Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
DFD – диаграммы потоков данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
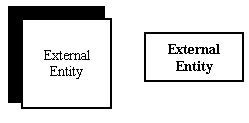
Моделирование данных Данный раздел содержит сведения о методологиях описания документооборота организации, составе, структуре и взаимосвязях используемой в процессе её деятельности информации. Рассматриваются следующие методологии моделирования: · DFD (Data Flow Diagram) - методология документирования передачи и обработки информации. Диаграммы DFD обычно строятся для наглядного изображения текущей работы системы документооборота организации и, в частности, могут использоваться в качестве дополнения функциональной модели бизнес процессов, выполненной в IDEF0; · IDEF1 – этот стандарт разработан как методология изучения и анализа состава, структуры и взаимосвязей используемой в организации информации (модель AS IS), с целью выявления потребностей в её управлении и выработки соответствующих правил. При модернизации существующих процессов этот стандарт может использоваться как инструмент изучения и анализа состава и структуры дополнительных данных и правил управления информацией, необходимых при функционировании предприятия в новых условиях (модель TO BE); · IDEF1X – является стандартом и методологией разработки реляционных баз данных. IDEF1X изначально не предназначен для проведения динамического анализа по принципу «AS IS» - «TO BE». Эта методология используется, когда все информационные ресурсы изучены с помощью других методов и принято решение о внедрении реляционной базы данных как основы или части корпоративной информационной системы. DFD – диаграммы потоков данных В соответствии с DFD (Data Flow Diagram) методологией, модель системы определяется как иерархия диаграмм потоков данных, описывающих процессы преобразования информации от момента ее ввода в систему до выдачи конечному пользователю. Диаграммы верхних уровней иерархии - контекстные диаграммы, задают границы модели, определяя её окружение (внешние входы и выходы) и основные рассматриваемые процессы. Контекстные диаграммы детализируются при помощи диаграмм следующих уровней. Элементы DFD диаграмм Основными элементами диаграмм потоков данных являются: · внешние сущности; · процессы; · накопители данных; · потоки данных. Внешние сущности Под внешней сущностью (External Entity) понимается материальный объект, являющийся источником или приемником информации. В качестве внешней сущности на DFD диаграмме могут выступать заказчики, поставщики, клиенты, склад, банк и другие. К сожалению, DFD методология не оформлена как стандарт. По этой причине в диаграммах потоков данных используются различные условные обозначения. На рисунке 1 показаны символы внешних сущностей, используемые в нотациях «Yourdon and Coad Process Notation» и «Gane and Sarson Process Notation».
Рис. 1. Символы внешних сущностей Определение некоторого объекта в качестве внешней сущности указывает на то, что он находится за пределами границ анализируемой информационной системы. Процессы Процессы представляют собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. В реальной жизни процесс может выполняться некоторым подразделением организации, выполняющим обработку входных документов и выпуск отчетов, отдельным сотрудником, программой, установленной на компьютере, специальным логическим устройством и тому подобное. Процессы на диаграмме потоков данных изображаются, как показано на рисунке 2.
Рис. 2. Символы процессов Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить) и поясняющими существительными, например: «Напечатать адрес получателя», «Акцептовать счет». Информация в нижнем поле символа процесса указывает, какое подразделение организации, сотрудник, программа или аппаратное устройство выполняет данный процесс. Если такое поле отсутствует, то подобная информация может быть указана в текстовом примечании. В отличие от IDEF0 диаграмм, в DFD диаграммах не используются стрелки управления для обозначения правил выполнения действия и стрелки механизмов для обозначения требуемых ресурсов. Накопители данных Накопители данных предназначены для изображения неких абстрактных устройств для хранения информации, которую можно туда в любой момент времени поместить или извлечь, безотносительно к их конкретной физической реализации. Накопители данных являются неким прообразом базы данных информационной системы организации. Наиболее часто употребляемые символы для их обозначения показаны на рисунке 3.
Рис. 3. Символы накопителей данных Внутри символа указывается его уникальное в рамках данной модели имя, наиболее точно, с точки зрения аналитика, отражающее информационную сущность содержимого, например, «Поставщики», «Заказчики», «Счета-фактуры», «Накладные». Символы накопителей данных в качестве дополнительных элементов идентификации могут содержать порядковые номера. Потоки данных Поток данных определяет информацию, передаваемую через некоторое соединение (кабель, почтовая связь, курьер) от источника к приемнику. На DFD диаграммах потоки данных изображаются линиями со стрелками, показывающими их направление. Каждому потоку данных присваивается имя, отражающее его содержание. Пример типичной потоковой диаграммы показан на рисунке 4.
Рис. 4. Пример диаграммы поков данных
Как отмечалось ранее, диаграммы потоков данных строятся по иерархическому принципу. Структура иерархии DFD диаграмм показана на рисунке 5.
Рис. 5. Структура иерархии DFD диаграмм
Рис. 6. Контекстная диаграмма потоков данных На первом уровне иерархии показываются основные внутренние процессы системы и соответствующие им внешние сущности, накопители и потоки данных (рис. 7).
Рис. 7. Пример первого уровня иерархии DFD диаграмм Для каждого процесса диаграммы первого уровня может быть произведена декомпозиция, которая, в свою очередь, также может быть раскрыта более подробно. Декомпозиция процессов заканчивается, когда достигнута требуемая степень детализации или отображаемые на очередном уровне диаграмм процессы являются элементарными и не могут быть разбиты на более мелкие. Фаза 0 На этой фазе решаются основные организационные вопросы: определяются предмет, цели и границы моделирования, методы сбора и источники информации, план выполнения работ и их распределение между исполнителями, которые фиксируются в соответствующих документах. Информация об источниках данных и конкретные данные фиксируются в специальных табличных формах, пример которых приведен на рисунках 8 и 9.
Рис. 8. Таблица источников данных
Рис. 9. Таблица данных
Фаза 1 Задачей этой фазы является определение и описание классов сущностей информационной модели. Изучая документы, которые используются в процессах деятельности организации, и опрашивая сотрудников, аналитик, действуя как показано на рисунке 10, формирует пул классов сущностей (рис. 11).
Рис. 10. Алгоритм формирования класса сущностей
Рис. 11. Пример пула класса сущностей После того как классы сущностей определены, они должны быть описаны. Поэтому следующим шагом этой фазы моделирования является формирование глоссария или словаря классов сущностей. Пример описания класса сущности показан на рисунке 12.
Рис. 12. Пример описания класса сущностей
Фаза 2 На этой фазе моделирования определяются классы отношений, существующие между классами сущностей модели. Отношения между классами сущностей изображаются в виде диаграмм. Перед построением диаграмм рекомендуется создать матрицу отношений, как показано на рисунке 13.
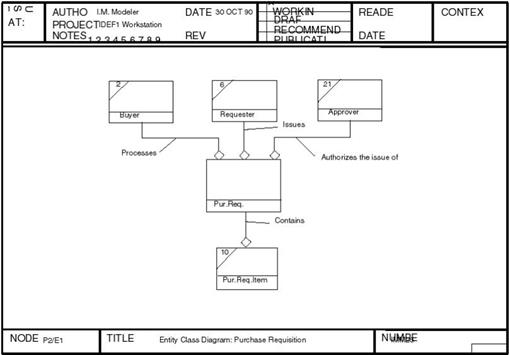
Рис. 13. Матрица отношений Используя матрицу отношений, создают диаграммы классов сущностей. IDEF1 диаграммы содержат изображения некоторого количества классов сущностей, соединенных линиями, представляющими их взаимные отношения. Как правило, в центре диаграммы располагают изображение класса сущностей, являющегося предметом рассмотрения данной диаграммы. Пример такой диаграммы показан на рисунке 14.
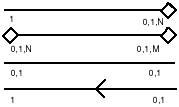
Рис. 14. Диаграмма класса сущностей Для обозначения классов отношений между классами сущностей используются показанные на рисунке 15 линии. Символы на концах линий обозначают, какое количество экземпляров одного класса сущностей могут быть связаны с экземплярами другого класса сущностей. Таким образом, диаграммы классов сущностей создают графическое изображение информации, используемой в организации. Модель представляет структуру информации двояким образом – как множество экземпляров сущностей внутри каждого класса сущностей и как множество экземпляров отношений между классами сущностей.
Рис. 15. Обозначения классов отношений Классы отношений должны быть подробно описаны. Описание классов отношений становится частью глоссария классов сущностей.
Фаза 3 Целью третьей фазы является определение классов ключей для каждого класса сущностей. Наборы классов атрибутов разработчиком модели группируются в пул классов атрибутов, пример табличной формы которого показан на рисунке 16.
Рис. 16. Пул классов атрибутов Классы атрибутов, также как ранее классы сущностей и отношений, должны быть подробно описаны. Анализируя свойства классов атрибутов, разработчик модели определяет те, которые будут использоваться в классе ключей. Когда классы ключей определены, разработчик переходит к построению диаграмм классов атрибутов (рис. 17).
Рис. 17. Диаграмма класса атрибутов Как и в диаграммах классов сущностей в диаграммах классов атрибутов внимание фокусируется на одном из классов сущностей, изображение которого помещается в центре формы диаграммы. Диаграмма класса атрибутов может рассматриваться как дальнейшее развитие диаграммы класса сущностей, так как они отличаются только информацией, содержащейся внутри блока, изображающего класс сущностей – ключевые классы и другие классы атрибутов используются как содержание блока класса сущностей.
Фаза 4 На фазе 4 осуществляется распределение классов атрибутов, которые не могут быть использованы в классах ключей, по соответствующим классам сущностей. Действия, выполняемые на четвертой фазе разработки модели, во многом схожи с действиями на предыдущей фазе. В результате выполнения работ четвертой фазы разработчик получает структурированную информационную модель. Если действия на всех фазах были выполнены корректно, то каждый класс сущностей будет представлен оптимальным набором информации и каждая пара классов сущностей, совместно использующая класс отношений, будет точно отображать взаимозависимость данных в модели. Таким образом, IDEF1 информационная модель является формой представления данных, которая облегчает разработку базы данных системы управления. Тем не менее, нельзя сказать, что разработка информационной IDEF1 модели является разработкой базы данных. IDEF1-модель представляет лишь устойчивую информационную структуру и устойчивый набор правил и определений, с учетом которых может проводиться разработка базы данных. Иерархия диаграмм Построение SADT-модели начинается с представления всей системы в виде простейшей компоненты - одного блока и дуг, изображающих интерфейсы с функциями вне системы. Поскольку единственный блок представляет всю систему как единое целое, имя, указанное в блоке, является общим. Это верно и для интерфейсных дуг - они также представляют полный набор внешних интерфейсов системы в целом. Затем блок, который представляет систему в качестве единого модуля, детализируется на другой диаграмме с помощью нескольких блоков, соединенных интерфейсными дугами. Эти блоки представляют основные подфункции исходной функции. Данная декомпозиция выявляет полный набор подфункций, каждая из которых представлена как блок, границы которого определены интерфейсными дугами. Каждая из этих подфункций может быть декомпозирована подобным образом для более детального представления. Во всех случаях каждая подфункция может содержать только те элементы, которые входят в исходную функцию. Кроме того, модель не может опустить какие-либо элементы, т.е., как уже отмечалось, родительский блок и его интерфейсы обеспечивают контекст. К нему нельзя ничего добавить, и из него не может быть ничего удалено. Модель SADT представляет собой серию диаграмм с сопроводительной документацией, разбивающих сложный объект на составные части, которые представлены в виде блоков. Детали каждого из основных блоков показаны в виде блоков на других диаграммах. Каждая детальная диаграмма является декомпозицией блока из более общей диаграммы. На каждом шаге декомпозиции более общая диаграмма называется родительской для более детальной диаграммы. Дуги, входящие в блок и выходящие из него на диаграмме верхнего уровня, являются точно теми же самыми, что и дуги, входящие в диаграмму нижнего уровня и выходящие из нее, потому что блок и диаграмма представляют одну и ту же часть системы. На рисунках 2.3 - 2.5 представлены различные варианты выполнения функций и соединения дуг с блоками. Некоторые дуги присоединены к блокам диаграммы обоими концами, у других же один конец остается неприсоединенным. Неприсоединенные дуги соответствуют входам, управлениям и выходам родительского блока. Источник или получатель этих пограничных дуг может быть обнаружен только на родительской диаграмме. Неприсоединенные концы должны соответствовать дугам на исходной диаграмме. Все граничные дуги должны продолжаться на родительской диаграмме, чтобы она была полной и непротиворечивой. На SADT-диаграммах не указаны явно ни последовательность, ни время. Обратные связи, итерации, продолжающиеся процессы и перекрывающиеся (по времени) функции могут быть изображены с помощью дуг. Обратные связи могут выступать в виде комментариев, замечаний, исправлений и т.д. (рисунок 2.5). Как было отмечено, механизмы (дуги с нижней стороны) показывают средства, с помощью которых осуществляется выполнение функций. Механизм может быть человеком, компьютером или любым другим устройством, которое помогает выполнять данную функцию (рисунок 2.6). Каждый блок на диаграмме имеет свой номер. Блок любой диаграммы может быть далее описан диаграммой нижнего уровня, которая, в свою очередь, может быть далее детализирована с помощью необходимого числа диаграмм. Таким образом, формируется иерархия диаграмм. Для того, чтобы указать положение любой диаграммы или блока в иерархии, используются номера диаграмм. Например, А21 является диаграммой, которая детализирует блок 1 на диаграмме А2. Аналогично, А2 детализирует блок 2 на диаграмме А0, которая является самой верхней диаграммой модели. На рисунке 2.7 показано типичное дерево диаграмм. Типы связей между функциями Одним из важных моментов при проектировании ИС с помощью методологии SADT является точная согласованность типов связей между функциями. Различают по крайней мере семь типов связывания:
Ниже каждый тип связи кратко определен и проиллюстрирован с помощью типичного примера из SADT. (0) Тип случайной связности: наименее желательный. Случайная связность возникает, когда конкретная связь между функциями мала или полностью отсутствует. Это относится к ситуации, когда имена данных на SADT-дугах в одной диаграмме имеют малую связь друг с другом. Крайний вариант этого случая показан на рисунке 2.8. (1) Тип логической связности. Логическое связывание происходит тогда, когда данные и функции собираются вместе вследствие того, что они попадают в общий класс или набор элементов, но необходимых функциональных отношений между ними не обнаруживается. (2) Тип временной связности. Связанные по времени элементы возникают вследствие того, что они представляют функции, связанные во времени, когда данные используются одновременно или функции включаются параллельно, а не последовательно. (3) Тип процедурной связности. Процедурно-связанные элементы появляются сгруппированными вместе вследствие того, что они выполняются в течение одной и той же части цикла или процесса. Пример процедурно-связанной диаграммы приведен на рисунке 2.9. (4) Тип коммуникационной связности. Диаграммы демонстрируют коммуникационные связи, когда блоки группируются вследствие того, что они используют одни и те же входные данные и/или производят одни и те же выходные данные (рисунок 2.10). (5) Тип последовательной связности. На диаграммах, имеющих последовательные связи, выход одной функции служит входными данными для следующей функции. Связь между элементами на диаграмме является более тесной, чем на рассмотренных выше уровнях связок, поскольку моделируются причинно-следственные зависимости (рисунок 2.11). (6) Тип функциональной связности. Диаграмма отражает полную функциональную связность, при наличии полной зависимости одной функции от другой. Диаграмма, которая является чисто функциональной, не содержит чужеродных элементов, относящихся к последовательному или более слабому типу связности. Одним из способов определения функционально-связанных диаграмм является рассмотрение двух блоков, связанных через управляющие дуги, как показано на рисунке 2.12. В математических терминах необходимое условие для простейшего типа функциональной связности, показанной на рисунке 2.12, имеет следующий вид: C = g(B) = g(f(A))Ниже в таблице представлены все типы связей, рассмотренные выше. Важно отметить, что уровни 4-6 устанавливают типы связностей, которые разработчики считают важнейшими для получения диаграмм хорошего качества.
2.3. Моделирование потоков данных (процессов) В основе данной методологии (методологии Gane/Sarson [11]) лежит построение модели анализируемой ИС - проектируемой или реально существующей. В соответствии с методологией модель системы определяется как иерархия диаграмм потоков данных (ДПД или DFD), описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи пользователю. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы ИС с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут такой уровень декомпозиции, на котором процесс становятся элементарными и детализировать их далее невозможно. Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те в свою очередь преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям - потребителям информации. Таким образом, основными компонентами диаграмм потоков данных являются:
Внешние сущности Внешняя сущность представляет собой материальный предмет или физическое лицо, представляющее собой источник или приемник информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что она находится за пределами границ анализируемой ИС. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой ИС, если это необходимо, или, наоборот, часть процессов ИС может быть вынесена за пределы диаграммы и представлена как внешняя сущность. Внешняя сущность обозначается квадратом (рисунок 2.13), расположенным как бы "над" диаграммой и бросающим на нее тень, для того, чтобы можно было выделить этот символ среди других обозначений: Системы и подсистемы При построении модели сложной ИС она может быть представлена в самом общем виде на так называемой контекстной диаграмме в виде одной системы как единого целого, либо может быть декомпозирована на ряд подсистем. Подсистема (или система) на контекстной диаграмме изображается следующим образом (рисунок 2.14). Номер подсистемы служит для ее идентификации. В поле имени вводится наименование подсистемы в виде предложения с подлежащим и соответствующими определениями и дополнениями. Процессы Процесс представляет собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс может быть реализован различными способами: это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, программа, аппаратно реализованное логическое устройство и т.д. Процесс на диаграмме потоков данных изображается, как показано на рисунке 2.15. Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например:
Использование таких глаголов, как "обработать", "модернизировать" или "отредактировать" означает, как правило, недостаточно глубокое понимание данного процесса и требует дальнейшего анализа. Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс. Накопители данных Накопитель данных представляет собой абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми. Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Накопитель данных на диаграмме потоков данных изображается, как показано на рисунке 2.16. Накопитель данных идентифицируется буквой "D" и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика. Накопитель данных в общем случае является прообразом будущей базы данных и описание хранящихся в нем данных должно быть увязано с информационной моделью. Потоки данных Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д. Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рисунок 2.17). Каждый поток данных имеет имя, отражающее его содержание. Моделирование данных Case-метод Баркера Цель моделирования данных состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных. Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных. Нотация ERD была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера [8]. Метод Баркера будет излагаться на примере моделирования деятельности компании по торговле автомобилями. Ниже приведены выдержки из интервью, проведенного с персоналом компании. Главный менеджер: одна из основных обязанностей - содержание автомобильного имущества. Он должен знать, сколько заплачено за машины и каковы накладные расходы. Обладая этой информацией, он может установить нижнюю цену, за которую мог бы продать данный экземпляр. Кроме того, он несет ответственность за продавцов и ему нужно знать, кто что продает и сколько машин продал каждый из них. Продавец: ему нужно знать, какую цену запрашивать и какова нижняя цена, за которую можно совершить сделку. Кроме того, ему нужна основная информация о машинах: год выпуска, марка, модель и т.п. Администратор: его задача сводится к составлению контрактов, для чего нужна информация о покупателе, автомашине и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи. Первый шаг моделирования - извлечение информации из интервью и выделение сущностей. Сущность (Entity) - реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению (рисунок 2.18). Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами:
Обращаясь к приведенным выше выдержкам из интервью, видно, что сущности, которые могут быть идентифицированы с главным менеджером - это автомашины и продавцы. Продавцу важны автомашины и связанные с их продажей данные. Для администратора важны покупатели, автомашины, продавцы и контракты. Исходя из этого, выделяются 4 сущности (автомашина, продавец, покупатель, контракт), которые изображаются на диаграмме следующим образом (рисунок 2.19). Следующим шагом моделирования является идентификация связей. Связь (Relationship) - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя. Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка. Например, связь продавца с контрактом может быть выражена следующим образом:
Степень связи и обязательность графически изображаются следующим образом (рисунок 2.20). Таким образом, 2 предложения, описывающие связь продавца с контрактом, графически будут выражены следующим образом (рисунок 2.21). Описав также связи остальных сущностей, получим следующую схему (рисунок 2.22). Последним шагом моделирования является идентификация атрибутов. Атрибут - любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута. Атрибут может быть либо обязательным, либо необязательным (рисунок 2.23). Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа). Уникальный идентификатор - это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рисунок 2.24). Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком "#". Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности - это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные - как альтернативные ключи. С учетом имеющейся информации дополним построенную ранее диаграмму (рисунок 2.25). Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных. Подтипы и супертипы: одна сущность является обобщающим понятием для группы подобных сущностей (рисунок 2.26). Взаимно исключающие связи: каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей (рисунок 2.27). Рекурсивная связь: сущность может быть связана сама с собой (рисунок 2.28). Неперемещаемые (non-transferrable) связи: экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 2.29). Методология IDEF1 Метод IDEF1, разработанный Т.Рэмей (T.Ramey), также основан на подходе П.Чена и позволяет построить модель данных, эквивалентную реляционной модели в третьей нормальной форме. В настоящее время на основе совершенствования методологии IDEF1 создана ее новая версия - методология IDEF1X. IDEF1X разработана с учетом таких требований, как простота изучения и возможность автоматизации. IDEF1X-диаграммы используются рядом распространенных CASE-средств (в частности, ERwin, Design/IDEF). Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рисунок 2.30). Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком. Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей:
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае - неидентифицирующей. Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Мощность связи обозначается как по
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-09-20; просмотров: 7376; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.214.16 (0.015 с.) |




 Иерархия диаграмм потоков данных
Иерархия диаграмм потоков данных
 Контекстная диаграмма верхнего уровня определяет границы модели. Как правило, она имеет звездообразную топологию, в центре которой находится главный процесс, соединенный с приемниками и источниками информации, являющимися внешним окружением моделируемой информационной системы (рис. 6).
Контекстная диаграмма верхнего уровня определяет границы модели. Как правило, она имеет звездообразную топологию, в центре которой находится главный процесс, соединенный с приемниками и источниками информации, являющимися внешним окружением моделируемой информационной системы (рис. 6).