Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Функции администрации банка данных.Содержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Функции администрации банка данных. Функции: 1)Анализ предметной области 2)Проектирование структуры БД 3)Задание ограничения целостности 4)Первоначальная загрузка и ведение БД 5)Защита данных 6)Обеспечение восстановления БД 7)Анализ обращения пользователей БД 8)Анализ эффективного функционирования БД 9)Работа с пользователем 10)Подготовка и содержание программных средств. Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации. Предметная область представляется множеством фрагментов, например, предприятие - цехами, конструкцией, технологией. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область.
СУБД. Функции СУБД. Типовая организация СУБД. СУБД - совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных. Функции: 1)Управление данными во внешней памяти(на дисках) 2)Управление данными в оперативной памяти с использованием дискового кэша 3)Журнализация изменений, резервное копирование и восстановление базы данных после сбоев, 4)Поддержка языков БД. В СУБД можно выделить внутреннюю часть: 1)ядро СУБД (отвечает за управление буферами оперативной памяти,управление транзакцией,журнализацией.. Компоненты ядра: менеджер данных, менеджер буферов, менеджер транзакций, менеджер журнала) 2)компилятор языка БД (обычно SQL),(компиляция операторов языка БД в некоторую выполняемую программу) 3)подсистему поддержки времени выполнения 4)набор утилит. Утилиты – процедуры по загрузке, выгрузке, проверке статистики и т.д.
Этапы разработки базы данных. Этапы: 1)Обследовать предметную область 2)Определить объекты и перечень их атрибутов,свойства 3) Определить ключи 4)Установить связи между объектами(структурные и иерархические) 5)Вычертить схему проекта 6)Выработать технологию обслуживания(определить порядок сбора, хранения данных, Частоту и правила работы с пользователем) 7)Реализовать проект. Последовательность создания: 1)описание предметной области,выполненной без ориентации на использование в дальнейшем 2)физ.модель определяет используемое заполняющее устройство,выбор методов доступа,управление размещением в данных, управление памятью
Инфологическая модель, даталогическая модель, физическая модель. Инфологическая модель – описание предметной области, выполненной без ориентации на использование в дальнейшем програмные и технические средства. Датологическая модель - модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается с учётом конкретной реализации СУБД, также с учётом специфики конкретной предметной области на основе ее инфологической модели. Физические модели баз данных определяют способы размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне Любая модель данных должна содержать три компоненты:
ER - модель. Основные понятия. Сущность, атрибут, ключ, связи. Прежде, чем приступать к созданию системы автоматизированной обработки информации, разработчик должен сформировать понятия о предметах, фактах и событиях, которыми будет оперировать данная система. Для того, чтобы привести эти понятия к той или иной модели данных, необходимо заменить их информационными представлениями. Одним из наиболее удобных инструментов унифицированного представления данных, независимого от реализующего его программного обеспечения, является модель "сущность-связь" ER - model Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным. Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты). Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть Изделие, а экземпляром – Редуктор, Муфта и т.д. Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, Масса может быть определен для многих сущностей: Редуктор, Муфта, и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности РЕДУКТОР являются ТИПРАЗМЕР, МОЩНОСТЬ, КПД, и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута МОЩНОСТЬ имеет много экземпляров или значений: Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность. Клю ч – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей. ER-модель - модель данных, позволяющая описывать концептуальные схемы предметной области.С её помощью можно выделить ключевые сущности и обозначить связи, которые могут устанавливаться между этими сущностями. Сущность – класс однотипных объектов, информация о которых должна быть учтена в модели. Атрибут – именованноесв-во сущности. Экземпляр – конкретный представитель данной сущности. Ключ – набор атрибутов, значения которых являются уникальными для каждого экземпляра сущности. Связь – некоторая ассоциация между сущностями(1:1, 1:М, М:М. М:М реализуется путем разбиения связи на две)
Общая характеристика реляционной модели данных. Типы данных. Простые типы данных. Структурированные типы данных. Ссылочные типы данных. Типы данных, используемые в реляционной модели. Домены. Отношения. Атрибуты. Кортежи.
Реляционная модель состоит из трех частей: 1)Структурной части. 2)Целостной части. 3)Манипуляционной части. Типы данных делятся на три группы: 1)Простые типы данных -логический -строковый -численный 2)Структурированные типы данных 3)Ссылочные типы данных. Структурированные типы данных предназначены для задания сложных структур данных. (Массивы, Записи (Структуры)). Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Собственно, для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым, нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных. Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д. Домен можно рассматривать как подмножество значений некоторого типа данных, имеющих определенный смысл. Атрибут отношения- это пара вида < имя атрибута >< имя домена >. Отношение –определенное на подмножестве доменов содержит 2 части: заголовок и тело. Кортеж отношения представляет собой множество пар вида <Имя_атрибута: Значение_атрибута>:
Свойства отношений: 1)Отсутствие кортежей-дубликатов(Из этого свойства вытекает наличие у каждого кортежа первичного ключа. Для каждого отношения, по крайней мере, полный набор его атрибутов является первичным ключом. Однако, при определении первичного ключа должно соблюдаться требование "минимальности", т.е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа - однозначно определять кортеж) 2)Отсутствие упорядоченности кортежей 3)Отсутствие упорядоченности атрибутов 4)Атомарность значений атрибутов. Потенциальный ключ: Любое отношение имеет по крайней мере один потенциальный ключ. Действительно, если никакой атрибут или группа атрибутов не являются потенциальным ключом, то, в силу уникальности кортежей, все атрибуты вместе образуют потенциальный ключ. Потенциальный ключ, состоящий из одного атрибута, называется простым. Потенциальный ключ, состоящий из нескольких атрибутов, называется составным. Отношение может иметь несколько потенциальных ключей. Традиционно, один из потенциальных ключей объявляется первичным, а остальные - альтернативными. Потенциальные ключи служат средством идентификации объектов предметной области, данные о которых хранятся в отношении. Объекты предметной области должны быть различимы. Правило целостности сущностей: Атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
Деление Пусть отношение R, называемое делимым, содержит атрибуты (A1,A2,...,An). Отношение S - делитель содержит подмножество атрибутов A: (A1,A2,...,Ak)(k<n). Результирующее отношение C определено на атрибутах отношения R, которых нет в S, т.е. Ak+1,Ak+2,...,An. Кортежи включаются в результирующее отношение C только в том случае, если его декартово произведение с отношением S содержится в делимом R.
Синтаксис операции деления:
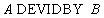
Выборка SELECT * Проекция SELECT DISTINCT X, Y, …, Z Соединение SELECT * Деление SELECT DISTINCT A.X Оператор выборки::= Табличное выражение [ORDER BY {{Имя столбца-результата [ASC | DESC]} | {Положительное целое [ASC | DESC]}}.,..]; Табличное выражение::= Select-выражение [ {UNION | INTERSECT | EXCEPT} [ALL] {Select-выражение | TABLE Имя таблицы | Конструктор значений таблицы} ] Select-выражение::= SELECT [ALL | DISTINCT] {{{Скалярное выражение | Функция агрегирования | Select-выражение} [AS Имя столбца]}.,..} | {{Имя таблицы|Имя корреляции}.*} | * FROM { {Имя таблицы [AS] [Имя корреляции] [(Имя столбца.,..)]} | {Select-выражение [AS] Имя корреляции [(Имя столбца.,..)]} | Соединенная таблица }.,.. [WHERE Условное выражение] [GROUP BY {[{Имя таблицы|Имя корреляции}.]Имя столбца}.,..] [HAVING Условное выражение]
Функциональные зависимости. Реляционная база данных содержит как структурную, так и семантическую информацию. Структура базы данных определяется числом и видом включенных в нее отношений, и связями типа "один ко многим", существующими между кортежами этих отношений. Семантическая часть описывает множество функциональных зависимостей, существующих между атрибутами этих отношений. Дадим определение функциональной зависимости. Определение: Если даны два атрибута X и Y некоторого отношения, то говорят, что Y функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y. Функциональная зависимость обозначается X -> Y. Отметим, что X и Y могут представлять собой не только единичные атрибуты, но и группы, составленные из нескольких атрибутов одного отношения. Можно сказать, что функциональные зависимости представляют собой связи типа "один ко многим", существующие внутри отношения. Некоторые функциональные зависимости могут быть нежелательны. Определение: Избыточная функциональная зависимость - зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных. Корректной считается такая схема базы данных, в которой отсутствуют избыточные функциональные зависимости. В противном случае приходится прибегать к процедуре декомпозиции (разложения) имеющегося множества отношений. При этом порождаемое множество содержит большее число отношений, которые являются проекциями отношений исходного множества. (Операция проекции описана в разделе, посвященном реляционной алгебре). Обратимый пошаговый процесс замены данной совокупности отношений другой схемой с устранением избыточных функциональных зависимостей называется нормализацией. Условие обратимости требует, чтобы декомпозиция сохраняла эквивалентность схем при замене одной схемы на другую, т.е. в результирующих отношениях: · не должны появляться ранее отсутствовавшие кортежи; · на отношениях новой схемы должно выполняться исходное множество функциональных зависимостей. Втораня нормальная форма Отношение находится во 2НФ, если оно находится в 1НФ и каждый неключевой атрибут функционально полно зависит от ключа. Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут полностью зависит от первичного ключа. Можно произвести следующую декомпозицию отношения СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ в два отношения СОТРУДНИКИ-ОТДЕЛЫ и СОТРУДНИКИ-ПРОЕКТЫ: СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, СОТР_ЗАРП, ОТД_НОМЕР) Первичный ключ: СОТР_НОМЕР Функциональные зависимости: СОТР_НОМЕР СОТР_ЗАРП СОТР_НОМЕР ОТД_НОМЕР ОТД_НОМЕР СОТР_ЗАРП СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН) Первичный ключ: СОТР_НОМЕР, ПРО_НОМЕР Функциональные зависимости: СОТР_НОМЕР, ПРО_НОМЕР CОТР_ЗАДАН Каждое из этих двух отношений находится в 2NF, и в них устранены отмеченные выше аномалии (легко проверить, что все указанные операции выполняются без проблем).
Неповторяемое считывание Транзакция A дважды читает одну и ту же строку. Между этими чтениями вклинивается транзакция B, которая изменяет значения в строке.
Транзакция A ничего не знает о существовании транзакции B, и, т.к. сама она не меняет значение в строке, то ожидает, что после повторного чтения значение будет тем же самым. Результат. Транзакция A работает с данными, которые, с точки зрения транзакции A, самопроизвольно изменяются. Блокировки Основная идея блокировок заключается в том, что если для выполнения некоторой транзакции необходимо, чтобы некоторый объект не изменялся без ведома этой транзакции, то этот объект должен быть заблокирован, т.е. доступ к этому объекту со стороны других транзакций ограничивается на время выполнения транзакции, вызвавшей блокировку. Различают два типа блокировок:
Если транзакция A блокирует объект при помощи X-блокировки, то всякий доступ к этому объекту со стороны других транзакций отвергается. Если транзакция A блокирует объект при помощи S-блокировки, то
Правила взаимного доступа к заблокированным объектам можно представить в виде следующей матрицы совместимости блокировок. Если транзакция A наложила блокировку на некоторый объект, а транзакция B после этого пытается наложить блокировку на этот же объект, то успешность блокирования транзакцией B объекта описывается таблицей:
Таблица 1 Матрица совместимости S- и X-блокировок Три случая, когда транзакция B не может блокировать объект, соответствуют трем видам конфликтов между транзакциями. Доступ к объектам базы данных на чтение и запись должен осуществляться в соответствии со следующим протоколом доступа к данным:
Преднамеренные блокировки Как видно из анализа поведения транзакций, при использовании протокола доступа к данным не решается проблема фантомов. Это происходит оттого, что были рассмотрены только блокировки на уровне строк. Можно рассматривать блокировки и других объектов базы данных:
Кроме того, можно блокировать индексы, заголовки таблиц или другие объекты. Чем крупнее объект блокировки, тем меньше возможностей для параллельной работы. Достоинством блокировок крупных объектов является уменьшение накладных расходов системы и решение проблем, не решаемых с использованием блокировок менее крупных объектов. Например, использование монопольной блокировки на уровне таблицы, очевидно, решает проблему фантомов. Современные СУБД, как правило, поддерживают минимальный уровень блокировки на уровне строк или страниц. (В старых версиях настольной СУБД Paradox поддерживалась блокировка на уровне отдельных полей.). При использовании блокировок объектов разной величины возникает проблема обнаружения уже наложенных блокировок. Если транзакция A пытается заблокировать таблицу, то необходимо иметь информацию, не наложены ли уже блокировки на уровне строк этой таблицы, несовместимые с блокировкой таблицы. Для решения этой проблемы используется протокол преднамеренных блокировок, являющийся расширением протокола доступа к данным. Суть этого протокола в том, что перед тем, как наложить блокировку на объект (например, на строку таблицы), необходимо наложить специальную преднамеренную блокировку (блокировку намерения) на объекты, в состав которых входит блокируемый объект - на таблицу, содержащую строку, на файл, содержащий таблицу, на базу данных, содержащую файл. Тогда наличие преднамеренной блокировки таблицы будет свидетельствовать о наличии блокировки строк таблицы и для другой транзакции, пытающейся блокировать целую таблицу не нужно проверять наличие блокировок отдельных строк. Более точно, вводятся следующие новые типы блокировок:
IS, IX и SIX-блокировки должны накладываться на сложные объекты базы данных (таблицы, файлы). Кроме того, на сложные объекты могут накладываться и блокировки типов S и X. Для сложных объектов (например, для таблицы базы данных) таблица совместимости блокировок имеет следующий вид:
Таблица 2 Расширенная таблица совместимости блокировок Более точная формулировка протокола преднамеренных блокировок для доступа к данным выглядит следующим образом:
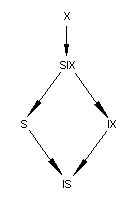
Понятие относительной силы блокировок можно описать при помощи следующей диаграммы приоритета (сверху - более сильные блокировки, снизу - более слабые):
Таблица 3 Диаграмма приоритета блокировок Замечание. Протокол преднамеренных блокировок не определяет однозначно, какие блокировки должны быть наложены на родительский объект при блокировании дочернего объекта. Например, при намерении задать S-блокировку строки таблицы, на таблицу, включающую эту строку, можно наложить любую из блокировок типа IS, S, IX, SIX, X. При намерении задать X-блокировку строки, на таблицу можно наложить любую из блокировок типа IX, SIX, X. Посмотрим, как разрешается проблема фиктивных элементов (фантомов) с использованием протокола преднамеренных блокировок для доступа к данным. Транзакция A дважды выполняет выборку строк с одним и тем же условием. Между выборками вклинивается транзакция B, которая добавляет новую строку, удовлетворяющую условию отбора. Транзакция B перед попыткой вставить новую строку должна наложить на таблицу IX-блокировку, или более сильную (SIX или X). Тогда транзакция A, для предотвращения возможного конфликта, должна наложить такую блокировку на таблицу, которая не позволила бы транзакции B наложить IX-блокировку. По таблице совместимости блокировок определяем, что транзакция A должна наложить на таблицу S, или SIX, или X-блокировку. (Блокировки IS недостаточно, т.к. эта блокировка позволяет транзакции B наложить IX-блокировку для последующей вставки строк).
Результат. Проблема фиктивных элементов (фантомов) решается, если транзакция A использует преднамеренную S-блокировку или более сильную. Замечание. Т.к. транзакция A собирается только читать строки таблицы, то минимально необходимым условием в соответствии с протоколом преднамеренных блокировок является преднамеренная IS-блокировка таблицы. Однако этот тип блокировки не предотвращает появление фантомов. Таким образом, транзакцию A можно запускать с разными уровнями изолированности - предотвращая или допуская появление фантомов. Причем, оба способа запуска соответствуют протоколу преднамеренных блокировок для доступа к данным. Уровни изоляции Стандарт SQL не предусматривает понятие блокировок для реализации сериализуемости смеси транзакций. Вместо этого вводится понятие уровней изоляции. Этот подход обеспечивает необходимые требования к изолированности транзакций, оставляя возможность производителям различных СУБД реализовывать эти требования своими способами (в частности, с использованием блокировок или выделением версий данных). Стандарт SQL предусматривает 4 уровня изоляции:
Если все транзакции выполняются на уровне способности к упорядочению (принятом по умолчанию), то чередующееся выполнение любого множества параллельных транзакций может быть упорядочено. Если некоторые транзакции выполняются на более низких уровнях, то имеется множество способов нарушить способность к упорядочению. В стандарте SQL выделены три особых случая нарушения способности к упорядочению, фактически именно те, которые были описаны выше как проблемы параллелизма:
Потеря результатов обновления стандартом SQL не допускается, т.е. на самом низком уровне изолированности транзакции должны работать так, чтобы не допустить потери результатов обновления. Различные уровни изоляции определяются по возможности или исключению этих особых случаев нарушения способности к упорядочению. Эти определения описываются следующей таблицей:
Таблица 4 Уровни изоляции стандарта SQL Выводы Современные многопользовательские системы допускают одновременную работу большого числа пользователей. При этом если не предпринимать специальных мер, транзакции будут мешать друг другу. Этот эффект известен как проблемы параллелизма. Имеются три основные проблемы параллелизма:
График запуска набора транзакций называется последовательным, если транзакции выполняются строго по очереди. Если график запуска набора транзакций содержит чередующиеся элементарные операции транзакций, то такой график называется чередующимся. Два графика называются эквивалентными, если при их выполнении будет получен один и тот же результат, независимо от начального состояния базы данных. График запуска транзакции называется верным (сериализуемым), если он эквивалентен какому-либо последовательному графику. Решение проблем параллелизма состоит в нахождении такой стратегии запуска транзакций, чтобы обеспечить сериализуемость графика запуска и не слишком уменьшить степень параллельности. Одним из методов обеспечения сериальности графика запуска является протокол доступа к данным при помощи блокировок. В простейшем случае различают S-блокировки (разделяемые) и X-блокировки (монопольные). Протокол доступа к данным имеет вид:
Если все транзакции в смеси подчиняются протоколу доступа к данным, то проблемы параллелизма решаются (почти все, кроме "фантомов"), но появляются тупики. Состояние тупика (dead locks) характеризуется тем, что две или более транзакции пытаются заблокировать одни и те же объекты, и бесконечно долго ожидают друг друга. Для разрушения тупиков система периодически или постоянно поддерживает графа ожидания транзакций. Наличие циклов в графе ожидания свидетельствует о возникновении тупика. Для разрушения тупика одна из транзакций (наиболее дешевая с точки зрения системы) выбирается в качестве жертвы и откатывается. Для решения проблемы "фантомов", а также для уменьшения накладных расходов, вызываемых большим количеством блокировок, применяют
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 424; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.200.95 (0.012 с.) |

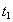
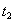
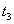
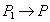
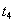
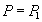
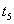

 . (Заблокировано n строк)
. (Заблокировано n строк)