могут быть отнесены следующие: 1. В библиотеке должны быть записаны читатели не моложе 17 лет. 2. В библиотеке присутствуют книги, изданные начиная с 1960 по текущий год. 3. Каждый читатель может держать на руках не более 5 книг. 4. 4. Каждый читатель при регистрации в библиотеке должен дать телефон для связи: он может быть рабочим или домашним. Принципы семантической поддержки целостности как раз и позволяют обеспечить автоматическое выполнение тех условий, которые перечислены ранее. Семантическая поддержка может быть обеспечена двумя путями: декларативным и процедурным путем. Декларативный путь связан с наличием механизмов в рамках СУБД, обеспечивающих проверку и выполнение ряда декларативно заданных правил-ограничений, называемых чаще всего «бизнес-правилами» (Business Rules) или декларативными ограничениями целостности. Выделяются следующие виды декларативных ограничений целостности: · Ограничения целостности атрибута: значение по умолчанию, задание обязательности или необязательности значений (Null), задание условий на значения атрибутов. Задание значения по умолчанию означает, что каждый раз при вводе новой строки в отношение, при отсутствии данных в указанном столбце этому атрибуту присваивается именно значение по умолчанию. Например, при вводе новых книг разумно в качестве значения по умолчанию для года издания задать значение текущего года. Например, для MS Access 97 это выражение будет иметь вид: YEAR(NOW()) Здесь NOW() — функция, возвращающая значение текущей даты, YEAR(data) — функция, возвращающая значение года указанной в качестве параметра даты. В качестве условия на значение для года издания надо задать выражение, которое будет истинным только тогда, когда год издания будет лежать в пределах от 1960 года до текущего года. В конкретных СУБД это значение будет формироваться с использованием специальных встроенных функций СУБД. Для MS Access 97 это выражение будет выглядеть следующим образом: Between 1960 AND YEAR(NOW()) В СУБД MS SQL Server7.0 значение по умолчанию записывается в качестве «бизнес-правила». В этом случае будет использоваться выражение, в котором явным образом должно быть указано имя соответствующего столбца, например: YEAR_PUBL >= 1960 AND YEAR_PUBL <- YEAR(GETDATE()) Здесь GETDATE() — функция MS SQL Server7.0, возвращающая значение текущей даты, YEAR_PUBL — имя столбца, соответствующего году издания. · Ограничения целостности, задаваемые на уровне доменов, при поддержке доменной структуры. Эти ограничения удобны, если в базе данных присутствуют несколько столбцов разных отношений, которые принимают значения из одного и того же множества допустимых значений. Некоторые СУБД поддерживают подобную доменную структуру, то есть разрешают определять отдельно домены, задавать тип данных для каждого домена и задавать соответственно ограничения в виде бизнес-правил для доменов. А для атрибутов задается не примитивный первичный тип данных, а их принадлежность тому или другому домену. Иногда доменная структура выражена неявно и в ряде СУБД применяется специальная терминология для этого. Так, например, в MS SQL Server 7.0 вместо понятия домена вводится понятие типа данных, определенных пользователем, но смысл этого типа данных фактически эквивалентен смыслу домена. В этом случае действительно удобно задать ограничение на значение прямо на уровне домена, тогда оно автоматически будет выполняться для всех атрибутов, которые принимают значения из этого домена. А почему удобно задать это ограничение на уровне домена? А если мы зададим это ограничение для каждого атрибута, входящего в домен, разве наша система будет работать неправильно? Нет, конечно, она будет работать правильно, но представьте себе, что у вас в организации изменились правила работы, которые выражены в виде декларативных ограничений на значения. В нашем случае, например, мы будем комплектовать библиотеку более новыми книгами и теперь будем принимать в библиотеку книги, изданные не позднее 1980 года. А если это ограничение у нас задано не на один столбец, то нам надо просматривать все отношения и во всех отношениях менять старое правило на новое. Не легче ли заменить его один раз в домене, а все атрибуты, которые принимают значения из этого домена, будут автоматически работать по новому правилу. Да, это действительно легче, тем более что в процессе работы схема базы данных разрастается и начинает содержать более сотни отношений, и задача нетривиальная — найти все отношения, в которых ранее установлено это ограничение и исправить его. Одним из основных правил при разработке проекта базы данных, как мы уже упоминали раньше, является минимизация избыточности, а это означает, что если возможно информацию о чем-то, в том числе и об ограничениях, хранить в одном месте, то это надо делать обязательно. · Ограничения целостности, задаваемые на уровне отношения. Некоторые семантические правила невозможно преобразовать в выражения, которые будут применимы только к одному столбцу. В нашем примере с библиотекой мы не сможем выразить требование наличия по крайней мере одного телефонного номера для быстрой связи с читателем. У нас под телефоны отведены два столбца, это в некотором роде искусственно, но специально так сделано, чтобы показать вам другой тип ограничений. Каждый из атрибутов является в общем случае необязательным и может принимать неопределенные значения: не обязательно должен быть задан как рабочий, так и домашний телефон. Мы хотим потребовать, чтобы из двух по крайней мере один телефон был бы задан обязательно. Попробуем сформулировать это в терминологии неопределенных значений баз данных. Домашний телефон должен быть задан (NOT NULL) или рабочий телефон должен быть задан (NOT NULL). Для MS Access97 или для MS SQL Server97 соответствующее выражение будет выглядеть следующим образом: HOME_PHON IS NOT NULL OR WORK_PHON IS NOT NULL · Ограничения целостности, задаваемые на уровне связи между отношениями: задание обязательности связи, принципов каскадного удаления и каскадного изменения данных, задание поддержки ограничений по мощности связи. Эти виды ограничений могут быть выражены заданием обязательности или необязательности значений внешних ключей во взаимосвязанных отношениях. Декларативные ограничения целостности относятся к ограничениям, которые являются немедленно проверяемыми. Есть ограничения целостности, которые являются откладываемыми. Эти ограничения целостности поддерживаются механизмом транзакций и триггеров. Мы их рассмотрим в следующих главах. Операторы DDL в языке SQL с заданием ограничений целостности Декларативные ограничения целостности задаются на уровне операторов создания таблиц. В стандарте SQL оператор создания таблиц имеет следующий синтаксис: определение таблицы>::=CREATE TABLE <имя таблицы> (<описание элемента таблицы> [{.<описание элемента таблицы>}...]) <описание элемента таблицы>::=<определение столбца>| <определение ограничений таблицы> определение столбца>::=<имя столбца> <тип данных> [<значение по умолчанию>][<дополнительные ограничения столбца>...] <значение по умолчанию>::=DEFAULT { <litera1> | USER | NULL } дополнительные ограничения столбца>::=NOT NULL [ограничение уникальности столбца>]| <ограничение по ссылкам столбца>| CHECK (<условия проверки на допустимость>) ограничение уникальности столбца>::= UNIQUE <ограничение по ссылкам столбца>::=FOREIGN KEY спецификация ссылки> спецификация ссылки>::= REFERENCES <имя основной таблицы> (<имя первичного ключа основной таблицы>) Давайте кратко прокомментируем оператор определения таблицы, синтаксис которого мы задали с помощью традиционной формы Бэкуса—Наура. При описании таблицы задается имя таблицы, которое является идентификатором в базовом языке СУБД и должно соответствовать требованиям именования объектов в данном языке. Кроме имени таблицы в операторе указывается список элементов таблицы, каждый из которых служит либо для определения столбца, либо для определения ограничения целостности определяемой таблицы. Требуется наличие хотя бы одного определения столбца. То есть таблицу, которая не имеет ни одного столбца, определить нельзя. Количество столбцов в одной таблице не ограничено, но в конкретных СУБД обычно бывают ограничения на количество атрибутов. Так, например, в MS SQL Server 6.5 максимальное количество столбцов в таблице было 250, но уже в MS SQL Server 7.0 оно увеличено до 1024. Оператор CREATE TABLE определяет так называемую базовую таблицу, то есть реальное хранилище данных. Как видно, кроме обязательной части, в которой задается имя столбца и его тип данных, определение столбца может содержать два необязательных раздела: значение столбца по умолчанию и раздел дополнительных ограничений целостности столбца. В разделе значения по умолчанию указывается значение, которое должно быть помещено в строку, заносимую в данную таблицу, если значение данного столбца явно не указано. В соответствии со стандартом языка SQL значение по умолчанию может быть указано в виде литеральной константы с типом, соответствующим типу столбца; путем задания ключевого слова USER, которому при выполнении оператора занесения строки соответствует символьная строка, содержащая имя текущего пользователя (в этом случае столбец должен иметь тип символьных строк); или путем задания ключевого слова NULL, означающего, что значением по умолчанию является неопределенное значение. Если значение столбца по умолчанию не специфицировано и в разделе ограничений целостности столбца указано NOT NULL (то есть наличие неопределенных значений запрещено), то попытка занести в таблицу строку с незаданным значением данного столбца приведет к ошибке. Задание в разделе ограничений целостности столбца выражения NOT NULL приводит к неявному порождению проверочного ограничения целостности для всей таблицы "CHECK (С IS NOT NULL)" (где С — имя данного столбца). Если ограничение NOT NULL не указано и раздел умолчаний отсутствует, то неявно порождается раздел умолчаний DEFAULT NULL. Если указана спецификация уникальности, то порождается соответствующая спецификация уникальности для таблицы. При задании ограничений уникальности данный столбец определяется как возможный ключ, что предполагает уникальность каждого вводимого значения в данный столбец. И если это ограничение задано, то СУБД будет автоматически осуществлять проверку на отсутствие дубликатов значений данного столбца во всей таблице. Если в. разделе ограничений целостности указано ограничение по ссылкам данного столбца, то порождается соответствующее определение ограничения по ссылкам для таблицы: FOREIGN КЕУ(<имя столбца>) <спецификация ссылки>, что означает, что значения данного столбца должны быть взяты из соответствующего столбца родительской таблицы. Родительской таблицей в данном случае называется таблица, которая связана с данной таблицей связью «один-ко-многим» (1:М). При этом каждая строка родительской таблицы может быть связана с несколькими строками определяемой таблицы. Трансляция операторов SQL проводится в режиме интерпретации, поэтому важно, чтобы сначала была бы описана родительская таблица, а потом уже все подчиненные (дочерние) таблицы, связанные с ней. Иначе транслятор определит ссылку на неопределенный объект. Наконец, если указано проверочное ограничение столбца, то условие поиска этого ограничения должно ссылаться только на данный столбец, и неявно порождается соответствующее проверочное ограничение для всей таблицы. В проверочных ограничениях, накладываемых на столбец, нельзя задавать сравнение со значениями других столбцов данной таблицы. В главе 5 определены типы данных, которые допустимы по стандартам SQL. Попробуем написать простейший оператор создания таблицы BOOKS из базы данных «Библиотека». При этом будем предполагать наличие следующих ограничений целостности: · Шифр книги — последовательность символов длиной не более 14, однозначно определяющая книгу, значит, это — фактически первичный ключ таблицы BOOKS. · Название книги — последовательность символов, не более 120. Обязательно должно быть задано. · Автор — последовательность символов, не более 30, может быть не задан. · Соавтор — последовательность символов, не более 30, может быть не задан. · Год издания — целое число, не менее 1960 и не более текущего года. По умолчанию ставится текущий год. · Издательство — последовательность символов, не более 20, может отсутствовать. · Количество страниц — целое число не менее 5 и не более 1000. CREATE TABLE BOOKS ( ISBN varchar(14) NOT NULL PRIMARY KEY, TITLE varchar(120) NOT NULL. AUTOR varchar (30) NULL. COAUTOR varchar(30) NULL, YEAR_PUBLsmallint DEFAULT Year(GetDate()) CHECK(YEAR_PUBL >= 1960 AND YEAR PUBL <= YEAR(GetDate())), PUBLICH varchar(20) NULL. PAGES smalllnt CHECK(PAGES > = 5 AND PAGES <= 1000) ); Почему мы не задали обязательность значения для количества страниц в книге? Потому что это является следствием проверочного ограничения, заданного на количество страниц, количество страниц всегда должно лежать в пределах от 5 до 1000, значит, оно не может быть незаданным и система это контролирует автоматически. Теперь зададим описание таблицы «Читатели», которой соответствует отношение READERS: · Номер читательского билета — это целое число в пределах 32 000 и он уникально определяет читателя. · Имя, фамилия читателя — это последовательность символов, не более 30. · Адрес — это последовательность символов, не более 50. · Номера телефонов рабочего и домашнего — последовательность символов, не более 12. · Дата рождения — календарная дата. В библиотеку принимаются читатели не младше 17 лет. CREATE TABLE READERS ( READER_ID Smallint(4) PRIMARY KEY. FIRST_NAME char(30) NOT NULL. LAST_NAME char(30) NOT NULL. ADRES char(50). HOME_PHON char(12). WORK_PHON chart 12), BIRTH_DAYdate CHECK(DateDiff(year. GetDate(),BIRTH_DAY) >=17) ); Здесь DateDiff (часть даты, начальная дата, конечная дата) — функция MS SQL Server 7.0, которая определяет разность между начальной и конечной датами, заданную в единицах, определенных первым параметром — часть даты. Мы задали в качестве параметра Year, что значит, что мы разность определяем в годах. Теперь зададим операцию создания таблицы EXEMPLAR (экземпляры книги). В этой таблице первичным ключом является атрибут, задающий инвентарный номер экземпляра книги. В такой постановке мы полагаем, что при поступлении книг в библиотеку им просто присваиваются соответствующие порядковые номера. Для того чтобы не утруждать библиотекаря все время помнить, какой номер был последним, мы можем воспользоваться тем, что некоторые СУБД допускают специальный инкрементный тип данных, то есть такой, значения которого автоматически увеличиваются или уменьшаются на заданную величину при каждом новом вводе данных. В СУБД MS Access такой тип данных называется «счетчик» (counter) и он всегда имеет начальное значение 1 и шаг, равный тоже 1, то есть при вводе каждого нового значения счетчик увеличивается на 1, значит, практически считает вновь введенные значения. В СУБД MS SQL Server 7.0 это свойство -IDENTITY, которое может быть присвоено ряду целочисленных типов данных. В отличие от «счетчика» свойство IDENTITY позволяет считать с любым шагом, положительным или отрицательным, но обязательно целым. Если мы не задаем дополнительных параметров этому свойству, то оно начинает работать как счетчик в MS Access, начиная с единицы и добавляя при каждом вводе тоже единицу. Кроме того, таблица EXEMPLAR является подчиненной двум другим ранее определенным таблицам: BOOKS и READERS. При этом с таблицей BOOKS таблица EXEMPLAR связана обязательной связью, потому что не может быть ни одного экземпляра книги, который бы не был приписан конкретной книге. С таблицей READERS таблица EXEMPLAR связана необязательной связью, потому что не каждый экземпляр в данный момент находится на руках у читателя. Для моделирования этих связей при создании таблицы EXEMPLAR должны быть определены два внешних ключа (FOREIGN KEY). При этом атрибут, соответствующий шифру книги (мы его назовем так же, как и в родительской таблице — ISBN), является обязательным, то есть не может принимать неопределенных значений, а атрибут, который является внешним ключом для связи с таблице READERS, является необязательным и может принимать неопределенные значения. Необязательными там являются два остальных атрибута: дата взятия и дата возврата книги, оба они имеют тип данных, соответствующей календарной дате. Атрибут, который содержит информацию о присутствии или отсутствии книги, имеет логический тип. Напишем оператор создания таблицы EXEMPLAR в синтаксисе MS SQL Server 7.0: CREATE TABLE EXEMPLAR ( EXEMPLAR_ID | NT IDENTITY PRIMARY KEY, ISBN varchar(14) NOT NULL FOREIGN KEY references BOOKS(ISBN), READERJD Smallint(4) NULL FOREIGN KEY references READERS (READERJD). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| Поделиться: |