Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Теоретико-графовые модели данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Как уже упоминалось ранее, эти модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. В зависимости от типа графа выделяют иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной. Иерархическая модель данных Иерархическая модель данных является наиболее простой среди всех даталогических моделей. Исторически она появилась первой среди всех даталогических моделей: именно эту модель поддерживает первая из зарегистрированных промышленных СУБД IMS фирмы IBM. Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов. Иерархия проста и естественна в отображении взаимосвязи между классами объектов. Основными информационными единицами в иерархической модели являются: база данных (БД), сегмент и поле. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Например, если в задачах требуется печатать в документах адрес клиента, но не требуется дополнительного анализа полного адреса, то есть города, улицы, дома, квартиры, то мы можем принять весь адрес за элемент данных, и он будет храниться полностью, а пользователь сможет получить его только как полную строку символов из БД. Если же в наших задачах существует анализ частей, составляющих адрес, например города, где расположен клиент, то нам необходимо выделить город как отдельный элемент данных, только в этом случае пользователь может получить к нему доступ и выполнить, например, запрос на поиск всех клиентов, которые проживают в конкретном городе, например в Париже. Однако если пользователю понадобится и полный адрес клиента, то остальную информацию по адресу также необходимо хранить в отдельном поле, которое может быть названо, например, Сокращенный адрес. В этом случае для каждого клиента в БД хранится как Город, так и Сокращенный адрес. Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи. Тип сегмента — это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающий сотрудника организации, мы должны выделить те характеристики сотрудника, которые могут его однозначно идентифицировать в рамках БД предприятия. Если предположить, что на предприятии могут работать однофамильцы, то, вероятно, наиболее надежным будет идентифицировать сотрудника по его табельному номеру. Однако если мы будем строить БД, содержащую описание множества граждан, например нашей страны, то, скорее всего, нам придется в качестве ключа выбрать совокупность полей, отражающих его паспортные данные. В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента. Тип сегмента, находящийся на более высоком уровне иерархии, называется логически исходным по отношению к типам сегментов, соединенным с данным направленными иерархическими ребрами, которые в свою очередь называются логически подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-предками, а подчиненные сегменты называют сегментами-потомками.
Рис. 3.1. Пример иерархических связей между сегментами На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели. Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической базой данных. Каждая физическая БД удовлетворяет следующим иерархическим ограничениям: · в каждой физической БД существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента; · каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов; · каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским) сегментом. Очень важно понимать различие между сегментом и типом сегмента — оно такое же, как между типом переменной и самой переменной: сегмент является экземпляром типа сегмента. Например, у нас может быть тип сегмента Группа (Номер, Староста) и сегменты этого типа, такие как (4305, Петров Ф. И.) или (383, Кустова Т. С.). Между экземплярами сегментов также существуют иерархические связи. Рассмотрим, например, иерархический граф, представленный на рис. 3.2.
Рис. 3.2. Пример структуры иерархического дерева Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи. На рис. 3.3 представлены 2 экземпляра иерархического дерева соответствующей
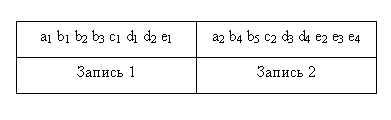
Рис. 3.3. Пример двух экземпляров данного дерева Экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-предка, называют «близнецами». Так, для нашего примера экземпляры b1, b2 и bЗ являются «близнецами», но экземпляр b4 подчинен другому экземпляру родительского сегмента, и он не является «близнецом» по отношению к экземплярам b1, b2 и bЗ. Набор всех экземпляров сегментов, подчиненных одному экземпляру корневого сегмента, называется физической записью. Количество экземпляров-потомков может быть разным для разных экземпляров родительских сегментов, поэтому в общем случае физические записи имеют разную длину. Так, используя принцип линейной записи иерархических графов, пример на рис 3.3 можно представить в виде двух записей:
Как видно из нашего примера, физические записи в иерархической модели различаются по длине и структуре. Язык описания данных иерархической модели В рамках иерархической модели выделяют языковые средства описания данных (DDL, Data Definition Language) и средства манипулирования данными (DML, Data Manipulation Language). Каждая физическая база описывается набором операторов, определяющих как ее логическую структуру, так и структуру хранения БД. Описание начинается с оператора DBD (Data Base Definition): DBD Name = < имя БД>, ACCESS = < способ доступа> Способ доступа определяет способ организации взаимосвязи физических записей. Определено 5 способов доступа: HSAM — hierarchical sequential access method (иерархически последовательный метод), HISAM — hierarchical index sequential access method (иерархически индексно-последовательный метод), EDAM — hierarchical direct access method (иерархически прямой метод), HID AM — hierarchical index direct access method (иерархически индексно-прямой метод), INDEX — индексный метод. Далее идет описание наборов данных, предназначенных для хранения БД: DATA SET D01 = < имя оператора, определяющего хранимый набор данных>. DEVICE =< устройство хранения БД>, [OVFLW = < имя области переполнения>] Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться и превысит исходную длину записи до модификации. В этом случае при определенных методах хранения может понадобиться дополнительное пространство хранения, где и будут размещены дополнительные данные. Это пространство и называется областью переполнения. После описания всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш с иерархией. Описание сегментов всегда начинается с описания корневого сегмента. Общая схема описания типа сегмента такова: SEGM NAME = < имя сегмента>. BYTES =< размер в байтах>. FREQ = <средняя частота реализаций сегмента под одним исходным> PARENT = <имя родительского сегмента> Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром родительского сегмента. Для корневого сегмента это число возможных экземпляров корневого сегмента. Для корневого сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание полей: FIELD NAME = {(<имя поля> [. SEQ].{U M}) | <имя поля> }. START = < номер байта, с которого начинается значения поля >, BYTES = <размер поля в байтах>, TYPE = {X | Р | С} Признак SEQ — задается для ключевого поля, если экземпляры данного сегмента физически упорядочены в соответствии со значениями данного поля. Параметр U задается, если значения ключевого поля уникальны для всех экземпляров данного сегмента, М — в противном случае. Если поле является ключевым, то его описание задается в круглых скобках, в противном случае имя поля задается без скобок. Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С — символьный. Заканчивается описание схемы вызовом процедуры генерации: · DBDGEN — указывает на конец последовательности управляющих операторов описания БД; · FINISH — устанавливает ненулевой код завершения при обнаружении ошибки; · END — конец. В системе может быть несколько физических БД (ФБД), но каждая из них описывается отдельно своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один корневой сегмент. Совокупность ФБД образует концептуальную модель данных. Внешние модели При работе с иерархической моделью каждая программа, пользователь или приложение определяет свою внешнюю модель. Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данный пользователь. Каждый подграф внешней модели в обязательном порядке должен содержать корневой тип сегмента соответствующей физической базы данных концептуальной модели. Представление внешней модели называется логической базой данных и определяется совокупностью блоков связи данного приложения с физическими БД, входящими в концептуальную схему БД. Блок связи — РСВ, program communication bloc — описывает связь с одной физической БД по следующим правилам: DBD NAME = < имя логической БД (подсхемы)>, ACCESS = LOGICAL DATA SET = LOGICAL. SEGM NAME = <имя сегмента в подсхеме>, PARENT =<имя родительского сегмента в подсхеме>, SOURSE =(Имя соответствующего сегмента ФБД. имя ФБД) DBDGEN FINISH END Совокупность блоков РСВ образует полное внешнее представление данного приложения, называемое «блоком спецификации программ» (PSB, program specification block). Рассмотрим пример иерархической БД. Наша организация занимается производством и продажей компьютеров, в рамках производства мы комплектуем компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько базовых моделей, которые мы продаем без предварительных заказов по наличию на складе. В организации существуют несколько филиалов (рис. 3.4) и несколько складов, на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции.
Рис. 3.4. Физическая БД «Филиалы» Какие задачи нам надо решать в ходе разработки приложения? · При приеме заказа мы должны выяснить, какую модель заказывает заказчик: типичную или индивидуальную комплектацию. · Если заказывается типичная модель, то выясняется, какая модель и есть ли она в наличии, если модель есть, то надо уменьшить количество компьютеров данной модели в данном филиале на покупаемое количество. На этом будем считать заказ выполненным, однако при оформлении заказа может потребоваться задание полной спецификации покупаемого изделия. · Если заказывается индивидуальная модель, то требуется описать весь состав новой модели. Для того чтобы можно было бы принимать заказы на индивидуальные модели, нам понадобится информация о наличие конкретных деталей на складе, в этом случае нам необходимо второе дерево — Склады (см. рис. 3.5).
Рис. 3.5. Физическая модель «Склады» Язык манипулирования данными в иерархических базах данных Для доступа к базе данных у пользователя должна быть сформирована специальная среда окружения, поддерживающая в явном виде имеющиеся навигационные операции. Для этого в ней должны храниться: · шаблоны всех записей логических баз данных, доступных пользователю; · указатели на текущий экземпляр сегмента данного типа — для всех типов сегментов. Язык манипулирования данными в иерархической модели поддерживает в явном виде навигационные операции. Эти операции связаны с перемещением указателя, который определяет текущий экземпляр конкретного сегмента. Все операторы в языке манипулирования данными можно разделить на 3 группы. Первую группу составляют операторы поиска данных. Операторы поиска данных Синтаксис: GET UNIQUE <имя сегмента> WHERE <список поиска>; список поиска состоит из последовательности условий вида: <имя сегмента>.<имя поля>ОС <constant или имя другого поля данного сегмента или имя переменной>: ОС — операция сравнения; условия могут быть соединены логическими операциями И и ИЛИ {&, V}. Назначение: Получить единственное значение. Пример: Найти типовую модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах. GET UNIQUE ТИПОВЫЕ МОДЕЛИ WHERE Типовые модели.Стоимость <= $600 AND Типовые модели,Количество на складе >= 10 Данная команда всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента, удовлетворяющий условиям поиска. Синтаксис: GET NEXT <имя сегмента> WHERE <список аргументов поиска> Назначение: Получить следующий экземпляр сегмента для тех же условии. Пример: Напечатать полный список заказов стоимостью не менее $500. GET UNIQUE ИНДИВИДУАЛЬНЫЕ МОДЕЛИ WHERE Индивидуальные модели.Стоимость >- $500 WHILE NOT EAIL (пока не конец поиска) DO PRINT № заказа. Стоимость, Количество GET NEXT ИНДИВИДУАЛЬНЫЕ МОДЕЛИ END Синтаксис: GET NEXT <имя сегмента> WITHIN PARENT [ where <дополн.условия>]
Назначение: Получить следующий для того же исходного. Пример: Получить перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10 с объемом 10 Гбайт. GET UNIQUE СКЛАД WHERE Склад.Номер = 1 GET NEXT ИЗДЕЛИЕ WITHIN PARENT WHERE Изделие.Наименование = "Винчестер" GET NEXT ХАРАКТЕРИСТИКИ WITHIN PARENT WHERE ХАРАКТЕРИСТИКИ.Параметр = 10 AND ХАРАКТЕРИСТИКИ.Единицы Измерения = Гб AND ХАРАКТЕРИСТИКИ.Величина > 10 While Not Fail (пока поиск не завершен) DO Get Next Within Parent end
|
||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 620; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.113 (0.009 с.) |