Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели физической организации данных при бесфайловой организацииСодержание книги
Поиск на нашем сайте
Файловая структура и система управления файлами являются прерогативой операционной среды, поэтому принципы обмена данными подчиняются законам операционной системы. По отношению к базам данных эти принципы могут быть далеки от оптимальности. СУБД подчиняется несколько иным принципам и стратегиям управления внешней памятью, чем те, которые поддерживают операционные среды для большинства пользовательских процессов или задач. Это и послужило причиной того, что СУБД взяли на себя непосредственное управление внешней памятью. При этом пространство внешней памяти предоставляется СУБД полностью для управления, а операционная среда не получает непосредственного доступа к этому пространству. Физическая организация современных баз данных является наиболее закрытой, она определяется как коммерческая тайна для большинства поставщиков коммерческих СУБД. И здесь не существует никаких стандартов, поэтому в общем случае каждый поставщик создает свою уникальную структуру и пытается обосновать ее наилучшие качества по сравнению со своими конкурентами. Физическая организация является в настоящий момент наиболее динамичной частью СУБД. Стремительно расширяются возможность устройств внешней памяти, дешевеет оперативная память, увеличивается ее объем и поэтому изменяются сами принципы организации физических структур данных. И можно предположить, что и в дальнейшем эта часть современных СУБД будет постоянно меняться. Поэтому при рассмотрении моделей данных, используемых для физического хранения и обработки, мы коснемся только наиболее общих принципов и тенденций. При распределении дискового пространства рассматриваются две схемы структуризации: физическая, которая определяет хранимые данные, и логическая, которая определяет некоторые логические структуры, связанные с концептуальной моделью данных (рис. 9.12).
Рис. 9.12. Классификация объектов при статичной организации физической модели данных Определим некоторые понятия, используемые в указанной классификации. Чанк (chank) — представляет собой часть диска, физическое пространство на диске, которое ассоциировано одному процессу (on line процессу обработки данных). Чанком может быть назначено неструктурированное устройство, часть этого устройства, блочно-ориентированное устройство или просто файл UNIX. Чанк характеризуется маршрутным именем, смещением (от физического начала устройства до начальной точки на устройстве, которая используется как чанк), размером, заданным в Кбайтах или Мбайтах. При использовании блочных устройств и файлов величина смещения считается равной нулю. Логические единицы образуются совокупностью экстентов, то есть таблица моделируется совокупностью экстентов. Экстент — это непрерывная область дисковой памяти. Для моделирования каждой таблицы используется 2 типа экстентов: первый и последующие. Первый экстент задается при создании нового объекта типа таблица, его размер задается при создании. EXTENTSIZE — размер первого экстента, NEXT SIZE — размер каждого следующего экстента. Минимальный размер экстента в каждой системе свой, но в большинстве случаев он равен 4 страницам, максимальный — 2 Гбайтам. Новый экстент создается после заполнения предыдущего и связывается с ним специальной ссылкой, которая располагается на последней странице экстента. В ряде систем экстенты называются сегментами, но фактически эти понятия эквиваленты. При динамическом заполнении БД данными применяется специальный механизм адаптивного определения размера экстентов. Внутри экстента идет учет свободных станиц. Между экстентами, которые располагаются друг за другом без промежутков, производится своеобразная операция конкатенации, которая просто увеличивает размер первого экстента. Механизм удвоения размера экстента: если число выделяемых экстентов для процесса растет в пропорции, кратной 16, то размер экстента удваивается каждые 16 экстентов. Например, если размер текущего экстента 16 Кбайт, то после заполнения 16 экстентов данного размера размер следующего будет увеличен до 32 Кбайт. Совокупность экстентов моделирует логическую единицу — таблицу-отношение (tblspace). Экстенты состоят из четырех типов страниц: страницы данных, страницы индексов, битовые страницы и страницы blob-объектов. Blob — это сокращение Binary Larg Object, и соответствует оно неструктурированным данным. В ранних СУБД такие данные относились к типу Memo. В современных СУБД к этому типу относятся неструктурированные большие текстовые данные, картинки, просто наборы машинных кодов. Для СУБД важно знать, что этот объект надо хранить целиком, что размеры этих объектов от записи к записи могут резко отличаться и этот размер в общем случае неограничен. Основной единицей осуществления операций обмена (ввода-вывода) является страница данных. Все данные хранятся постранично. При табличном хранении данные на одной странице являются однородными, то есть станица может хранить только данные или только индексы. Все страницы данных имеют одинаковую структуру, представленную на рис. 9.13. Слот — это 4-байтовое слово, 2 байта соответствуют смещению строки на странице и 2 байта — длина строки. Слоты характеризуют размещение строк данных на странице. На одной странице хранится не более 255 строк. В базе данных каждая строка имеет уникальный идентификатор в рамках всей базы данных, часто называемый RowID — номер строки, он имеет размер 4 байта и состоит из номера страницы и номера строки на странице. Под номер страницы отводится 3 байта, поэтому при такой идентификации возможна адресация к 16 777 215 страницам.
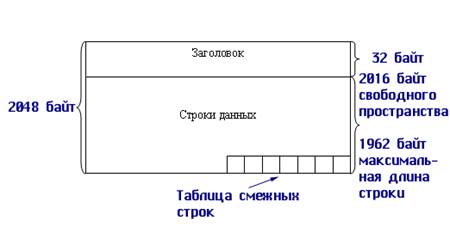
Рис. 9.13. Обобщенная структура страницы данных При упорядочении строк на страницах не происходит физического перемещения строк, все манипуляции происходят со слотами. При переполнении страниц создается специальный вид страниц, называемых страницами остатка. Строки, не уместившиеся на основной странице, связываются (линкуются) со своим продолжением на страницах остатка с помощью ссылок-указателей «вперед» (то есть на продолжение), которые содержат номер страницы и номер слота на странице. Страницы индексов организованы в виде В-деревьев. Страницы blob предназначены для хранения слабоструктурнровашюй информации, содержащей тексты большого объема, графическую информацию, двоичные коды. Эти данные рассматриваются как потоки байтов произвольного размера, в страницах данных делаются ссылки на эти страницы. Битовые страницы служат для трассировки других типов страниц. В зависимости от трассируемых страниц битовые страницы строятся по 2-битовой или 4-битовой схеме. 4-битовые страницы служат для хранения сведений о столбцах типа Varchar, Byte, Text, для остальных типов данных используются 2-битовые страницы. Битовая структура трассирует 32 страницы. Каждая битовая структура представлена двумя 4-байтными словами. Каждая i-я позиция описывает одну i-ю страницу. Сочетание разрядов в i-х позициях двух слов обозначает состояние данной страницы: ее тип и занятость. При обработке данных СУБД организует специальные структуры в оперативной памяти, называемые разделяемой памятью, и специальные структуры во внешней памяти, называемые журналами транзакций. Разделяемая память служит для кэширования данных при работе с внешней памятью с целью сокращения времени доступа, кроме того, разделяемая память служит для эффективной поддержки режимов одновременной параллельной работы пользователей с базой данных. Журнал транзакций служит для управления корректным выполнением транзакций. Однако тема параллельной обработки данных выходит за рамки данного раздела, и поэтому архитектура разделяемой памяти будет освещена в разделах, посвященных распределенной обработке данных. Структура хранения данных для MS SQL 6.5 В версии 6.0 и 6.5 MS SQL Server логическая структура хранения рассматривается в следующей иерархии [1]. Файлы операционной системы представляются как устройства для хранения БД (Device), устройства нумеруются. Сервер может управлять 256 устройствами. Главное устройство называется MASTER: на нем хранятся системные базы данных: Master, Model, Pubs, TempDb. Устройство Master имеет номер 0 — ноль. Каждое устройство разбивается не более чем на 16 777 216 виртуальных страниц по 2 Кбайта (Virtual page), максимальный размер устройства 32 Гбайт. Первые 4 страницы устройства Master заняты под блок конфигурации (Confi,-guration block) — там хранятся все параметры конфигурации сервера. На устройствах размещаются конкретные базы. На каждом устройстве может быть размещено несколько баз, но и одна база может быть размещена на нескольких устройствах. Каждая страница БД имеет свой уникальный номер. Физически используются 3 единицы хранения данных: · страница; · блок (extent) — 16Кб из 8 следующих друг за другом страниц; · единица размещения (Allocation Unit) — 512 Кб из 32 последовательных блоков (256 страниц). При создании новой базы данных пространство для нее отводится единицами размещения. Минимальный объем базы данных для данной версии сервера равен 1 Мбайт, то есть составляет 2 единицы размещения. Страницы бывают пяти типов: · страницы размещения (Allocation page); · страницы данных (Data page); · индексные страницы (Index page); · текстовые страницы (Text/image page); · статистические страницы (Distribution page). Любая страница имеет заголовок, занимающий 32 байта. Заголовок содержит номер страницы, номера предыдущей и следующей страниц, идентификатор объекта — владельца страницы и сведения о свободном пространстве на странице. Как видно из заголовка, страницы связаны в двунаправленный список. Первая страница каждой единицы размещения является страницей размещения. Таким образом, все страницы, кратные 256, начиная с 0 являются страницами размещения. Они хранят информацию, необходимую для управления размещением страниц внутри единицы размещения. Страница размещения содержит 32 16-байтовых структуры, по одной на каждый блок. Каждая структура содержит следующую информацию: · идентификатор объекта—владельца блока; · номер следующего блока в цепи; · номер предыдущего блока в цепи; · битовую карту распределения блока (Allocation bitmap); · битовую карту перераспределения блока (Deallocation bitmap); · идентификатор индекса (если таковой есть), размещенного на блоке; · статус. Битовая карта распределения блока хранится в единственном байте, каждый бит которого соответствует одной странице блока. Если бит равен 1, то страница в данный момент содержит данные, если 0 — то страница свободна. Карта перераспределения применяется для отслеживания страниц, которые освобождаются в течение транзакций. Реально страница помечается как пустая только после успешной фиксации (завершения) транзакции. Это делается, чтобы другие транзакции не обращались к странице до подтверждения того факта, что она освобождена. Все страницы в блоке могут использоваться только одной таблицей или ее индексом. Это означает, что таблица может занимать минимально 1 блок — 16 Кбайт, даже если она содержит всего несколько строк. Страницы данных используются для хранения собственно данных. Структурно страницу данных можно подразделить на три зоны: заголовок, строки данных и таблицу смещения (см. рис. 9.14).
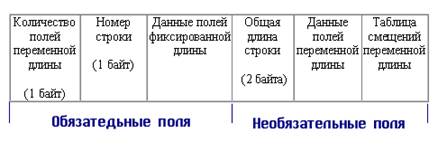
Рис. 9.14. Структура страницы данных для MS SQL Server 6.5 Строка данных должна полностью умещаться на странице, поэтому существуют ограничения на длину строки. Размер страницы 2048 байт, 32 байта занимает заголовок. Кроме того, в таблице смещения отводится по 2 байта на каждую строку на странице. Страницы данных, относящиеся к одной таблице, объединяются в двунаправленный список и организуют цепочки. Данные хранятся на страницах в виде строк (кортежей). Каждая строка данных кроме собственно данных хранит дополнительную форматирующую информацию. Длина строки зависит от определения полей таблицы и конкретных данных в ней. Независимо от объявления, каждая строка имеет номер и поле с количеством полей переменной длины (к ним относятся также поля, допускающие неопределенные значения NULL). Оба эти поля имеют размер по одному байту, следовательно, количество строк на странице не превышает 256, а на количество полей также существует внешнее ограничение 250 полей в одной таблице. Структура строки таблицы приведена на рис. 9.15.
Рис. 9.15. Структура строки данных для MS SQL Server 6.5 Вторая часть — это необязательная область, она существует только тогда, когда имеются в записи поля переменной длины. Таблица смещений (Column offset table) состоит из: · таблицы подстройки смещений (Offset table adjust bytes) — но 1 дополнительному байту на каждое поле, смещение которого превышает 256 плюс 1 байт; · указателя на местоположение таблицы смещений; · указателя на местоположение полей переменной длины (1 байт на каждое поле). Указатели занимают два последних байта в каждой структуре и поэтому они доступны для анализа. Таблица смещения строк Местоположение строки на странице определяется таблицей смешения строк (Row offset table). Таблица располагается в самом конце страницы и забирает дополнительно по 2 байта па каждую строку данных (см. рис. 9.16). Чтобы найти строку с заданным номером, SQL Server считывает из соответствующей ячейки смещение, которое и является адресом требуемой строки. Ячейка таблицы однозначно связана с определенным номером строки. Удаленные строки имеют нулевое смещение. Поэтому из примера на рис. 9.16 видно, что строки 1 и 4 удалены. У этой модели есть недостаток. После удаления строки в таблице смещения все равно остается ссылка на нее, которая занимает 1 байт. Однако при добавлении новой строки SQL Server проверяет таблицу смещений и ищет нулевое смещение, и новой строке присваивается номер удаленной, а в соответствующую ячейку таблицы смещений заносится адрес новой строки. В SQL Server 6.5 используется понятие кластерного индекса. В таблице, для которой создается кластерный индекс, данные хранятся строго упорядочение) по полю, для которого создан этот кластерный индекс. Это поле (или набор полей) является первичным ключом таблицы или обладает свойством уникальности. При заполнении таблиц с кластерным индексом вводится параметр, соответствующий проценту заполнения страницы (fill-factor). Если страница заполнена, то данные заносятся на последнюю страницу в цепочке страниц, занятых этой таблицей.
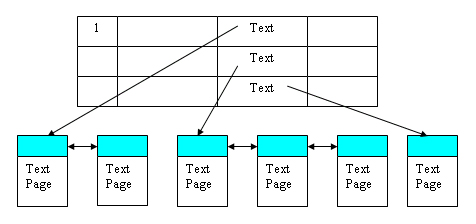
Рис. 9.16. Пример заполнения таблицы смещения строк Некластерный индекс хранится отдельно от данных. Текстовые страницы предназначены для хранения данных типа Next или Image. На одной текстовой странице хранятся только данные одной строки основной таблицы (см. рис. 9.17). В основной таблице в соответствующем месте хранится только ссылка на соответствующую текстовую страницу. Если неструктурированные данные не умещаются на одной странице, то они образуют цепочку взаимосвязанных страниц.
Рис. 9.17. Хранение текстовых данных Структуры хранения данных в SQL Server.7.0 В новой версии сервера баз данных фирма Microsoft реализовала абсолютно новый механизм хранения. SQL Server 7.0 организует следующую иерархию хранения: · База данных — некоторый объем физического пространства, на котором размещаются данные, принадлежащие одной логической базе данных. · Файл. Каждая база данных содержит не менее двух файлов. Один из них отводится под журнал транзакций. И в отличие от версии 6.5 в новой версии журнал транзакций не может располагаться в одном файле с данными. И еще одно принципиальное отличие — в новой версии каждый файл может принадлежать только одной базе данных, у нас не может быть разделяемых файлов. · Страница. Файлы делятся на страницы размером по 8 Кбайт каждая. Логический номер страницы складывается из внутреннего номера базы данных, номера файла и номера страницы в файле. В рамках БД файлы нумеруются, начиная с 1, и так же нумеруются страницы в рамках файла. · Блоки (экстенты, extents). Пространство под объекты отводится блоками по 8 следующих друг за другом страниц. Блок является основной единицей отведения пространства. Поэтому при создании БД можно указывать размер файла с точностью до 64 Кбайт. Для суперкомпьютеров заложена возможность увеличения размера блоков до 128 страниц. В отличие от версии 6.5 объекты БД не обязательно занимают целый блок. На начальном этапе заполнения объект может занимать внутри блока несколько страниц. Поэтому существуют два типа блоков: · Однородные (Uniform). Все страницы однородного блока принадлежат одному объекту БД. · Смешанные (Mixed). Разные страницы в блоке принадлежат разным объектам. Когда объект создается, то обычно его первые страницы отводятся в смешанном блоке, по мере роста объекта он уже размещается в однородных блоках. В SQL 7.0 существуют уже 7 типов страниц: · страница данных (Data page); · индексные страницы (Index page); · страницы журнала транзакций (Log page); · текстовые страницы (Text/image page); · карты распределения блоков (Global allocation map page); · карты свободного пространства (Page free space page); · индексные карты размещения (Index allocation map page). Все страницы имеют заголовок размером 96 байтов. В заголовке хранится общая информация, используемая ядром СУБД для работы со страницами. На странице в отличие от блока хранится однородная информация. Поэтому среди параметров страницы задаются: · номер страницы в формате <номер файла, номер страницы>; · идентификатор объекта, которому принадлежит страница; · номер индекса, которому принадлежит страница; · уровень внутри индексного дерева, которому принадлежит страница; · количество отведенных строк на странице, количество заполненных слотов; · общий объем свободного пространства на странице; · указатель на расположение свободного пространства после последней строки на странице; · минимальная длина строки на странице; · объем зарезервированного пространства. После заголовка следует информация о статусе страницы в картах распределения блоков и карте свободного пространства. Новыми в архитектуре дисковой памяти являются страницы размещения. В этих страницах хранятся сведения о размещении данных. SQL Server 7.0 использует три типа страниц размещения: карты распределения блоков, карты свободного пространства, индексные карты размещения. SQL Server 7.0 хранит информацию размещения на разных уровнях: на уровне блоков, на уровне страниц, на уровне объектов. Такой разносторонний мониторинг помогает СУБД оптимизировать работу в соответствии с требованиями конкретного запроса. Карты распределения блоков В данных картах хранится информация о распределении блоков. Карта распределения блоков состоит из стандартного заголовка и одного битового массива в 64 000 битов. Каждый бит характеризует один блок. Поэтому одна страница карты распределения описывает пространство в 64 000 блоков или 4 Гбайт данных. Карты распределения блоков делятся на два типа: · Глобальная карта распределения (Global allocation map, GAM) хранит информацию об использовании блоков. Если бит установлен в 0, то блок занят данными, если в 1 — то блок свободен. · Вторичная глобальная карта распределения (Secondary global allocation map, SGAM) хранит информацию о типе блоков. Если бит установлен в 1, то блок смешанный и минимум одна страница в нем свободна, в остальных случаях (блок свободен, блок смешанный, но свободных страниц нет, блок однородный) бит равен 0. При отведении пространства сервер использует обе карты распределения.
|
||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 353; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.95.167 (0.008 с.) |