
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Консалтинг при автоматизации предприятий: подходы, методы, средстваСодержание книги
Поиск на нашем сайте
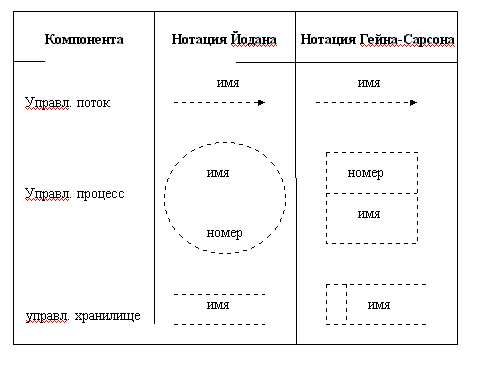
ГЛАВА 2 ДИАГРАММЫ ПОТОКОВ ДАННЫХ Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств - продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами. Диаграммы потоков данных известны очень давно. В фольклоре упоминается следующий пример использования DFD для реорганизации переполненного клерками офиса, относящийся к 20-м годам. Осуществлявший реорганизацию консультант обозначил кружком каждого клерка, а стрелкой - каждый документ, передаваемый между ними. Используя такую диаграмму, он предложил схему реорганизации, в соответствии с которой двое клерков, обменивающиеся множеством документов, были посажены рядом, а клерки с малым взаимодействием были посажены на большом расстоянии. Так родилась первая модель, представляющая собой потоковую диаграмму - предвестника DFD. Для изображения DFD традиционно используются две различные нотации: Йодана (Yourdon) и Гейна-Сарсона (Gane-Sarson). Далее при построении примеров будет использоваться нотация Йодана, все исключения будут предварительно оговариваться. 2.1. Основные символы Основные символы DFD изображены на рис.2.1. Опишем их назначение. На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных.
Рис. 2.1. Основные символы диаграммы потоков данных Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним - двунаправленным. Назначение ПРОЦЕССА состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, ВЫЧИСЛИТЬ МАКСИМАЛЬНУЮ ВЫСОТУ). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели. ХРАНИЛИЩЕ (НАКОПИТЕЛЬ) ДАННЫХ позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет "срезы" потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме. ВНЕШНЯЯ СУЩНОСТЬ (или ТЕРМИНАТОР) представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, СКЛАД ТОВАРОВ. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке. 2.2. Контекстная диаграмма и детализация процессов Декомпозиция DFD осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD нижнего уровня. Важную специфическую роль в модели играет специальный вид DFD - контекстная диаграмма, моделирующая систему наиболее общим образом. Контекстная диаграмма отражает интерфейс системы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель или природу системы насколько это возможно. И хотя контекстная диаграмма выглядит тривиальной, несомненная ее полезность заключается в том, что она устанавливает границы анализируемой системы. Каждый проект должен иметь ровно одну контекстную диаграмму, при этом нет необходимости в нумерации единственного ее процесса. DFD первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме. Построенная диаграмма первого уровня также имеет множество процессов, которые в свою очередь могут быть декомпозированы в DFD нижнего уровня. Таким образом строится иерархия DFD с контекстной диаграммой в корне дерева. Этот процесс декомпозиции продолжается до тех пор, пока процессы могут быть эффективно описаны с помощью коротких (до одной страницы) миниспецификаций обработки (спецификаций процессов). При таком построении иерархии DFD каждый процесс более низкого уровня необходимо соотнести с процессом верхнего уровня. Обычно для этой цели используются структурированные номера процессов. Так, например, если мы детализируем процесс номер 2 на диаграмме первого уровня, раскрывая его с помощью DFD, содержащей три процесса, то их номера будут иметь следующий вид: 2.1, 2.2 и 2.3. При необходимости можно перейти на следующий уровень, т.е. для процесса 2.2 получим 2.2.1, 2.2.2. и т.д. 2.3. Декомпозиция данных и соответствующие расширения диаграмм потоков данных Индивидуальные данные в системе часто являются независимыми. Однако иногда необходимо иметь дело с несколькими независимыми данными одновременно. Например, в системе имеются потоки ЯБЛОКИ, АПЕЛЬСИНЫ и ГРУШИ. Эти потоки могут быть сгруппированы с помощью введения нового потока ФРУКТЫ. Для этого необходимо определить формально поток ФРУКТЫ как состоящий из нескольких элементов-потомков. Такое определение задается с помощью формы Бэкуса-Наура (БНФ) в словаре данных (см. главу 3). В свою очередь поток ФРУКТЫ сам может содержаться в потоке-предке ЕДА вместе с потоками ОВОЩИ, МЯСО и др. Такие потоки, объдиняющие несколько потоков, получили название групповых. Обратная операция, расщепление потоков на подпотоки, осуществляется с использованием группового узла (рис. 2.2), позволяющего расщепить поток на любое число подпотоков. При расщеплении также необходимо формально определить подпотоки в словаре данных (с помощью БНФ).
Рис 2.2. Расширения диаграммы потоков данных Аналогичным образом осуществляется и декомпозиция потоков через границы диаграмм, позволяющая упростить детализирующую DFD. Пусть имеется поток ФРУКТЫ, входящий в детализируемый процесс. На детализирующей этот процесс диаграмме потока ФРУКТЫ может не быть вовсе, но вместо него могут быть потоки ЯБЛОКИ и АПЕЛЬСИНЫ (как будто бы они переданы из детализируемого процесса). В этом случае должно существовать БНФ-определение потока ФРУКТЫ, состоящего из подпотоков ЯБЛОКИ и АПЕЛЬСИНЫ, для целей балансирования. Применение этих операций над данными позволяет обеспечить структуризацию данных, увеличивает наглядность и читабельность диаграмм. Для обеспечения декомпозиции данных и некоторых других сервисных возможностей к DFD добавляются следующие типы объектов:
Возможный способ изображения этих узлов приведен на рис. 2.2. 2.4. Построение модели Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы:
2.5. Пример банковской задачи В качестве примера создания модели рассмотрим фрагмент проекта системы, организующей работу банкомата по обслуживанию клиента по его кредитной карте. Этот пример будет строиться поэтапно, на нем будут продемонстрированы базовые техники структурного анализа и проектирования по мере их определения.
Рис. 2.3. Контекстная диаграмма банковской задачи Для банковского обслуживания клиенту необходимо предоставить системе свою КРЕДИТНУЮ КАРТУ для автоматического считывания с нее информации (ПАРОЛЬ, ЛИМИТ ДЕНЕГ, ДЕТАЛИ КЛИЕНТА), а также сообщить свои КЛЮЧЕВЫЕ ДАННЫЕ, а именно ПАРОЛЬ и ЗАПРОС НА ОБСЛУЖИВАНИЕ, т.е. требуемую ему услугу (например, снятие со счета наличных денег). Банковское обслуживание с позиций клиента, в свою очередь, должно обеспечить следующее:
Контекстный процесс и КОМПЬЮТЕР БАНКА должны обмениваться следующей информацией:
Контекстный процесс может быть детализирован DFD первого уровня как показано на рис. 2.4. Эта диаграмма содержит 4 процесса и хранилище ДАННЫЕ КРЕДИТНОЙ КАРТЫ, которое изображено дважды на диаграмме с целью избежания пересечений линий потоков данных. Процесс 1.1 (ПОЛУЧИТЬ ПАРОЛЬ) осуществляет прием и проверку пароля клиента и имеет на входе/выходе следующие потоки:
Процесс 1.2 (ПОЛУЧИТЬ ЗАПРОС НА ОБСЛУЖИВАНИЕ) осуществляет прием и проверку запроса клиента на проведение необходимой ему банковской операции и имеет на входе/выходе следующие потоки:
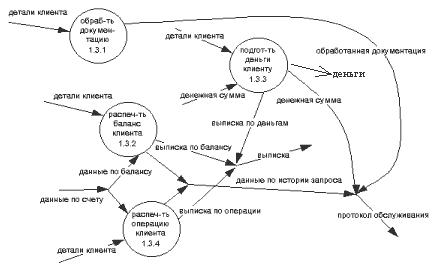
Рис. 2.4. Детализация процесса ОБСЛУЖИТЬ Процесс 1.3 (ОБРАБОТАТЬ ЗАПРОС НА ОБСЛУЖИВАНИЕ) имеет внешний входной поток ДАННЫЕ ПО СЧЕТУ (из внешней сущности КОМПЬЮТЕР БАНКА), входной поток ДЕТАЛИ КЛИЕНТА (из хранилища), а также внешние выходные потоки ВЫПИСКА, ДЕНЬГИ и ПРОТОКОЛ ОБСЛУЖИВАНИЯ. Процесс 1.4 (ОБРАБОТАТЬ КРЕДИТНУЮ КАРТУ) осуществляет считывание информации с кредитной карты и имеет на входе внешний поток КРЕДИТНАЯ КАРТА, а на выходе поток ДАННЫЕ КРЕДИТНОЙ КАРТЫ. Отметим, что нет необходимости в идентификации последнего потока, т.к. идентифицировано соответствующее хранилище. Процессы 1.1, 1.2 и 1.4 являются элементарными, поэтому нет необходимости в их детализации с помощью DFD уровня 2 (они будут раскрыты с помощью спецификаций процессов в главе 4). Процесс 1.3 может быть детализирован с помощью DFD второго уровня как показано на рис. 2.5. Эта диаграмма содержит 4 элементарных процесса, спецификации которых также будут приведены в главе 4. Процесс 1.3.1 (ОБРАБОТАТЬ ДОКУМЕНТАЦИЮ БАНКА) осуществляет обработку внутренней банковской документации по клиенту и имеет входной поток ДЕТАЛИ КЛИЕНТА и выходной поток ОБРАБОТАННАЯ ДОКУМЕНТАЦИЯ (часть внешнего потока ПРОТОКОЛ СДЕЛКИ). Процесс 1.3.2 (РАСПЕЧАТАТЬ БАЛАНС КЛИЕНТА) выдает справку по истории счета клиента и по балансу клиента. Входные потоки - ДЕТАЛИ КЛИЕНТА и ДАННЫЕ ПО БАЛАНСУ (часть внешнего потока ДАННЫЕ ПО СЧЕТУ), выходные потоки - ВЫПИСКА ПО БАЛАНСУ (часть внешнего потока ВЫПИСКА) и ДАННЫЕ ПО ИСТОРИИ ЗАПРОСА (часть внешнего потока ПРОТОКОЛ ОБСЛУЖИВАНИЯ). Процесс 1.3.3 (ПРИГОТОВИТЬ ДЕНЬГИ КЛИЕНТУ) обеспечивает выдачу наличных денег и информирование компьютера банка об изъятых из банка деньгах. Он имеет входные потоки ДЕНЕЖНАЯ СУММА и ДЕТАЛИ КЛИЕНТА, и выходные потоки ДЕНЬГИ и ДЕНЕЖНАЯ СУММА (часть потока ПРОТОКОЛ ОБСЛУЖИВАНИЯ).
Рис. 2.5. Детализация процесса ОБРАБОТАТЬ ЗАПРОС НА ОБСЛУЖИВАНИЕ Процесс 1.3.4 (РАСПЕЧАТАТЬ ОПЕРАЦИЮ КЛИЕНТА) выдает справку по истории счета и уведомление по проведенной операции. Входные потоки ДАННЫЕ ПО СЧЕТУ и ДЕТАЛИ КЛИЕНТА, выходные потоки - ВЫПИСКА ПО ОПЕРАЦИИ (часть потока ВЫПИСКА) и ДАННЫЕ ПО ИСТОРИИ ЗАПРОСА (часть потока ПРОТОКОЛ ОБСЛУЖИВАНИЯ). 2.6. Расширения реального времени Расширения реального времени используются для дополнения модели функционирования данных (иерархии DFD) средствами описания управляющих аспектов в системах реального времени. Для этих целей применяются следующие символы (рис. 2.6):
Логически управляющий процесс есть некий командный пункт, реагирующий на изменения внешних условий, передаваемые ему с помощью управляющих потоков, и продуцирующий в соответствии со своей внутренней логикой выполняемые процессами команды.
Рис. 2.6. Расширения реального времени При этом режим выполнения процесса зависит от типа управляющего потока. Имеются следующие типы управляющих потоков:
Иногда возникает необходимость в представлении одного и того же фрагмента данных потоками различных типов. Например, поток данных СКОРОСТЬ МАШИНЫ в отдельных случаях может использоваться как управляющий для контроля критического значения. Для обеспечения этого используется УЗЕЛ ИЗМЕНЕНИЯ ТИПА (рис. 2.7): поток данных является входным для этого узла, а управляющий поток - выходным.
Рис. 2.7. Узел изменения типа Дополним модель предложенной в 2.5 банковской системы, введя в диаграммы управляющий процесс и управляющие потоки, позволяющие описать ее функционирование в реальном времени. После такого расширения DFD, приведенные на рис. 2.4 и 2.5 будут выглядеть, как показано на рис. 2.8 и 2.9, соответственно. Управляющий процесс 1.5 (УПРАВЛЕНИЕ ОБСЛУЖИВАНИЕМ), получив информацию о том, что кредитная карта введена (поток ВВЕДЕННАЯ КРЕДИТНАЯ КАРТА), вызывает выполнение процесса 1.1 (поток А: ПОЛУЧИТЬ ПАРОЛЬ). Получив информацию о введенном пароле (поток КОРРЕКТНЫЙ ПАРОЛЬ), процесс 1.5 информирует процесс 1.4 о необходимости удаления кредитной карты (поток: УДАЛЕННАЯ КРЕДИТНАЯ КАРТА) и с помощью потока Т: ОБЕСПЕЧИТЬ ТРЕБУЕМОЕ ОБСЛУЖИВАНИЕ вызывает выполнение процесса 1.2, затем процесса 1.3 (поток ТРЕБУЕМОЕ ОБСЛУЖИВАНИЕ).
Рис. 2.8. Расширение диаграммы, детализирующей контекстный процесс
Рис. 2.9. Расширение диаграммы, детализирующей процесс 1.3
ГЛАВА 3 СЛОВАРЬ ДАННЫХ Диаграммы потоков данных обеспечивают удобное описание функционирования компонент системы, но не снабжают аналитика средствами описания деталей этих компонент, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных задач предназначены текстовые средства моделирования, служащие для описания структуры преобразуемой информации и получившие название словарей данных. Словарь данных представляет собой определенным образом организованный список всех элементов данных системы с их точными определениями, что дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ. Определения элементов данных в словаре осуществляются следующими видами описаний:
3.1. Содержимое словаря данных Для каждого потока данных в словаре необходимо хранить имя потока, его тип и атрибуты. Информация по каждому потоку состоит из ряда словарных статей, каждая из которых начинается с ключевого слова - заголовка соответствующей статьи, которому предшествует символ “@”. По типу потока в словаре содержится информация, идентифицирующая:
Атрибуты потока данных включают:
3.2. БНФ - нотация БНФ-нотация позволяет формально описать расщепление/ объединение потоков. Поток может расщепляться на собственные отдельные ветви, на компоненты потока-предка или на то и другое одновременно. При расщеплении/объединении потока существенно, чтобы каждый компонент потока-предка являлся именованным. Если поток расщепляется на подпотоки, необходимо, чтобы все подпотоки являлись компонентами потока-предка. И наоборот, при объединении потоков каждый компонент потока-предка должен по крайней мере однажды встречаться среди подпотоков. Отметим, что при объединении подпотоков нет необходимости осуществлять исключение общих компонент, а при расщеплении подпотоки могут иметь такие общие (одинаковые) компоненты. Важно понимать, что точные определения потоков содержатся в словаре данных, а не на диаграммах. Например, на диаграмме может иметься групповой узел с входным потоком X и выходными подпотоками Y и Z. Однако это вовсе не означает, что соответствующее определение в словаре данных обязательно должно быть X=Y+Z. Это определение может быть следующим: X=A+B+C; Y=A+B; Z=B+C Такие определения хранятся в словаре данных в так называемой БНФ-статье. БНФ-статья используется для описания компонент данных в потоках данных и в хранилищах. Ее синтаксис имеет вид: @БНФ = <простой оператор>! <БНФ-выражение>, где <простой оператор> есть текстовое описание, заключенное в "/", а <БНФ-выражение> есть выражение в форме Бэкуса-Наура, допускающее следующие операции отношений:
Итерационные скобки могут иметь нижний и верхний предел, например:
БНФ-выражение может содержать произвольные комбинации операций:
Ниже приведен пример описания потока данных с помощью БНФ:
Посмотрим, как некоторые потоки, присутствующие на вышеприведенных диаграммах потоков данных, представляются в словаре данных.
ГЛАВА 4 МЕТОДЫ ЗАДАНИЯ СПЕЦИФИКАЦИЙ ПРОЦЕССОВ Спецификация процесса (СП) используется для описания функционирования процесса в случае отсутствия необходимости детализировать его с помощью DFD (т.е. если он достаточно невелик, и его описание может занимать до одной страницы текста). Фактически СП представляют собой алгоритмы описания задач, выполняемых процессами: множество всех СП является полной спецификацией системы. СП содержат номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое число разнообразных методов, позволяющих задать тело процесса, соответствующий язык может варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования (типа FLOW-форм и диаграмм Насси-Шнейдермана) и формальных компьютерных языков. Независимо от используемой нотации спецификация процесса должна начинаться с ключевого слова (например, @СПЕЦПРОЦ). Требуемые входные и выходные данные должны быть специфицированы следующим образом: @ВХОД = <имя символа данных> @ВЫХОД = <имя символа данных> @ВХОДВЫХОД = <имя символа данных>, где <имя символа данных> - соответствующее имя из словаря данных. Эти ключевые слова должны использоваться перед определением СП, например, @ВХОД = СЛОВА ПАМЯТИ @ВЫХОД = ХРАНИМЫЕ ЗНАЧЕНИЯ @СПЕЦПРОЦ Распечатать ХРАНИМЫЕ ЗНАЧЕНИЯ @ Ситуация, когда символ данных является одновременно входным и выходным, может быть описана двумя способами: либо символ описывается два раза с помощью @ВХОД и @ВЫХОД, либо один раз с помощью @ВХОДВЫХОД. Иногда в СП задаются пред- и пост-условия выполнения данного процесса. В пред-условии записываются объекты, значения которых должны быть истинны перед началом выполнения процесса, что обеспечивает определенные гарантии безопасности для пользователя. Аналогично, в случае наличия пост-условия гарантируется, что значения всех входящих в него объектов будут истинны при завершении процесса. Спецификации должны удовлетворять следующим требованиям:
Ниже рассматриваются некоторые наиболее часто используемые методы задания спецификаций процессов. 4.1. Структурированный естественный язык Структурированный естественный язык применяется для читабельного, строгого описания спецификаций процессов. Он является разумной комбинацией строгости языка программирования и читабельности естественного языка и состоит из подмножества слов, организованных в определенные логические структуры, арифметических выражений и диаграмм. В состав языка входят следующие основные символы:
Управляющие структуры языка имеют один вход и один выход. К ним относятся: 1) последовательная конструкция: ВЫПОЛНИТЬ функция1 ВЫПОЛНИТЬ функция2 ВЫПОЛНИТЬ функция3 2) конструкция выбора: ЕСЛИ <условие> ТО ВЫПОЛНИТЬ функция1 ИНАЧЕ КОНЕЦЕСЛИ 3) итерация: ДЛЯ <условие> ВЫПОЛНИТЬ функция КОНЕЦДЛЯ ВЫПОЛНИТЬ функция КОНЕЦПОКА При использовании структурированного естественного языка приняты следующие соглашения:
Ниже приведен пример спецификации процесса 1 (ПОЛУЧИТЬ ПАРОЛЬ) для диаграммы, изображенной на рис. 2.8. @ВХОД = ВВЕДЕННЫЙ ПАРОЛЬ @ВХОД = ПАРОЛЬ @ВЫХОД = СООБЩЕНИЕ @ВЫХОД = КОРРЕКТНЫЙ ПАРОЛЬ @СПЕЦПРОЦ 1.1 ПОЛУЧИТЬ ПАРОЛЬ ВЫПОЛНИТЬ выдать СООБЩЕНИЕ клиенту, запрашивающее ввод пароля принять ВВЕДЕННЫЙ ПАРОЛЬ ДОТЕХПОРПОКА ВВЕДЕННЫЙ ПАРОЛЬ = ПАРОЛЬ или были сделаны три попытки ввода КОНЕЦВЫПОЛНИТЬ ПАРОЛЬ в случае равенства @ КОНЕЦ СПЕЦИФИКАЦИИ ПРОЦЕССА 1.1 4.2. Таблицы и деревья решений Структурированный естественный язык неприемлем для некоторых типов преобразований. Например, если действие зависит от нескольких переменных, которые в совокупности могут продуцировать большое число комбинаций, то его описание будет слишком запутанным и с большим числом уровней вложенности. Для описания подобных действий традиционно используются таблицы и деревья решений. Проектирование спецификаций процессов с помощью таблиц решений (ТР) заключается в задании матрицы, отображающей множество входных условий в множество действий. ТР состоит из двух частей. Верхняя часть таблицы используется для определения условий. Обычно условие является ЕСЛИ-частью оператора ЕСЛИ-ТО и требует ответа "да-нет". Однако иногда в условии может присутствовать и ограниченное множество значений, например, ЯВЛЯЕТСЯ ЛИ ДЛИНА СТРОКИ БОЛЬШЕЙ, МЕНЬШЕЙ ИЛИ РАВНОЙ ГРАНИЧНОМУ ЗНАЧЕНИЮ? Нижняя часть ТР используется для определения действий, т.е. ТО-части оператора ЕСЛИ-ТО. Так, в конструкции ЕСЛИ ИДЕТ ДОЖДЬ ТО РАСКРЫТЬ ЗОНТ ИДЕТ ДОЖДЬ является условием, а РАСКРЫТЬ ЗОНТ - действием. Левая часть ТР содержит собственно описание условий и действий, а в правой части перечисляются все возможные комбинации условий и, соответственно, указывается, какие конкретно действия и в какой последовательности выполняются, когда определенная комбинация условий имеет место. Поясним вышесказанное на примере спецификации процесса выбора символов из входного потока. При выборе символов необходимо руководствоваться следующими правилами: 1) если очередной символ является управляющим, то подать звуковой сигнал и вернуть код ошибки; Таблица 4.1
|

 ПОТОКИ ДАННЫХ являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
ПОТОКИ ДАННЫХ являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
 На рис. 2.3 приведена контекстная диаграмма системы с единственным процессом ОБСЛУЖИТЬ, идентифицирующая внешние сущности КЛИЕНТ и КОМПЬЮТЕР БАНКА, хранящий информацию о счетах всех клиентов. Опишем потоки данных, которыми обменивается проектируемая система с внешними объектами.
На рис. 2.3 приведена контекстная диаграмма системы с единственным процессом ОБСЛУЖИТЬ, идентифицирующая внешние сущности КЛИЕНТ и КОМПЬЮТЕР БАНКА, хранящий информацию о счетах всех клиентов. Опишем потоки данных, которыми обменивается проектируемая система с внешними объектами.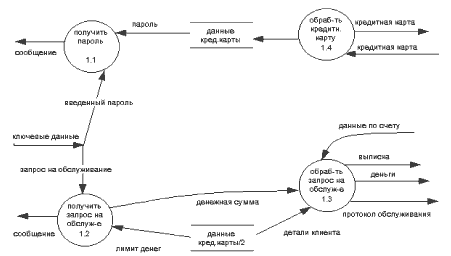


 Последний управляющий поток на детализирующей процесс 1.3 диаграмме расчленяется на 4 подпотока, каждый из которых вызывает выполнение процессов 1.3.1 - 1.3.4, соответственно.
Последний управляющий поток на детализирующей процесс 1.3 диаграмме расчленяется на 4 подпотока, каждый из которых вызывает выполнение процессов 1.3.1 - 1.3.4, соответственно.


