Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Общие сведения о базах данныхСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Базы данных Общие сведения о базах данных Первые компьютеры (англ. computer – вычислитель), как это ясно из названия, были ориентированы только для решения вычислительных задач (например, в ядерной физике, механике, баллистике). Особенностью этих задач было то, что они имели небольшой объем исходных данных, которые сравнительно редко менялись, и поэтому их можно было хранить внутри программы. При попытке использовать компьютер для решения экономических и управленческих задач возникла следующая проблема: такие задачи имели большой объем исходных данных, и эти данные часто менялись. Следовательно, хранение данных вместе с программой было нецелесообразным. Кроме того, в различных программах встречались очень похожие фрагменты кода, выполняющие некоторые стандартные действия: открыть-закрыть файл, найти на внешнем машинном носителе информации (магнитной ленте) нужную запись, отсортировать массив данных, добавить-удалить-изменить (данные в файле) и т. д. Поэтому в середине 50-х гг. XX в. была разработана концепция БД. Основные положения этой концепции следующие: • централизованное хранение информации; • хранение данных независимо от программы их обработки; • возможность использования одних и тех же данных для решения различных задач; • специальная организация данных для оптимизации времени обращения к ним. Тогда же и появилось первое упоминание о БД. Одинаковые фрагменты кода программ, встречающиеся в самых разных задачах, организовали в виде библиотеки подпрограмм. Такую библиотеку подпрограмм назвали СУБД. Ее основные функции: определение данных (описание структуры БД), их обработка и управление ими. В настоящее время существуют различные СУБД – MS SQL Server, MySQL, Interbase, Oracle, DB2, Paradox, FoxPro и множество других, менее известных. Администрирование баз данных Пользователями БД могут быть: 1. прикладные программы; 2. программные комплексы; 3. специалисты предметной области, выступающие в роли потребителей или источников данных, называемые конечными пользователями. Администратор БД — физическое лицо или группа лиц, ответственных за состояние, развитие и использование БД организации или учреждения. Администратор БД обеспечивает: 1. работоспособность БД,
2. контролирует и поддерживает полноту, достоверность, непротиворечивость и целостность данных, 3. реализует необходимый уровень защиты. Защита базы данных. В современных многопользовательских СУБД защитные механизмы реализуются следующими способами: 1. установка пароля для открытия БД. После установки пароля при каждом открытии БД будет появляться диалоговое окно, в которое требуется ввести пароль. Только те пользователи, которые введут правильный пароль, смогут открыть БД. Этот способ достаточно надежен, но он действует только при открытии БД. 2. установка шифра. Для шифрования применяются специальные шифры (тайнопись, криптография). При шифровании БД ее файл кодируется и становится недоступным для чтения с помощью служебных программ или текстовых редакторов. Дешифрование БД отменяет результаты операции шифрования. 3. защита на уровне пользователей: o защита приложения, работающего с БД, от повреждения из-за неумышленного изменения пользователями таблиц, запросов, форм, отчетов от которых зависит работа; o защита конфиденциальных сведений в базе данных. При запуске СУБД от пользователя требуется идентифицировать себя и ввёсти пароль. Пользователи идентифицируются как члены группы. СУБД по умолчанию создает две группы: администраторы (группа "Admins") и пользователи (группа "Users"). Допускается также определение других групп. Группам и пользователям предоставляются разрешения на доступ. Восстановление базы данных. Важными средствами восстановления БД являются регулярное и частое резервное копирование БД и ведение журнала транзакций. Резервная копия БД — это копия всех файлов, составляющих БД. Если повреждается или теряется файл, являющийся частью БД, то из резервной копии можно извлечь копию этого файла и восстановить его в базе. Журнал транзакций — это группа файлов, в которые записываются изменения, внесенные завершенными транзакциями. Эта информация достаточна для повторного выполнения, если надо восстановить БД. Сжатие базы данных. В процессе работы с БД приходится удалять ее объекты. Файл БД становится фрагментированным и место на диске используется нерационально. Сжатие БД приводит к созданию ее копии, в которой диск используется более экономно. Работа с этой копией повышает быстродействие запросов, повышает скорость отбора записей.
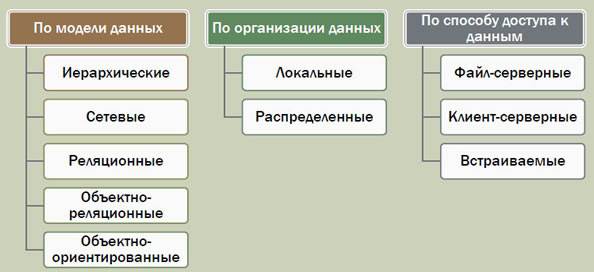
СУБД СУБД - Комплекс языков и программ, позволяющий создавать базы данных и управлять их функционированием. СУБД обрабатывает обращения к базе данных, поступающие от пользователей, прикладных процессов и выдает необходимые им сведения. СУБД характеризуется используемой моделью и средствами администрирования, разработки прикладных процессов, работы в информационной сети. Классификация СУБД
Распределенные СУБД Для того чтобы сохранить конкурентоспособность, организации разукрупняют свои информационные ресурсы, делают их распределенными. В распределенной БД не все данные хранятся централизованно. Они распределены по узлам, удаленным географически, но связанным коммуникационными линиями. Каждый узел имеет собственную (локальную) БД. Кроме того, он может обращаться к данным, хранящимся на других узлах. Пользователь распределенной БД не обязан знать, каким образом ее компоненты размещены в узлах сети и представляет себе эту БД как единое целое. Распределенная база данных (РаБД) — совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети. Работу с распределенной БД обеспечивают распределенные СУБД. Распределенная СУБД (РаСУБД)— это программная система, которая обеспечивает управление распределенной БД и прозрачность ее распределенности для пользователей. Требования к РаБД: o локальная автономность; o никакой конкретный сервис не должен возлагаться на какой-либо специально выделенный центральный узел; o непрерывность функционирования; o независимость от местоположения, от фрагментации, от тиражирования; o распределенная обработка запросов; o управление распределенными транзакциями; o независимость от оборудования, от операционных систем, от сети, от СУБД. РаБД могут быть однородными и неоднородными. Однородные РаБД имеют в своей основе одну СУБД, обычно с единственным языком баз данных; неоднородные РаБД — две или более существенно различающиеся СУБД. В РаБД различаются и формы распределения данных. В одних случаях данные фрагментируются, т. е. делятся на порции, распределенные между множеством физических ресурсов. Фрагментация есть горизонтальная (деление по географическому или другому характеристическому признаку) и вертикальная (разбивание таблицы по столбцам). Независимо от того, какого вида применяется фрагментация, поддерживается глобальная схема, позволяющая воссоздать из имеющихся фрагментов логически централизованную таблицу или другую структуру БД. Пользователь взаимодействует с РаБД посредством транзакций. Транзакция может вызвать несколько процессов в различных узлах, контролируемых независимыми программными модулями. В других случаях данные тиражируются. Тиражирование — это создание дублирующих копий (репликатор) объектов БД на разных узлах с целью повышения доступности и/или сокращения времени доступа к критически важным данным. Репликаты — это множество различных физических копий некоторого объекта БД (обычно таблицы), для которых в соответствии с определенными в БД правилами поддерживается синхронизация (идентичность) с некоторой "главной" копией.
Типовая организация СУБД - ядро, которое отвечает за управление данными во внешней и оперативной памяти, управление транзакциями и журнализацию. При использовании архитектуры "клиент-сервер" ядро является основной составляющей серверной части системы. - компилятор языка SQL - подсистема поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД - сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы. База данных База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например, для ведения счетов, учета материальных ценностей, планирования и т.п. Структурирование данных – это введение соглашения о способах представления данных. Проектирование базы данных Проектирование БД является очень важным этапом, от которого зависят последующие этапы разработки СУБД. Время, затраченное разработчиком на проектирование БД, обычно окупается высокой скоростью реализации проекта. Перед созданием базы данных необходимо располагать описанием выбранной предметной области, которое должно охватывать реальные объекты и процессы, иметь всю необходимую информацию для удовлетворения предполагаемых запросов пользователя и определить потребности в обработке данных. На основе такого описания на этапе проектирования базы данных осуществляется определение состава и структуры данных предметной области, которые должны находиться в базе данных и обеспечивать выполнение необходимых запросов и задач пользователя. Структура данных предметной области может отображаться информационно-логической моделью. На основе этой модели легко создается реляционная база данных. Под проектированием понимают процесс создания описаний новой системы, которая способна функционировать при постоянном совершенствовании ее технических, программных, информационных составляющих и расширять спектр реализуемых управленческих функций и объектов взаимодействия.
Целью концептуального проектирования является разработка БД на основе описания предметной области. Это описание должно содержать совокупность документов и данных, необходимых для загрузки в БД, а также сведения об объектах и процессах, характеризующих предметную область. Такое описание охватывает весь класс реальных объектов, процессов и явлений, т.е. сущностей, информация о которых должна содержаться в БД и обеспечивать реализацию возможных запросов к БД и решение задач. Разработка БД начинается с определения состава данных, подлежащих хранению в базе для обеспечения выполнения запросов пользователя. Далее производится их анализ и структурирование.
Целью логического проектирования является выбор конкретной СУБД и преобразование концептуальной модели в логическую. Для реляционной БД этот этап состоит в разработке структуры таблиц, связей между ними и определении ключевых реквизитов. Этап физического проектирования дополняет логическую модель характеристиками, которые необходимы для определения способов физического хранения и использования БД, объема памяти и типа устройств для хранения. Наиболее рациональным считается сочетание перечисленных подходов к проектированию. Это связано с тем, что на начальном этапе, как правило, еще не имеется исчерпывающих сведений о всех задачах и пришлось бы отложить проектирование и создание БД до постановки всех задач. Использование такой технологий удобно потому, что средства создания реляционной БД в СУБД позволяют на любом этапе разработки внести изменения в БД и модифицировать ее структуру без ущерба для введенных ранее данных. Эта технология предполагает использование предварительных сведений о необходимости получения из БД различной информации. В результате проектирования БД должна быть разработана информационно-логическая модель (ИЛМ) данных, т.е. определен состав реляционных таблиц, их структура и логические связи. Структура реляционной таблицы определяется составом полей, типом и размером каждого поля, а также ключом таблицы. Информационно-логическая модель отображает данные предметной области в виде совокупности информационных объектов и связей между ними. Эта модель представляет данные, подлежащие хранению в базе данных. Функции управления БД · управление данными во внешней памяти – обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей. · управление буферами оперативной памяти – обычно СУБД работает с БД значительного размера, по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Если при обращении к элементу будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройств внешней памяти, поэтому единственный способ увеличить скорость является буферизация данных оперативной памяти, выполняемая самой СУБД, а не ОС. · управление транзакциями. Транзакция – последовательность операций над БД, рассматриваемых как единое целое. · журнализация. СУБД должна обеспечивать надежность хранения данных. · поддержка языков БД. Назначение транзакций Транзакция - это последовательность операций, которые должны быть или все выполнены или все не выполнены (все или ничего).
Методом контроля за транзакциями является ведение журнала, в котором фиксируются все изменения, совершаемые транзакцией в БД. Если во время обработки транзакции происходит сбой, транзакция откатывается - из журнала восстанавливается состояние БД на момент начала транзакции. В СУБД различных поставщиков начало транзакции может задаваться явно (например, командой BEGIN TRANSACTION), либо предполагаться неявным (так определено в стандарте SQL), т.е. очередная транзакция открывается автоматически сразу же после удачного или неудачного завершения предыдущей. Основные понятия о моделях данных Модель данных - совокупность структур данных и операций их обработки. На практике наиболее распространены три модели: · иерархическая · сетевая · реляционная Иерархическая модель данных Данные представлены в виде древовидной структуры. Иерархическая модель представляет собой перевернутое дерево. На самом верхнем уровне только один узел — корень.
Узел – информационная модель элемента, находящегося на данном уровне иерархии. Свойства иерархической модели данных: · Несколько узлов низшего уровня связано только с одним узлом высшего уровня. · Иерархическое дерево имеет только одну вершину (корень), не подчиненную никакой другой вершине. · Каждый узел имеет свое имя (идентификатор). · Существует только один путь от корневой записи к более частной записи данных. Иерархическая модель характеризуется сложностью, неоднородностью, что затрудняет манипулирование данными. Ее применение ограничено, так как не любая предметная область может быть представлена с помощью этой модели. Сетевая модель данных Данные представлены в виде произвольного графа. Сетевая модель представляет структуру, у которой один или несколько порожденных элементов имеют более одного исходного элемента. В сетевой структуре любой элемент может быть связан с любым другим элементом.
Иерархическая модель является частным случаем сетевой. Сетевые модели более универсальны. Взаимосвязи большинства предметных областей имеют сетевой характер. Технология работы с сетевыми моделями удобна для пользователя, так как возможен непосредственный доступ к элементам данных. В качестве примера можно рассмотреть базу данных, хранящую сведения о закреплении учителей - предметников за определенными классами. Один учитель может преподавать в нескольких классах и один и тот же предмет могут вести разные учителя. Достоинства и недостатки сетевой и иерархической моделей: Достоинства: · Компактность данных · Высокое быстродействие при обработке Недостатки: · Не универсальность · Высокая степень зависимости от конкретных данных (проблемы с обновлением, дополнением, изменением) Реляционная модель данных На практике более распространена реляционная модель. Данные представляют собой совокупность таблиц, связанных отношениями Сотрудник фирмы IBMЭ.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation. Реляционная модель БД представляет собой набор связанных между собой таблиц. Каждая из таблиц содержит информацию о каких-либо объектах одной группы. Все записи одной таблицы имеют идентичные, заданные пользователем, структуру и размеры. Например, какой-либо журнал. Каждая строка такой таблицы называется записью, а столбец – полем. Имя поля — любое имя длиной до 64 символов и может содержать буквы кириллицы, пробелы и специальные символы, за исключением точек, восклицательных знаков и угловых скобок. Имя каждому полю дается при создании базы данных. Обычно имя состоит из 3—б символов (до 10). Имена разных полей совпадать не могут. Длина поля — это максимальное число символов, которые могут быть записаны в поле. Структура базы данных Структурой базы данных называют порядок расположения полей записи с указанием имени, типа (формата) и длины. Таблицы должны обладать следующими свойствами: · каждый столбец таблицы — это элемент данных (атрибут) и его значения должны быть не расчленяемыми на несколько значений · все столбцы однородные · в таблице нет двух одинаковых строк · столбцы и строки могут просматриваться в любом порядке, безотносительно к их информационному содержанию и смыслу · число строк не ограничено Жизненный цикл БД 1.планирование разработки БД. Рассмотрение с какой целью разрабатывается. Определение объема работ и ресурсов. 2.определение требований к системе, определение диапазон действий, состав пользователей, область применения. 3.сбор и анализ требований пользователей. Анализ документооборота сведений о выполнении транзакций, список требований с указанием приоритетов 4.проектирование БД: - потенциальное проектирование (создание подробной модели) - логическое(слияние отдельных моделей в глобальную логическую модель) - физическое(описание реляционных таблиц и ограничений, разработка ср-в защиты) 5. разработка приложений - проектирование транзакций и пользовательского интерфейса Реализация Загрузка данных Тестирование Нормализация отношений Нормализация- это процесс последовательной замены таблицы ее полными декомпозициями до тех пор пока все они не будут находится в 5НФ. Реляционная база данных представляет собой некоторое множество таблиц, связанных между собой. Число таблиц в одном файле или одной базе данных зависит от многих факторов, основными из которых являются: 1. состав пользователей базы данных, 2. обеспечение целостности информации (особенно важно в многопользовательских информационных системах), 3. обеспечение наименьшего объем требуемой памяти и минимального времени обработки данных. Учет данных факторов при проектировании реляционных баз данных осуществляется методами нормализации таблиц и установлением связей между ними. Нормализация таблиц представляет собой способы разделения одной таблицы базы данных на несколько таблиц, в целом отвечающих перечисленным выше требованиям. Нормализация таблицы представляет собой последовательное изменение структуры таблицы до тех пор, пока она не будет удовлетворять требованиям последней формы нормализации. Всего существует шесть форм нормализации: • первая нормальная форма (First Normal Form — INF); • вторая нормальная форма (Second Normal Form — 2NF); • третья нормальная форма (Third Normal Form — 3NF); • нормальная форма Бойса—Кодда (Brice—Codd Normal Form — BCNF); • четвертая нормальная форма (Fourth Normal Form — 4NF); • пятая нормальная форма, или нормальная форма проекции-соединения (Fifth Normal Form — 5NF, или PJ/NF). Примеры нормализации Самым простым примером реляционной БД является БД, состоящая всего из одного отношения – одной таблицы. Однако в таком случае, как правило, не будут выполняться основные требования, предъявляемые к структуре БД из-за возникающих проблем избыточности информации, нарушения целостности данных, сложности редактирования данных, низкой скорости обработки информации и т. п. Пример. В таблице «Поставки товаров» есть сведения о товарах, их цене, количестве и стоимости, а также о поставщиках, их адресах и расчетных счетах:
Анализируя структуру таблицы, необходимо, прежде всего, отметить, что в ней имеется повторяющаяся информация о поставщике. Кроме того, стоимость товара является избыточной информацией, т. к. всегда может быть получена на основе цены товара и его количества. Далее, атрибуты «Адрес» и «Счет» характеризуют только поставщика и, вообще говоря, не связаны с поставляемым товаром. Существуют и другие более тонкие недостатки в структуре такой БД. Таким образом, на первом этапе проектирования реляционной БД важнейшим является вопрос, какую выбрать схему отношений для данной БД из множества альтернативных вариантов, т. е. какую систему таблиц и с каким набором столбцов в каждой таблице выбрать для данной БД. Как правило, БД содержит объекты разных типов, и для каждого типа объектов создается своя таблица с соответствующим набором столбцов-атрибутов объекта. Процесс создания оптимальной схемы отношений для реляционной БД строго формализован и называется нормализацией БД. Нормализация – это формализованная процедура, в процессе выполнения которой атрибуты данных группируются в таблицы, а таблицы, в свою очередь, в БД. Цели нормализации следующие: • исключить дублирование информации; • исключить избыточность информации; • обеспечить возможность проведения непротиворечивых и корректных изменений данных в таблицах; • упростить и ускорить поиск информации в БД. Процесс нормализации состоит в приведении таблиц реляционной БД к так называемым нормальным формам. Всего существует пять нормальных форм, которые удовлетворяют соответствующим правилам нормализации. При этом в большинстве случаев оптимальная структура БД достигается при выполнении уже первых трех правил нормализации, которые были сформулированы для реляционных БД Э. Ф. Коддом в 1972 г. Чтобы таблица, а вместе с ней и БД, соответствовала первой нормальной форме, необходимо, чтобы все значения ее полей были атомарными (неделимыми) и невычисляемыми, а все записи – уникальными (не должно быть полностью совпадающих строк). Выполняя это правило, преобразуем первоначальную таблицу к следующему виду:
Чтобы таблица соответствовала второй нормальной форме, необходимо, чтобы она уже находилась в первой нормальной форме и все неключевые поля полностью зависели от ключевого. В данной таблице на роль ключевого поля может претендовать только поле (атрибут-признак) «Товар», значения которого в таблице не повторяются. Из других полей только поле «Поставщик» непосредственно связано с поставляемым товаром (полем «Товар»), а поля «Индекс», «Область», «Город» и «Счет» характеризуют только самого поставщика. Поэтому, удовлетворяя второму правилу нормализации, необходимо разбить (или разложить) исходную таблицу на две – соответственно «Товары» и «Поставщики».
Проведенное преобразование называется разложением, или проектированием, БД и является обратимой операцией. Причем проектирование исходной таблицы привело, с одной стороны, к уменьшению записей (строк) во второй таблице, однако, с другой стороны, для организации связей между отдельными таблицами и обеспечения таким образом целостности БД поле «Поставщик» появилось уже в обеих таблицах, привнося этим некоторую неизбежную избыточность информации. Очевидно, что в больших БД, где реально существуют сотни и тысячи записей, эта избыточность во много раз будет перекрыта уменьшением общего размера таблиц, полученных из исходной таблицы при ее разложении. Заметим, что на роль ключевого поля таблицы «Поставщики» подходит поле «Поставщик», значения которого в этой таблице уже не повторяются. Можно отметить, что на эту роль вполне подходит и поле «Счет», значения которого также не будут повторяться, а само поле, хотя и выглядит как набор цифр, все же является не количественной, а качественной характеристикой объекта, т. е. является атрибутом-признаком, что необходимо для ключевого поля. Чтобы теперь перейти к третьей нормальной форме, необходимо, прежде всего, обеспечить, чтобы все таблицы БД находились во второй нормальной форме и все неключевые поля в таблицах зависели только от ключа таблицы и не зависели непосредственно друг от друга. Анализируя таблицу «Поставщики», можно заметить, что поля «Область» и «Город» являются зависимыми от поля «Индекс», и поэтому эта таблица не находится в третьей нормальной форме. В связи с этим необходимо разбить таблицу на две: оставить в таблице «Поставщики» только два («Поставщик» и «Счет»), а также поле «Индекс» для обеспечения связи между таблицами, а остальные поля выделить в новую таблицу «Адреса», в которой поле «Индекс», естественно, будет ключевым, т. к. его значения в таблице не повторяются.
Приведение БД к четвертой и пятой нормальным формам является необходимой операцией в специальных случаях, когда между элементами БД существуют связи типа «многие-ко-многим» и при этом необходимо обеспечить возможность точного восстановления исходной таблицы из таблиц, на которые она была спроектирована. Как уже говорилось, этими правилами нормализации при проектировании БД в большинстве случаев можно пренебречь. Типы данных СУБД Access Каждое поле базы данных имеет имя, тип (формат) и длину. Тип (формат) поля связан с формой представления информации в этом поле. К основным типам (форматам) полей относят: Текстовый (символьный) - предназначен для записи алфавитно-цифровой информации; Числовой - предназначен для записи чисел. Существуют и другие типы (форматы) полей.
Мастер подстановок - создает поле, в котором предлагается выбор значений из раскрывающегося списка, содержащего набор постоянных значений или значений из другой таблицы. Фильтрация данных Фильтрация - выделение из БД данных, отвечающих некоторому критерию. Критерии бывают двух типов. Критерии вычисления – это критерии, которые являются результатом вычисления формулы. Например, диапазон критериев =F7=СУММ($В$2:$В$22) выводит на экран строки, имеющие в столбце F значения большие, чем сумма величин в ячейках В2:В22. Формула должна представлять из себя логическое выражение (условие). При фильтрации будут доступные только те строки, значения которых будут придавать формуле значения ИСТИНА. Критерии сравнения – это набор условий для поиска, используемый для извлечения данных при запросах по примеру. Критерий сравнения может быть последовательностью символов (константой) или выражением (например, Цена > 700). Команда Фильтр позволяет отыскивать и использовать нужное подмножество данных в списке. В отфильтрованном списке выводятся на экран только те строки, которые содержат определенное значение или отвечают определенным критериям, при этом другие строки скрываются. Для фильтрации данных используются команды Автофильтр и Расширенный фильтр. Команда Автофильтр устанавливает кнопки скрытых списков (кнопки со стрелками) непосредственно в строку с именами столбцов. С их помощью можно выбирать записи базы данных, которые следует вывести на экран. После выделения элемента в открывшемся списке, строки, не содержащие данный элемент, будут скрыты. Команда Расширенный фильтр позволяет фильтровать данные с использованием диапазона критериев для вывода только записей, удовлетворяющих определенным критериям. Логические связи между таблицами Между таблицами устанавливаются связи. Связи делают их более информативными, чем они являются по отдельности. Они позволяют минимизировать избыточность данных в БД. Связь устанавливается посредством связи ключей, содержащих общую информацию для обоих таблиц. Пусть таблица R1 именуется главной, а R2 — подчиненной. Ключ главной таблицы называется первичным, а подчиненной — вторичным. Особенностью вторичного ключа является то, что его значения могут повторяться. Существует логическая связь четырех типов: · один к одному (1:1); · один ко многим (1:∞); · многие к одному (∞:l) · многие ко многим (∞:∞) В случае связи 1:1 одному значению первичного ключа соответствует одно и только одно значение вторичного ключа, например:
В случае связи 1:∞ одному значению первичного ключа может соответствовать несколько значений вторичного ключа, например:
В случае связи ∞:1 одному значению вторичного ключа может соответствовать несколько значений первичного, например:
В случае связи ∞:∞ одному значению первичного ключа может соответствовать несколько значений вторичного и одному значению вторичного — несколько значений первичного, например:
Каждый поставщик может поставлять несколько товаров; каждый товар может поставляться несколькими поставщиками. Объекты СУБД MS Access: 1. Таблица 2. Запрос 3. Форма 4. Отчёт 5. Макрос 6. Страница доступа к данным 7. Модуль Объект, который позволяет пользователю получить данные из одной или несколько таблиц – запрос. Объект, предназначенный для создания документа, который впоследствии может бать распечатан либо включён в документ другого приложения – отчёт. Объект, предназначенный для просмотра, ввода и редактирования записей базы данных – форма. Страница доступа к данным — диалоговая Web-страница, которая поддерживает динамическую связь с БД и позволяет просматривать, редактировать и вводить данные в базу, работая в окне браузера. Макрос — этопоследовательность макрокоманд для автоматизации выполнения операций в среде Access без программирования. Модуль — это программа для работы с БД, написанная на языке Visual Basic for Applications (VBA). Из всех типов объектов только таблицы предназначены для хранения информации. Остальные используются для просмотра, редактирования, обработки и анализа данных - иначе говоря, для обеспечения эффективного доступа к информации. Таблицы: Таблицы играют ключевую роль в базах данных, поскольку именно в них хранится информация. База данных может содержать тысячи таблиц, размеры которых ограничиваются только доступным пространством на жестком диске компьютера. Для таблиц обычно используются режим таблицы, предназначенный для ввода данных, и режим конструктора, позволяющий просмотреть и модифицировать структуру таблицы. Запросы: Запросы предназначены для поиска в базе данных информации, отвечающей определенным критериям. Найденные записи, называемые результатами запроса, можно просматривать, редактировать и анализировать различными способами. Кроме того, результаты запроса могут использоваться в качестве основы для создания других объектов Access. В сущности, запрос представляет собой вопрос, сформулированный в терминах базы данных. Существует различные типы запросов. Наиболее распространенными являются запросы на выборку, параметрические и перекрестные запросы. Для создания простых запросов используется мастер, в менее тривиальных случаях можно создать запрос вручную в режиме конструктора. Формы: Информация хранится в таблицах в том виде, в котором была введена. Это не имеет особого значения, если никто, кроме вас, не работает с базой данных. Однако если база данных предназначена для пользователей, имеющих смутное представление об Access, работа с таблицами может показаться им чрезмерно сложной, не говоря уже о том, как это отразится на сохранности информации. В таких случаях лучше воспользоваться формами, которые позволяют упростить и сделать более эффективными ввод и обработку содержимого таблиц.В сущности, форма представляет собой окно, куда можно поместить элементы управления, предназначенные для ввода и отображения данных. Access включает панель, которая содержит многие стандартные элементы управления Windows, в том числе поля, надписи, флажки и кнопки выбора. Не требуется особых талантов, чтобы с помощью этих элементов создать формы, которые выглядят и функционируют примерно так же, как диалоговые окна в приложениях Microsoft Windows.Формы используются для ввода и редактирования записей в таблицах базы данных. Подобно таблицам и запросам, их можно отображать в трех режимах: в режим формы, предназначенном для ввода данных, в режиме таблицы, где данны
|
|||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-06-26; просмотров: 1825; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.89.175 (0.02 с.) |